A ultra-high performance package for sending requests to Baseten Embedding Inference'



Project description
High performance client for Baseten.co
This library provides a high-performance Python client for Baseten.co endpoints including embeddings, reranking, and classification. It was built for massive concurrent post requests to any URL, also outside of baseten.co. PerformanceClient releases the GIL while performing requests in the Rust, and supports simultaneous sync and async usage. It was benchmarked with >1200 rps per client in our blog. PerformanceClient is built on top of pyo3, reqwest and tokio and is MIT licensed.
Installation
pip install baseten_performance_client
Usage
import os
import asyncio
from baseten_performance_client import PerformanceClient, OpenAIEmbeddingsResponse, RerankResponse, ClassificationResponse
api_key = os.environ.get("BASETEN_API_KEY")
base_url_embed = "https://model-yqv4yjjq.api.baseten.co/environments/production/sync"
# Also works with OpenAI or Mixedbread.
# base_url_embed = "https://api.openai.com" or "https://api.mixedbread.com"
# Basic client setup
client = PerformanceClient(base_url=base_url_embed, api_key=api_key)
# Advanced setup with HTTP version selection and connection pooling
from baseten_performance_client import HttpClientWrapper
http_wrapper = HttpClientWrapper(http_version=1) # HTTP/1.1 (default)
advanced_client = PerformanceClient(
base_url=base_url_embed,
api_key=api_key,
http_version=1, # HTTP/1.1
client_wrapper=http_wrapper # Share connection pool
)
Embeddings
Synchronous Embedding
from baseten_performance_client import RequestProcessingPreference
texts = ["Hello world", "Example text", "Another sample"]
preference = RequestProcessingPreference(
batch_size=16,
max_concurrent_requests=32,
timeout_s=360,
max_chars_per_request=256000, # Character limit per request
hedge_delay=0.5, # Enable hedging with 0.5s delay
total_timeout_s=360 # Total operation timeout
)
response = client.embed(
input=texts,
model="my_model",
preference=preference
)
# Accessing embedding data
print(f"Model used: {response.model}")
print(f"Total tokens used: {response.usage.total_tokens}")
print(f"Total time: {response.total_time:.4f}s")
if response.individual_batch_request_times:
for i, batch_time in enumerate(response.individual_batch_request_times):
print(f" Time for batch {i}: {batch_time:.4f}s")
for i, embedding_data in enumerate(response.data):
print(f"Embedding for text {i} (original input index {embedding_data.index}):")
# embedding_data.embedding can be List[float] or str (base64)
if isinstance(embedding_data.embedding, list):
print(f" First 3 dimensions: {embedding_data.embedding[:3]}")
print(f" Length: {len(embedding_data.embedding)}")
# Using the numpy() method (requires numpy to be installed)
import numpy as np
numpy_array = response.numpy()
print("\nEmbeddings as NumPy array:")
print(f" Shape: {numpy_array.shape}")
print(f" Data type: {numpy_array.dtype}")
if numpy_array.shape[0] > 0:
print(f" First 3 dimensions of the first embedding: {numpy_array[0][:3]}")
Note: The embed method is versatile and can be used with any embeddings service, e.g. OpenAI API embeddings, not just for Baseten deployments.
