A package for building customizable decision trees and random forests.

Project description

Custom Decision Trees




Custom Decision Trees is a Python package that lets you build machine learning models with advanced configuration :
Main Features
Splitting criteria customization
Define your own cutting criteria in Python language (documentation in the following sections).
This feature is particularly useful in "cost-dependent" scenarios. Examples:
- Trading Movements Classification: When the goal is to maximize economic profit, the metric can be set to economic profit, optimizing tree splitting accordingly.
- Churn Prediction: To minimize false negatives, metrics like F1 score or recall can guide the splitting process.
- Fraud Detection: Splitting can be optimized based on the proportion of fraudulent transactions identified relative to the total, rather than overall classification accuracy.
- Marketing Campaigns: The splitting can focus on maximizing expected revenue from customer segments identified by the tree.
Multi-conditional node splitting
Allow trees to split nodes with one or more simultaneous conditions.
Example of multi-condition splitting on the Titanic dataset:
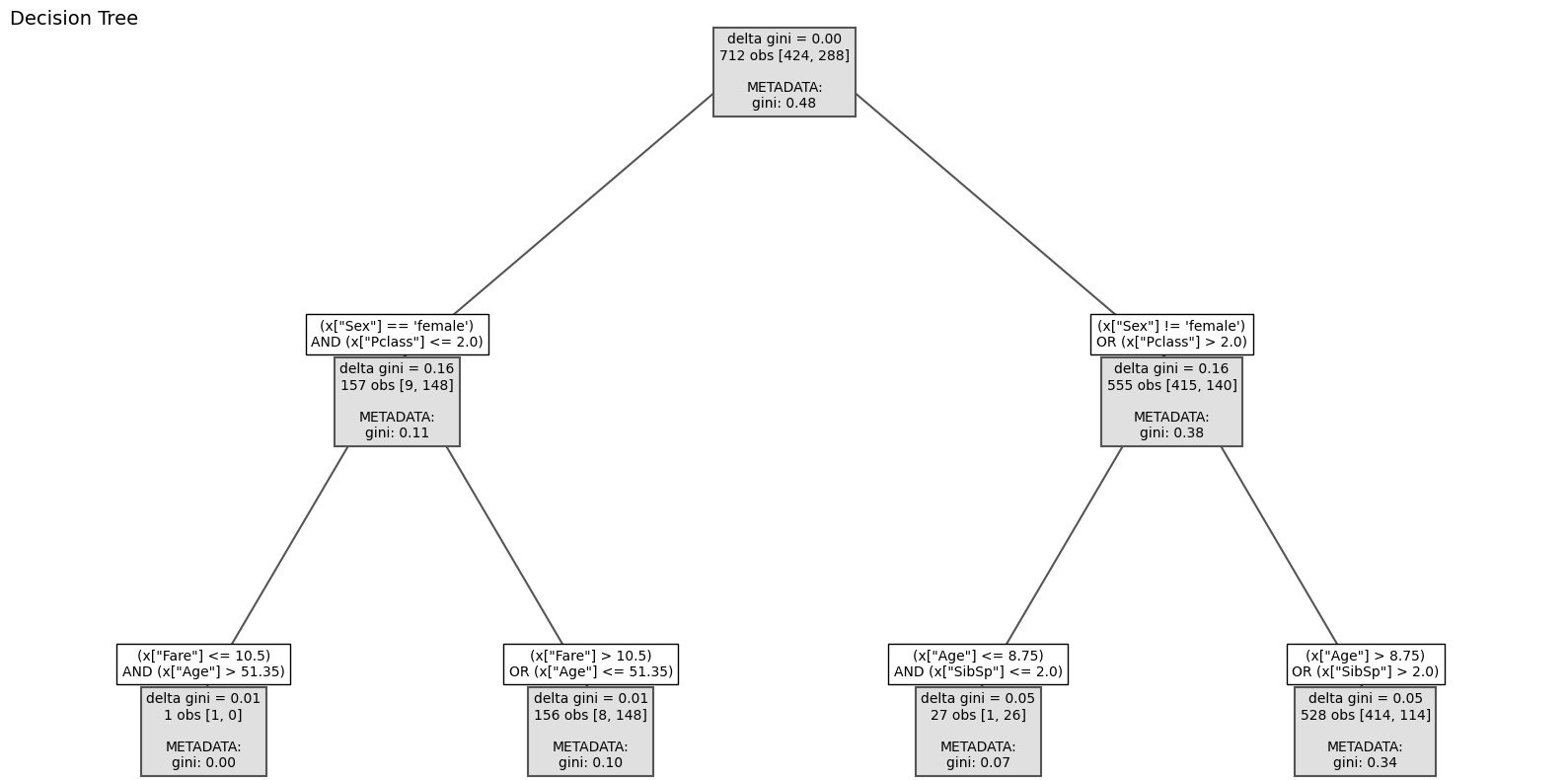
Other features
- Supports multiclass classification
- Supports standard decision tree parameters (max_depth, min_samples_split, max_features, n_estimators, etc.)
- Supports STRING type explanatory variables
- Ability to control the number of variable splitting options when optimizing a split (i.e
nb_max_cut_options_per_varparameter). - Ability to control the maximum number of splits to be tested per node to avoid overly long calculations in multi-condition mode (i.e
nb_max_split_options_per_nodeparameters) - Possibility of parallelizing calculations (i.e
n_jobsparameters)
Reminder on splitting criteria
Splitting in a decision tree is achieved by optimizing a metric. For example, Gini optimization consists in maximizing the $\Delta_{Gini}$ :
- The Gini Index represents the impurity of a group of observations based on the observations of each class (0 and 1):
$$ I_{Gini} = 1 - p_0^2 - p_1^2 $$
- The metric to be maximized is $\Delta_{Gini}$, the difference between the Gini index on the parent node and the weighted average of the Gini index between the two child nodes ($L$ and $R$).
$$ \Delta_{Gini} = I_{Gini} - \frac{N_L * I_{Gini_L}}{N} - \frac{N_R * I_{Gini_R}}{N} $$
At each node, the tree algorithm finds the split that minimizes $\Delta$ over all possible splits and over all features. Once the optimal split is selected, the tree is grown by recursively applying this splitting process to the resulting child nodes.
Usage
See
./notebooks/folder for a complete examples.
Installation
pip install custom-decision-trees
Define your metric
To integrate a specific measure, the user must define a class containing the compute_metric and compute_delta methods, then insert this class into the classifier.
Example of a class with the Gini index :
import numpy as np
from custom_decision_trees.metrics import MetricBase
class Gini(MetricBase):
def __init__(
self,
n_classes: int = 2,
) -> None:
self.n_classes = n_classes
self.max_impurity = 1 - 1 / n_classes
def compute_gini(
self,
metric_data: np.ndarray,
) -> float:
y = metric_data[:, 0]
nb_obs = len(y)
if nb_obs == 0:
return self.max_impurity
props = [(np.sum(y == i) / nb_obs) for i in range(self.n_classes)]
metric = 1 - np.sum([prop**2 for prop in props])
return float(metric)
def compute_metric(
self,
metric_data: np.ndarray,
mask: np.ndarray,
):
gini_parent = self.compute_gini(metric_data)
gini_side1 = self.compute_gini(metric_data[mask])
gini_side2 = self.compute_gini(metric_data[~mask])
delta = (
gini_parent -
gini_side1 * np.mean(mask) -
gini_side2 * (1 - np.mean(mask))
)
metadata = {"gini": round(gini_side1, 3)}
return float(delta), metadata
Train and predict
Once you have instantiated the model with your custom metric, all you have to do is use the .fit and .predict_proba methods:
from custom_decision_trees import DecisionTree
gini = Gini()
decision_tree = DecisionTree(
metric=gini,
max_depth=2,
nb_max_conditions_per_node=2 # Set to 1 for a traditional decision tree
)
decision_tree.fit(
X=X_train,
y=y_train,
metric_data=metric_data,
)
probas = model.predict_probas(
X=X_test
)
probas[:5]
>>> array([[0.75308642, 0.24691358],
[0.36206897, 0.63793103],
[0.75308642, 0.24691358],
[0.36206897, 0.63793103],
[0.90243902, 0.09756098]])
Print the tree
You can also display the decision tree, with the values of your metrics, using the print_tree method:
decision_tree.print_tree(
feature_names=features,
metric_name="MyMetric",
)
>>> [0] 712 obs -> MyMetric = 0.0
| [1] (x["Sex"] <= 0.0) AND (x["Pclass"] <= 2.0) | 157 obs -> MyMetric = 0.16
| | [3] (x["Age"] <= 2.0) AND (x["Fare"] > 26.55) | 1 obs -> MyMetric = 0.01
| | [4] (x["Age"] > 2.0) OR (x["Fare"] <= 26.55) | 156 obs -> MyMetric = 0.01
| [2] (x["Sex"] > 0.0) OR (x["Pclass"] > 2.0) | 555 obs -> MyMetric = 0.16
| | [5] (x["SibSp"] <= 2.0) AND (x["Age"] <= 8.75) | 27 obs -> MyMetric = 0.05
| | [6] (x["SibSp"] > 2.0) OR (x["Age"] > 8.75) | 528 obs -> MyMetric = 0.05
Plot the tree
decision_tree.plot_tree(
feature_names=features,
metric_name="delta gini",
)
Random Forest
Same with Random Forest Classifier :
from custom_decision_trees import RandomForest
random_forest = RandomForest(
metric=gini,
n_estimators=10,
max_depth=2,
nb_max_conditions_per_node=2,
)
random_forest.fit(
X=X_train,
y=y_train,
metric_data=metric_data
)
probas = random_forest.predict_probas(
X=X_test
)


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file custom_decision_trees-2.0.3.tar.gz.
File metadata
- Download URL: custom_decision_trees-2.0.3.tar.gz
- Upload date:
- Size: 23.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dd84096ffaac3108e2dc4711da088e5fa4c1332d3ee0b871e87e6a927162e4a7
|
|
| MD5 |
451962b8bd84b9e0b868f97a7eee8066
|
|
| BLAKE2b-256 |
7bf8976a44654b7e670199df2fcf0ec2532262eb9e5b5f062ec3d204fa44ec65
|
File details
Details for the file custom_decision_trees-2.0.3-py3-none-any.whl.
File metadata
- Download URL: custom_decision_trees-2.0.3-py3-none-any.whl
- Upload date:
- Size: 31.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
644714c8b0c00249b40f0682dcf924ffd58f2273a3c2186177de0e2d8edfe6bf
|
|
| MD5 |
c63154a8ca5760968dbf0202e4f84863
|
|
| BLAKE2b-256 |
1be57790c12e41eae0617ea24885f60fcb312a23d48a4ae9a980304665de2ada
|







