No project description provided

Project description



Python Stateful Stream Processing Framework
Bytewax is a Python framework that simplifies event and stream processing. Because Bytewax couples the stream and event processing capabilities of Flink, Spark, and Kafka Streams with the friendly and familiar interface of Python, you can re-use the Python libraries you already know and love. Connect data sources, run stateful transformations and write to various different downstream systems with built-in connectors or existing Python libraries.
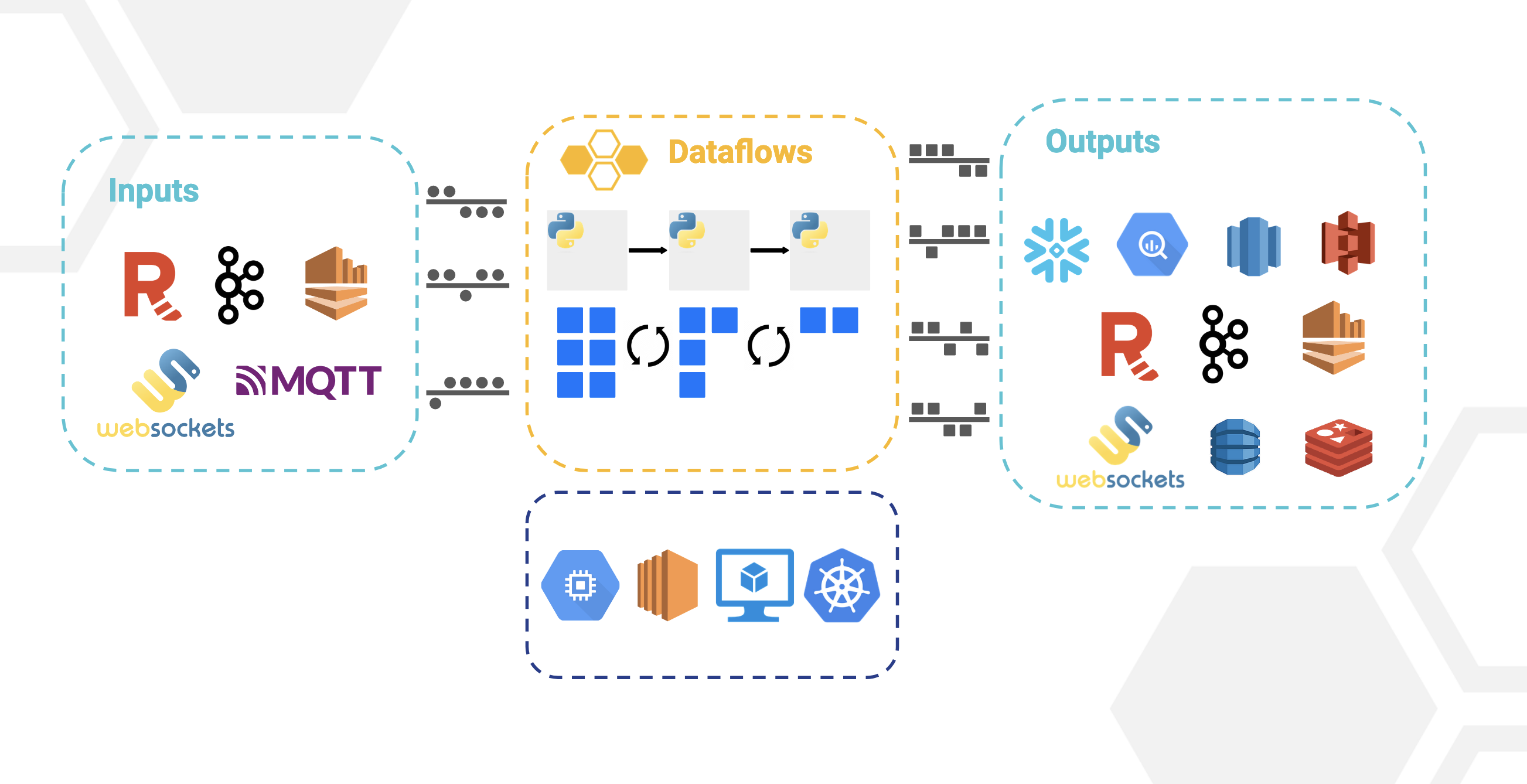
How it all works
Bytewax is a Python framework and Rust distributed processing engine that uses a dataflow computational model to provide parallelizable stream processing and event processing capabilities similar to Flink, Spark, and Kafka Streams. You can use Bytewax for a variety of workloads from moving data à la Kafka Connect style all the way to advanced online machine learning workloads. Bytewax is not limited to streaming applications but excels anywhere that data can be distributed at the input and output.
Bytewax has an accompanying command line interface, waxctl, which supports the deployment of dataflows on cloud vms or kuberentes. You can download it here.
Getting Started with Bytewax
pip install bytewax
A Bytewax dataflow is Python code that will represent an input, a series of processing steps, and an output. The inputs could range from a Kafka stream to a WebSocket and the outputs could vary from a data lake to a key-value store.
from bytewax.dataflow import Dataflow
from bytewax.inputs import KafkaInputConfig
from bytewax.outputs import ManualOutputConfig
# Bytewax has input and output helpers for common input and output data sources
# but you can also create your own with the ManualOutputConfig.
At a high-level, the dataflow compute model is one in which a program execution is conceptualized as data flowing through a series of operator-based steps. Operators like map and filter are the processing primitives of Bytewax. Each of them gives you a “shape” of data transformation, and you give them regular Python functions to customize them to a specific task you need. See the documentation for a list of the available operators
import json
def deserialize(key_bytes__payload_bytes):
key_bytes, payload_bytes = key_bytes__payload_bytes
key = json.loads(key_bytes) if key_bytes else None
event_data = json.loads(payload_bytes) if payload_bytes else None
return event_data["user_id"], event_data
def anonymize_email(user_id__event_data):
user_id, event_data = user_id__event_data
event_data["email"] = "@".join(["******", event_data["email"].split("@")[-1]])
return user_id, event_data
def remove_bytewax(user_id__event_data):
user_id, event_data = user_id__event_data
return "bytewax" not in event_data["email"]
flow = Dataflow()
flow.input("inp", KafkaInputConfig(brokers=["localhost:9092"], topic="web_events"))
flow.map(deserialize)
flow.map(anonymize_email)
flow.filter(remove_bytewax)
Bytewax is a stateful stream processing framework, which means that some operations remember information across multiple events. Windows and aggregations are also stateful, and can be reconstructed in the event of failure. Bytewax can be configured with different state recovery mechanisms to durably persist state in order to recover from failure.
There are multiple stateful operators available like reduce, stateful_map and fold_window. The complete list can be found in the API documentation for all operators. Below we use the fold_window operator with a tumbling window based on system time to gather events and calculate the number of times events have occurred on a per-user basis.
import datetime
from collections import defaultdict
from bytewax.window import TumblingWindowConfig, SystemClockConfig
cc = SystemClockConfig()
wc = TumblingWindowConfig(length=datetime.timedelta(seconds=5))
def build():
return defaultdict(lambda: 0)
def count_events(results, event):
results[event["type"]] += 1
return results
flow.fold_window("session_state_recovery", cc, wc, build, count_events)
Output mechanisms in Bytewax are managed in the capture operator. There are a number of helpers that allow you to easily connect and write to other systems (output docs). If there isn’t a helper built, it is easy to build a custom version, which we will do below. Similar the input, Bytewax output can be parallelized and the client connection will occur on the worker.
import json
import psycopg2
def output_builder(worker_index, worker_count):
# create the connection at the worker level
conn = psycopg2.connect("dbname=website user=bytewax")
conn.set_session(autocommit=True)
cur = conn.cursor()
def write_to_postgres(user_id__user_data):
user_id, user_data = user_id__user_data
query_string = '''
INSERT INTO events (user_id, data)
VALUES (%s, %s)
ON CONFLICT (user_id)
DO
UPDATE SET data = %s;'''
cur.execute(query_string, (user_id, json.dumps(user_data), json.dumps(user_data)))
return write_to_postgres
flow.capture(ManualOutputConfig(output_builder))
Bytewax dataflows can be executed on a single host with multiple Python processes, or on multiple hosts. Below is an example of running bytewax across multiple hosts. When processing data in a distributed fashion, Bytewax will ensure that all items with the same key are routed to the same host.
if __name__ == "__main__":
addresses = [
"localhost:2101"
]
cluster_main(
flow,
addresses=addresses,
proc_id=0,
worker_count_per_proc=2)
Deploying and Scaling
Bytewax can be run on a local machine or remote machine, just like a regular Python script.
python my_dataflow.py
It can also be run in a Docker container as described further in the documentation.
Kubernetes
The recommended way to run dataflows at scale is to leverage the kubernetes ecosystem. To help manage deployment, we built waxctl, which allows you to easily deploy dataflows that will run at huge scale across multiple compute nodes.
waxctl df deploy my_dataflow.py --name my-dataflow
Why Bytewax?
At a high level, Bytewax provides a few major benefits:
- The operators in Bytewax are largely “data-parallel”, meaning they can operate on independent parts of the data concurrently.
- Bytewax offers the ability to express higher-level control constructs, like iteration.
- Bytewax allows you to develop and run your code locally, and then easily scale that code to multiple workers or processes without changes.
- Bytewax can be used in both a streaming and batch context
- Ability to leverage the Python ecosystem directly
Community
Slack Is the main forum for communication and discussion.
GitHub Issues is reserved only for actual issues. Please use the slack community for discussions.
Usage
Install the latest release with pip:
pip install bytewax
Building From Source
To build a specific branch, you will need to use Maturin and have Rust installed on your machine. Once those have been installed run
maturin develop -E dev
Important: If you are testing with a maturin built version from source, you should use maturin build --release since maturin develop will be slower.
More Examples
For a more complete example, and documentation on the available operators, check out the User Guide and the Examples
For an exhaustive list of examples, checkout the /examples folder
License
Bytewax is licensed under the Apache-2.0 license.
Contributing
Contributions are welcome! This community and project would not be what it is without the contributors. All contributions, from bug reports to new features, are welcome and encouraged. Please view the contribution guidelines before getting started.
With ❤️ Bytewax


Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file bytewax-0.12.0-cp310-cp310-manylinux_2_31_x86_64.whl.
File metadata
- Download URL: bytewax-0.12.0-cp310-cp310-manylinux_2_31_x86_64.whl
- Upload date:
- Size: 6.6 MB
- Tags: CPython 3.10, manylinux: glibc 2.31+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
15ccdfceea3e78a00bb5b2f67dbd3394ecf78c3fd066a94af2abe4e885be9b4a
|
|
| MD5 |
559315786b0918968c9100009fd6ea84
|
|
| BLAKE2b-256 |
92a91f3e8ed404694e56ad10d40da25a6e36c72cf9018bbc93eeb92c5bd7acb5
|
File details
Details for the file bytewax-0.12.0-cp310-cp310-macosx_11_0_arm64.whl.
File metadata
- Download URL: bytewax-0.12.0-cp310-cp310-macosx_11_0_arm64.whl
- Upload date:
- Size: 4.7 MB
- Tags: CPython 3.10, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f505f68fb0e99c24dd33bf6f8cd0256889914d83e519f693c6d3b2ec6bcab6e5
|
|
| MD5 |
5f3b9b75283addeda858182245a50540
|
|
| BLAKE2b-256 |
cc058fc265caab176b371d9f9f005457c47b3529840fc33d62af39e9211860cf
|
File details
Details for the file bytewax-0.12.0-cp310-cp310-macosx_10_7_x86_64.whl.
File metadata
- Download URL: bytewax-0.12.0-cp310-cp310-macosx_10_7_x86_64.whl
- Upload date:
- Size: 5.1 MB
- Tags: CPython 3.10, macOS 10.7+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
808bf9f8deed343a505637e6696fd94722067532e1fba901e24a8750e47d56d1
|
|
| MD5 |
1deafb67daf9c164a6cc0de6bdafc447
|
|
| BLAKE2b-256 |
d2c6a4a35836c80a7991a0029c39f0018e96c8f47fff00d2efd872674d3d0fc2
|
File details
Details for the file bytewax-0.12.0-cp39-cp39-manylinux_2_31_x86_64.whl.
File metadata
- Download URL: bytewax-0.12.0-cp39-cp39-manylinux_2_31_x86_64.whl
- Upload date:
- Size: 6.6 MB
- Tags: CPython 3.9, manylinux: glibc 2.31+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a6b434684ed54317608aaaaf50e30d3a232fa7707e4367fddcc00bfea064136a
|
|
| MD5 |
a65a0b85eaa8acacebcebf8f52a98f38
|
|
| BLAKE2b-256 |
6f14c90e9bc9be4a69408532ad12a010206038cd92870851724b255bf47ecde3
|
File details
Details for the file bytewax-0.12.0-cp39-cp39-macosx_11_0_arm64.whl.
File metadata
- Download URL: bytewax-0.12.0-cp39-cp39-macosx_11_0_arm64.whl
- Upload date:
- Size: 4.7 MB
- Tags: CPython 3.9, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6ff7b37c8c0a65901059c078cd0bc78ff78b57616198b36052b5080b68110e65
|
|
| MD5 |
e44928f33e3244743fe5a231e364f820
|
|
| BLAKE2b-256 |
5df8c68ad3f06693c29da13b0beba1b2ac8317177837ef289184e910047b989c
|
File details
Details for the file bytewax-0.12.0-cp39-cp39-macosx_10_7_x86_64.whl.
File metadata
- Download URL: bytewax-0.12.0-cp39-cp39-macosx_10_7_x86_64.whl
- Upload date:
- Size: 5.1 MB
- Tags: CPython 3.9, macOS 10.7+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
040a69c81cd819e4d420c945bd60e4d294c0a95a6809af9ff6098c0ed2094394
|
|
| MD5 |
60cded9d8bc96238ea2e41b6ef3b48d7
|
|
| BLAKE2b-256 |
6035a8872c6a187b9fb2bc68d6fa9a4d07d0dcd775c65b956db56b2bb0d06adb
|
File details
Details for the file bytewax-0.12.0-cp38-cp38-manylinux_2_31_x86_64.whl.
File metadata
- Download URL: bytewax-0.12.0-cp38-cp38-manylinux_2_31_x86_64.whl
- Upload date:
- Size: 6.6 MB
- Tags: CPython 3.8, manylinux: glibc 2.31+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
570a0df69cff8e41bdb80d41410193e8572be19027981d2724aeefd7fa96d921
|
|
| MD5 |
24178b34ed0330d392571d3c8cb82b2c
|
|
| BLAKE2b-256 |
82b651a169ec23c55e2e6f798dcd84f9e82e9f12d567b3a4a8e346ec225ac7b5
|
File details
Details for the file bytewax-0.12.0-cp38-cp38-macosx_11_0_arm64.whl.
File metadata
- Download URL: bytewax-0.12.0-cp38-cp38-macosx_11_0_arm64.whl
- Upload date:
- Size: 4.7 MB
- Tags: CPython 3.8, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
60b96341e0c6873ea5d8ad1efca79f210b82e817c253866b5c05bf7904e9b813
|
|
| MD5 |
a733e220bba88899036feb87fcb9ff1b
|
|
| BLAKE2b-256 |
2d138a5857e23749ceb734edf1f30b3bde3df259c45e8da29ed9a94cddeaec5f
|
File details
Details for the file bytewax-0.12.0-cp38-cp38-macosx_10_7_x86_64.whl.
File metadata
- Download URL: bytewax-0.12.0-cp38-cp38-macosx_10_7_x86_64.whl
- Upload date:
- Size: 5.1 MB
- Tags: CPython 3.8, macOS 10.7+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ae01d3473c0b0105a3c6ab3d5d39df813b9ff8f184fa399111386630cf3f7b0f
|
|
| MD5 |
5473d96ac47767702b4a36b52ee0dc37
|
|
| BLAKE2b-256 |
d044ade801e637115ca9b5610b3fdb1f12f565927e05380feb4b003ce1c860e1
|
File details
Details for the file bytewax-0.12.0-cp37-cp37m-manylinux_2_31_x86_64.whl.
File metadata
- Download URL: bytewax-0.12.0-cp37-cp37m-manylinux_2_31_x86_64.whl
- Upload date:
- Size: 6.6 MB
- Tags: CPython 3.7m, manylinux: glibc 2.31+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
76c8463696a6995b6fb4b647a85b6eab2e875a00f1c893f7ac672753070b023b
|
|
| MD5 |
aa36c201621c4de85f9377dd4ba32010
|
|
| BLAKE2b-256 |
e5a81509211b2f8910d77a78db472c3e2e0bd6c1c439b81218c468054fb0ecaa
|
File details
Details for the file bytewax-0.12.0-cp37-cp37m-macosx_11_0_arm64.whl.
File metadata
- Download URL: bytewax-0.12.0-cp37-cp37m-macosx_11_0_arm64.whl
- Upload date:
- Size: 4.7 MB
- Tags: CPython 3.7m, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6d609ed046e4371382a240d2b1748e857079da15505bbe225b8fd5d781517254
|
|
| MD5 |
0307e91eb52c1ee6c7aa3def782aab3c
|
|
| BLAKE2b-256 |
1434d91d99aa093299811eb3ba227f7b146b6648995333b41dd93aa53e5e19eb
|
File details
Details for the file bytewax-0.12.0-cp37-cp37m-macosx_10_7_x86_64.whl.
File metadata
- Download URL: bytewax-0.12.0-cp37-cp37m-macosx_10_7_x86_64.whl
- Upload date:
- Size: 5.1 MB
- Tags: CPython 3.7m, macOS 10.7+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
af9a4b169ace218d51b0375558690ae041b7884e62148050ec544b3b31328254
|
|
| MD5 |
bcd46062f210e361870cb0ce4ba70f41
|
|
| BLAKE2b-256 |
100f3906f08b96d2ecf05d6f15e0837542de59bb71bae1893ca8901428ff1fcb
|