Asynchronous Embedding
async def async_embed():
from baseten_performance_client import RequestProcessingPreference
texts = ["Async hello", "Async example"]
preference = RequestProcessingPreference(
batch_size=16,
max_concurrent_requests=32,
timeout_s=360,
max_chars_per_request=256000, # Character limit per request
hedge_delay=0.5, # Enable hedging with 0.5s delay
total_timeout_s=360 # Total operation timeout
)
response = await client.async_embed(
input=texts,
model="my_model",
preference=preference
)
print("Async embedding response:", response.data)
# To run:
# asyncio.run(async_embed())
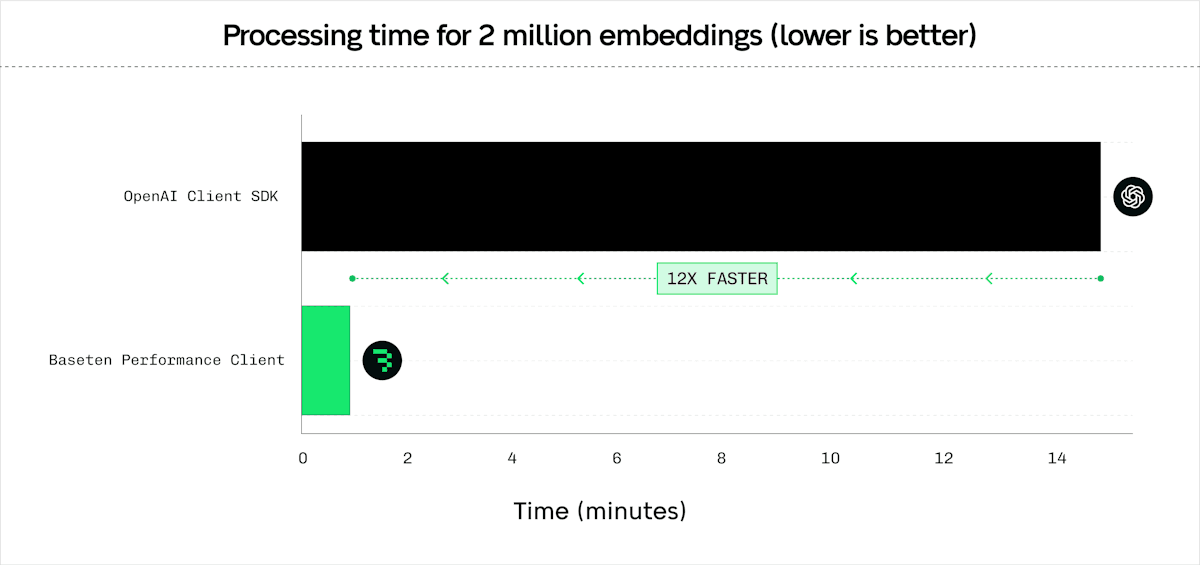
Embedding Benchmarks
Comparison against pip install openai for /v1/embeddings. Tested with the ./scripts/compare_latency_openai.py with mini_batch_size of 128, and 4 server-side replicas. Results with OpenAI similar, OpenAI allows a max mini_batch_size of 2048.
| Number of inputs / embeddings | Number of Tasks | PerformanceClient (s) | AsyncOpenAI (s) | Speedup |
|---|---|---|---|---|
| 128 | 1 | 0.12 | 0.13 | 1.08× |
| 512 | 4 | 0.14 | 0.21 | 1.50× |
| 8 192 | 64 | 0.83 | 1.95 | 2.35× |
| 131 072 | 1 024 | 4.63 | 39.07 | 8.44× |
| 2 097 152 | 16 384 | 70.92 | 903.68 | 12.74× |
General Batch POST
The batch_post method is generic. It can be used to send POST requests to any URL, not limited to Baseten endpoints. The input and output can be any JSON item.
