Making it easier to use SEC filings.

Project description



datamule
A python package to make using SEC filings easier. Integrated with datamule's APIs and datasets.
features
current:
- monitor edgar for new filings
- parse textual filings into simplified html, interactive html, or structured json.
- download sec filings quickly and easily
- download datasets such as every MD&A from 2024 or every 2024 10K converted to structured json
installation
pip install datamule
quickstart:
import datamule as dm
downloader = dm.Downloader()
downloader.download_using_api(form='10-K',ticker='AAPL')
documentation
indexer
indexer = dm.Indexer()
indexer.run() constructs the locations of filings for the downloader and stores it to 'data/submissions_index.csv'. If download is set to True, the indexer downloads the locations using the prebuilt indices from Dropbox. The prebuilt indices are typically updated every few days.
It uses the submissions endpoint, and submissions archive endpoint.
TODO: add indexer run option using EFTS endpoint
indexer.run(download=True)
indexer.watch() returns True when new filings are posted to edgar.
It uses the EFTS endpoint.
watching all companies and forms
print("Monitoring SEC EDGAR for changes...")
changed_bool = indexer.watch(1,silent=False)
if changed_bool:
print("New filing detected!")
watching specific companies and forms
print("Monitoring SEC EDGAR for changes...")
changed_bool = indexer.watch(1,silent=False,cik=['0001267602','0001318605'],form=['3','S-8 POS'])
if changed_bool:
print("New filing detected!")
TODO: add args for company and ticker.
downloader
downloader = dm.Downloader()
downloads and downloads_using_api
downloader.download() downloads filings using the indices.
# Example 1: Download all 10-K filings for Tesla using CIK
downloader.download(form='10-K', cik='1318605', output_dir='filings')
# Example 2: Download 10-K filings for Tesla and META using CIK
downloader.download(form='10-K', cik=['1318605','1326801'], output_dir='filings')
# Example 3: Download 10-K filings for Tesla using ticker
downloader.download(form='10-K', ticker='TSLA', output_dir='filings')
# Example 4: Download 10-K filings for Tesla and META using ticker
downloader.download(form='10-K', ticker=['TSLA','META'], output_dir='filings')
# Example 5: Download every form 3 for a specific date
downloader.download(form ='3', date='2024-05-21', output_dir='filings')
# Example 6: Download every 10K for a year
downloader.download(form='10-K', date=('2024-01-01', '2024-12-31'), output_dir='filings')
# Example 7: Download every form 4 for a list of dates
downloader.download(form = '4',date=['2024-01-01', '2024-12-31'], output_dir='filings')
downloader.download_using_api() downloads filings using the datamule API instead. For more information look at SEC Router.
It uses the datamule sec router endpoint.
downloader.download_using_api(form='10-K',ticker='AAPL')
Both functions operate mostly the same. If return_urls is set to True, returns filing primary document urls instead of downloading them. If human_readable = True, it will download human readable versions of the filings. For more information look at the Human Readable Jupyter Notebook
download_datasets
downloader.download_dataset('10K')
downloader.download_dataset('MDA')
Need a better way to store datasets, as I'm running out of storage. Currently stored on Dropbox 2gb free tier.
parsing
Uses endpoint: https://jgfriedman99.pythonanywhere.com/parse_url with params url and return_type. Current endpoint can be slow. If it's too slow for your use-case, please contact me.
simplified html
simplified_html = dm.parse_textual_filing(url='https://www.sec.gov/Archives/edgar/data/1318605/000095017022000796/tsla-20211231.htm',return_type='simplify')

interactive html
interactive_html = dm.parse_textual_filing(url='https://www.sec.gov/Archives/edgar/data/1318605/000095017022000796/tsla-20211231.htm',return_type='interactive')

json
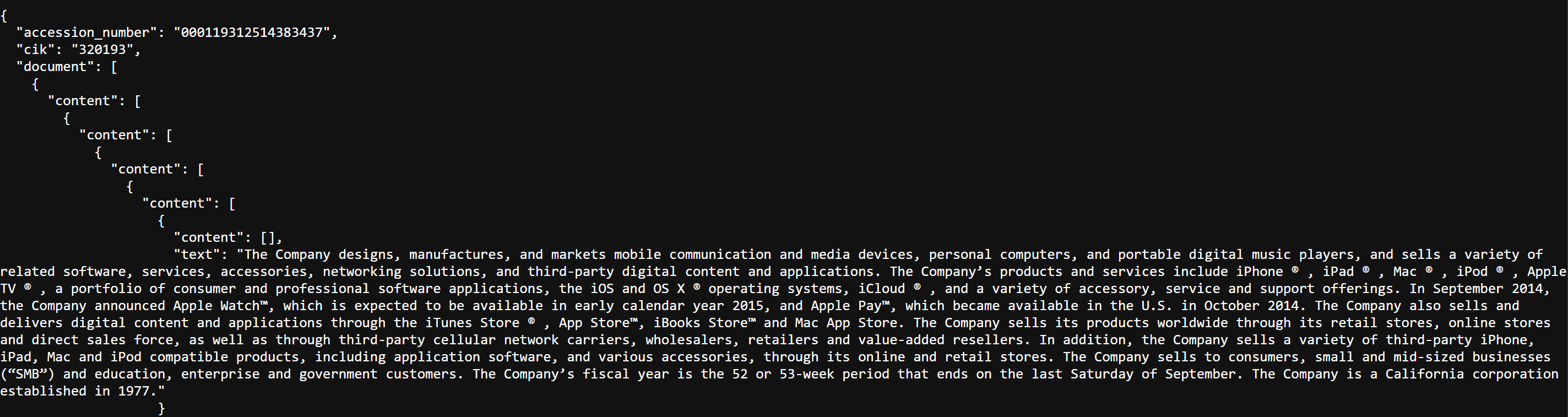
d = dm.parse_textual_filing(url='https://www.sec.gov/Archives/edgar/data/1318605/000095017022000796/tsla-20211231.htm',return_type='json')
TODO
- standardize accession number to not include '-'. Currently db does not have '-' but submissions_index.csv does.
- add code to convert parsed json to interactive html
- add mulebot
Update Log
9/16/24 v0.26
- added indexer.watch(interval,cik,form) to monitor when EDGAR updates. v0.25
- added human_readable option to download, and download_using_api.
9/15/24
- fixed downloading filings overwriting each other due to same name.
9/14/24
- added support for parser API
9/13/24
- added download_datasets
- added option to download indices
- added support for jupyter notebooks
9/9/24
- added download_using_api(self, output_dir, **kwargs). No indices required.
9/8/24
- Added integration with datamule's SEC Router API
9/7/24
- Simplified indices approach
- Switched from pandas to polar. Loading indices now takes under 500 milliseconds.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file datamule-0.26.tar.gz.
File metadata
- Download URL: datamule-0.26.tar.gz
- Upload date:
- Size: 13.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c242230245f497bfd8f177e9fdc13fdf2ff7c5c671dc1f81b8adf74cc25b82f4
|
|
| MD5 |
806964e8f25d4aff141ef08eb2c389b3
|
|
| BLAKE2b-256 |
d7de5955b38c6c6c114d463718af73373bee8f00476da0415b793b62e450cbdc
|
File details
Details for the file datamule-0.26-py3-none-any.whl.
File metadata
- Download URL: datamule-0.26-py3-none-any.whl
- Upload date:
- Size: 13.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.0 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4c2c7664b3c9286ac7589f6b1949e7a0ffa7df6f4e37b2f1b157a9b6883a6978
|
|
| MD5 |
78d08fecc7fa88645fb6671659e217e3
|
|
| BLAKE2b-256 |
7f8ddcddf9288de6909246251b3eb0ee4c0926f4c5821e33f20362131e7187a7
|







