Effortless LLM extraction from documents
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description

ContextGem: Effortless LLM extraction from documents
| Package |     |
| Quality |      |
| Tools |         |
| Docs |     |
| Community |    |

ContextGem is a free, open-source LLM framework that makes it radically easier to extract structured data and insights from documents — with minimal code.
💎 Why ContextGem?
Reliable structured extraction from documents typically involves writing extraction prompts, designing validation models, mapping outputs back to source references, orchestrating multi-step pipelines, and tracking usage across LLMs. ContextGem handles all of this through powerful abstractions — you describe what to extract in natural language, and the framework handles how.
The result: structured data with precise paragraph- and sentence-level references, automatic justifications, hierarchical multi-aspect extraction, and a unified, serializable document storage model — all from minimal code.
📖 Read more on the project motivation in the documentation.
⭐ Key features
| ✨ Automated dynamic prompts | 📐 Automated data modelling | 📍 Granular reference mapping |
| 💭 Built-in justifications | 🪆 Nested context extraction | 🔗 Unified declarative pipeline |
💡 What you can build
With minimal code, you can:
- Extract structured data from documents (text, images)
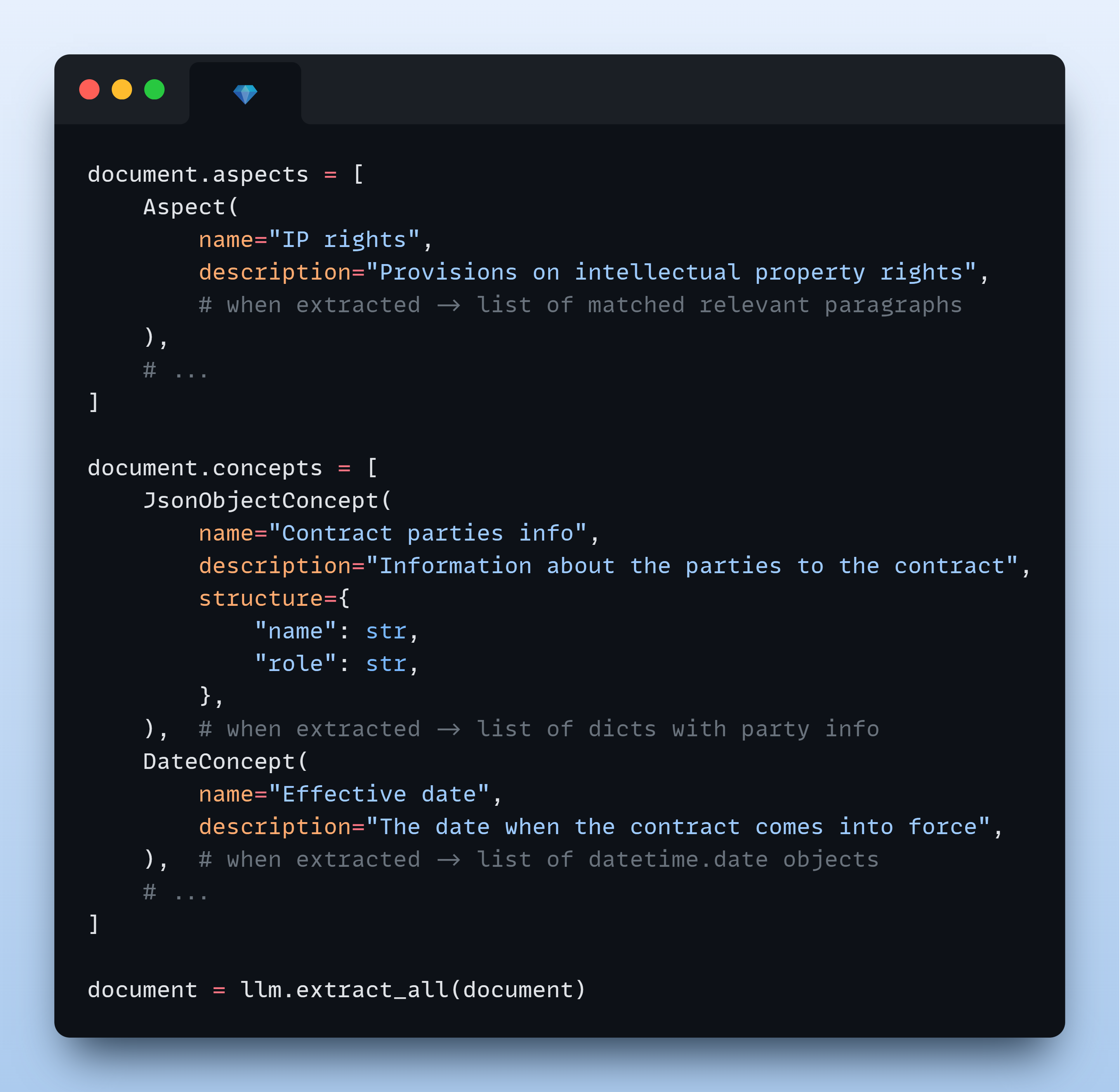
- Identify and analyze key aspects (topics, themes, categories) within documents (learn more)
- Extract specific concepts (entities, facts, conclusions, assessments) from documents (learn more)
- Build complex extraction workflows through a simple, intuitive API
- Create multi-level extraction pipelines (aspects containing concepts, hierarchical aspects)
📦 Installation
Using uv (recommended):
uv add contextgem
Or using pip:
pip install -U contextgem
🚀 Quick start
The following example demonstrates how to use ContextGem to extract anomalies from a legal document - a complex concept that requires contextual understanding. Unlike traditional RAG approaches that might miss subtle inconsistencies, ContextGem analyzes the entire document context to identify content that doesn't belong, complete with source references and justifications.
# Quick Start Example - Extracting anomalies from a document, with source references and justifications
import os