Synchronous Batch POST
from baseten_performance_client import RequestProcessingPreference
payload1 = {"model": "my_model", "input": ["Batch request sample 1"]}
payload2 = {"model": "my_model", "input": ["Batch request sample 2"]}
preference = RequestProcessingPreference(
max_concurrent_requests=32,
timeout_s=360,
hedge_delay=0.5, # Enable hedging with 0.5s delay
total_timeout_s=360, # Total operation timeout
extra_headers={"x-custom-header": "value"} # Custom headers
)
response_obj = client.batch_post(
url_path="/v1/embeddings", # Example path, adjust to your needs
payloads=[payload1, payload2],
preference=preference
)
print(f"Total time for batch POST: {response_obj.total_time:.4f}s")
for i, (resp_data, headers, time_taken) in enumerate(zip(response_obj.data, response_obj.response_headers, response_obj.individual_request_times)):
print(f"Response {i+1}:")
print(f" Data: {resp_data}")
print(f" Headers: {headers}")
print(f" Time taken: {time_taken:.4f}s")
Asynchronous Batch POST
async def async_batch_post_example():
from baseten_performance_client import RequestProcessingPreference
payload1 = {"model": "my_model", "input": ["Async batch sample 1"]}
payload2 = {"model": "my_model", "input": ["Async batch sample 2"]}
preference = RequestProcessingPreference(
max_concurrent_requests=32,
timeout_s=360,
hedge_delay=0.5, # Enable hedging with 0.5s delay
total_timeout_s=360, # Total operation timeout
extra_headers={"x-custom-header": "value"} # Custom headers
)
response_obj = await client.async_batch_post(
url_path="/v1/embeddings",
payloads=[payload1, payload2],
preference=preference
)
print(f"Async total time for batch POST: {response_obj.total_time:.4f}s")
for i, (resp_data, headers, time_taken) in enumerate(zip(response_obj.data, response_obj.response_headers, response_obj.individual_request_times)):
print(f"Async Response {i+1}:")
print(f" Data: {resp_data}")
print(f" Headers: {headers}")
print(f" Time taken: {time_taken:.4f}s")
# To run:
# asyncio.run(async_batch_post_example())
Reranking
Reranking compatible with BEI or text-embeddings-inference.
Synchronous Reranking
from baseten_performance_client import RequestProcessingPreference
query = "What is the best framework?"
documents = ["Doc 1 text", "Doc 2 text", "Doc 3 text"]
preference = RequestProcessingPreference(
batch_size=16,
max_concurrent_requests=32,
timeout_s=360,
max_chars_per_request=256000, # Character limit per request
hedge_delay=0.5, # Enable hedging with 0.5s delay
total_timeout_s=360 # Total operation timeout
)
rerank_response = client.rerank(
query=query,
texts=documents,
model="rerank-model", # Optional model specification
return_text=True,
preference=preference
)
for res in rerank_response.data:
print(f"Index: {res.index} Score: {res.score}")
Asynchronous Reranking
async def async_rerank():
from baseten_performance_client import RequestProcessingPreference
query = "Async query sample"
docs = ["Async doc1", "Async doc2"]
preference = RequestProcessingPreference(
batch_size=16,
max_concurrent_requests=32,
timeout_s=360,
max_chars_per_request=256000, # Character limit per request
hedge_delay=0.5, # Enable hedging with 0.5s delay
total_timeout_s=360 # Total operation timeout
)
response = await client.async_rerank(
query=query,
texts=docs,
model="rerank-model", # Optional model specification
return_text=True,
preference=preference
)
for res in response.data:
print(f"Async Index: {res.index} Score: {res.score}")
# To run:
# asyncio.run(async_rerank())
Classification
Predict (classification endpoint) compatible with BEI or text-embeddings-inference.
Synchronous Classification
from baseten_performance_client import RequestProcessingPreference
texts_to_classify = [
"This is great!",
"I did not like it.",
"Neutral experience."
]
preference = RequestProcessingPreference(
batch_size=16,
max_concurrent_requests=32,
timeout_s=360,
max_chars_per_request=256000, # Character limit per request
hedge_delay=0.5, # Enable hedging with 0.5s delay
total_timeout_s=360 # Total operation timeout
)
classify_response = client.classify(
inputs=texts_to_classify,
model="classification-model", # Optional model specification
preference=preference
)
for group in classify_response.data:
for result in group:
print(f"Label: {result.label}, Score: {result.score}")
Asynchronous Classification
async def async_classify():
from baseten_performance_client import RequestProcessingPreference
texts = ["Async positive", "Async negative"]
preference = RequestProcessingPreference(
batch_size=16,
max_concurrent_requests=32,
timeout_s=360,
max_chars_per_request=256000, # Character limit per request
hedge_delay=0.5, # Enable hedging with 0.5s delay
total_timeout_s=360 # Total operation timeout
)
response = await client.async_classify(
inputs=texts,
model="classification-model", # Optional model specification
preference=preference
)
for group in response.data:
for res in group:
print(f"Async Label: {res.label}, Score: {res.score}")
# To run:
# asyncio.run(async_classify())
Advanced Features
RequestProcessingPreference
The RequestProcessingPreference class provides a unified way to configure all request processing parameters. This is the recommended approach for advanced configuration as it provides better type safety and clearer intent.
from baseten_performance_client import RequestProcessingPreference
# Create a preference with custom settings
preference = RequestProcessingPreference(
max_concurrent_requests=64, # Parallel requests (default: 128)
batch_size=32, # Items per batch (default: 128)
timeout_s=30.0, # Per-request timeout (default: 3600.0)
hedge_delay=0.5, # Hedging delay (default: None)
hedge_budget_pct=0.15, # Hedge budget percentage (default: 0.10)
retry_budget_pct=0.08, # Retry budget percentage (default: 0.05)
max_retries=3, # Maximum HTTP retries (default: 4)
initial_backoff_ms=250, # Initial backoff in milliseconds (default: 125)
total_timeout_s=300.0 # Total operation timeout (default: None)
)
# Use with any method
response = client.embed(
input=["text1", "text2"],
model="my_model",
preference=preference
)
# Also works with async methods
response = await client.async_embed(
input=["text1", "text2"],
model="my_model",
preference=preference
)
Property-based Configuration: You can also modify preferences after creation using property setters:
# Create preference and modify properties
preference = RequestProcessingPreference()
preference.max_concurrent_requests = 64 # Set parallel requests
preference.batch_size = 32 # Set batch size
preference.timeout_s = 30.0 # Set timeout
preference.hedge_delay = 0.5 # Enable hedging
preference.hedge_budget_pct = 0.15 # Set hedge budget
preference.retry_budget_pct = 0.08 # Set retry budget
preference.max_retries = 3 # Set max retries
preference.initial_backoff_ms = 250 # Set backoff
# Use with any method
response = client.embed(
input=["text1", "text2"],
model="my_model",
preference=preference
)
Budget Percentages:
hedge_budget_pct: Percentage of total requests allocated for hedging (default: 10%)retry_budget_pct: Percentage of total requests allocated for retries (default: 5%)- Maximum allowed: 300% for both budgets
Retry Configuration:
max_retries: Maximum number of HTTP retries (default: 4, max: 4)initial_backoff_ms: Initial backoff duration in milliseconds (default: 125, range: 50-30000)- Backoff uses exponential backoff with jitter
Request Hedging
The client supports request hedging for improved latency by sending duplicate requests after a specified delay:
# Enable hedging with 0.5 second delay
preference = RequestProcessingPreference(
hedge_delay=0.5, # Send hedge request after 0.5s
max_chars_per_request=256000,
total_timeout_s=360
)
response = client.embed(
input=texts,
model="my_model",
preference=preference
)
Custom Headers
Use custom headers with batch_post:
preference = RequestProcessingPreference(
extra_headers={
"x-custom-header": "value",
"authorization": "Bearer token"
}
)
response = client.batch_post(
url_path="/v1/embeddings",
payloads=payloads,
preference=preference
)
HTTP Version Selection
Choose between HTTP/1.1 and HTTP/2:
# HTTP/1.1 (default, better for high concurrency)
client_http1 = PerformanceClient(base_url, api_key, http_version=1)
# HTTP/2 (better for single requests)
client_http2 = PerformanceClient(base_url, api_key, http_version=2)
Connection Pooling
Share connection pools across multiple clients:
from baseten_performance_client import HttpClientWrapper
# Create shared wrapper
wrapper = HttpClientWrapper(http_version=1)
# Reuse across multiple clients
client1 = PerformanceClient(base_url="https://api1.example.com", client_wrapper=wrapper)
client2 = PerformanceClient(base_url="https://api2.example.com", client_wrapper=wrapper)
HTTP Proxy Support
Route all HTTP requests through a proxy (e.g., for connection pooling with Envoy):
from baseten_performance_client import HttpClientWrapper
# Create wrapper with HTTP proxy
wrapper = HttpClientWrapper(
http_version=1,
proxy="http://envoy-proxy.local:8080"
)
# Share the wrapper across multiple clients
client1 = PerformanceClient(
base_url="https://api1.example.com",
api_key="your_key",
client_wrapper=wrapper
)
client2 = PerformanceClient(
base_url="https://api2.example.com",
api_key="your_key",
client_wrapper=wrapper
)
