A Python package

Project description

DAG-based Gradio workflows!
DAG-based Gradio workflows!
daggr is a Python library for building AI workflows that connect Gradio apps, ML models (through Hugging Face Inference Providers), and custom Python functions. It automatically generates a visual canvas for your workflow allowing you to inspect intermediate outputs, rerun any step any number of times, and preserves state for complex or long-running workflows. Daggr also tracks provenance—when you browse through previous results, it automatically restores the exact inputs that produced each output, and visually indicates which parts of your workflow are stale.
https://github.com/user-attachments/assets/2cfe49c0-3118-4570-b2bd-f87c333836b5
Installation
pip install daggr
(requires Python 3.10 or higher).
Quick Start
After installing daggr, create a new Python file, say app.py, and paste this code:
import random
import gradio as gr
from daggr import GradioNode, Graph
glm_image = GradioNode(
"hf-applications/Z-Image-Turbo",
api_name="/generate_image",
inputs={
"prompt": gr.Textbox( # An input node is created for the prompt
label="Prompt",
value="A cheetah in the grassy savanna.",
lines=3,
),
"height": 1024, # Fixed value (does not appear in the canvas)
"width": 1024, # Fixed value (does not appear in the canvas)
"seed": random.random, # Functions are rerun every time the workflow is run (not shown in the canvas)
},
outputs={
"image": gr.Image(
label="Image" # Display original image
),
},
)
background_remover = GradioNode(
"hf-applications/background-removal",
api_name="/image",
inputs={
"image": glm_image.image,
},
postprocess=lambda _, final: final,
outputs={
"image": gr.Image(label="Final Image"), # Display only final image
},
)
graph = Graph(
name="Transparent Background Image Generator", nodes=[glm_image, background_remover]
)
graph.launch()
Run daggr app.py to start the app with hot reloading (or python app.py for standard execution). You should see a Daggr app like this that you can use to generate images with a transparent background!
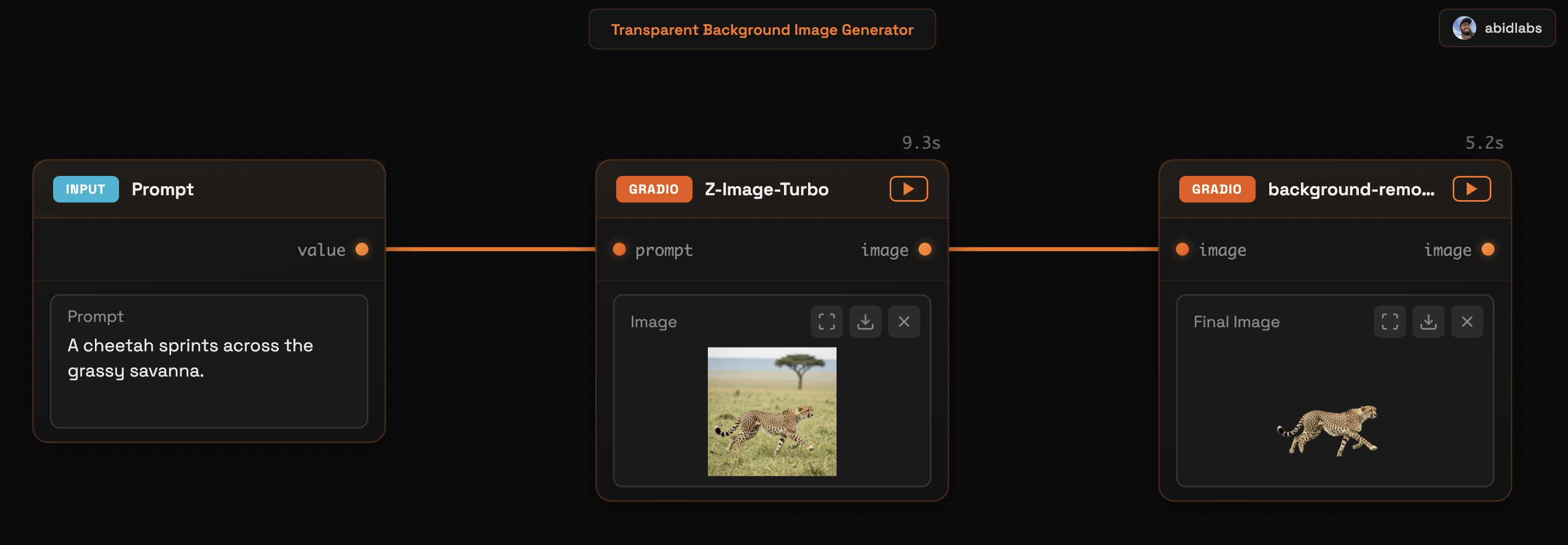
When to (Not) Use Daggr
Use Daggr when:
- You want to define an AI workflow in Python involving Gradio Spaces, inference providers, or custom functions
- The workflow is complex enough that inspecting intermediate outputs or rerunning individual steps is useful
- You need a fixed pipeline that you or others can run with different inputs
- You want to explore variations—generate multiple outputs, compare them, and always know exactly what inputs produced each result
Why not... ComfyUI? ComfyUI is a visual node editor where you build workflows by dragging and connecting nodes. Daggr takes a code-first approach: you define workflows in Python and the visual canvas is generated automatically. If you prefer writing code over visual editing, Daggr may be a better fit. In addition, Daggr works with Gradio Spaces and Hugging Face models directly, no need for specialized nodes.
