An AI ensemble model for predicting chemical classes


Project description
python-chebifier
An AI ensemble model for predicting chemical classes in the ChEBI ontology. It integrates deep learning models, rule-based models and generative AI-based models.
A web application for the ensemble is available at https://chebifier.hastingslab.org/.
Installation
You can get the package from PyPI:
pip install chebifier
or get the latest development version from GitHub:
# Clone the repository
git clone https://github.com/yourusername/python-chebifier.git
cd python-chebifier
# Install the package
pip install -e .
chebai-graph and its dependencies cannot be installed automatically. If you want to use Graph Neural Networks, follow
the instructions in the chebai-graph repository.
Usage
Command Line Interface
The package provides a command-line interface (CLI) for making predictions using an ensemble model.
The ensemble configuration is given by a configuration file (by default, this is chebifier/ensemble.yml). If you
want to change which models are included in the ensemble or how they are weighted, you can create your own configuration file.
Model weights for deep learning models are downloaded automatically from Hugging Face.
However, you can also supply your own model checkpoints (see configs/example_config.yml for an example).
# Make predictions
python -m chebifier predict --smiles "CC(=O)OC1=CC=CC=C1C(=O)O" --smiles "C1=CC=C(C=C1)C(=O)O"
# Make predictions using SMILES from a file
python -m chebifier predict --smiles-file smiles.txt
# Make predictions using a configuration file
python -m chebifier predict --ensemble-config configs/my_config.yml --smiles-file smiles.txt
# Get all available options
python -m chebifier predict --help
Python API
You can also use the package programmatically:
from chebifier.ensemble.base_ensemble import BaseEnsemble
import yaml
# Load configuration from YAML file
with open('configs/example_config.yml', 'r') as f:
config = yaml.safe_load(f)
# Instantiate ensemble model
ensemble = BaseEnsemble(config)
# Make predictions
smiles_list = ["CC(=O)OC1=CC=CC=C1C(=O)O", "C1=CC=C(C=C1)C(=O)O"]
predictions = ensemble.predict_smiles_list(smiles_list)
# Print results
for smiles, prediction in zip(smiles_list, predictions):
print(f"SMILES: {smiles}")
if prediction:
print(f"Predicted classes: {prediction}")
else:
print("No predictions")
The models
Currently, the following models are supported:
| Model | Description | #Classes | Publication | Repository |
|---|---|---|---|---|
electra |
A transformer-based deep learning model trained on ChEBI SMILES strings. | 1522 | Glauer, Martin, et al., 2024: Chebifier: Automating semantic classification in ChEBI to accelerate data-driven discovery, Digital Discovery 3 (2024) 896-907 | python-chebai |
resgated |
A Residual Gated Graph Convolutional Network trained on ChEBI molecules. | 1522 | python-chebai-graph | |
chemlog_peptides |
A rule-based model specialised on peptide classes. | 18 | Flügel, Simon, et al., 2025: ChemLog: Making MSOL Viable for Ontological Classification and Learning, arXiv | chemlog-peptides |
chemlog_element, chemlog_organox |
Extensions of ChemLog for classes that are defined either by the presence of a specific element or by the presence of an organic bond. | 118 + 37 | chemlog-extra | |
c3p |
A collection Chemical Classifier Programs, generated by LLMs based on the natural language definitions of ChEBI classes. | 338 | Mungall, Christopher J., et al., 2025: Chemical classification program synthesis using generative artificial intelligence, arXiv | c3p |
In addition, Chebifier also includes a ChEBI lookup that automatically retrieves the ChEBI superclasses for a class matched by a SMILES string. This is not activated by default, but can be included by adding
chebi_lookup:
type: chebi_lookup
model_weight: 10 # optional
to your configuration file.
