Deterministic architectural drift detection for AI-accelerated Python repositories through cross-file coherence analysis

Project description
Drift — Finds the architecture erosion that AI-generated code silently introduces













Repo:
sauremilk/drift· Package:drift-analyzer· Command:drift· Requires: Python 3.11+97.3% precision on 263 ground-truth findings across 15 repositories · deterministic · no LLM in pipeline · full study →
Start here
Drift is a deterministic static analyzer that finds the architecture erosion AI-generated code silently introduces: pattern fragmentation, boundary violations, near-duplicate utilities, and structural hotspots that pass tests but weaken the codebase.
It is designed for Python teams that want fast structural feedback in AI-accelerated repositories without adding an LLM to the analysis path.
When code is produced faster than shared conventions evolve, repositories quietly accumulate problems such as:
- error handling implemented several different ways inside the same service
- API modules importing directly from database or infrastructure layers
- AI-generated helpers copied into new files instead of reused
- churn hotspots that keep changing because the structure is unclear
1-minute quickstart
pip install -q drift-analyzer
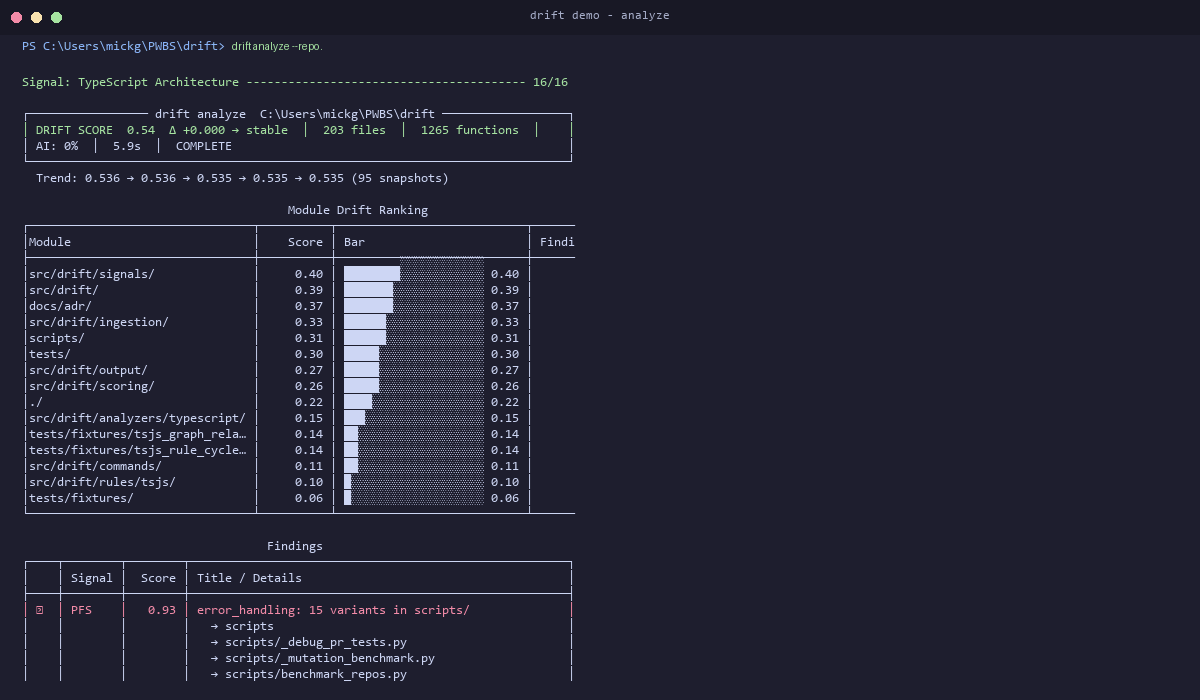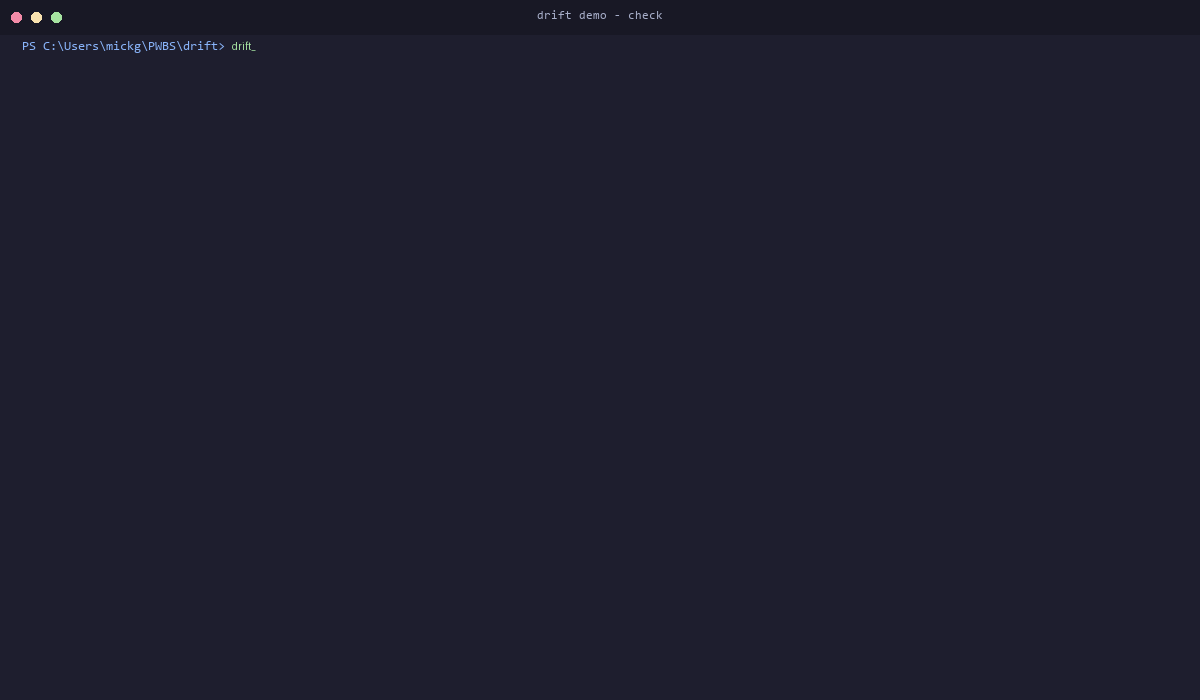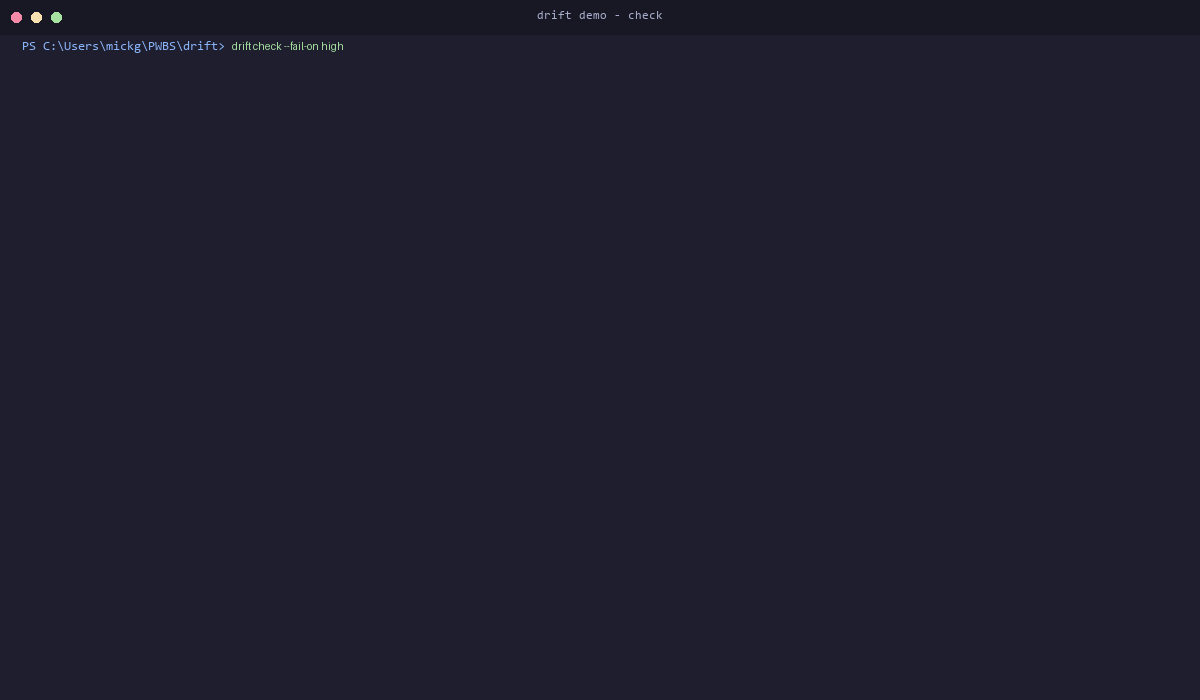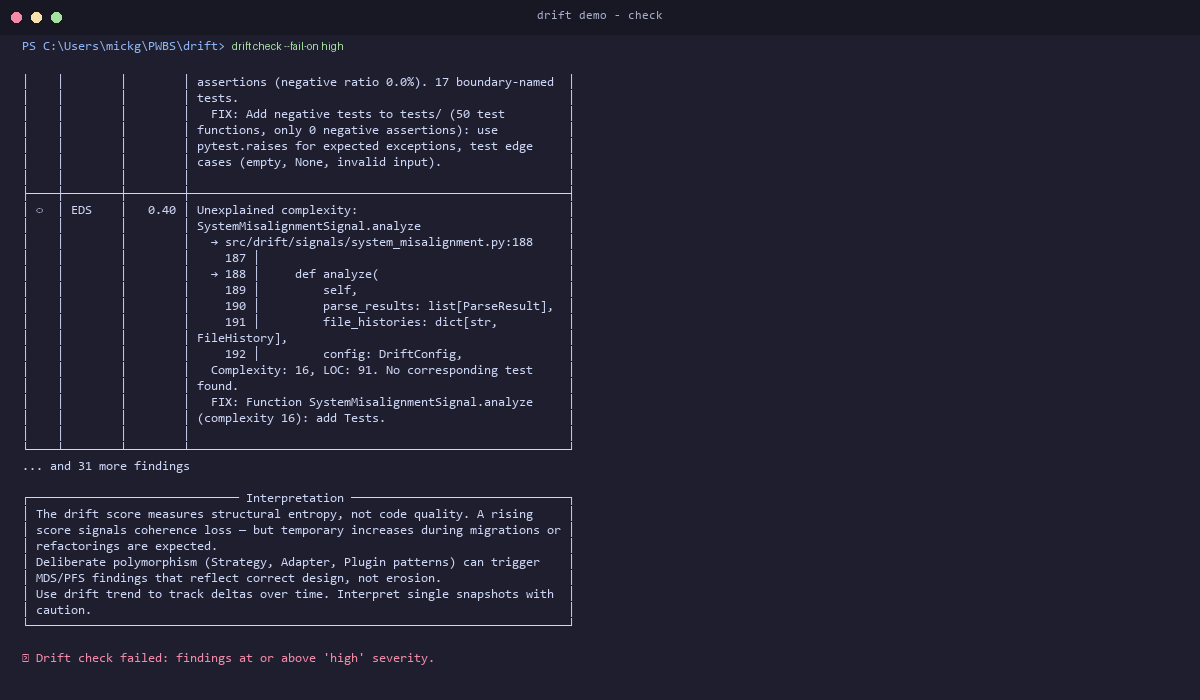
drift analyze --repo .
That gives you a drift score, the hottest modules, and actionable findings in one run.
Example output
DRIFT SCORE 0.52
Top finding: PFS 0.85 Error handling split 4 ways at src/api/routes.py:42
Next action: consolidate variants into one shared pattern
Three good ways to start
- Try it on your repository: start with Quick Start and Configuration.
- Evaluate before rollout: review Example Findings, Trust and Evidence, and Stability and Release Status.
- Work on the project itself: use CONTRIBUTING.md, DEVELOPER.md, and POLICY.md.
Start report-only in CI
- uses: sauremilk/drift@v1
with:
fail-on: none
upload-sarif: "true"
Start report-only first. Tighten to fail-on: high once the team understands the signal quality in its own repo.
Try it on a demo project
git clone https://github.com/sauremilk/drift.git
cd drift/examples/demo-project
pip install -q drift-analyzer
drift analyze --repo .
The demo project contains intentional drift patterns, so you get useful findings immediately.
Why teams use drift
Your linter, type checker, and test suite can tell you whether code is valid. They do not tell you whether the repository is quietly splitting into incompatible patterns across modules.
Drift focuses on that gap:
- Ruff / formatters / type checkers: local correctness and style, not cross-module coherence.
- Semgrep / CodeQL / security scanners: risky flows and policy violations, not architectural consistency.
- Maintainability dashboards: broad quality heuristics, not a drift-specific score with reproducible signal families.
Current public evidence: 15 real-world repositories in the study corpus, 15 scoring signals, and auto-calibration that rebalances weights at runtime. Full study → · Trust & limitations
Use cases
Pattern fragmentation in a connector layer
Problem: A FastAPI service has 4 connectors, each implementing error handling differently — bare except, custom exceptions, retry decorators, and silent fallbacks.
Solution:
drift analyze --repo . --sort-by impact --max-findings 5
Output: PFS finding with score 0.96 — "26 error_handling variants in connectors/" — shows exactly which files diverge and suggests consolidation.
Architecture boundary violation in a monorepo
Problem: A database model file imports directly from the API layer, creating a circular dependency that breaks test isolation.
Solution:
drift check --fail-on high
Output: AVS finding — "DB import in API layer at src/api/auth.py:18" — blocks the CI pipeline until the import direction is fixed.
Duplicate utility code from AI-generated scaffolding
Problem: AI code generation created 6 identical _run_async() helper functions across separate task files instead of finding the existing shared utility.
Solution:
drift analyze --repo . --format json | jq '.findings[] | select(.signal=="MDS")'
Output: MDS findings listing all 6 locations with similarity scores ≥ 0.95, enabling a single extract-to-shared-module refactoring.
Setup and rollout options
Full GitHub Action (recommended: start report-only)
name: Drift
on: [push, pull_request]
jobs:
drift:
runs-on: ubuntu-latest
permissions:
contents: read
security-events: write
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- uses: sauremilk/drift@v1
with:
fail-on: none # report findings without blocking CI
upload-sarif: "true" # findings appear as PR annotations
Once the team has reviewed findings for a few sprints, tighten the gate:
- uses: sauremilk/drift@v1
with:
fail-on: high # block only high-severity findings
upload-sarif: "true"
CI gate (local)
drift check --fail-on none # report-only
drift check --fail-on high # block on high-severity findings
pre-commit hook
The fastest way to add drift to your workflow:
# .pre-commit-config.yaml
repos:
- repo: https://github.com/sauremilk/drift
rev: v0.10.2
hooks:
- id: drift-check # blocks on high-severity findings
# - id: drift-report # report-only alternative (start here)
Or use a local hook if you already have drift installed:
# .pre-commit-config.yaml
repos:
- repo: local
hooks:
- id: drift
name: drift
entry: drift check --fail-on high
language: system
pass_filenames: false
always_run: true
More setup paths:
If you want example findings before integrating, start with docs-site/product/example-findings.md.
What you get
╭─ drift analyze myproject/ ──────────────────────────────────────────────────╮
│ DRIFT SCORE 0.52 │ 87 files │ 412 functions │ AI: 34% │ 2.1s │
╰──────────────────────────────────────────────────────────────────────────────╯
Module Drift Ranking
Module Score Findings Top Signal
─────────────────────────────────────────────────────────────
src/api/routes/ 0.71 12 PFS 0.85
src/services/auth/ 0.58 7 AVS 0.72
src/db/models/ 0.41 4 MDS 0.61
┌──┬────────┬───────┬──────────────────────────────────────┬──────────────────────┐
│ │ Signal │ Score │ Title │ Location │
├──┼────────┼───────┼──────────────────────────────────────┼──────────────────────┤
│◉ │ PFS │ 0.85 │ Error handling split 4 ways │ src/api/routes.py:42 │
│◉ │ AVS │ 0.72 │ DB import in API layer │ src/api/auth.py:18 │
│○ │ MDS │ 0.61 │ 3 near-identical validators │ src/utils/valid.py │
└──┴────────┴───────┴──────────────────────────────────────┴──────────────────────┘
Drift scores 15 signal families. For the full list, weights, and scoring details, see:
How drift compares
Data sourced from STUDY.md §9 and benchmark_results/.
| Capability | drift | SonarQube | pylint / mypy | jscpd / CPD |
|---|---|---|---|---|
| Pattern Fragmentation across modules | Yes | No | No | No |
| Near-Duplicate Detection | Yes | Partial (text) | No | Yes (text) |
| Architecture Violation signals | Yes | Partial | No | No |
| Temporal / change-history signals | Yes | No | No | No |
| GitHub Code Scanning via SARIF | Yes | Yes | No | No |
| Zero server setup | Yes | No | Partial | Yes |
| TypeScript Support | Optional ¹ | Yes | No | Yes |
¹ Experimental via drift-analyzer[typescript]. Python is the primary target.
Drift is designed to complement linters and security scanners, not replace them. Recommended stack: linter (style) + type checker (types) + drift (coherence) + security scanner (SAST).
Full comparison: STUDY.md §9 — Tool Landscape Comparison
Is drift a good fit?
Drift is a strong fit for:
- Python teams using AI coding tools in repositories where architecture matters
- repositories with 20+ files and recurring refactors across modules
- teams that want deterministic architectural feedback in local runs and CI
Wait or start more cautiously if:
- the repository is tiny and a few findings would dominate the score
- you need bug finding, security review, or type-safety enforcement rather than structural analysis
- Python 3.11+ is not available in your local and CI execution path yet
The safest rollout path is progressive:
- Start with
drift analyzelocally and review the top findings. - Add
drift check --fail-on nonein CI as report-only discipline. - Gate only on
highfindings once the team understands the output. - Ignore generated or vendor code and tune config only after reviewing real findings in your repo.
Recommended guides:
Trust and limitations
Public claims safe to repeat today: Drift is deterministic, benchmarked on 15 real-world repositories in the current study corpus, and uses 15 scoring signals with auto-calibration for runtime weight rebalancing and small-repo noise suppression.
What's limited: Benchmark validation is single-rater; not yet independently replicated. Small repos can be noisy. Temporal signals depend on clone depth. The composite score is orientation, not a verdict.
What's next: Independent external validation, multi-rater ground truth, signal-specific confidence intervals.
Drift is designed to earn trust through determinism and reproducibility:
- no LLMs in the detection pipeline
- reproducible CLI and CI output
- signal-specific interpretation instead of score-only messaging
- explicit benchmarking and known-limitations documentation
Interpreting the score
The drift score measures structural entropy, not code quality. Keep these principles in mind:
- Interpret deltas, not snapshots. Use
drift trendto track changes over time. A single score in isolation has limited meaning. - Temporary increases are expected during migrations. Two coexisting patterns (old and new) will raise PFS/MDS signals. This is the migration happening, not a problem.
- Deliberate polymorphism is not erosion. Strategy, Adapter, and Plugin patterns produce structural similarity that MDS flags as duplication. Findings include a
deliberate_pattern_riskhint — verify intent before acting. - The score rewards reduction, not correctness. Deleting code lowers the score just like refactoring does. Do not optimize for a low score — optimize for understood, intentional structure.
For a detailed discussion of epistemological boundaries (what drift can and cannot see), see STUDY.md §14.
Drift vs. erosion: Without
layer_boundariesindrift.yaml, drift detects emergent drift — structural patterns that diverge without explicit prohibition. With configuredlayer_boundaries, drift additionally performs conformance checking against a defined architecture. Both modes are complementary: drift does not replace dedicated architecture conformance frameworks (e.g. PyTestArch for executable layer rules in pytest), but catches cross-file coherence issues those tools do not model.
Start with the strongest, most actionable findings first. If a signal is noisy for your repository shape, tune or de-emphasize it instead of forcing an early hard gate.
Further reading:
Release status
The PyPI classifier remains Development Status :: 3 - Alpha intentionally.
That is a conservative release signal, not a claim that the core workflow is unusable. The strongest path today is the deterministic Python analysis and report-only CI rollout; some adjacent surfaces remain intentionally marked as experimental.
Current release posture:
- core Python analysis: stable
- CI and SARIF workflow: stable
- TypeScript support: experimental
- embeddings-based parts: optional / experimental
- benchmark methodology: evolving
Full rationale and matrix: Stability and Release Status
Contributing
Drift seeks contributions that increase the credibility of static architecture findings: reproducible cases, better explainability, fewer false alarms, and clearer next actions.
If you run drift on your codebase and get surprising results — good or bad — please open an issue or start a discussion.
New here? Start contributing
- Pick an issue labelled
good first issue git clone https://github.com/sauremilk/drift.git && cd drift && make installmake test-fast— confirm everything passes- Make your change, then open a PR
Typical first contributions:
- Add a ground-truth fixture for a false positive or false negative
- Improve a finding's explanation text to be more actionable
- Write a test for an untested edge case
- Fix or extend signal documentation with a concrete example
What we value most: reproducibility, explainability, false-alarm reduction.
What we deprioritize: new output formats without insight value, comfort features, complexity without analysis improvement.
See CONTRIBUTING.md for the full guide and ROADMAP.md for current priorities.
Documentation map
- Getting Started
- How It Works
- Benchmarking and Trust
- Product Strategy
- Contributor Guide
- Developer Guide
License
MIT. See LICENSE.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file drift_analyzer-1.1.2.tar.gz.
File metadata
- Download URL: drift_analyzer-1.1.2.tar.gz
- Upload date:
- Size: 628.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
986d2843c01943c100c2357635cd34b93bca0e8b0aa25a14d7afa82f99afca30
|
|
| MD5 |
08df3ec859a588ead37e81afb8d74d70
|
|
| BLAKE2b-256 |
8d3a554720d30ca073a747d43609b064ab05bea1ae5a63083dcb7c25585c6cdb
|
File details
Details for the file drift_analyzer-1.1.2-py3-none-any.whl.
File metadata
- Download URL: drift_analyzer-1.1.2-py3-none-any.whl
- Upload date:
- Size: 223.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7ed35fbb2124fba018522a30566051927c4762d906d808810f8946b9f8e7be06
|
|
| MD5 |
24c3f54c32e331aa99f2584e888cd50e
|
|
| BLAKE2b-256 |
ef99ce452023bac3e6833b0405d0b7278cd789730aeda27057db0eb7edfe894c
|