from contextgem import Document, DocumentLLM, StringConcept
# Sample document text (shortened for brevity)
doc = Document(
raw_text=(
"Consultancy Agreement\n"
"This agreement between Company A (Supplier) and Company B (Customer)...\n"
"The term of the agreement is 1 year from the Effective Date...\n"
"The Supplier shall provide consultancy services as described in Annex 2...\n"
"The Customer shall pay the Supplier within 30 calendar days of receiving an invoice...\n"
"The purple elephant danced gracefully on the moon while eating ice cream.\n" # 💎 anomaly
"Time-traveling dinosaurs will review all deliverables before acceptance.\n" # 💎 another anomaly
"This agreement is governed by the laws of Norway...\n"
),
)
# Attach a document-level concept
doc.concepts = [
StringConcept(
name="Anomalies", # in longer contexts, this concept is hard to capture with RAG
description="Anomalies in the document",
add_references=True,
reference_depth="sentences",
add_justifications=True,
justification_depth="brief",
# see the docs for more configuration options
)
# add more concepts to the document, if needed
# see the docs for available concepts: StringConcept, JsonObjectConcept, etc.
]
# Or use `doc.add_concepts([...])`
# Define an LLM for extracting information from the document
llm = DocumentLLM(
model="openai/gpt-4o-mini", # or another provider/LLM
api_key=os.environ.get(
"CONTEXTGEM_OPENAI_API_KEY"
), # your API key for the LLM provider
# see the docs for more configuration options
)
# Extract information from the document
doc = llm.extract_all(doc) # or use async version `await llm.extract_all_async(doc)`
# Access extracted information in the document object
anomalies_concept = doc.concepts[0]
# or `doc.get_concept_by_name("Anomalies")`
for item in anomalies_concept.extracted_items:
print("Anomaly:")
print(f" {item.value}")
print("Justification:")
print(f" {item.justification}")
print("Reference paragraphs:")
for p in item.reference_paragraphs:
print(f" - {p.raw_text}")
print("Reference sentences:")
for s in item.reference_sentences:
print(f" - {s.raw_text}")
print()

🧠 How it works
📝 Step 1: Define extraction context
| 📄 Document |
|---|
| Create a Document that contains text and/or visual content representing your document (contract, invoice, report, CV, etc.), from which an LLM extracts information (aspects and/or concepts). Learn more |
document = Document(raw_text="Non-Disclosure Agreement...")