The ensemble
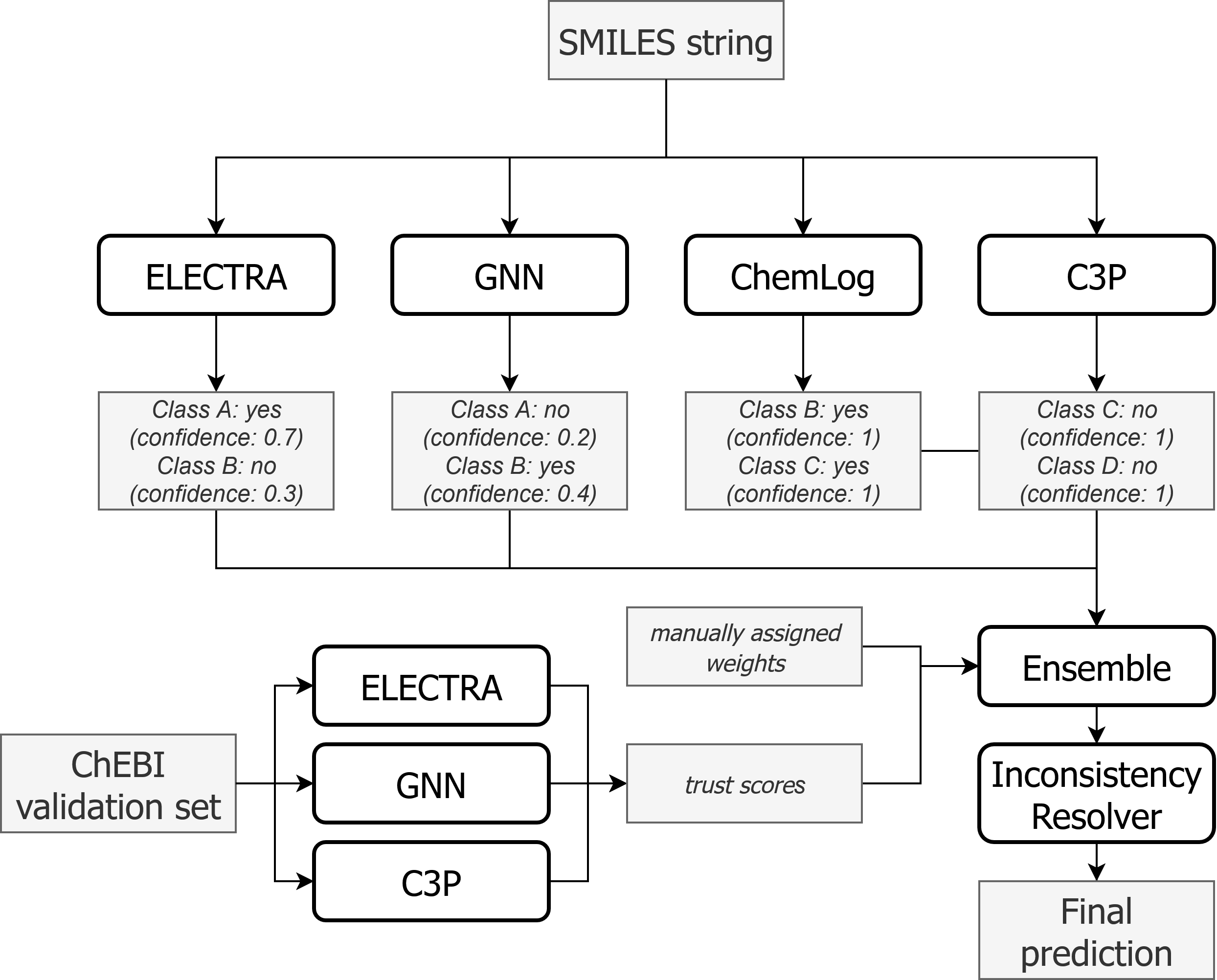
Given a sample (i.e., a SMILES string) and models $m_1, m_2, \ldots, m_n$, the ensemble works as follows:
- Get predictions from each model $m_i$ for the sample.
- For each class $c$, aggregate predictions $p_c^{m_i}$ from all models that made a prediction for that class. The aggregation happens separately for all positive predictions (i.e., $p_c^{m_i} \geq 0.5$) and all negative predictions ($p_c^{m_i} < 0.5$). If the aggregated value is larger for the positive predictions than for the negative predictions, the ensemble makes a positive prediction for class $c$:
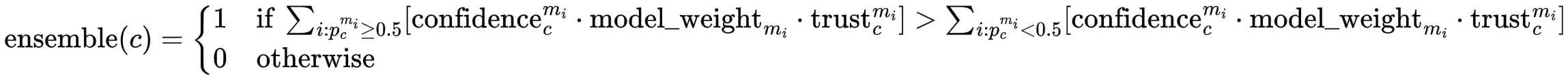
Here, confidence is the model's (self-reported) confidence in its prediction, calculated as $ \text{confidence}_c^{m_i} = 2|p_c^{m_i} - 0.5| $ For example, if a model makes a positive prediction with $p_c^{m_i} = 0.55$, the confidence is $2|0.55 - 0.5| = 0.1$. One could say that the model is not very confident in its prediction and very close to switching to a negative prediction. If another model is very sure about its negative prediction with $p_c^{m_j} = 0.1$, the confidence is $2|0.1 - 0.5| = 0.8$. Therefore, if in doubt, we are more confident in the negative prediction.
Confidence can be disabled by the use_confidence parameter of the predict method (default: True).
The model_weight can be set for each model in the configuration file (default: 1). This is used to favor a certain
model independently of a given class.
Trust is based on the model's performance on a validation set. After training, we evaluate the Machine Learning models
on a validation set for each class. If the ensemble_type is set to wmv-f1, the trust is calculated as 1 + the F1 score.
If the ensemble_type is set to mv (the default), the trust is set to 1 for all models.
Inconsistency resolution
After a decision has been made for each class independently, the consistency of the predictions with regard to the ChEBI hierarchy and disjointness axioms is checked. This is done in 3 steps:
- (1) First, the hierarchy is corrected. For each pair of classes $A$ and $B$ where $A$ is a subclass of $B$ (following the is-a relation in ChEBI), we set the ensemble prediction of $B$ to 1 if the prediction of $A$ is 1. Intuitively speaking, if we have determined that a molecule belongs to a specific class (e.g., aromatic primary alcohol), it also belongs to the direct and indirect superclasses (e.g., primary alcohol, aromatic alcohol, alcohol).
- (2) Next, we check for disjointness. This is not specified directly in ChEBI, but in an additional ChEBI module (chebi-disjoints.owl).
We have extracted these disjointness axioms into a CSV file and added some more disjointness axioms ourselves (see
data>disjoint_chebi.csvanddata>disjoint_additional.csv). If two classes $A$ and $B$ are disjoint and we predict both, we select one with the higher class score and set the other to 0. - (3) Since the second step might have introduced new inconsistencies into the hierarchy, we repeat the first step, but with a small change. For a pair of classes $A \subseteq B$ with predictions $1$ and $0$, instead of setting $B$ to $1$, we now set $A$ to $0$. This has the advantage that we cannot introduce new disjointness-inconsistencies and don't have to repeat step 2.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file chebifier-1.1.0.tar.gz.
File metadata
- Download URL: chebifier-1.1.0.tar.gz
- Upload date:
- Size: 59.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1a8384c33e8223cc4e5230411802dc6a84c721df6d7ef233abfceb2db4b36684
|
|
| MD5 |
671d4d2816173593c441dd80164caee0
|
|
| BLAKE2b-256 |
2422efa3f1cef543e074bf8bada272275a94dfde4d30131f0294eacc6513a26f
|
Provenance
The following attestation bundles were made for chebifier-1.1.0.tar.gz:
Publisher:
python-publish.yml on ChEB-AI/python-chebifier
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
chebifier-1.1.0.tar.gz -
Subject digest:
1a8384c33e8223cc4e5230411802dc6a84c721df6d7ef233abfceb2db4b36684 - Sigstore transparency entry: 299446568
- Sigstore integration time:
-
Permalink:
ChEB-AI/python-chebifier@47126b884886676f7baeac4f7f2efb9b562d3bf6 -
Branch / Tag:
refs/tags/v1.1.0 - Owner: https://github.com/ChEB-AI
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
python-publish.yml@47126b884886676f7baeac4f7f2efb9b562d3bf6 -
Trigger Event:
release
-
Statement type:
File details
Details for the file chebifier-1.1.0-py3-none-any.whl.
File metadata
- Download URL: chebifier-1.1.0-py3-none-any.whl
- Upload date:
- Size: 49.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
18279d6f755d0e76f17e64a2c50b97d388946000051b65ee395d0134336536de
|
|
| MD5 |
d10fbf5b14371c0a9091bf4dc926ff76
|
|
| BLAKE2b-256 |
d2ce2dacff18d1b357311d0648e9a29d690987ea6064ac16a4434d61be2f4621
|
Provenance
The following attestation bundles were made for chebifier-1.1.0-py3-none-any.whl:
Publisher:
python-publish.yml on ChEB-AI/python-chebifier
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
chebifier-1.1.0-py3-none-any.whl -
Subject digest:
18279d6f755d0e76f17e64a2c50b97d388946000051b65ee395d0134336536de - Sigstore transparency entry: 299446593
- Sigstore integration time:
-
Permalink:
ChEB-AI/python-chebifier@47126b884886676f7baeac4f7f2efb9b562d3bf6 -
Branch / Tag:
refs/tags/v1.1.0 - Owner: https://github.com/ChEB-AI
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
python-publish.yml@47126b884886676f7baeac4f7f2efb9b562d3bf6 -
Trigger Event:
release
-
Statement type:







