BanditBench: A Bandit Benchmark to Evaluate Self-Improving LLM Algorithms

Project description
EVOLvE: Evaluating and Optimizing LLMs For Exploration In-Context







EVOLvE is a framework for evaluating Large Language Models (LLMs) for In-Context Reinforcement Learning (ICRL). We provide a flexible framework for single-step RL experiments (bandit) with LLMs. This repository contains the code to reproduce the results from the EVOLvE paper.
📰 News
- [Jan 2025] 🎉 EVOLvE codebase is released and available on GitHub
- [Jan 2025] 📦 First version of
banditbenchpackage is published on PyPI - [Oct 2024] 📄 Our paper "EVOLvE: Evaluating and Optimizing LLMs For Exploration" is now available on arXiv
🚀 Features
- Flexible framework for evaluating LLMs for In-Context Reinforcement Learning (ICRL)
- Support for both multi-armed and contextual bandit scenarios
- Mixin-based design for highly customizable LLM agents
- Built-in support for few-shot learning and demonstration
- Includes popular benchmark environments (e.g., MovieLens)
🛠️ Installation
Option 1: Install from PyPI (Recommended for Users)
pip install banditbench
Option 2: Install from Source (Recommended for Developers)
git clone https://github.com/allenanie/EVOLvE.git
cd EVOLvE
pip install -e . # Install in editable mode for development
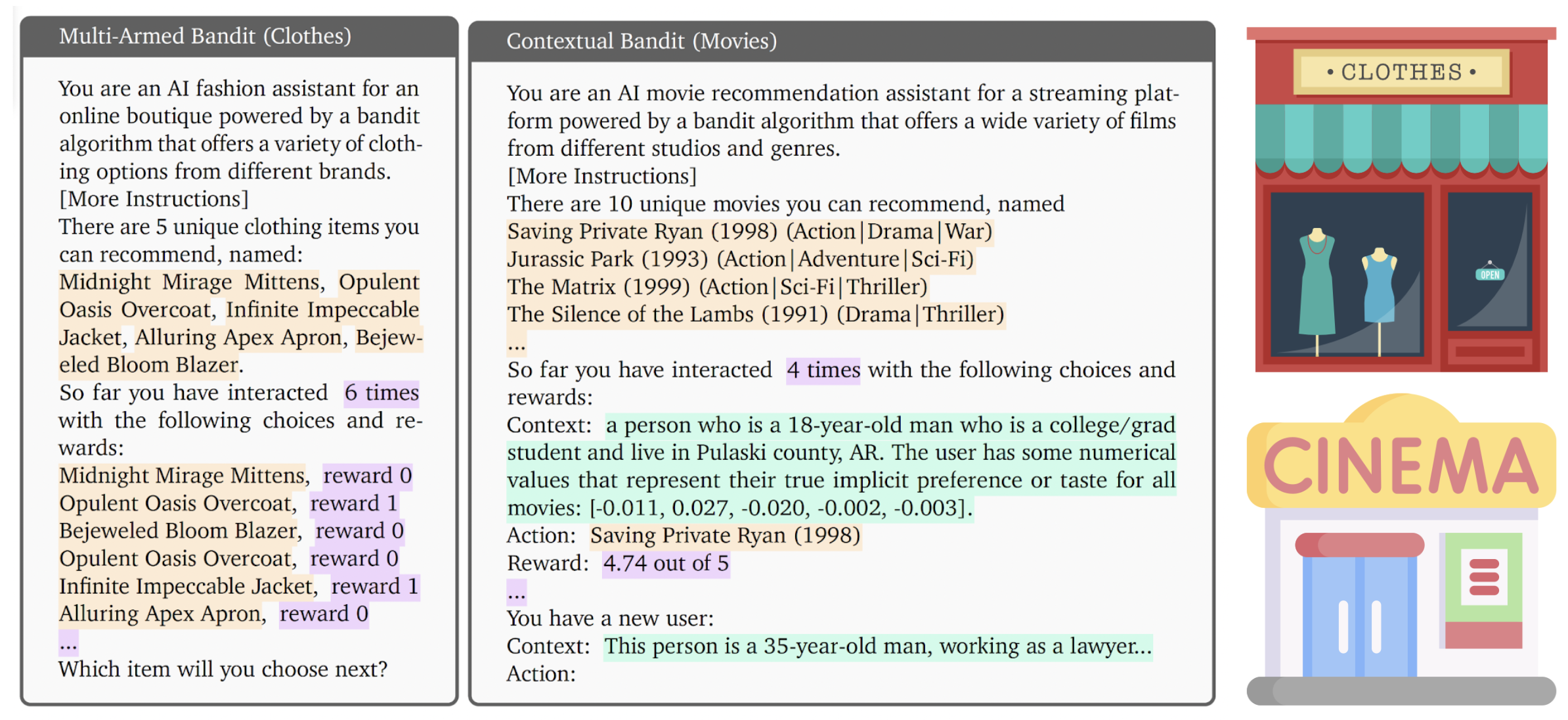
🎯 Bandit Scenario
We provide two types of bandit scenarios:
Multi-Armed Bandit Scenario
- Classic exploration-exploitation problem with stochastic reward sampled from a fixed distributions
- Agent learns to select the best arm without any contextual information
- Example: Choosing between 5 different TikTok videos to show, without knowing which one is more popular at first
Contextual Bandit Scenario
- Reward distributions depend on a context (e.g., user features)
- Agent learns to map contexts to optimal actions
- Example: Recommending movies to users based on their age, location (e.g., suggesting "The Dark Knight" to a 25-year-old who enjoys action movies and lives in an urban area)
🎮 Quick Start
Evaluate LLMs for their In-Context Reinforcement Learning Performance
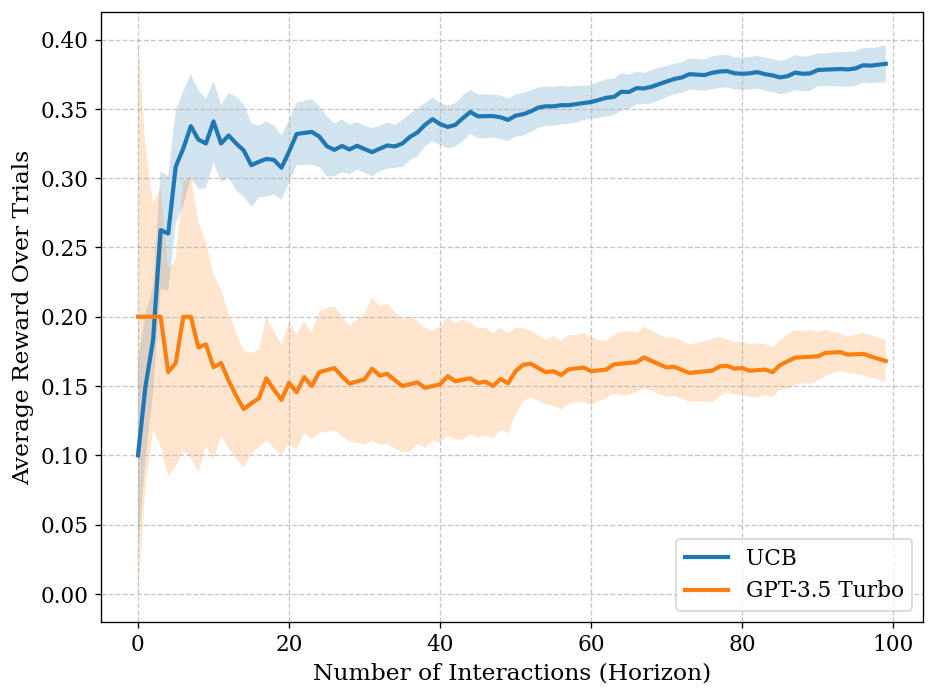
In this example, we will compare the performance of two agents (LLM and one of the classic agents) on a multi-armed bandit task.
from banditbench.tasks.mab import BernoulliBandit, VerbalMultiArmedBandit
from banditbench.agents.llm import LLMAgent
from banditbench.agents.classics import UCBAgent
# this is a 5-armed bandit
# with the probability of getting a reward to be [0.2, 0.2, 0.2, 0.2, 0.5]
core_bandit = BernoulliBandit(5, horizon=100, arm_params=[0.2, 0.2, 0.2, 0.2, 0.5])
# The scenario is "ClothesShopping", agent sees actions as clothing items
verbal_bandit = VerbalMultiArmedBandit(core_bandit, "ClothesShopping")
# we create an LLM agent that uses summary statistics (mean, number of times, etc.)
agent = LLMAgent.build(verbal_bandit, summary=True, model="gpt-3.5-turbo")
llm_result = agent.in_context_learn(verbal_bandit, n_trajs=5)
# we create a UCB agent, which is a classic agent that uses
# Upper Confidence Bound to make decisions
classic_agent = UCBAgent(core_bandit)
# we run the classic agent in-context learning on the core bandit for 5 trajectories
classic_result = classic_agent.in_context_learn(core_bandit, n_trajs=5)
classic_result.plot_performance(llm_result, labels=['UCB', 'GPT-3.5 Turbo'])
Doing this will give you a plot like this:
🌍 Environments & 🤖 Agents
Here are a list of agents that are supported by EVOLvE:
For Multi-Armed Bandit Scenario:
| Agent Name | Code | Interaction History | Algorithm Guide |
|---|---|---|---|
| UCB | UCBAgent(env) |
False |
NA |
| Greedy | GreedyAgent(env) |
False |
NA |
| Thompson Sampling | ThompsonSamplingAgent(env) |
False |
NA |
| LLM with Raw History | LLMAgent.build(env) |
False |
False |
| LLM with Summary | LLMAgent.build(env, summary=True) |
True |
False |
| LLM with UCB Guide | LLMAgent.build(env, summary=True, guide=UCBGuide(env)) |
True |
True |
For Contextual Bandit Scenario:
| Agent Name | Code | Interaction History | Algorithm Guide |
|---|---|---|---|
| LinUCB | LinUCBAgent(env) |
False |
NA |
| LLM with Raw History | LLMAgent.build(env) |
False |
False |
| LLM with UCB Guide | LLMAgent.build(env, guide=LinUCBGuide(env)) |
True |
True |
Here are a list of environments that are supported by EVOLvE:
Multi-Armed Bandit Scenario
| Environment Name | Code | Description |
|---|---|---|
| Bernoulli Bandit | BernoulliBandit(n_arms, horizon, arm_params) |
Arm parameter is Bernoulli p |
| Gaussian Bandit | GaussianBandit(n_arms, horizon, arm_params) |
Arm parameter is a tuple of (mean, variance) |
For LLM, we provide a VerbalMultiArmedBandit environment that converts the core bandit into a verbal bandit.
| Scenario Name | Code | Action Names |
|---|---|---|
| Button Pushing | ButtonPushing |
Action names are colored buttons like "Red", "Blue", "Green", etc. |
| Online Ads | OnlineAds |
Action names are online ads like "Ad A", "Ad B", "Ad C", etc. |
| Video Watching | VideoWatching |
Action names are videos like "Video A", "Video B", "Video C", etc. |
| Clothes Shopping | ClothesShopping |
Action names are clothing items like "Velvet Vogue Jacket", "Silk Serenity Dress", etc. |
They can be coupled together like:
from banditbench.tasks.mab import BernoulliBandit, VerbalMultiArmedBandit
core_bandit = BernoulliBandit(2, 10, [0.5, 0.2], 123)
verbal_bandit = VerbalMultiArmedBandit(core_bandit, "VideoWatching")
Contextual Bandit Scenario
| Environment Name | Code | Description |
|---|---|---|
| MovieLens | MovieLens(task_name, num_arms, horizon) |
task_name loads in specific MovieLens dataset |
| MovieLensVerbal | MovieLensVerbal(env) |
Similar to VerbalEnv before. Scenario is fixed to be "MovieLens" |
from banditbench.tasks.contextual import MovieLens, MovieLensVerbal
env = MovieLens('100k-ratings', num_arms=10, horizon=200, rank_k=5, mode='train',
save_data_dir='./tensorflow_datasets/')
verbal_env = MovieLensVerbal(env)
To use the environments listed in the paper, you can use the following code:
from banditbench.tasks.mab import create_small_gap_bernoulli_bandit, create_large_gap_bernoulli_bandit
from banditbench.tasks.mab import create_high_var_gaussian_bandit, create_low_var_gaussian_bandit
easy_bern_bandit = create_small_gap_bernoulli_bandit(num_arms=5, horizon=1000)
🧩 Architecture
Decision-Making Context
The framework represents decision-making contexts in three segments:
{Task Description + Instruction} (provided by the environment)
{Few-shot demonstrations from historical interactions}
{Current history of interaction} (decided by the agent)
{Query prompt for the next decision} (provided by the environment)
LLM Agents
We use a Mixin-based design pattern to provide maximum flexibility and customization options for agent implementation. This allows you to:
- Combine different agent behaviors
- Customize prompt engineering strategies
- Implement new decision-making algorithms
🔧 Customization
Adding Custom Multi-Armed Bandit Scenarios
To create a custom bandit scenario:
- Inherit from the base scenario class
- Implement required methods (Coming soon)
Creating Custom Agents
(Coming soon)
⚠️ Known Issues
-
TFDS Issues: There is a known issue with TensorFlow Datasets when using multiple Jupyter notebooks sharing the same kernel. The kernel may crash when loading datasets, even with different save locations.
-
TensorFlow Dependency: The project currently requires TensorFlow due to TFDS usage. We plan to remove this dependency in future releases.
🎈 Citation
If you find EVOLvE useful in your research, please consider citing our paper:
@article{nie2024evolve,
title={EVOLvE: Evaluating and Optimizing LLMs For Exploration},
author={Nie, Allen and Su, Yi and Chang, Bo and Lee, Jonathan N and Chi, Ed H and Le, Quoc V and Chen, Minmin},
journal={arXiv preprint arXiv:2410.06238},
year={2024}
}
📄 License
This project is licensed under the [LICENSE NAME] - see the LICENSE file for details.
🌻 Acknowledgement
The design of EVOLvE is inspired by the following projects:
🤝 Contributing
We welcome contributions! Please start by reporting an issue or a feature request.



Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file banditbench-0.0.3.tar.gz.
File metadata
- Download URL: banditbench-0.0.3.tar.gz
- Upload date:
- Size: 4.0 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.10.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
58396c0a5af15cf180956ecf88d7416dcb7dc7941bdb460958cacc4d6cf6c708
|
|
| MD5 |
dc7a25a01bf91d8655000bd02c9f2f01
|
|
| BLAKE2b-256 |
cce3f6d758d481926e620d19417c08b7f79d5f80fece082f0eae991dd38eb879
|
File details
Details for the file banditbench-0.0.3-py3-none-any.whl.
File metadata
- Download URL: banditbench-0.0.3-py3-none-any.whl
- Upload date:
- Size: 348.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.10.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
58717e96c363fa50bd170422fbfa78d57d07e11bd02b833b721ff8c36ea90b8d
|
|
| MD5 |
d286fef9a0c12a03d7957b0d4823c027
|
|
| BLAKE2b-256 |
027c59e428049006d2f5f57ce5a2e748318bd2f61eb71e13b35498fc974c2855
|