Why not... Airflow/Prefect? Daggr was inspired by Airflow/Prefect, but whereas the focus of these orchestration platforms is scheduling, monitoring, and managing pipelines at scale, Daggr is built for interactive AI/ML workflows with real-time visual feedback and immediate execution, making it ideal for prototyping, demos, and workflows where you want to inspect intermediate outputs and rerun individual steps on the fly.
Why not... Gradio? Gradio creates web UIs for individual ML models and demos. While complex workflows can be built in Gradio, they often fail in ways that are hard to debug when using the Gradio app. Daggr tries to provide a transparent, easily-inspectable way to chain multiple Gradio apps, custom Python functions, and inference providers through a visual canvas.
Don't use Daggr when:
- You need a simple UI for a single model or function - consider using Gradio directly
- You want a node-based editor for building workflows visually - consider using ComfyUI instead
How It Works
A Daggr workflow consists of nodes connected in a directed graph. Each node represents a computation: a Gradio Space API call, an inference call to a model, or a Python function.
Each node has input ports and output ports, which correspond to the node's parameters and return values. Ports are how data flows between nodes.
Input ports can be connected to:
- A previous node's output port → creates an edge, data flows automatically
- A Gradio component → creates a standalone input in the UI
- A fixed value → passed directly, doesn't appear in UI
- A callable → called each time the node runs (useful for random seeds)
Output ports can be connected to:
- A Gradio component → displays the output in the node's card
None→ output is hidden but can still connect to downstream nodes
Node Types
GradioNode
Calls a Gradio Space API endpoint. Use this to connect to any Gradio app on Hugging Face Spaces or running locally.
from daggr import GradioNode
import gradio as gr
image_gen = GradioNode(
space_or_url="black-forest-labs/FLUX.1-schnell", # HF Space ID or URL
api_name="/infer", # API endpoint name
inputs={
"prompt": gr.Textbox(label="Prompt"), # Creates UI input
"seed": 42, # Fixed value
"width": 1024,
"height": 1024,
},
outputs={
"image": gr.Image(label="Generated Image"), # Display in node card
},
)
Finding the right inputs: To find what parameters a GradioNode expects, go to the Gradio Space and click "Use via API" at the bottom of the page. This shows you the API endpoints and their parameters. For example, if the API page shows:
from gradio_client import Client
client = Client("black-forest-labs/FLUX.1-schnell")
result = client.predict(
prompt="Hello!!",
seed=0,
randomize_seed=True,
width=1024,
height=1024,
num_inference_steps=4,
api_name="/infer"
)
Then your GradioNode inputs should use the same parameter names: prompt, seed, randomize_seed, width, height, num_inference_steps.
Outputs: Output port names can be anything you choose—they simply map to the return values of the API endpoint in order. If an endpoint returns (image, seed), you might define:
outputs={
"generated_image": gr.Image(), # Maps to first return value
"used_seed": gr.Number(), # Maps to second return value
}
FnNode
Runs a Python function. Input ports are automatically discovered from the function signature.
from daggr import FnNode
import gradio as gr
def summarize(text: str, max_words: int = 100) -> str:
words = text.split()[:max_words]
return " ".join(words) + "..."
summarizer = FnNode(
fn=summarize,
inputs={
"text": gr.Textbox(label="Text to Summarize", lines=5),
"max_words": gr.Slider(minimum=10, maximum=500, value=100, label="Max Words"),
},
outputs={
"summary": gr.Textbox(label="Summary"),
},
)
Inputs: Keys in the inputs dict must match the function's parameter names. If you don't specify an input, it uses the function's default value (if available).
Outputs: Return values are mapped to output ports in the same order they are defined in the outputs dict—just like GradioNode. For a single output, simply return the value. For multiple outputs, return a tuple:
def process(text: str) -> tuple[str, int]:
return text.upper(), len(text)
node = FnNode(
fn=process,
inputs={"text": gr.Textbox()},
outputs={
"uppercase": gr.Textbox(), # First return value
"length": gr.Number(), # Second return value
},
)
Note: If you return a dict or list, it will be treated as a single value (mapped to the first output port), not as a mapping to output ports.
Concurrency: By default, FnNodes execute sequentially (one at a time per user session) to prevent resource contention from concurrent function calls. If your function is safe to run in parallel, you can enable concurrent execution:
# Allow this node to run in parallel with other nodes
node = FnNode(my_func, concurrent=True)
# Share a resource limit with other nodes (e.g., GPU memory)
gpu_node_1 = FnNode(process_image, concurrency_group="gpu", max_concurrent=2)
gpu_node_2 = FnNode(enhance_image, concurrency_group="gpu", max_concurrent=2)
| Parameter | Default | Description |
|---|---|---|
concurrent |
False |
If True, allow parallel execution |
concurrency_group |
None |
Name of a group sharing a concurrency limit |
max_concurrent |
1 |
Max parallel executions in the group |
Tip: When possible, prefer
GradioNodeorInferenceNodeoverFnNode. These nodes automatically run concurrently (they're external API calls), and your Hugging Face token is automatically passed through for ZeroGPU quota tracking, private Spaces access, and gated model access.
InferenceNode
Calls a model via Hugging Face Inference Providers. This lets you use models hosted on the Hugging Face Hub without downloading them.
from daggr import InferenceNode
import gradio as gr
llm = InferenceNode(
model="meta-llama/Llama-3.1-8B-Instruct",
inputs={
"prompt": gr.Textbox(label="Prompt", lines=3),
},
outputs={
"response": gr.Textbox(label="Response"),
},
)
Inputs: The expected inputs depend on the model's task type. For text generation models, use prompt. For other tasks, check the model's documentation on the Hub.
Outputs: Like other nodes, output names are arbitrary and map to return values in order.
Tip:
InferenceNodeandGradioNodeautomatically run concurrently and pass your HF token for ZeroGPU, private Spaces, and gated models. Prefer these overFnNodewhen possible.
Node Concurrency
Different node types have different concurrency behaviors:
| Node Type | Concurrency | Why |
|---|---|---|
GradioNode |
Concurrent | External API calls—safe to parallelize |
InferenceNode |
Concurrent | External API calls—safe to parallelize |
FnNode |
Sequential (default) | Local Python code may have resource constraints |
Why sequential by default for FnNode? Local Python functions often:
- Access shared resources (files, databases, GPU memory)
- Use libraries that aren't thread-safe
- Consume significant CPU/memory
By running FnNodes sequentially per session, daggr prevents race conditions and resource contention. If your function is safe to run in parallel, opt in with concurrent=True.
Concurrency groups let multiple nodes share a resource limit:
# Both nodes share GPU—at most 2 concurrent executions total
upscale = FnNode(upscale_image, concurrency_group="gpu", max_concurrent=2)
enhance = FnNode(enhance_image, concurrency_group="gpu", max_concurrent=2)
Testing Nodes
You can test-run any node in isolation using the .test() method:
tts = GradioNode("mrfakename/MeloTTS", api_name="/synthesize", ...)
result = tts.test(text="Hello world", speaker="EN-US")
# Returns: {"audio": "/path/to/audio.wav"}
If called without arguments, .test() auto-generates example values using each input component's .example_value() method:
result = tts.test() # Uses gr.Textbox().example_value(), etc.
This is useful for quickly checking what format a node returns without wiring up a full workflow.
Input Types
Each node's inputs dict accepts four types of values:
| Type | Example | Result |
|---|---|---|
| Gradio component | gr.Textbox(label="Topic") |
Creates UI input |
| Port reference | other_node.output_name |
Connects nodes |
| Fixed value | "Auto" or 42 |
Constant, no UI |
| Callable | random.random |
Called each run, no UI |
Output Types
Each node's outputs dict accepts two types of values:
| Type | Example | Result |
|---|---|---|
| Gradio component | gr.Image(label="Result") |
Displays output in node card |
| None | None |
Hidden, but can connect to downstream nodes |
Scatter / Gather (experimental)
When a node outputs a list and you want to process each item individually, use .each to scatter and .all() to gather:
script = FnNode(fn=generate_script, inputs={...}, outputs={"lines": gr.JSON()})
tts = FnNode(
fn=text_to_speech,
inputs={
"text": script.lines.each["text"], # Scatter: run once per item
"speaker": script.lines.each["speaker"],
},
outputs={"audio": gr.Audio()},
)
final = FnNode(
fn=combine_audio,
inputs={"audio_files": tts.audio.all()}, # Gather: collect all outputs
outputs={"audio": gr.Audio()},
)
Choice Nodes (experimental)
Sometimes you want to offer multiple alternatives for the same step in your workflow—for example, two different TTS providers or image generators. Use the | operator to create a choice node that lets users switch between variants in the UI:
host_voice = GradioNode(
space_or_url="abidlabs/tts",
api_name="/generate_voice_design",
inputs={
"voice_description": gr.Textbox(label="Host Voice"),
"language": "Auto",
"text": "Hi! I'm the host!",
},
outputs={"audio": gr.Audio(label="Host Voice")},
) | GradioNode(
space_or_url="mrfakename/E2-F5-TTS",
api_name="/basic_tts",
inputs={
"ref_audio_input": gr.Audio(label="Reference Audio"),
"gen_text_input": gr.Textbox(label="Text to Generate"),
},
outputs={"audio": gr.Audio(label="Host Voice")},
)
# Downstream nodes connect to host_voice.audio regardless of which variant is selected
dialogue = FnNode(
fn=generate_dialogue,
inputs={"host_voice": host_voice.audio, ...},
...
)
In the canvas, choice nodes display an accordion UI where you can:
- See all available variants
- Click to select which variant to use
- View the selected variant's input components
The selected variant is persisted per sheet, so your choice is remembered across page refreshes. All variants must have the same output ports (so downstream connections work regardless of selection), but they can have different input ports.
Putting It Together: A Mock Podcast Generator
import gradio as gr
from daggr import FnNode, GradioNode, Graph
# Generate voice profiles
host_voice = GradioNode(
space_or_url="abidlabs/tts",
api_name="/generate_voice_design",
inputs={
"voice_description": gr.Textbox(label="Host Voice", value="Deep British voice..."),
"language": "Auto",
"text": "Hi! I'm the host.",
},
outputs={"audio": gr.Audio(label="Host Voice")},
)
guest_voice = GradioNode(
space_or_url="abidlabs/tts",
api_name="/generate_voice_design",
inputs={
"voice_description": gr.Textbox(label="Guest Voice", value="Friendly American voice..."),
"language": "Auto",
"text": "Hi! I'm the guest.",
},
outputs={"audio": gr.Audio(label="Guest Voice")},
)
# Generate dialogue (would be an LLM call in production)
def generate_dialogue(topic: str, host_voice: str, guest_voice: str) -> tuple[list, str]:
dialogue = [
{"voice": host_voice, "text": "Hello, how are you?"},
{"voice": guest_voice, "text": "I'm great, thanks!"},
]
html = "<b>Host:</b> Hello!<br><b>Guest:</b> I'm great!"
return dialogue, html # Returns tuple: first value -> "json", second -> "html"
dialogue = FnNode(
fn=generate_dialogue,
inputs={
"topic": gr.Textbox(label="Topic", value="AI"),
"host_voice": host_voice.audio,
"guest_voice": guest_voice.audio,
},
outputs={
"json": gr.JSON(visible=False), # Maps to first return value
"html": gr.HTML(label="Script"), # Maps to second return value
},
)
# Generate audio for each line (scatter)
def text_to_speech(text: str, audio: str) -> str:
return audio # Would call TTS model in production
samples = FnNode(
fn=text_to_speech,
inputs={
"text": dialogue.json.each["text"],
"audio": dialogue.json.each["voice"],
},
outputs={"audio": gr.Audio(label="Sample")},
)
# Combine all audio (gather)
def combine_audio(audio_files: list[str]) -> str:
from pydub import AudioSegment
combined = AudioSegment.empty()
for path in audio_files:
combined += AudioSegment.from_file(path)
combined.export("output.mp3", format="mp3")
return "output.mp3"
final = FnNode(
fn=combine_audio,
inputs={"audio_files": samples.audio.all()},
outputs={"audio": gr.Audio(label="Full Podcast")},
)
graph = Graph(name="Podcast Generator", nodes=[host_voice, guest_voice, dialogue, samples, final])
graph.launch()
Sharing and Hosting
Create a public URL to share your workflow with others:
graph.launch(share=True)
This generates a temporary public URL (expires in 1 week) using Gradio's tunneling infrastructure.
Deploying to Hugging Face Spaces
For permanent hosting, use daggr deploy to deploy your app to Hugging Face Spaces:
daggr deploy my_app.py
Assuming you are logged in locally with your Hugging Face token, this command:
- Extracts the Graph from your script
- Creates a Space named after your Graph (e.g., "Podcast Generator" →
podcast-generator) - Uploads your script and dependencies
- Configures the Space with the Gradio SDK
Deploy Options
# Custom Space name
daggr deploy my_app.py --name my-custom-space
# Deploy to an organization
daggr deploy my_app.py --org huggingface
# Private Space with GPU
daggr deploy my_app.py --private --hardware t4-small
# Add secrets (e.g., API keys)
daggr deploy my_app.py --secret HF_TOKEN=xxx --secret OPENAI_KEY=yyy
# Preview without deploying
daggr deploy my_app.py --dry-run
| Option | Short | Description |
|---|---|---|
--name |
-n |
Space name (default: derived from Graph name) |
--title |
-t |
Display title (default: Graph name) |
--org |
-o |
Organization to deploy under |
--private |
-p |
Make the Space private |
--hardware |
Hardware tier: cpu-basic, cpu-upgrade, t4-small, t4-medium, a10g-small, etc. |
|
--secret |
-s |
Add secrets (repeatable) |
--requirements |
-r |
Custom requirements.txt path |
--dry-run |
Preview what would be deployed |
The deploy command automatically:
- Detects local Python imports and includes them
- Uses existing
requirements.txtif present, or generates one withdaggr - Renames your script to
app.py(HF Spaces convention) - Generates the required
README.mdwith Space metadata
Manual Deployment
You can also deploy manually by creating a new Space with the Gradio SDK, adding your workflow code to app.py, and including daggr in your requirements.txt.
Daggr automatically reads the GRADIO_SERVER_NAME and GRADIO_SERVER_PORT environment variables, which Hugging Face Spaces sets automatically for Gradio apps. This means your daggr app will work on Spaces without any additional configuration.
Persistence and Sheets
Daggr automatically saves your workflow state—input values, node results, and canvas position—so you can pick up where you left off after a page reload.
Sheets
Sheets are like separate workspaces within a single Daggr app. Each sheet has its own:
- Input values for all nodes
- Cached results from previous runs
- Canvas zoom and pan position
Use sheets to work on multiple projects within the same workflow. For example, in a podcast generator app, each sheet could represent a different podcast episode you're working on.
The sheet selector appears in the title bar. Click to switch between sheets, create new ones, rename them (double-click), or delete them.
Result History and Provenance Tracking
Every time a node runs, Daggr saves not just the output, but also a snapshot of all input values at that moment. This enables powerful exploratory workflows:
Browsing previous results: Use the ‹ and › arrows in the node footer to navigate through all cached results for that node (shown as "1/3", "2/3", etc.).
Automatic input restoration: When you select a previous result, Daggr automatically restores the input values that produced it. This means you can:
- Generate multiple variations by running a node several times with different inputs
- Browse through your results to find the best one
- When you select a result, see exactly what inputs created it
- Continue your workflow from that point with all the original context intact
Cascading restoration: When you toggle through results on a node, Daggr also automatically selects the matching result on downstream nodes (if one exists). For example, if you generated 3 images and removed the background from 2 of them, selecting image #1 will automatically show background-removal result #1.
Visual Staleness Indicators
Daggr uses edge colors to show you which parts of your workflow are up-to-date:
| Edge Color | Meaning |
|---|---|
| Orange | Fresh—the downstream node ran with this exact upstream value |
| Gray | Stale—the upstream value has changed, or the downstream hasn't run yet |
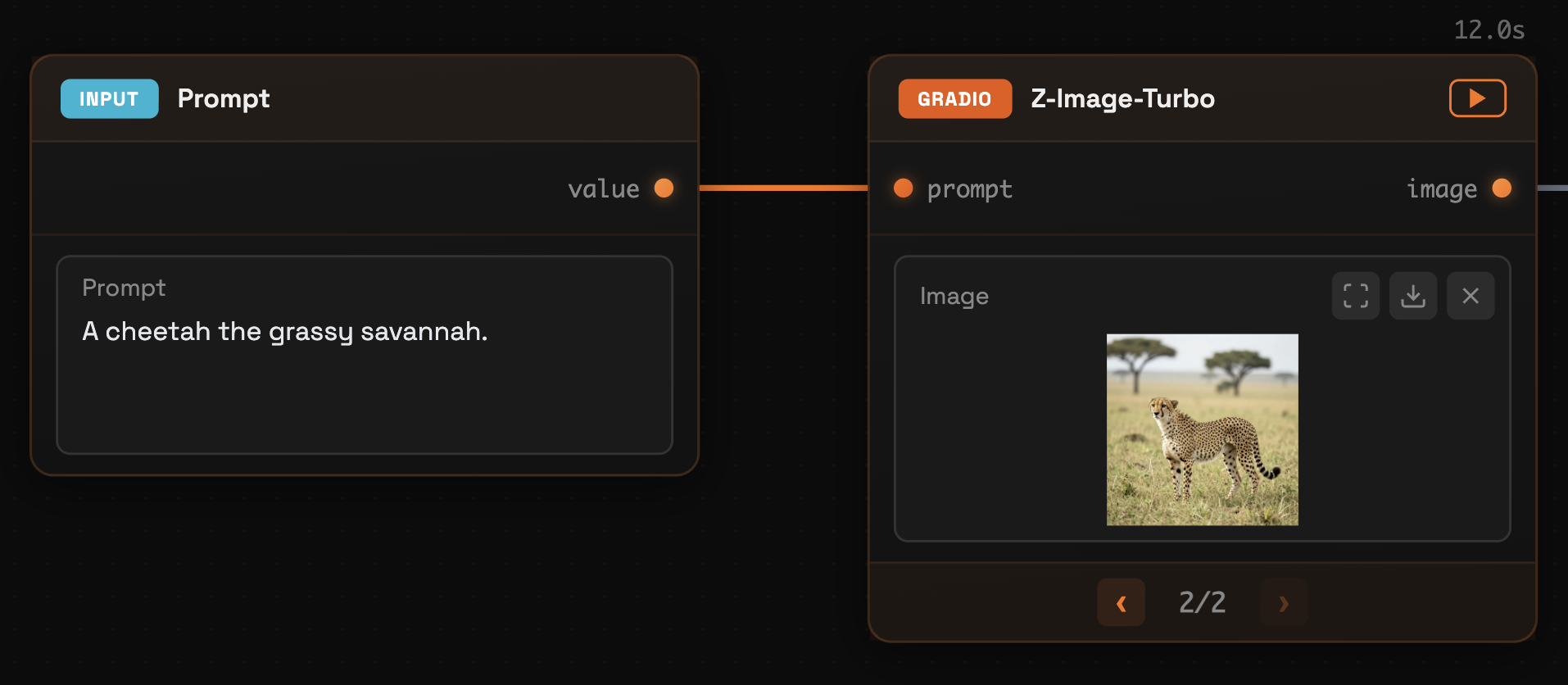
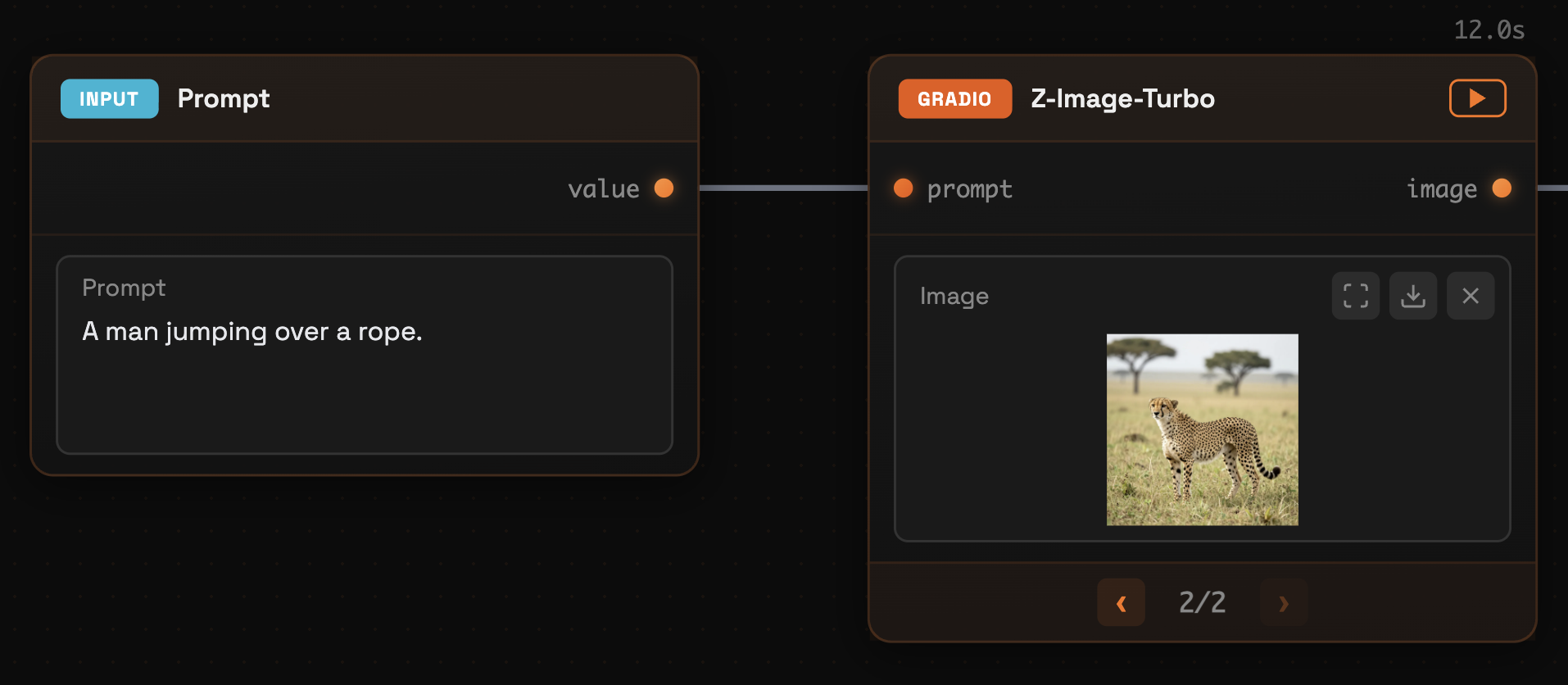
Edges are stale when:
- You edit an input value (e.g., change a text prompt)
- You select a different cached result on an upstream node
- A downstream node hasn't been run yet
This visual feedback helps you understand at a glance which results are current and which need to be re-run. It's especially useful in long workflows where you might forget which steps you've already executed with your current inputs.
Example workflow:
- Generate an image with prompt "A cheetah in the savanna" → edge turns orange
- Edit the prompt to "A lion in the jungle" → edge turns gray (stale)
- Re-run the image generation → edge turns orange again
- Run the background removal node → that edge also turns orange
This provenance tracking is particularly valuable for creative workflows where you're exploring variations and want to always know exactly what inputs produced each output.
How Persistence Works
| Environment | User Status | Persistence |
|---|---|---|
| Local | Not logged in | ✅ Saved as "local" user |
| Local | HF logged in | ✅ Saved under your HF username |
When running locally, your data is stored in a SQLite database at ~/.cache/huggingface/daggr/sessions.db.
The persist_key Parameter
By default, the persist_key is derived from your graph's name:
Graph(name="My Podcast Generator") # persist_key = "my_podcast_generator"
If you later rename your app but want to keep the existing saved data, set persist_key explicitly:
Graph(name="Podcast Generator v2", persist_key="my_podcast_generator")
Disabling Persistence
For scratch workflows or demos where you don't want data saved:
Graph(name="Quick Demo", persist_key=False)
This disables all persistence—no sheets UI, no saved state.
Hugging Face Authentication
Daggr automatically uses your local Hugging Face token for both GradioNode and InferenceNode. This enables:
- ZeroGPU quota tracking: Your HF token is sent to Gradio Spaces running on ZeroGPU, so your usage is tracked against your account's quota
- Private Spaces access: Connect to private Gradio Spaces you have access to
- Gated models: Use gated models on Hugging Face that require accepting terms of service
To log in with your Hugging Face account:
pip install huggingface_hub
hf auth login
You'll be prompted to enter your token, which you can find at https://huggingface.co/settings/tokens.
Once logged in, the token is saved locally and daggr will automatically use it for all GradioNode and InferenceNode calls—no additional configuration needed.
Alternatively, you can set the HF_TOKEN environment variable directly:
export HF_TOKEN=hf_xxxxx
LLM-Friendly Error Messages
Daggr is designed to be LLM-friendly, making it easy for AI coding assistants to generate and debug workflows.
When you (or an LLM) make a mistake, Daggr provides detailed, actionable error messages with suggestions:
Invalid API endpoint:
ValueError: API endpoint '/infer' not found in 'hf-applications/background-removal'.
Available endpoints: ['/image', '/text', '/png']. Did you mean '/image'?
Typo in parameter name:
ValueError: Invalid parameter(s) {'promt'} for endpoint '/generate_image' in
'hf-applications/Z-Image-Turbo'. Did you mean: 'promt' -> 'prompt'?
Valid parameters: {'width', 'height', 'seed', 'prompt'}
Missing required parameter:
ValueError: Missing required parameter(s) {'prompt'} for endpoint '/generate_image'
in 'hf-applications/Z-Image-Turbo'. These parameters have no default values.
Invalid output port reference:
ValueError: Output port 'img' not found on node 'Z-Image-Turbo'.
Available outputs: image. Did you mean 'image'?
Invalid function parameter:
ValueError: Invalid input(s) {'toppic'} for function 'generate_dialogue'.
Did you mean: 'toppic' -> 'topic'? Valid parameters: {'topic', 'host_voice', 'guest_voice'}
Invalid model name:
ValueError: Model 'meta-llama/nonexistent-model' not found on Hugging Face Hub.
Please check the model name is correct (format: 'username/model-name').
These errors make it easy for LLMs to understand what went wrong and fix the generated code automatically, enabling a smoother AI-assisted development experience.
Discovering Output Formats
When building workflows, LLMs can use .test() to discover a node's actual output format:
# LLM wants to understand what whisper returns
whisper = InferenceNode("openai/whisper-large-v3", inputs={"audio": gr.Audio()})
result = whisper.test(audio="sample.wav")
# Returns: {"text": "Hello, how are you?"}
This helps LLMs:
- Understand the structure of node outputs
- Apply
postprocessfunctions to extract specific values - Create intermediate
FnNodes to transform data between nodes
For example, if a node returns multiple values but you only need one:
# After discovering the output format with .test()
bg_remover = GradioNode(
"hf-applications/background-removal",
api_name="/image",
inputs={"image": some_image.output},
postprocess=lambda original, final: final, # Keep only the second output
outputs={"image": gr.Image()},
)
Running Locally
While in our examples above, we've seen how Daggr works with remote Gradio Spaces and Hugging Face Inference Providers, it's also well-suited for completely local, offline workflows.
Automatic Local Execution
The easiest way to run a Space locally is to set run_locally=True on any GradioNode. Daggr will automatically clone the Space, install dependencies in an isolated virtual environment, and launch the Gradio app:
from daggr import GradioNode, Graph
import gradio as gr
# Automatically clone and run the Space locally
background_remover = GradioNode(
"hf-applications/background-removal",
api_name="/image",
run_locally=True, # Run locally instead of calling the remote API
inputs={"image": gr.Image(label="Input Image")},
outputs={"final_image": gr.Image(label="Output")},
)
graph = Graph(name="Local Background Removal", nodes=[background_remover])
graph.launch()
On first run, daggr will:
- Clone the Space repository to
~/.cache/huggingface/daggr/spaces/ - Create an isolated virtual environment with the Space's dependencies
- Launch the Gradio app on an available port
- Connect to it automatically
Subsequent runs reuse the cached clone and venv, making startup much faster.
Graceful Fallback
If local execution fails (missing dependencies, GPU requirements, etc.), daggr automatically falls back to the remote API and prints helpful guidance:
⚠️ Local execution failed for 'owner/space-name'
Reason: Failed to install dependencies
Logs: ~/.cache/huggingface/daggr/logs/owner_space-name_pip_install_2026-01-27.log
Falling back to remote API...
To disable fallback and see the full error (useful for debugging):
export DAGGR_LOCAL_NO_FALLBACK=1
Environment Variables
| Variable | Default | Description |
|---|---|---|
DAGGR_LOCAL_TIMEOUT |
120 |
Seconds to wait for the app to start |
DAGGR_LOCAL_VERBOSE |
0 |
Set to 1 to show app stdout/stderr |
DAGGR_LOCAL_NO_FALLBACK |
0 |
Set to 1 to disable fallback to remote |
DAGGR_UPDATE_SPACES |
0 |
Set to 1 to re-clone cached Spaces |
GRADIO_SERVER_NAME |
127.0.0.1 |
Host to bind to. Set to 0.0.0.0 on HF Spaces |
GRADIO_SERVER_PORT |
7860 |
Port to bind to |
Manual Local URL
You can also run a Gradio app yourself and point to it directly:
from daggr import GradioNode, Graph
import gradio as gr
# Connect to a Gradio app you're running locally
local_model = GradioNode(
"http://localhost:7860", # Local URL instead of Space ID
api_name="/predict",
inputs={"text": gr.Textbox(label="Input")},
outputs={"result": gr.Textbox(label="Output")},
)
graph = Graph(name="Local Workflow", nodes=[local_model])
graph.launch()
This approach lets you run your entire workflow offline, use custom or fine-tuned models, and avoid API rate limits.
API Access
Daggr workflows can be called programmatically via REST API, making it easy to integrate workflows into other applications or run automated tests.
Discovering the API Schema
First, get the API schema to see available inputs and outputs:
curl http://localhost:7860/api/schema
Response:
{
"subgraphs": [
{
"id": "main",
"inputs": [
{"node": "image_gen", "port": "prompt", "type": "textbox", "id": "image_gen__prompt"}
],
"outputs": [
{"node": "background_remover", "port": "image", "type": "image"}
]
}
]
}
Calling the Workflow
Execute the entire workflow by POSTing inputs to /api/call:
curl -X POST http://localhost:7860/api/call \
-H "Content-Type: application/json" \
-d '{"inputs": {"image_gen__prompt": "A mountain landscape"}}'
Response:
{
"outputs": {
"background_remover": {
"image": "/file/path/to/output.png"
}
}
}
Input keys follow the format {node_name}__{port_name} (with spaces/dashes replaced by underscores).
Disconnected Subgraphs
If your workflow has multiple disconnected subgraphs, use /api/call/{subgraph_id}:
# List available subgraphs
curl http://localhost:7860/api/schema
# Call a specific subgraph
curl -X POST http://localhost:7860/api/call/subgraph_0 \
-H "Content-Type: application/json" \
-d '{"inputs": {...}}'
Python Example
import requests
# Get schema
schema = requests.get("http://localhost:7860/api/schema").json()
# Execute workflow
response = requests.post(
"http://localhost:7860/api/call",
json={"inputs": {"my_node__text": "Hello world"}}
)
outputs = response.json()["outputs"]
Hot Reload Mode
During development, you can use the daggr CLI to run your app with automatic hot reloading. When you make changes to your Python file or its dependencies, the app automatically restarts:
daggr examples/01_quickstart.py
This is much faster than manually stopping and restarting your app each time you make a change.
CLI Options
daggr <script> [options]
| Option | Description |
|---|---|
--host |
Host to bind to (default: 127.0.0.1) |
--port |
Port to bind to (default: 7860) |
--no-reload |
Disable auto-reload |
--no-watch-daggr |
Don't watch daggr source for changes |
What Gets Watched
By default, the CLI watches for changes in:
- Your script file and its directory
- Local imports from your script
- The daggr source code itself (useful when developing daggr)
To disable watching the daggr source (e.g., in production-like testing):
daggr examples/01_quickstart.py --no-watch-daggr
API Caching
To speed up reloads, daggr caches Gradio Space API info in ~/.cache/huggingface/daggr/. This means:
- First run: Connects to each Gradio Space to fetch API info (cached to disk)
- Subsequent reloads: Loads from cache, no network calls needed
If you change a Space's API or encounter stale cache issues, clear the cache:
rm -rf ~/.cache/huggingface/daggr
When to Use Hot Reload
Use daggr <script> when you're actively developing and want instant feedback on changes.
Use python <script> when you want the standard behavior (no file watching, direct execution).
Beta Status
[!WARNING] Daggr is in active development. APIs may change between versions, and while we persist workflow state locally, data loss is possible during updates. We recommend not relying on daggr for production-critical workflows yet. Please report issues if you encounter bugs!
Development
pip install -e ".[dev]"
ruff check --fix --select I && ruff format
License
MIT License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file daggr-0.5.0-py3-none-any.whl.
File metadata
- Download URL: daggr-0.5.0-py3-none-any.whl
- Upload date:
- Size: 1.5 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.2.0 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
df8b5a1b9e84567144362349caa933fc154f13a1b4648ef8c91b7759cfbc229f
|
|
| MD5 |
f6276f7a513864a206e0a67f25557602
|
|
| BLAKE2b-256 |
fd8f90d7954d368d62607a8aae0bcaf4d10c692ff20ac5bca78904d2ab904915
|
Provenance
The following attestation bundles were made for daggr-0.5.0-py3-none-any.whl:
Publisher:
publish.yml on gradio-app/daggr
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
daggr-0.5.0-py3-none-any.whl -
Subject digest:
df8b5a1b9e84567144362349caa933fc154f13a1b4648ef8c91b7759cfbc229f - Sigstore transparency entry: 869434160
- Sigstore integration time:
-
Permalink:
gradio-app/daggr@f7097b6d0985eadc10ae783d158a761352558413 -
Branch / Tag:
refs/heads/main - Owner: https://github.com/gradio-app
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@f7097b6d0985eadc10ae783d158a761352558413 -
Trigger Event:
push
-
Statement type:







