Differentiable eigenvalue decomposition with JAX — CUDA 12.8 (GPU) build

Project description
Differentiable Generalized Eigenvalue Decomposition


Standalone implementation of differentiable eigenvalue decomposition with CPU (LAPACK) and GPU (cuSOLVER) backends. Extracted from pyscfad.
Wheels on PyPI: https://pypi.org/project/eigh/ — Linux (manylinux_2_28, x86_64) and macOS (arm64 / Apple Silicon), Python 3.10–3.13, compatible with JAX 0.5 through 0.9+ (single forward-compatible binary). macOS x86_64 (Intel) is not shipped: JAX has no jaxlib ≥0.5 for Intel Macs. GPU path (cuSOLVER) is tested locally; CI runs CPU tests only. See Compatibility for the full support matrix.
Features
- Generalized Problems:
A @ V = B @ V @ diag(W), etc. - JAX Integrated: Full support for
jit,vmap,grad, andjvp. - High Performance: Optimized LAPACK (CPU) and cuSOLVER (GPU) kernels.
- Precision:
float32/64andcomplex64/128. - Degeneracy Handling: Configurable
deg_threshfor stable gradients.
Installation & Quick Start
CPU (from PyPI)
pip install eigh
This pulls a prebuilt CPU-only wheel (see Compatibility).
pip install eigh always prefers the matching wheel, so it will not build a
GPU extension even on a GPU node.
GPU (prebuilt wheels)
GPU builds ship as separate package names (same repository, same import eigh), one per CUDA build target. Pick by your cluster's CUDA version:
# Older CUDA clusters (CUDA 12.0+). Forward-compatible: also runs on 12.8+.
# Widest reach (glibc 2.17). This is the right default if unsure.
pip install eigh-cuda120
# Modern CUDA clusters (CUDA 12.8+). Newer toolkit/glibc (2.34, RHEL 9+).
pip install eigh-cuda128
Each pulls a Linux x86_64 wheel with the cuSOLVER kernel compiled in, plus the
matching NVIDIA CUDA 12 runtime libraries and a CUDA-12 JAX. import eigh then
auto-detects the GPU backend.
| Package | Built against | Runs on CUDA | glibc | Pick when |
|---|---|---|---|---|
eigh-cuda120 |
CUDA 12.0 | 12.0 – 12.8+ | 2.17 | older clusters, or unsure (max compatibility) |
eigh-cuda128 |
CUDA 12.8 | 12.8+ | 2.34 | modern clusters wanting the newer toolchain |
Why separate packages? A single normal PyPI package cannot serve a small CPU wheel to CPU users and GPU wheels to GPU users (PyPI wheel-variants are not GA), and one GPU wheel can only target one CUDA version. So CPU users
pip install eigh; GPU users pickeigh-cuda120/eigh-cuda128. All are built from this same repo — this mirrorsjaxlibvsjax-cuda12-plugin.The GPU wheels are built in CI but functionally tested only on real GPU hardware before each release (CI has no GPU). If you rely on one, sanity check on your own device.
GPU (build from source on the cluster)
If you need a CUDA version other than the prebuilt eigh-cuda120 / eigh-cuda128
targets, a custom toolchain, or a platform with no prebuilt wheel, build from
source on the GPU machine:
There is no prebuilt GPU wheel — you compile one on the cluster against its CUDA
12 toolkit. The key flag is --no-build-isolation: it builds the FFI handler
against the jaxlib already in your environment (your cluster's CUDA jaxlib)
instead of pip pulling an isolated CPU jaxlib into a sandbox.
# 0. On the cluster, load CUDA 12 and put nvcc on PATH (module load cuda/12.x ...)
nvcc --version # confirm CUDA 12.x is visible
# 1. Install a CUDA-12 JAX matching the cluster (this provides the CUDA jaxlib)
pip install "jax[cuda12]" # or jax[cuda12-local] to use the system CUDA
# 2. Build eigh FROM SOURCE against that jaxlib, no build isolation
pip install --no-build-isolation "scikit-build-core>=0.8" "nanobind>=1.0.0" cmake ninja
pip install --no-build-isolation --no-binary eigh eigh
# ^ --no-binary forces a source build; CMake auto-detects nvcc and compiles
# the cuSOLVER kernel (look for "CUDA support enabled" in the build log).
# Or from a git checkout:
# pip install --no-build-isolation .
# 3. Verify the GPU backend loaded (no "CUDA backend not available" warning)
python -c "import eigh._core as c; print('cuda:', c._cuda_available)"
If the build prints CUDA not found - GPU support will be disabled, nvcc
wasn't on PATH at build time — fix the CUDA module load and rebuild. See the
CUDA / GPU compatibility notes for version constraints (CUDA 12
only).
Usage Example
import jax
import jax.numpy as jnp
# Gen. eigensolver from PySCFAD
from eigh import eigh, eigh_gen
jax.config.update("jax_enable_x64", True)
# Eigenvalue problem
A = jnp.array([[2., 1.], [1., 2.]])
B = jnp.array([[1., 1], [0.5, 1.]])
w1, v1 = eigh(A)
w2, v2 = eigh_gen(A, B)
# With gradients
grad1 = jax.grad(lambda A: eigh(A)[0].sum())(A)
grad2 = jax.grad(lambda A: eigh_gen(A, B)[0].sum())(A)
print("Eigenvalues:", w1, w2)
print("Eigenvectors:", v1, v2)
print("Gradients computed:", grad1.shape, grad2.shape)
Benchmarks
Forward/backward scaling vs. matrix size, and gradient stability as eigenvalues approach degeneracy — for the JAX eigensolvers in src/jax/. See benchmarks/suite/ for the scripts.
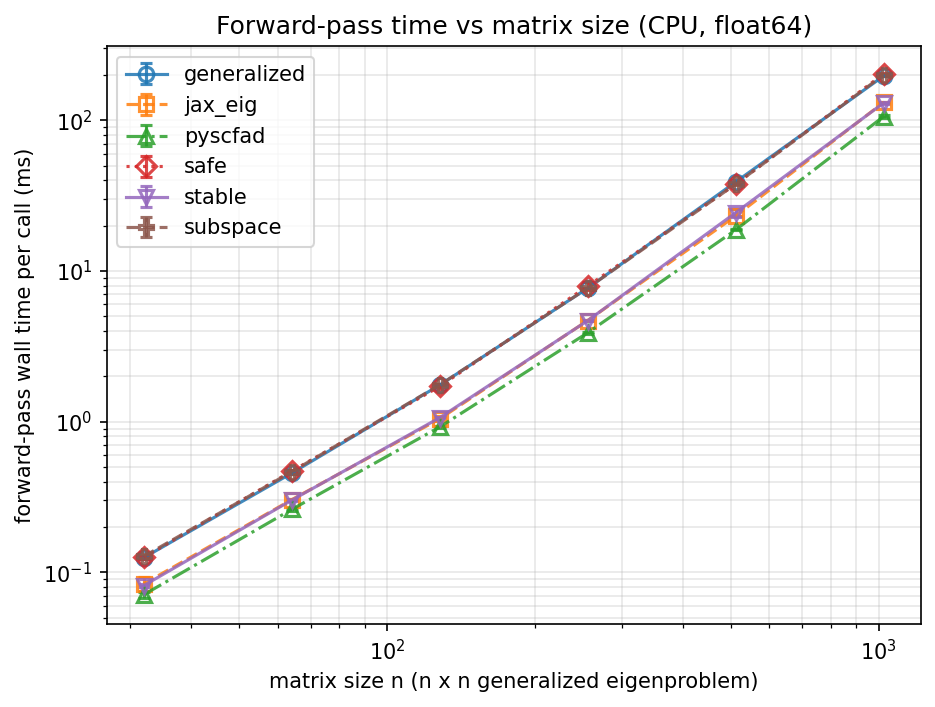
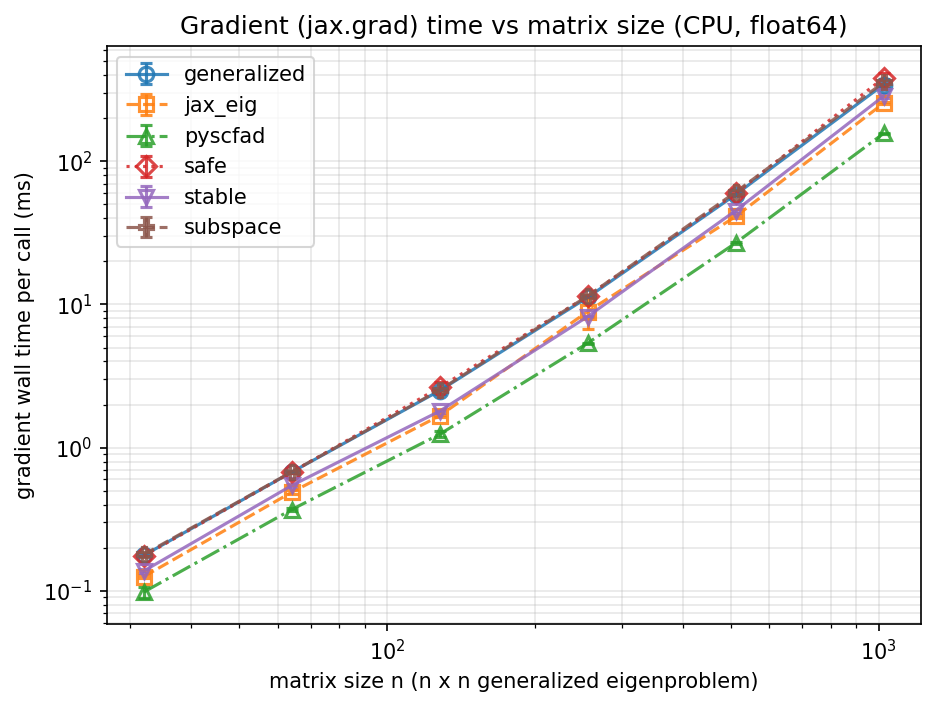
API Reference
eigh(a, b=None, *, lower=True, eigvals_only=False, type=1, deg_thresh=1e-9)Scipy-compatible interface.typesupports 1:A@v=B@v@λ, 2:A@B@v=v@λ, 3:B@A@v=v@λ.eigh_gen(a, b, *, lower=True, itype=1, deg_thresh=1e-9)Lower-level generalized solver.
Degenerate Eigenvalues & Gradients
Individual eigenvalue gradients are ill-defined for degenerate (repeated) eigenvalues. However, symmetric functions (like sum, var, trace) have stable gradients. The deg_thresh parameter (default 1e-9) masks divisions by near-zero gaps to maintain stability.
JAX Eigensolvers (src/jax/)
A collection of differentiable generalized eigensolvers with different strategies for handling degenerate eigenvalues in reverse-mode gradients. Useful for training pipelines where degeneracies are common.
If you just want a working solver, use stable_eigh_pyscfad / stable_eigh_gen_pyscfad from generalized_eigensolver_pyscfad.py. They wrap the fast LAPACK/cuSOLVER kernels with a Lorentzian-broadened custom VJP, so gradients stay stable when eigenvalues are (nearly) degenerate.
On Windows, or if you cannot build the C++ kernels, use stable_generalized_eigh from generalized_eigensolver_stable.py instead — same gradient treatment, pure JAX.
The remaining solvers below are kept for benchmarking and for reproducing prior work; they are not recommended as defaults.
Recommended
| Solver | File | Strategy |
|---|---|---|
stable_eigh_pyscfad / stable_eigh_gen_pyscfad |
generalized_eigensolver_pyscfad.py | LAPACK/cuSOLVER kernels + Lorentzian-broadened VJP [2] |
stable_eigh / stable_generalized_eigh (pure-JAX) |
generalized_eigensolver_stable.py | Pure-JAX Cholesky + Lorentzian-broadened VJP [2] |
Alternative stable solvers
| Solver | File | Strategy | Gradient notes |
|---|---|---|---|
subspace_eigh |
generalized_eigensolver.py | Custom VJP: Lorentzian broadening F/(F²+ε²) [2] |
Stable |
subspace_generalized_eigh |
generalized_eigensolver.py | Symmetry-breaking perturbation + subspace_eigh [2,4] |
Stable |
degen_eigh |
generalized_eigensolver.py | Custom VJP: mask degenerate F_ij by threshold [1,3] |
Stable only for symmetric-subspace losses |
safe_generalized_eigh |
generalized_eigensolver.py | Cholesky + degen_eigh |
Inherits degen_eigh caveat |
Baselines (not gradient-safe at degeneracies)
| Solver | File | Strategy |
|---|---|---|
standard_eig |
generalized_eigensolver.py | scipy.linalg.eigh — non-differentiable reference |
jax_eig |
generalized_eigensolver.py | Plain Cholesky + jnp.linalg.eigh, default VJP |
generalized_eigh |
generalized_eigensolver.py | Symmetrized Cholesky with SPD shift, default VJP |
Compatibility
Windows: no prebuilt wheel. The pure-JAX solvers in src/jax/ (e.g. safe_generalized_eigh, subspace_generalized_eigh, stable_generalized_eigh) work out-of-the-box — pip install jax numpy scipy and import directly from that module. The fast LAPACK/cuSOLVER-backed eigh / eigh_gen kernels (and therefore stable_eigh_pyscfad / stable_eigh_gen_pyscfad) require building from source against a local BLAS/LAPACK.
Python & JAX
The compiled CPU (LAPACK) handler registers through the XLA FFI C API, whose
ABI is stable within XLA_FFI_API_MAJOR == 0. A single wheel built against the
oldest supported jaxlib therefore loads on every newer one — verified working
on jax/jaxlib 0.5.3, 0.6.2, 0.7.0, 0.7.2, 0.8.3, and 0.9.2 (eigh_gen
correct and twice-differentiable on all of them).
| Python | JAX 0.5 / 0.6 | JAX 0.7+ | Wheel shipped |
|---|---|---|---|
| 3.10 | ✅ | — (jax 0.7 dropped 3.10) | cp310 |
| 3.11 | ✅ | ✅ | cp311 |
| 3.12 | ✅ | ✅ | cp312-abi3 |
| 3.13+ | — | ✅ | cp312-abi3 (forward-compatible) |
Why three wheels, not one? nanobind's stable ABI (
abi3) exists only from CPython 3.12, andabi3is forward-compatible only (a 3.12-built wheel runs on 3.12/3.13+, never on 3.10/3.11). So 3.10 and 3.11 get version-specific wheels and 3.12 ships oneabi3wheel that also serves 3.13+.
jaxlib < 0.5 (the pre-FFI custom-call era, e.g. 0.4.x) is not supported.
CUDA / GPU
GPU support uses the classic dense cuSOLVER routines
(cusolverDn{S,D}sygvd, cusolverDn{C,Z}hegvd) and is dispatched through JAX's
GPU FFI under platform="gpu".
| Aspect | Support | Notes |
|---|---|---|
| CUDA major version | CUDA 12 only | JAX ≥0.5 ships only cuda12 plugins (jax[cuda12]). CUDA 11 is not supported — it would require jax[cuda11], dropped in modern JAX. |
| Prebuilt wheels | eigh-cuda120 (CUDA 12.0, glibc 2.17) and eigh-cuda128 (CUDA 12.8, glibc 2.34) |
eigh-cuda120 is forward-compatible to 12.8+ and the safer default; eigh-cuda128 targets modern toolchains. Any CUDA 12.x toolkit can also build from source. |
| cuSOLVER API | CUDA 8+ | The *sygvd/*hegvd dense API is long-stable, so there is no upper CUDA-12 bound from the API surface. |
| Compute capability | nvcc default for the toolkit | No explicit -arch is set; PTX JITs forward to newer GPUs. Set CMAKE_CUDA_ARCHITECTURES to target a specific SM. |
| FFI ABI across JAX | Same MAJOR == 0 stability as CPU |
The GPU handler is forward-compatible across jax 0.5→0.9 just like the CPU one. |
Where the GPU path breaks / what to know:
- Prebuilt GPU wheels:
pip install eigh-cuda120(CUDA 12.0+, the safer default) oreigh-cuda128(CUDA 12.8+), Linux x86_64. The defaultpip install eighis CPU-only — pairing it withjax[cuda12]does not enable GPU, because the CUDA kernel must be compiled into the wheel and the CPU wheel does not contain it. - GPU wheels are built in CI but not GPU-tested there (no GPU runner); CI only checks the extension loads. Verify on real hardware before relying on a release.
- CUDA 11 clusters are unsupported (see table) — use a CUDA 12 module/env.
- For other CUDA versions or platforms, build from source (below). The build
auto-detects CUDA via
check_language(CUDA); setEIGH_REQUIRE_CUDA=ONto make a missingnvcca hard error instead of silently skipping the GPU module. - A GPU build is not portable the way the CPU wheel is: it must match the cluster's CUDA 12 runtime and driver.
Clusters / HPC
- glibc: Linux wheels target
manylinux_2_28(glibc 2.28) — runs on RHEL 8+, Ubuntu 18.04+, and most current HPC. CentOS 7 / RHEL 7 (glibc 2.17, EOL) is not supported; build from source there. - BLAS/LAPACK:
auditwheelbundles OpenBLAS + libgfortran into the Linux wheel, so cluster nodes do not need a system BLAS installed. - GPU nodes: build from source as above; the published wheel is CPU-only.
References
- [1] Kasim, M. F., & Vinko, S. M. Learning the exchange–correlation functional from nature with fully differentiable density functional theory. Phys. Rev. Lett. 127, 126403 (2021). https://doi.org/10.1103/PhysRevLett.127.126403
- [2] Colburn, S., & Majumdar, A. Inverse design and flexible parameterization of meta-optics using algorithmic differentiation. Communications Physics 4, 54 (2021). https://doi.org/10.1038/s42005-021-00568-6
- [3] JAX Issue #2748 — Differentiable
eighwith degeneracies. https://github.com/jax-ml/jax/issues/2748 - [4] JAX Issue #5461 — Stable generalized
eigh. https://github.com/jax-ml/jax/issues/5461
Development & Testing
- Requirements: CMake 3.18+, C++17, JAX, NumPy, LAPACK/CUDA.
- Tests:
pytest tests/test_eigh.py # Core functionality pytest tests/test_eigh_gen.py # Generalized itypes pytest tests/test_eigh_jit.py # JIT & vmap
- GPU Setup:
source setup_gpu_env_clean.sh ./run_gpu.sh python example_simple.py
License & Citation
Apache License 2.0. If used in research, please cite:
@software{sokolov2026eigh,
author={Sokolov, Igor},
title={Eigh: Differentiable eigenvalue decomposition with jax (cpu/gpu)},
url={https://github.com/Brogis1/eigh},
year={2026}
}
@software{pyscfad,
author = {Zhang, Xing},
title = {PySCFad: Automatic Differentiation for PySCF},
url = {https://github.com/fishjojo/pyscfad},
year = {2021-2025}
}
@article{10.1063/5.0118200,
author = {Zhang, Xing and Chan, Garnet Kin-Lic},
title = {Differentiable quantum chemistry with PySCF for molecules and materials at the mean-field level and beyond},
journal = {The Journal of Chemical Physics},
volume = {157},
number = {20},
pages = {204801},
year = {2022},
month = {11},
issn = {0021-9606},
doi = {10.1063/5.0118200},
url = {https://doi.org/10.1063/5.0118200},
}
@article{sokolov2026xc,
title = {Quantum-enhanced neural exchange-correlation functionals},
author = {Sokolov, Igor O. and Both, Gert-Jan and Bochevarov, Art D. and Dub, Pavel A. and Levine, Daniel S. and Brown, Christopher T. and Acheche, Shaheen and Barkoutsos, Panagiotis Kl. and Elfving, Vincent E.},
journal = {Phys. Rev. A},
volume = {113},
issue = {1},
pages = {012427},
numpages = {24},
year = {2026},
month = {Jan},
publisher = {American Physical Society},
doi = {10.1103/m51l-fys2},
url = {https://link.aps.org/doi/10.1103/m51l-fys2}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file eigh_cuda128-0.3.7-cp312-abi3-manylinux_2_34_x86_64.whl.
File metadata
- Download URL: eigh_cuda128-0.3.7-cp312-abi3-manylinux_2_34_x86_64.whl
- Upload date:
- Size: 14.2 MB
- Tags: CPython 3.12+, manylinux: glibc 2.34+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
98c5c02a1204975817c0f1b4b035c59e50d5db62bf9278db41692382ac0f366f
|
|
| MD5 |
0f848b3f7a95fcd97be39df6f53705db
|
|
| BLAKE2b-256 |
ef4672e8aedfae32e252899003dce458ac59d9ef8ff4b2268bc8f640b18f21b8
|
File details
Details for the file eigh_cuda128-0.3.7-cp311-cp311-manylinux_2_34_x86_64.whl.
File metadata
- Download URL: eigh_cuda128-0.3.7-cp311-cp311-manylinux_2_34_x86_64.whl
- Upload date:
- Size: 14.2 MB
- Tags: CPython 3.11, manylinux: glibc 2.34+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9db8ba81caa3d02fc5d41ab32b31bbaa64027f2793bf4cfe2fe60cad798ab711
|
|
| MD5 |
092740e2105b443b1f0bf8366bc5a32c
|
|
| BLAKE2b-256 |
278c3d72f661cda9778b4dda5381fa17a0e7fafc61ab9f3fb23dcdbfa7f17ee2
|
File details
Details for the file eigh_cuda128-0.3.7-cp310-cp310-manylinux_2_34_x86_64.whl.
File metadata
- Download URL: eigh_cuda128-0.3.7-cp310-cp310-manylinux_2_34_x86_64.whl
- Upload date:
- Size: 14.2 MB
- Tags: CPython 3.10, manylinux: glibc 2.34+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0df646870227447b94256cbe380e2a05f35f56436ed15a4ad5c5739c2c2a81bb
|
|
| MD5 |
846da8758cfdd94463471c3e6c936881
|
|
| BLAKE2b-256 |
4adbf1f7da78506b32ef8495617071b7379b5b8c3dd77ba09d61846c431fbd8b
|







