Lightweight wrapper for cortecs.ai enabling ⚡️ instant provisioning

Project description
cortecs-py






Lightweight wrapper for the cortecs.ai enabling instant provisioning.
⚡Quickstart
Dynamic provisioning allows you to run LLM-workflows on dedicated compute. The LLM and underlying resources are automatically provisioned for the duration of use, providing maximum cost-efficiency. Once the workflow is complete, the infrastructure is automatically shut down.
This library starts and stops your resources. The logic can be implemented using popular frameworks such as LangChain or crewAI.
- Start your LLM
- Execute (massive batch) jobs
- Shutdown your LLM
from cortecs_py.client import Cortecs
from cortecs_py.integrations.langchain import DedicatedLLM
cortecs = Cortecs()
with DedicatedLLM(client=cortecs, model_name='cortecs/phi-4-FP8-Dynamic') as llm:
essay = llm.invoke('Write an essay about dynamic provisioning')
print(essay.content)
Example
Install
pip install cortecs-py
Summarizing documents
First, set up the environment variables. Use your credentials from cortecs.ai.
export OPENAI_API_KEY="<YOUR_CORTECS_API_KEY>"
export CORTECS_CLIENT_ID="<YOUR_ID>"
export CORTECS_CLIENT_SECRET="<YOUR_SECRET>"
This example shows how to use LangChain to configure a simple summarization chain. The llm is dynamically provisioned and the chain is executed in parallel.
from langchain_community.document_loaders import ArxivLoader
from langchain_core.prompts import ChatPromptTemplate
from cortecs_py.client import Cortecs
from cortecs_py.integrations.langchain import DedicatedLLM
cortecs = Cortecs()
loader = ArxivLoader(
query="reasoning",
load_max_docs=40,
get_ful_documents=True,
doc_content_chars_max=25000, # ~6.25k tokens, make sure the models supports that context length
load_all_available_meta=False
)
prompt = ChatPromptTemplate.from_template("{text}\n\n Explain to me like I'm five:")
docs = loader.load()
with DedicatedLLM(client=cortecs, model_name='cortecs/phi-4-FP8-Dynamic') as llm:
chain = prompt | llm
print("Processing data batch-wise ...")
summaries = chain.batch([{"text": doc.page_content} for doc in docs])
for summary in summaries:
print(summary.content + '-------\n\n\n')
This simple example showcases the power of dynamic provisioning. We summarized 224.2k input tokens into 12.9k output tokens in 55 seconds. The llm can be fully utilized in those 55 seconds enabling better cost efficiency. Comparing to serverless open source model providers we observe the following:
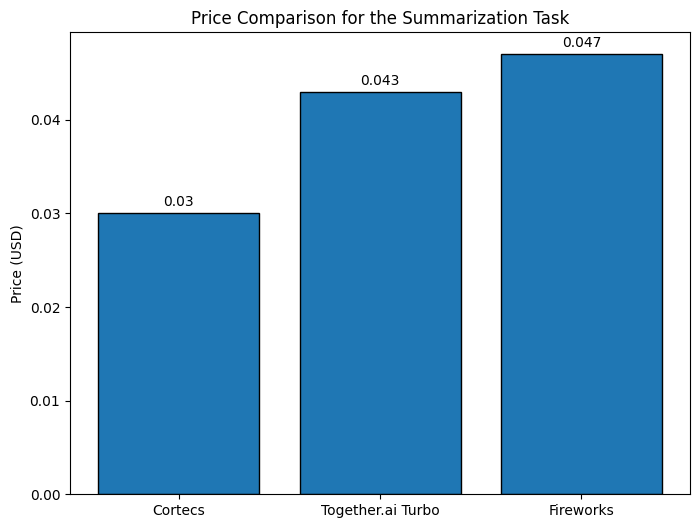
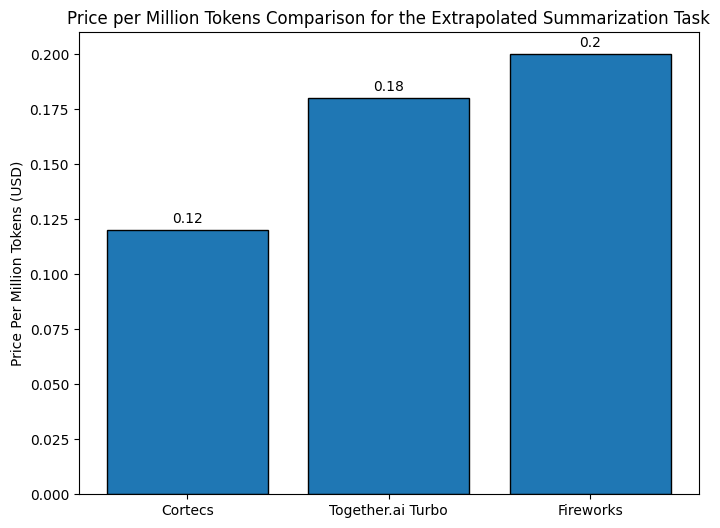
Use Cases
- Low latency -> How to process reddit in realtime
- Multi-agents -> How to use CrewAI without request limits
- Batch processing
- High-security


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file cortecs_py-0.1.0.tar.gz.
File metadata
- Download URL: cortecs_py-0.1.0.tar.gz
- Upload date:
- Size: 14.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.10.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
61bc6d439879b4ae9d03840769038656bd236a3d555d700c8b6978b8ee6e4ccf
|
|
| MD5 |
4b6c10d5be117e0d3c450d03c30452f5
|
|
| BLAKE2b-256 |
a6de75ef563a2758b39f0664758a7380933fa4ddc9bbb346e15e83e6ad5fae83
|
File details
Details for the file cortecs_py-0.1.0-py3-none-any.whl.
File metadata
- Download URL: cortecs_py-0.1.0-py3-none-any.whl
- Upload date:
- Size: 14.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.10.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a81b8db54f53a0a13180b8d9bb9324869425da65658ffc1eedbee5b6ceacfc50
|
|
| MD5 |
8c9578867e4eade39d5b514ed7740486
|
|
| BLAKE2b-256 |
468dabc9393579f03a7ab92a60d56def9a6b406b412e8c9724aa54cff5a26349
|