# Both clients will use the same connection pool and proxy
You can also specify the proxy directly when creating a client:
client = PerformanceClient(
base_url="https://api.example.com",
api_key="your_key",
proxy="http://envoy-proxy.local:8080"
)
Endpoint Pool and Health Checks
Route traffic across multiple deployments with deterministic weighted routing and a background health worker:
from baseten_performance_client import EndpointPool, HttpClientWrapper, PerformanceClient
health_wrapper = HttpClientWrapper(http_version=1)
endpoint_pool = EndpointPool(
endpoint_urls=[
"https://model-AAAA.api.baseten.co/environments/production/sync",
"https://model-BBBB.api.baseten.co/environments/production/sync",
],
client_wrapper=health_wrapper,
endpoint_weights=[0.8, 0.2], # deterministic weighted routing
deployment_health_path="/health",
deployment_timeout_is_no_vote=False,
)
client = PerformanceClient(
base_url="https://model-AAAA.api.baseten.co/environments/production/sync",
api_key="your_key",
endpoint_pool=endpoint_pool,
)
Health semantics:
- Weights are deterministic weighted routing, not weighted round robin.
- Each configured health check is retried up to
health_check_retries, and one successful retry is enough for that check. - If
deep_health_urlsare configured, both the shallow deployment health path and the deep health URL are evaluated. health_fail_on_first=Trueshort-circuits on the first hard failing check within an endpoint refresh cycle.- Endpoint eviction is stabilized across refresh cycles, so a single transient bad sample does not immediately move all traffic away from an otherwise healthy deployment.
Error Handling
The client can raise several types of errors. Here's how to handle common ones:
requests.exceptions.HTTPError: This error is raised for HTTP issues, such as authentication failures (e.g., 403 Forbidden if the API key is wrong), server errors (e.g., 5xx), or if the endpoint is not found (404). You can inspecte.response.status_codeande.response.text(ore.response.json()if the body is JSON) for more details.ValueError: This error can occur due to invalid input parameters (e.g., an emptyinputlist forembed, invalidbatch_sizeormax_concurrent_requestsvalues). It can also be raised byresponse.numpy()if embeddings are not float vectors or have inconsistent dimensions.
Here's an example demonstrating how to catch these errors for the embed method:
import requests
from baseten_performance_client import RequestProcessingPreference
# client = PerformanceClient(base_url="your_baseten_url", api_key="your_baseten_api_key")
texts_to_embed = ["Hello world", "Another text example"]
try:
preference = RequestProcessingPreference(
batch_size=2,
max_concurrent_requests=4,
timeout_s=60 # Timeout in seconds
)
response = client.embed(
input=texts_to_embed,
model="your_embedding_model", # Replace with your actual model name
preference=preference
)
# Process successful response
print(f"Model used: {response.model}")
print(f"Total tokens: {response.usage.total_tokens}")
for item in response.data:
embedding_preview = item.embedding[:3] if isinstance(item.embedding, list) else "Base64 Data"
print(f"Index {item.index}, Embedding (first 3 dims or type): {embedding_preview}")
except requests.exceptions.HTTPError as e:
print(f"An HTTP error occurred: {e}, code {e.args[0]}")
For asynchronous methods (async_embed, async_rerank, async_classify, async_batch_post), the same exceptions will be raised by the await call and can be caught using a try...except block within an async def function.
Development
# Install prerequisites
sudo apt-get install patchelf
# Install cargo if not already installed.
# Set up a Python virtual environment
python -m venv .venv
source .venv/bin/activate
# Install development dependencies
pip install maturin[patchelf] pytest requests numpy
# Build and install the Rust extension in development mode
maturin develop
cargo fmt
# Run tests
pytest tests
Contributions
Feel free to contribute to this repo, tag @michaelfeil for review.
License
MIT License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file baseten_performance_client-0.1.6rc0.tar.gz.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0.tar.gz
- Upload date:
- Size: 104.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
92234cd87fa9757254826fb14a8a8e349e62acb8ada520173feb48c46b0fd405
|
|
| MD5 |
2c47bd488e7ea6cffb75d593b27ad167
|
|
| BLAKE2b-256 |
8b41f68c4cdfdf110c106fd7f87b7b8f36b90aac8af7f6d089503fb6ce2e83f3
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp313-cp313t-musllinux_1_2_x86_64.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp313-cp313t-musllinux_1_2_x86_64.whl
- Upload date:
- Size: 5.8 MB
- Tags: CPython 3.13t, musllinux: musl 1.2+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
704a75da8b1b4f8dc71ef0ae8b1d4562eea9cdcd37832ef4bf6449e553c881ff
|
|
| MD5 |
b24a92112e23be800c56ae20650e2ad7
|
|
| BLAKE2b-256 |
9a3a0fde66c2229895ff1faed9b0f172481b7ddc72eca2f6364ee55d3ff63d6a
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp313-cp313t-musllinux_1_2_i686.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp313-cp313t-musllinux_1_2_i686.whl
- Upload date:
- Size: 5.7 MB
- Tags: CPython 3.13t, musllinux: musl 1.2+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ed69309918c2f0e96f1603269c893acb910853029dac498845dcc5411299a895
|
|
| MD5 |
e0c161bf88b9946c1dd844dea9ec5806
|
|
| BLAKE2b-256 |
3191d0e6a3523c79a1cb07e95ec42c573d5bb1c115336a9af3fdcde47870f440
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp313-cp313t-musllinux_1_2_armv7l.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp313-cp313t-musllinux_1_2_armv7l.whl
- Upload date:
- Size: 5.2 MB
- Tags: CPython 3.13t, musllinux: musl 1.2+ ARMv7l
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
28a0c059676732cb6b68db304371308c592ca9609a46f5df99036ef096ac3422
|
|
| MD5 |
c1d0ed83e23a7acc0c9d27bfbb74983a
|
|
| BLAKE2b-256 |
9d41a91b96b1b1384c2005f2d80c61069982f7fb6ea2e053b714fdb79e6793b3
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp313-cp313t-musllinux_1_2_aarch64.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp313-cp313t-musllinux_1_2_aarch64.whl
- Upload date:
- Size: 6.2 MB
- Tags: CPython 3.13t, musllinux: musl 1.2+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cb6d82d08d751574950e075e97a9f0ad5b9c05649b877d8a623a2024f005bc65
|
|
| MD5 |
94e23b251ae03fe4caeaa6e1d79b62fe
|
|
| BLAKE2b-256 |
c3045b163cd23a3d90604f2e719f355d78a0895bcf44639e8ca7d8c99c588a45
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp313-cp313t-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp313-cp313t-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 5.6 MB
- Tags: CPython 3.13t, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
84576b27ab9229c2ce9ff470fe8dd973c5e19dd82822c2bd4a9d67847f7c3a82
|
|
| MD5 |
f74c0b45f2cf9713f5e5e738bf5a3e9c
|
|
| BLAKE2b-256 |
92dca641a1a791d97d93e091656866fac3897c02546a0f7cf422870e3eb4226c
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp313-cp313t-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp313-cp313t-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl
- Upload date:
- Size: 5.9 MB
- Tags: CPython 3.13t, manylinux: glibc 2.17+ ppc64le
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b17fab46e05721fcc7ff1ffd8ea537c1ce7fba20eeb21409d34b9d81e7bf1de3
|
|
| MD5 |
0e9de84262fe4e2a77646988435f4846
|
|
| BLAKE2b-256 |
b28fdc12dd521fdaad3de631d5ed9dd0cb404776456133f04ec919477fdf84f1
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp313-cp313t-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp313-cp313t-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 5.7 MB
- Tags: CPython 3.13t, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f4a138df2a4d010430e4d0887866ee80158487f8ccacda8f0a80754ac0e42e75
|
|
| MD5 |
92f3eb24f2ea33bccb68120d8142ee7b
|
|
| BLAKE2b-256 |
00eb62716a9163b45e55129240fad586159b73cd5131eefb149cd7974cd2e136
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp313-cp313t-macosx_11_0_arm64.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp313-cp313t-macosx_11_0_arm64.whl
- Upload date:
- Size: 3.2 MB
- Tags: CPython 3.13t, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2e3ba0fe920b776a19b78f6f4be4aa48d5e3170ff1614056d047b519984ae005
|
|
| MD5 |
83f7dd098371a2d976b32b6a722c5993
|
|
| BLAKE2b-256 |
92a77f98d8221ca0b36bbb99b512a483d7617abbc4238df076ea6999b2896ae9
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp313-cp313t-macosx_10_12_x86_64.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp313-cp313t-macosx_10_12_x86_64.whl
- Upload date:
- Size: 3.3 MB
- Tags: CPython 3.13t, macOS 10.12+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fbfe95df43ccddd4b62f590b64e69e0bde08d1bcd70db43fe2a7b9a35b2ff024
|
|
| MD5 |
5b7ee62305d7fcc84672c92ab0ae3a00
|
|
| BLAKE2b-256 |
15fc385dbe3e79b769f6bed3f73d7562abf0b47605afb12cd1cfc51d68025542
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp38-abi3-win_amd64.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp38-abi3-win_amd64.whl
- Upload date:
- Size: 3.0 MB
- Tags: CPython 3.8+, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9218939cdd0011776e94d0dbbfafc5e25b1a46b479b51d32e2af460ae8f3b2a1
|
|
| MD5 |
606ef74d3ab0bbf719d309ed5317be00
|
|
| BLAKE2b-256 |
1108cb96668df40714834fd1abdb3c316c26119cb6efc5a94128c9b29df77e0c
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp38-abi3-musllinux_1_2_x86_64.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp38-abi3-musllinux_1_2_x86_64.whl
- Upload date:
- Size: 5.9 MB
- Tags: CPython 3.8+, musllinux: musl 1.2+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3dbf16e441a49e660ce898b7a76bb6fe2a74e2b840ff2018374c2912e16ac9f0
|
|
| MD5 |
3f0893af4e8022c3ca58a10c3efd6fc1
|
|
| BLAKE2b-256 |
fa558087ea7c2e33beb744794e1ce438ecbcabbdec9bf3bdf545b42bae90967d
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp38-abi3-musllinux_1_2_i686.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp38-abi3-musllinux_1_2_i686.whl
- Upload date:
- Size: 5.7 MB
- Tags: CPython 3.8+, musllinux: musl 1.2+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c948f82d690d9fa3f2415180723be9c2e229b66f76cacf4dce90967cdfc7db8d
|
|
| MD5 |
d38f274eda1ea570350470cdcd270325
|
|
| BLAKE2b-256 |
7d627162f972ced0d92f12dd7c4fad4b7f5bff592bf5f76d557ebd9949cb8c6e
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp38-abi3-musllinux_1_2_armv7l.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp38-abi3-musllinux_1_2_armv7l.whl
- Upload date:
- Size: 5.2 MB
- Tags: CPython 3.8+, musllinux: musl 1.2+ ARMv7l
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bc8ff767c52a9daecc0dc0eeed51abe7a63a18a92d1e0998a508f5a5ba84a01c
|
|
| MD5 |
0f36a2075ae895f264f4bc696df1a6f5
|
|
| BLAKE2b-256 |
97fc4a1d9e38cdf0dd8ecf7871f8e43dc9dab11885f84183ad3d45f8fbe4aa15
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp38-abi3-musllinux_1_2_aarch64.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp38-abi3-musllinux_1_2_aarch64.whl
- Upload date:
- Size: 6.2 MB
- Tags: CPython 3.8+, musllinux: musl 1.2+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a504aab3902a9341bd7487cb73e0e7a1f89b9b2c4746d9f3f44d4bb8b9108a67
|
|
| MD5 |
ae82d4ba09787568ac21ac50cb49a540
|
|
| BLAKE2b-256 |
ac68c22cce1d6c76a654b5dd26c190d0aed24a1362778bed888f086dc9e88556
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp38-abi3-manylinux_2_28_armv7l.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp38-abi3-manylinux_2_28_armv7l.whl
- Upload date:
- Size: 5.0 MB
- Tags: CPython 3.8+, manylinux: glibc 2.28+ ARMv7l
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6c52fe1c1575b3951d9a9956649fe66411ee16d54d56e97f91d6d8fbd6af864b
|
|
| MD5 |
af1b7b40e3ffe5db56f9ee2a9010562d
|
|
| BLAKE2b-256 |
8dd8f2aa1fc4a892b1feda7c1b6f6ee3e8d943ad2e2d4111f311dc78a7e2b9c4
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp38-abi3-manylinux_2_28_aarch64.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp38-abi3-manylinux_2_28_aarch64.whl
- Upload date:
- Size: 5.8 MB
- Tags: CPython 3.8+, manylinux: glibc 2.28+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a87b76e2ad2c4fa8fb454fbf161df08d78bff23014263a7ba2762d7a26f02f28
|
|
| MD5 |
11c166ea34c0828b8d87859c24982924
|
|
| BLAKE2b-256 |
a89da813f58f4dbe0ca4518c8ec0a09f925184b3a6e801d4ec3b37747f8ef114
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp38-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp38-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 5.6 MB
- Tags: CPython 3.8+, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d1e14e3a28cde58c14c846af43ac07d82da2bc4b3d8db8ab0c32408df42bf477
|
|
| MD5 |
7373c222576187a8513bd09779fd207b
|
|
| BLAKE2b-256 |
80fa129033ce2e62e17bbb1e33ec703decf1e30c958be8013bc716ba4084f93b
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp38-abi3-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp38-abi3-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl
- Upload date:
- Size: 5.9 MB
- Tags: CPython 3.8+, manylinux: glibc 2.17+ ppc64le
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e0f8de3261129b3f0c72e6c1d4deb564f54986d0c4bd2c24efe5914582ea7060
|
|
| MD5 |
18667fe86047c14ec2ff2455ed8501b9
|
|
| BLAKE2b-256 |
f36c7b7f092dc35f8966c7358e6598de24864fd9d57f6a67027b87d0487815ca
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp38-abi3-manylinux_2_17_i686.manylinux2014_i686.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp38-abi3-manylinux_2_17_i686.manylinux2014_i686.whl
- Upload date:
- Size: 5.7 MB
- Tags: CPython 3.8+, manylinux: glibc 2.17+ i686
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4afec49892a1c40a2ab922e2ee41899a0469ee13657dfbf7b7faa5fb4766c97d
|
|
| MD5 |
594da5ad5cbacc8f05aa9c912cfcd8ef
|
|
| BLAKE2b-256 |
3796c7760fecbde02e39d7f3a45911e9249bae8b792babaae5e7b38d28021c92
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp38-abi3-macosx_11_0_arm64.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp38-abi3-macosx_11_0_arm64.whl
- Upload date:
- Size: 3.2 MB
- Tags: CPython 3.8+, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4265b5a559429c71de593b815c953754db90f133be1c0c49eb379b6e9ebf8339
|
|
| MD5 |
4e79a2584af8f1da6ce0aeb932b44deb
|
|
| BLAKE2b-256 |
132ddd9ff5362121db5a5c66bead16990af60c13bb1268a0e5468c912fac73cf
|
File details
Details for the file baseten_performance_client-0.1.6rc0-cp38-abi3-macosx_10_12_x86_64.whl.
File metadata
- Download URL: baseten_performance_client-0.1.6rc0-cp38-abi3-macosx_10_12_x86_64.whl
- Upload date:
- Size: 3.3 MB
- Tags: CPython 3.8+, macOS 10.12+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dcacddd465238e16ba5b6301e526abd53e70fac5e983c76e6c10543083fb2c87
|
|
| MD5 |
b7e6e4408408d5623056d08dc56e9921
|
|
| BLAKE2b-256 |
a964a343cfb31b479f2c3d02cab7700dc0da6f48d6403b2a090a5aa52b48cf87
|