🎯 Step 2: Define what to extract
| 🔍 Aspects | 💡 Concepts |
|---|---|
| Define Aspects to extract text segments from the document (sections, topics, themes). You can organize content hierarchically and combine with concepts for comprehensive analysis. Learn more | Define Concepts to extract specific data points with intelligent inference: entities, insights, structured objects, classifications, numerical calculations, dates, ratings, and assessments. Learn more |
# Extract document sections
aspect = Aspect(
name="Term and termination",
description="Clauses on contract term and termination",
)
# Extract specific data points
concept = BooleanConcept(
name="NDA check",
description="Is the contract an NDA?",
)
# Add these to the document instance for further extraction
document.add_aspects([aspect])
document.add_concepts([concept])
| 🔄 Alternative: Configure Extraction Pipeline |
|---|
| Create a reusable collection of predefined aspects and concepts that enables consistent extraction across multiple documents. Learn more |
🧠 Step 3: Run LLM extraction
| 🤖 LLM | 🤖🤖 Alternative: LLM Group (advanced) |
|---|---|
| Configure a cloud or local LLM that will extract aspects and/or concepts from the document. DocumentLLM supports fallback models and role-based task routing for optimal performance. Learn more | Configure a group of LLMs with unique roles for complex extraction workflows. You can route different aspects and/or concepts to specialized LLMs (e.g., simple extraction vs. reasoning tasks). Learn more |
llm = DocumentLLM(
model="openai/gpt-5-mini", # or another provider/LLM
api_key="...",
)
document = llm.extract_all(document)
# print(document.aspects[0].extracted_items)
# print(document.concepts[0].extracted_items)
📖 Learn more about ContextGem's core components and their practical examples in the documentation.
📚 Usage Examples
🌟 Basic usage:
- Aspect Extraction from Document
- Extracting Aspect with Sub-Aspects
- Concept Extraction from Aspect
- Concept Extraction from Document (text)
- Concept Extraction from Document (vision)
- LLM chat interface with tool calling
🚀 Advanced usage:
- Extracting Aspects Containing Concepts
- Extracting Aspects and Concepts from a Document
- Using a Multi-LLM Pipeline to Extract Data from Several Documents
🎯 Focused document analysis
ContextGem leverages LLMs' long context windows to deliver superior extraction accuracy from individual documents. Unlike RAG approaches that often struggle with complex concepts and nuanced insights, ContextGem capitalizes on continuously expanding context capacity, evolving LLM capabilities, and decreasing costs. This focused approach enables direct information extraction from complete documents, eliminating retrieval inconsistencies while optimizing for in-depth single-document analysis. While this delivers higher accuracy for individual documents, ContextGem does not currently support cross-document querying or corpus-wide retrieval - for these use cases, modern RAG frameworks (e.g., LlamaIndex, Haystack) remain more appropriate.
📖 Read more on how ContextGem works in the documentation.
🤖 Supported LLMs
ContextGem supports both cloud-based and local LLMs through LiteLLM integration:
- Cloud LLMs: OpenAI, Anthropic, Google, Azure OpenAI, xAI, and more
- Local LLMs: Run models locally using providers like Ollama, LM Studio, etc.
- Model Architectures: Works with both reasoning/CoT-capable (e.g. gpt-5) and non-reasoning models (e.g. gpt-4.1)
- Simple API: Unified interface for all LLMs with easy provider switching
💡 Model Selection Note: For reliable structured extraction, we recommend using models with performance equivalent to or exceeding
gpt-4o-mini. Smaller models (such as 8B parameter models) may struggle with ContextGem's detailed extraction instructions. If you encounter issues with smaller models, see our troubleshooting guide for potential solutions.
📖 Learn more about supported LLM providers and models, how to configure LLMs, and LLM extraction methods in the documentation.
⚡ Optimizations
ContextGem documentation offers guidance on optimization strategies to maximize performance, minimize costs, and enhance extraction accuracy:
- Optimizing for Accuracy
- Optimizing for Speed
- Optimizing for Cost
- Dealing with Long Documents
- Choosing the Right LLM(s)
- Troubleshooting Issues with Small Models
💾 Serializing results
ContextGem allows you to save and load Document objects, pipelines, and LLM configurations with built-in serialization methods:
- Save processed documents to avoid repeating expensive LLM calls
- Transfer extraction results between systems
- Persist pipeline and LLM configurations for later reuse
📖 Learn more about serialization options in the documentation.
📚 Documentation
📖 Full documentation: contextgem.dev
🤖 AI-powered code exploration: DeepWiki provides visual architecture maps and natural language Q&A for the codebase.
📈 Change history: See the CHANGELOG for version history, improvements, and bug fixes.
💬 Community
🐛 Found a bug or have a feature request? Open an issue on GitHub.
💭 Need help or want to discuss? Start a thread in GitHub Discussions.
🤝 Contributing
We welcome contributions from the community - whether it's fixing a typo or developing a completely new feature!
📋 Get started: Check out our Contributor Guidelines.
🔐 Security
This project is automatically scanned for security vulnerabilities using multiple security tools:
- CodeQL - GitHub's semantic code analysis engine for vulnerability detection
- Bandit - Python security linter for common security issues
- Snyk - Dependency vulnerability monitoring (used as needed)
🛡️ Security policy: See SECURITY file for details.
💖 Acknowledgements
ContextGem relies on these excellent open-source packages:
- aiolimiter: Powerful rate limiting for async operations
- colorlog: Colored formatter for Python's logging module
- docstring-parser: Docstring parsing for auto-generating tool schemas
- fastjsonschema: Ultra-fast JSON schema validation
- genai-prices: LLM pricing data and utilities (by Pydantic) to automatically estimate costs
- Jinja2: Fast, expressive, extensible templating engine used for prompt rendering
- litellm: Unified interface to multiple LLM providers with seamless provider switching
- lxml: High-performance XML processing library for parsing DOCX document structure
- pillow: Image processing library for local model image handling
- pydantic: The gold standard for data validation
- python-ulid: Efficient ULID generation for unique object identification
- tenacity: General-purpose retry library for Python
- typing-extensions: Backports of the latest typing features for enhanced type annotations
- wtpsplit-lite: Lightweight version of wtpsplit for state-of-the-art paragraph/sentence segmentation using wtpsplit's SaT models
📄 License & Contact
License: Apache 2.0 License - see the LICENSE and NOTICE files for details.
Copyright: © 2025 Shcherbak AI AS — Enterprise AI Engineering. We build AI agents that transform how enterprises operate.
Connect: LinkedIn or X for questions or collaboration ideas.
Built with ❤️ in Oslo, Norway.
📦 More from Shcherbak AI
| Package | Description |
|---|---|
tethered   |
Runtime network egress control for Python. One function call blocks all unauthorized outbound connections — zero dependencies, no infrastructure changes. Ideal for supply chain defense, AI agent guardrails, and test isolation. |
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file contextgem-0.23.0.tar.gz.
File metadata
- Download URL: contextgem-0.23.0.tar.gz
- Upload date:
- Size: 190.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
db12918db2f47faa0be58039c1677cc8f234745c8dd9679bb5a3208d6efb8063
|
|
| MD5 |
a1d5023119ae125a372083a9560ce1e6
|
|
| BLAKE2b-256 |
eeece4955319a7a956d1edcf9a101780c23b6ec00754fda07329e2e89ee12dec
|
Provenance
The following attestation bundles were made for contextgem-0.23.0.tar.gz:
Publisher:
publish.yml on shcherbak-ai/contextgem
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
contextgem-0.23.0.tar.gz -
Subject digest:
db12918db2f47faa0be58039c1677cc8f234745c8dd9679bb5a3208d6efb8063 - Sigstore transparency entry: 1440346210
- Sigstore integration time:
-
Permalink:
shcherbak-ai/contextgem@7336514ef9ff9bf0060b6cf760c66bf03909d653 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/shcherbak-ai
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@7336514ef9ff9bf0060b6cf760c66bf03909d653 -
Trigger Event:
workflow_run
-
Statement type:
File details
Details for the file contextgem-0.23.0-py3-none-any.whl.
File metadata
- Download URL: contextgem-0.23.0-py3-none-any.whl
- Upload date:
- Size: 241.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
acd603e76b19afdf9d82555e2798e3ae923a4e75944e7a0e534df21a6a8537a3
|
|
| MD5 |
ba96ed659cdc064446e57cd0dd6f0a96
|
|
| BLAKE2b-256 |
095052c9f92455e0fcc18c55a7740efe4b0ae0eeafb7dcea58b8300ce0cffce5
|
Provenance
The following attestation bundles were made for contextgem-0.23.0-py3-none-any.whl:
Publisher:
publish.yml on shcherbak-ai/contextgem
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
contextgem-0.23.0-py3-none-any.whl -
Subject digest:
acd603e76b19afdf9d82555e2798e3ae923a4e75944e7a0e534df21a6a8537a3 - Sigstore transparency entry: 1440346217
- Sigstore integration time:
-
Permalink:
shcherbak-ai/contextgem@7336514ef9ff9bf0060b6cf760c66bf03909d653 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/shcherbak-ai
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@7336514ef9ff9bf0060b6cf760c66bf03909d653 -
Trigger Event:
workflow_run
-
Statement type:







