Analyze website anti-bot protections before you scrape

Project description
caniscrape 🔍
Know before you scrape. Analyze any website's anti-bot protections in seconds.
Stop wasting hours building scrapers only to discover the site has Cloudflare + JavaScript rendering + CAPTCHA + rate limiting. caniscrape does reconnaissance upfront so you know exactly what you're dealing with before writing a single line of code.
🎯 What It Does
caniscrape analyzes a URL and tells you:
- What protections are active (WAF, CAPTCHA, rate limits, TLS fingerprinting, honeypots)
- Difficulty score (0-10 scale: Easy → Very Hard)
- Specific recommendations on what tools/proxies you'll need
- Estimated complexity so you can decide: build it yourself or use a service
🚀 Quick Start
Installation
pip install caniscrape
Required dependency:
# Install wafw00f (WAF detection)
pipx install wafw00f
# Install Playwright browsers (for JS detection)
playwright install chromium
Basic Usage
caniscrape https://example.com
Example Output
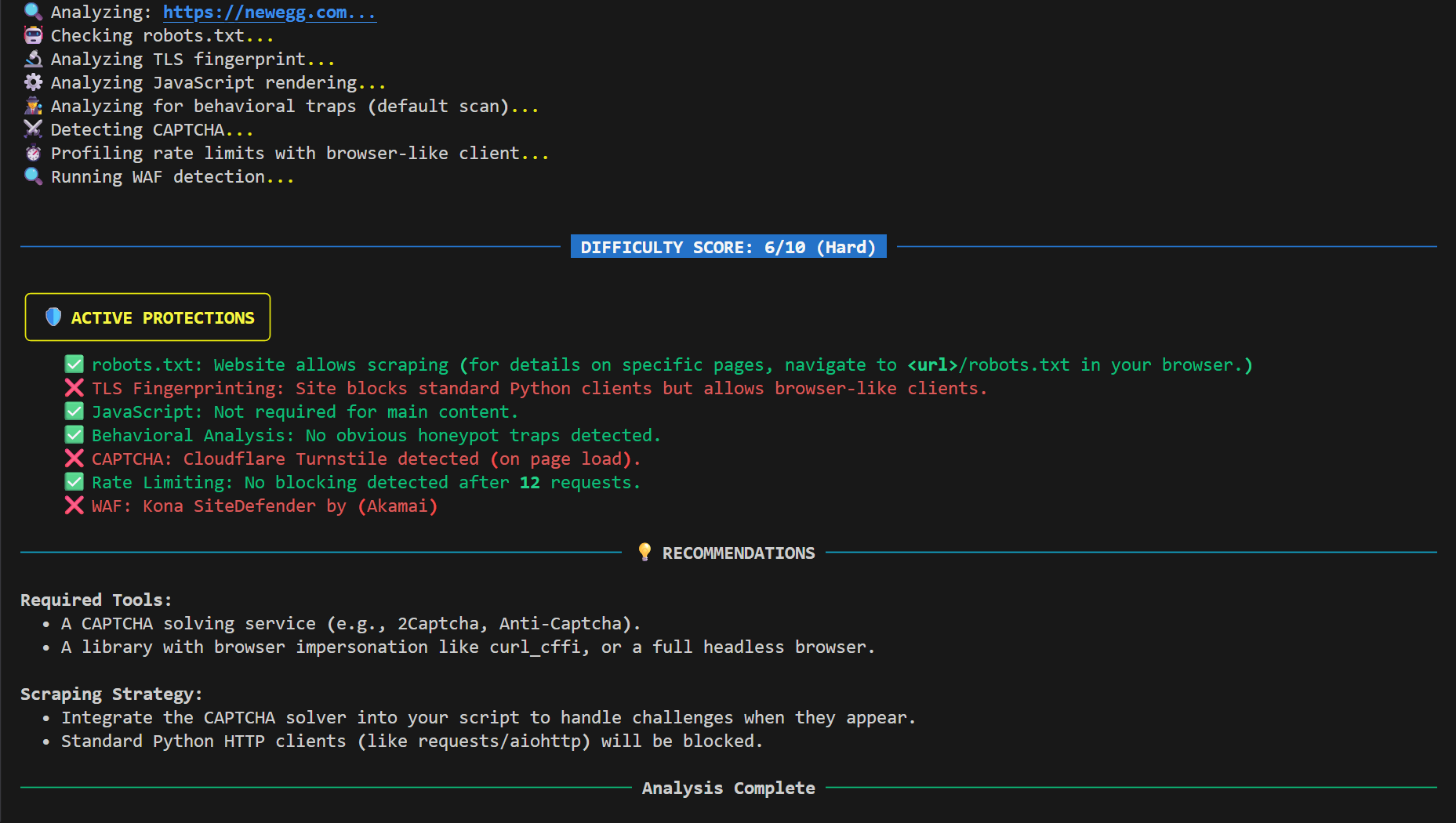
🔬 What It Analyzes
1. WAF Detection
Identifies Web Application Firewalls (Cloudflare, Akamai, Imperva, DataDome, PerimeterX, etc.)
2. Rate Limiting
- Tests with burst and sustained traffic patterns
- Detects HTTP 429s, timeouts, throttling, soft bans
- Determines blocking threshold (requests/min)
3. JavaScript Rendering
- Compares content with/without JS execution
- Detects SPAs (React, Vue, Angular)
- Calculates percentage of content missing without JS
4. CAPTCHA Detection
- Scans for reCAPTCHA, hCaptcha, Cloudflare Turnstile
- Tests if CAPTCHA appears on load or after rate limiting
- Monitors network traffic for challenge endpoints
5. TLS Fingerprinting
- Compares standard Python clients vs browser-like clients
- Detects if site blocks based on TLS handshake signatures
6. Behavioral Analysis
- Scans for invisible "honeypot" links (bot traps)
- Detects if site is monitoring mouse/scroll behavior
7. robots.txt
- Checks scraping permissions
- Extracts recommended crawl-delay
🛠️ Advanced Usage
Aggressive WAF Detection
# Find ALL WAFs (slower, may trigger rate limits)
caniscrape https://example.com --find-all
Browser Impersonation
# Use curl_cffi for better stealth (slower but more likely to succeed)
caniscrape https://example.com --impersonate
Deep Honeypot Scanning
# Check 2/3 of links (more accurate, slower)
caniscrape https://example.com --thorough
# Check ALL links (most accurate, very slow on large sites)
caniscrape https://example.com --deep
Combine Options
caniscrape https://example.com --impersonate --find-all --thorough
📊 Difficulty Scoring
The tool calculates a 0-10 difficulty score based on:
| Factor | Impact |
|---|---|
| CAPTCHA on page load | +5 points |
| CAPTCHA after rate limit | +4 points |
| DataDome/PerimeterX WAF | +4 points |
| Akamai/Imperva WAF | +3 points |
| Aggressive rate limiting | +3 points |
| Cloudflare WAF | +2 points |
| Honeypot traps detected | +2 points |
| TLS fingerprinting active | +1 point |
Score interpretation:
- 0-2: Easy (basic scraping will work)
- 3-4: Medium (need some precautions)
- 5-7: Hard (requires advanced techniques)
- 8-10: Very Hard (consider using a service)
🔧 Installation Details
System Requirements
- Python 3.9+
- pip or pipx
Full Installation
# 1. Install caniscrape
pip install caniscrape
# 2. Install wafw00f (WAF detection)
# Option A: Using pipx (recommended)
python -m pip install --user pipx
pipx install wafw00f
# Option B: Using pip
pip install wafw00f
# 3. Install Playwright browsers (for JS/CAPTCHA/behavioral detection)
playwright install chromium
Dependencies
Core dependencies (installed automatically):
click- CLI frameworkrich- Terminal formattingaiohttp- Async HTTP requestsbeautifulsoup4- HTML parsingplaywright- Headless browser automationcurl_cffi- Browser impersonation
External tools (install separately):
wafw00f- WAF detection
🎓 Use Cases
For Developers
- Before building a scraper: Check if it's even feasible
- Debugging scraper issues: Identify what protection broke your scraper
- Client estimates: Give accurate time/cost estimates for scraping projects
For Data Engineers
- Pipeline planning: Know what infrastructure you'll need (proxies, CAPTCHA solvers)
- Cost estimation: Calculate proxy/CAPTCHA costs before committing to a data source
For Researchers
- Site selection: Find the easiest data sources for your research
- Compliance: Check robots.txt before scraping
⚠️ Limitations & Disclaimers
What It Can't Detect
- Dynamic protections: Some sites only trigger defenses under specific conditions
- Behavioral AI: Advanced ML-based bot detection that adapts in real-time
- Account-based restrictions: Protections that only activate for logged-in users
Legal & Ethical Notes
- This tool is for reconnaissance only - it does not bypass protections
- Always respect
robots.txtand terms of service - Some sites may consider aggressive scanning hostile - use
--find-alland--deepsparingly - You are responsible for how you use this tool and any scrapers you build
Technical Notes
- Analysis takes 30-60 seconds per URL
- Some checks require making multiple requests (may trigger rate limits)
- Results are a snapshot - protections can change over time
🤝 Contributing
Found a bug? Have a feature request? Contributions are welcome!
- Fork the repo
- Create a feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'Add amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request
📝 License
MIT License - see LICENSE file for details
🙏 Acknowledgments
Built on top of:
- wafw00f - WAF detection
- Playwright - Browser automation
- curl_cffi - Browser impersonation
📬 Contact
Questions? Feedback? Open an issue on GitHub.
Remember: This tool tells you HOW HARD it will be to scrape. It doesn't do the scraping for you. Use it to make informed decisions before you start building.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file caniscrape-0.1.4.tar.gz.
File metadata
- Download URL: caniscrape-0.1.4.tar.gz
- Upload date:
- Size: 19.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
14296e086fcca05ad54830247b748e43085d79cca53e4e12dc9f9043b127a0c9
|
|
| MD5 |
e3fed704cc60be3d6485a3c6445e819d
|
|
| BLAKE2b-256 |
defeaeba48740ff63f6926c2affb38b69b5c364b933f011c5e4592f5198d0751
|
File details
Details for the file caniscrape-0.1.4-py3-none-any.whl.
File metadata
- Download URL: caniscrape-0.1.4-py3-none-any.whl
- Upload date:
- Size: 21.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c0a262554314e81afab72ec00519256fb0b14fda3b8284920a05f4ed18581f47
|
|
| MD5 |
3a165bb16407a89fd3ff4d9cb5b77750
|
|
| BLAKE2b-256 |
9d2eb40de19a63153e7dc15d9c0d0091bb2472c02fac755b05ec0f13a413478c
|







