Privacy-first LLM observability and budget control — full AI cost visibility with zero prompt storage.

Project description
DoCoreAI
The Privacy-First AI Cost & Governance Platform
🚧 Prototype Stage — Built on 17 months of research and validated against waste patterns observed across 20+ enterprise AI engagements. Closed source from v2.0. SOC2 certification in progress. Early adopters and design partners welcome.




The Problem Enterprise AI Teams Face Today
Your team ships an AI feature. Usage grows. Then one of two things happens.
Option A — You log everything. Prompts, responses, full request bodies. Now your compliance team is blocking the rollout. Legal wants a data retention policy. Security calls it a liability. The AI pilot stalls.
Option B — You skip logging. No compliance risk, but now you're flying blind. Costs spike overnight with no warning. A single bad deployment burns through the monthly budget by Tuesday. There's no audit trail, no governance, no way to explain the bill.
And even when logging is solved, the spending problem remains. LLM costs do not self-regulate. Without active budget control, a traffic surge at 10 AM can exhaust the entire day's budget by noon — leaving your service unavailable for the remaining 14 hours. There are no native guardrails in any LLM provider SDK. No pacing, no prediction, no automatic intervention. You either overspend or you build all of that yourself.
Enterprise AI teams have been forced to choose between privacy and visibility — and then left to solve cost control entirely on their own. DoCoreAI eliminates all three problems.
What DoCoreAI Does
Your office pays the electricity bill based on peak circuit capacity —
not what you actually consumed. Most LLM deployments work the same
way. The default max_tokens ceiling is set high as a safety net, and
you pay for every token up to that ceiling whether the response needed
it or not. The waste is silent, automatic, and compounds with every
request.
DoCoreAI sits between your application and any LLM provider — OpenAI, Anthropic, Google, Groq, AWS Bedrock, Ollama — and acts as an autonomous cost and governance layer. It learns your actual usage patterns, predicts what each request genuinely needs, replaces the wasteful ceiling with a precise prediction, and paces your budget across the full day. Your prompts never leave your network. Only cost and token metadata is aggregated — nothing sensitive, ever.
Projected outcome: 40–70% reduction in LLM spend, based on token waste patterns observed across 20+ enterprise AI deployments. Enterprise pilots will validate this at scale.
See It in Action

Architecture — Privacy by Design
DoCoreAI runs as a sidecar in the same Python environment as your
application. It monkey-patches all active LLM SDK calls automatically
at startup — no imports, no wrappers, no changes to your existing
code. Every request passes through governance checks, token
prediction, budget validation, pacing adjustment, and soft limit
injection before the LLM call is made. After the response arrives,
actuals are compared to predictions and fed back into the learning
loop. Your application sees none of this. It just gets the response.
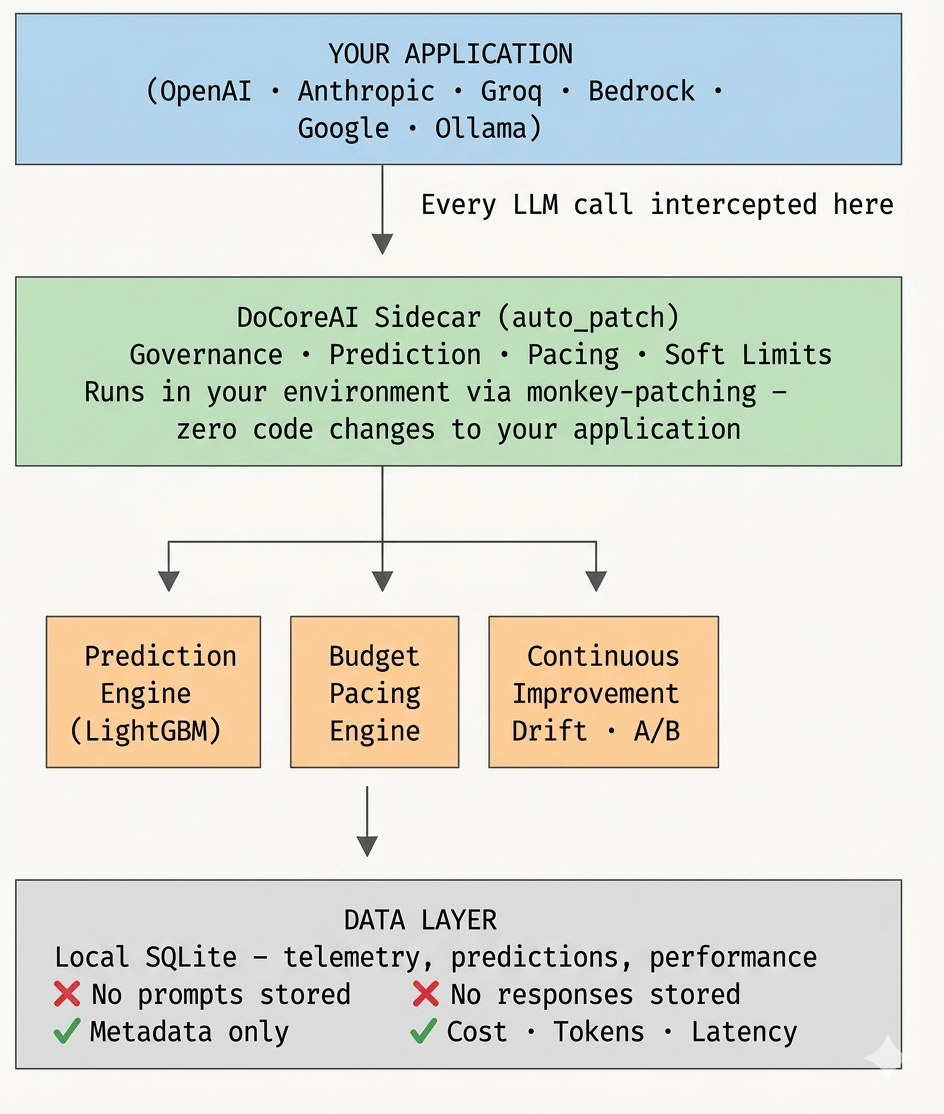
Why DoCoreAI Is an Agentic Platform
Most observability tools watch and report. DoCoreAI watches and acts.
Multi-step reasoning. Budget decisions weigh spend rate, prediction accuracy, model drift, team quotas, and policy rules simultaneously — not a single threshold trigger.
Autonomous task execution. The pacing engine, soft limit injector, auto-retrain triggers, and governance blocks all fire without human approval, in real time, on every request.
Predictive budget management. DoCoreAI learns your historical spending patterns over 30 days, builds a per-hour prediction model, distributes your budget intelligently, and auto-corrects when actual usage deviates from the learned baseline.
Continuous self-improvement. When prediction accuracy degrades, the system detects drift, retrains the LightGBM model on recent telemetry, runs an A/B test against the previous champion, and promotes the better model automatically — all without any action from your team.
How the Cost Reduction Works
The default max_tokens on most LLM calls is set to 2,000 or higher —
a safe ceiling, not a real estimate. Most responses need a fraction of
that. You pay for the ceiling.
DoCoreAI replaces that ceiling with a prediction.
 At 30,000 requests per month, that single optimisation saves
approximately $990/month — before pacing, soft limits, or governance
kick in.
At 30,000 requests per month, that single optimisation saves
approximately $990/month — before pacing, soft limits, or governance
kick in.
Quick Start
Requirements: Python 3.12+ · pip · A free org token from docoreai.com
Supported platforms: Actively developed and tested on Windows.
- macOS and Linux should work without issues — the codebase is pure Python — but has not yet been formally tested. Please report any platform issues at docoreai.com/docs.
Step 1 — Install DoCoreAI in the same environment as your application:
pip install docoreai
Step 2 — Generate your org token at docoreai.com and configure DoCoreAI:
docoreai config
Step 3 — Start DoCoreAI alongside your application:
docoreai start
DoCoreAI automatically intercepts all LLM SDK calls in your environment. No changes to your application code are required.
What you see in your terminal confirming it's working:
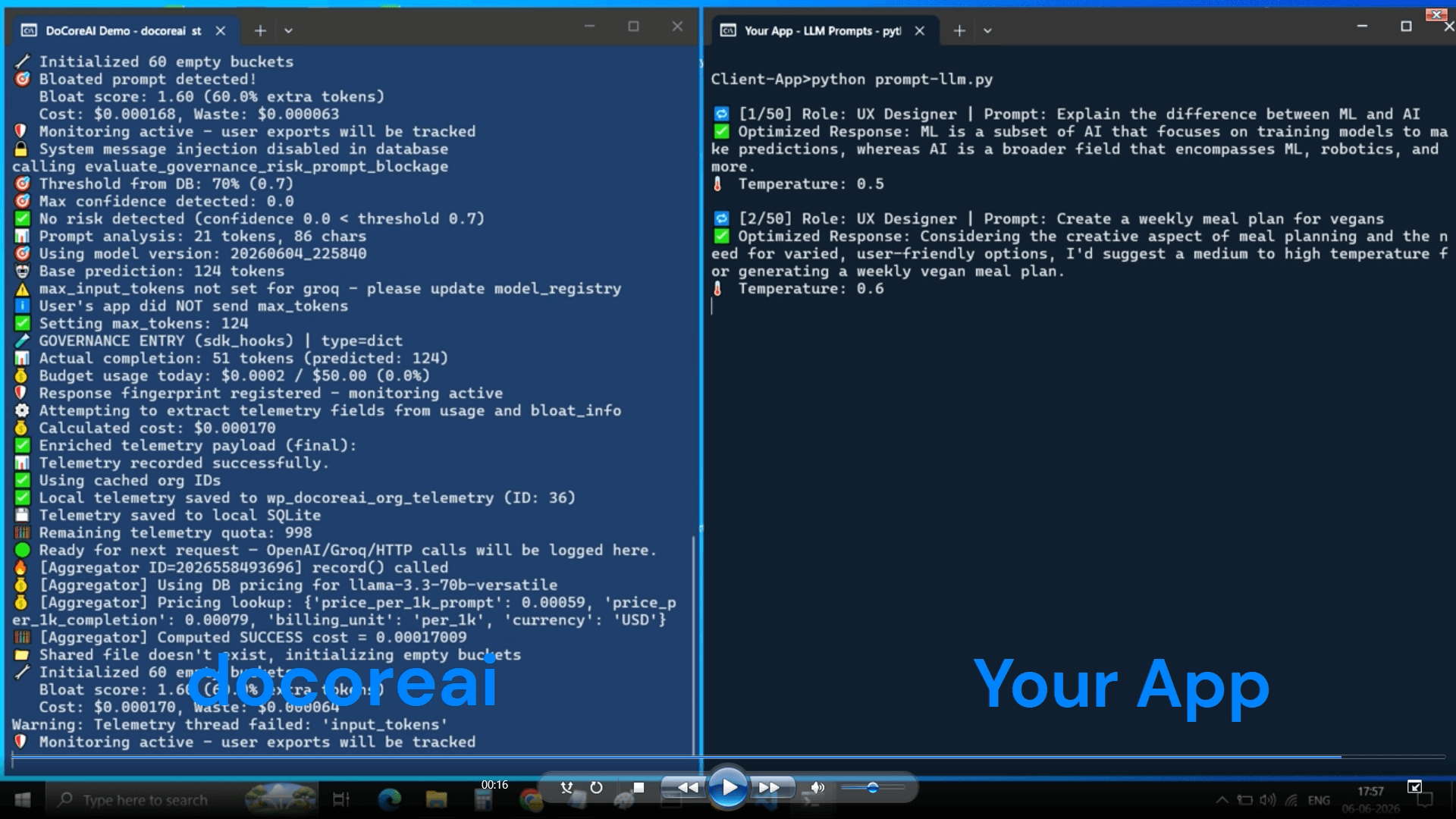
No prompt content. No response content. Just the signal that matters.
To stop DoCoreAI:
Ctrl+C
# Graceful shutdown — active requests complete before exit
What the Dashboard Will Show
🔧 The cloud dashboard is under active development. The metrics below reflect what is being built toward. Local telemetry is fully operational today.
For the engineering manager or CTO reviewing AI spend:
- Daily cost vs. budget — real-time spend curve against your set limit, by hour
- Savings percentage — projected vs. actual token consumption across all providers
- Budget pace status — on track, ahead, or over pace, with throttling events logged
- Provider breakdown — cost split across OpenAI, Anthropic, Groq, and others
For the developer monitoring prediction quality:
- Prediction accuracy (MAE) — mean absolute error across recent requests, trending over time
- Cutoff rate — percentage of responses that reached the token ceiling, indicating under-prediction
- Drift events — when the prediction model degraded and what triggered retraining
- A/B test results — champion vs. challenger model performance, promotion or rollback decisions
Real-World Use Cases
Preventing budget exhaustion — SaaS platforms A marketing email triggers a customer surge. Without pacing, the daily budget is gone by 11 AM and the service is blocked for 13 hours. DoCoreAI detects the spike, applies graduated throttling, and keeps the service running for the full 24 hours on the same budget.
Handling seasonal traffic — e-commerce Black Friday volume runs 5× normal. DoCoreAI's peak-aware pacing strategy recognises the anomaly, allows temporary over-pace during the critical window, and compensates during off-hours — keeping spend within the planned monthly envelope.
Enterprise compliance — regulated industries A healthcare or financial services team needs full AI observability but cannot log prompt content. DoCoreAI's metadata-only telemetry delivers complete cost and governance visibility with zero prompt retention — nothing that touches a compliance boundary ever leaves the local environment.
Privacy vs. Visibility — How DoCoreAI Solves Both
| Capability | Traditional APM | DoCoreAI |
|---|---|---|
| Prompt storage | ✗ Required | ✓ Never stored |
| Response storage | ✗ Required | ✓ Never stored |
| Cost tracking | ✓ | ✓ |
| Token-level visibility | Partial | ✓ Per request |
| Autonomous budget control | ✗ | ✓ |
| Intelligent pacing | ✗ | ✓ |
| PII detection at edge | ✗ | ✓ |
| Multi-LLM support | Partial | ✓ |
| Compliance-ready architecture | ✗ | ✓ |
| Closed source / IP protected | ✗ | ✓ from v2.0 |
| SOC2 | Varies | In progress |
Supported Providers
Works out of the box with any combination:
- OpenAI — GPT-4, GPT-4 Turbo, GPT-3.5, and all variants
- Anthropic — Claude 3 family and newer
- Google — Gemini Pro and Gemini Ultra
- AWS Bedrock — all supported foundation models
- Groq — Llama, Mixtral, and Groq-hosted models
- Ollama — local model deployments
No provider-specific configuration needed. DoCoreAI detects and wraps all active SDKs automatically at startup.
Installation
# Install
pip install docoreai
# Configure with your org token (generate at docoreai.com)
docoreai config
# Start
docoreai start
# Stop
Ctrl+C
v2.1.0 is the current release. This is prototype-stage software. APIs may evolve between releases. Production use is welcomed — real usage data helps us improve the prediction models faster. Report issues and get support at docoreai.com/docs.
Documentation
Full documentation, configuration reference, and integration guides:
Covers: auto-retrain configuration · A/B testing · soft limits · pacing engine · budget modes · retention policies · troubleshooting · developer API reference.
Design Partner Program
We are actively seeking 3–5 enterprise design partners for no-cost pilots with white-glove founder support. If your team is running LLMs in production and wrestling with cost visibility or compliance constraints, this is built for you.
What design partners get: direct founder access · custom configuration support · early access to enterprise features · input into the product roadmap.
What we ask in return: honest feedback · real usage data · a willingness to co-develop the enterprise use case with us.
Built With
Python · FastAPI · LightGBM · SQLite · scikit-learn · Chart.js
DoCoreAI — because your compliance team and your engineering team should both be able to say yes.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file docoreai-2.1.0.tar.gz.
File metadata
- Download URL: docoreai-2.1.0.tar.gz
- Upload date:
- Size: 222.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b088439a5948808d8eb3201a91f089fc2c0d4cae14ec647cc46a7cb4400830aa
|
|
| MD5 |
2a99331211e645db47a9411fcaa1b5bd
|
|
| BLAKE2b-256 |
0839547e376303cc2c9ced52a02f911725b9b7d6d812caca4ed1591ad475825a
|
File details
Details for the file docoreai-2.1.0-py3-none-any.whl.
File metadata
- Download URL: docoreai-2.1.0-py3-none-any.whl
- Upload date:
- Size: 269.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
197713331723189e02fe2ba5e7e608715ae4a3d526bbbf6f41d42b99b5ba40e9
|
|
| MD5 |
6d265b2121d3fea0c6722c9f39c60eda
|
|
| BLAKE2b-256 |
4b9d97dd0c3b786fce375adac7b9e68ea9ac6655e3c93a0f70e2fe1185bde8b4
|







