Eruption forecast modelling

Project description
eruption-forecast





Process raw seismic tremor, extract time-series features, train multi-seed classifier ensembles, and produce probabilistic volcanic eruption forecasts. Forked from ddempsey/whakaari and substantially extended.
References and Acknowledgments
Dempsey, D. E., Cronin, S. J., Mei, S., & Kempa-Liehr, A. W. (2020). Automatic precursor recognition and real-time forecasting of sudden explosive volcanic eruptions at Whakaari, New Zealand. Nature Communications, 11(1), 1–8. https://doi.org/10.1038/s41467-020-17375-2 This model implements a time series feature engineering and classification workflow that issues eruption alerts based on real-time tremor data. https://github.com/ddempsey/whakaari
Ardid, A., Dempsey, D., Caudron, C., Cronin, S., Kennedy, B., Girona, T., Roman, D., Miller, C., Potter, S., Lamb, O. D., Martanto, A., Cubuk-Sabuncu, Y., Cabrera, L., Ruiz, S., Contreras, R., Pacheco, J., Mora, M. M., & De Angelis, S. (2025). Ergodic seismic precursors and transfer learning for short term eruption forecasting at data scarce volcanoes. Nature Communications , 16(1), 1–12. https://doi.org/10.1038/s41467-025-56689-x
Ardid, A., Dempsey, D., Caudron, C., & Cronin, S. (2022). Seismic precursors to the Whakaari 2019 phreatic eruption are transferable to other eruptions and volcanoes. Nature Communications, 13(1), 2002. https://doi.org/10.1038/s41467-022-29681-y
Endo, E. T., & Murray, T. L. (1991). Real-time Seismic Amplitude Measurement (RSAM): a volcano monitoring and prediction tool. Bulletin of Volcanology, 53, 533–545.
Caudron, C., et al., 2019, Change in seismic attenuation as a long-term precursor of gas-driven eruptions: Geology, https://doi.org/10.1130/G46107.1
Rey-Devesa, P., Prudencio, J., Benítez, C., Bretón, M., Plasencia, I., León, Z., Ortigosa, F., Gutiérrez, L., Arámbula-Mendoza, R., & Ibáñez, J. M. (2023). Tracking volcanic explosions using Shannon entropy at Volcán de Colima. Scientific Reports, 13(1), 1–11. https://doi.org/10.1038/s41598-023-36964-x
Christ, M., Braun, N., Neuffer, J., & Kempa-Liehr, A. W. (2018). Time Series FeatuRe Extraction on basis of Scalable Hypothesis tests (tsfresh – A Python package). Neurocomputing, 307, 72–77. https://doi.org/10.1016/j.neucom.2018.03.067
Lei, Y., & Wu, Z. (2020). Time series classification based on statistical features. Eurasip Journal on Wireless Communications and Networking, 2020(1). https://doi.org/10.1186/s13638-020-1661-4
Chardot, L., Jolly, A. D., Kennedy, B. M., Fournier, N., & Sherburn, S. (2015). Using volcanic tremor for eruption forecasting at White Island volcano (Whakaari), New Zealand. Journal of Volcanology and Geothermal Research, 302, 11–23. https://doi.org/10.1016/j.jvolgeores.2015.06.001
Time-series feature analysis and eruption forecasting for volcano data. Successor package to Whakaari. This model implements a time series feature engineering and classification workflow that issues eruption alerts based on real-time tremor data. https://github.com/ddempsey/puia
Important Disclaimers
This software is intended for research purposes only.
-
Probabilistic Predictions: This eruption forecast model provides probabilistic predictions of future volcanic activity, NOT deterministic guarantees. Predictions should be interpreted as likelihood estimates based on historical seismic patterns.
-
No Guarantee of Accuracy: This model is not guaranteed to predict every future eruption. Volcanic systems are complex and can exhibit unexpected behavior. False negatives (missed eruptions) and false positives (false alarms) are possible.
-
Software Limitations: This software is not guaranteed to be free of bugs or errors. Users should validate results independently and use this tool as one component of a comprehensive volcano monitoring strategy.
-
Not for Operational Use: This package is a research tool and should not be used as the sole basis for public safety decisions, evacuation orders, or emergency response without expert volcanological assessment.
-
Expert Interpretation Required: Results should always be interpreted by qualified volcanologists familiar with the specific volcano being monitored.
Always consult with local volcano observatories and follow official warnings from government agencies.
Table of Contents
- References and Acknowledgments
- Features
- Package Architecture
- Pipeline Overview
- Installation
- Data Sources
- Quick Start
- Common Patterns
- Supported Classifiers
- Cross-Validation Strategies
- Output Directory Structure
- Requirements
- Development
- Contributing
- License
Detailed documentation — the wiki at https://github.com/martanto/eruption-forecast/wiki is the single source of truth (also mirrored under wiki/):
- Getting Started — Prerequisites, install, dev commands
- Pipeline Walkthrough — Research (
main.py) + Scenarios (scenarios.py) workflows - Training Workflow — Classifiers, CV strategies, imbalance handling
- Prediction Workflow — Forecast outputs and consensus probabilities
- Evaluation Workflow —
MetricsEnsemble,ClassifierComparator - Explanation Workflow —
ExplanationModel,ExplainerEnsemble, per-seed SHAP - Configuration — YAML save/replay, Telegram notifications, logging
- Visualization — Plot catalog and output paths
- Output Structure — Full directory tree
- Architecture — Package layout and class relationships
- API Reference — Every public class with parameter tables
Features
- Tremor Calculation — RSAM, DSAR, and Shannon Entropy across configurable frequency bands, from SDS archives or FDSN web services (with transparent local caching).
- Label Building — Standard sliding-window (
LabelBuilder) or per-eruption (DynamicLabelBuilder) generation from known eruption dates. - Feature Extraction — tsfresh feature engineering on windowed tremor matrices, with FDR-controlled selection (tsfresh statistical filter; RandomForest permutation importance available as an alternative).
- Multi-seed Training — 11 classifier families (
rf,gb,xgb,svm,lr,nn,dt,knn,nb,voting,lite-rf), three CV strategies, automatic imbalance handling, and per-seedGridSearchCV. - Ensemble Packaging —
SeedEnsemblebundles every seed for one classifier;ClassifierEnsemblebundles multiple classifiers; both implement the sklearnBaseEstimator + ClassifierMixininterface. - Probabilistic Forecasting —
PredictionModelproduces per-seed, per-classifier, and consensus probabilities with uncertainty bands over an unlabelled window grid. - Evaluation + Comparison —
EvaluationModelruns metrics over a training or prediction reuse mode;MetricsEnsemblepersists(n_samples, n_seeds)y_proba/y_predmatrices and keeps per-seed metric tables in memory;ClassifierComparatorranks classifiers head-to-head. - Model Explanation —
ExplanationModelproduces per-seed SHAP explanations over the fitted ensemble viaExplainerEnsemble(tree classifiers only — RF /lite-rf/ GB / XGB). Outputs include per-classifierClassifierExplanation_*.pkl, per-seed bar / beeswarm plots, and per-eruption highest-probability waterfall plots. - Content-Addressable Caching —
TrainingModelandPredictionModelcache their fitted state under{output_dir}/cache/so repeated runs with identical kwargs short-circuit. - Config Round-Trip —
fm.save_config()→ YAML →ForecastModel.from_config(path).run()replays a full pipeline. - Telegram Notifications —
@notifydecorator +send_telegram_notification()for start/finish/error messages and file attachments. - Multi-processing —
n_jobs(outer seed workers) ×n_grids(innerGridSearchCV/FeatureSelectorworkers) parallelism, clamped tototal_cpu - 2automatically.
Package Architecture
src/eruption_forecast/
├── __init__.py, logger.py, data_container.py
├── config/ forecast_config, training_config, constants
├── dataclass/ station_data, classifier_ensemble_summary,
│ classifier_explanation
├── decorators/ notify, decorator_class
├── ensemble/ base_ensemble, seed_ensemble, classifier_ensemble,
│ metrics_ensemble, explainer_ensemble
├── features/ tremor_matrix_builder, features_builder, feature_selector
├── label/ label_builder, dynamic_label_builder, label_data, label_plots
├── model/ base_model, cache_model, forecast_model,
│ training_model, prediction_model, evaluation_model,
│ explanation_model, classifier_model, classifier_comparator
├── plots/ styles, tremor_plots, feature_plots, forecast_plots,
│ evaluation_plots, explanation_plots
├── sources/ base, sds, fdsn
├── tremor/ calculate_tremor, rsam, dsar, shannon_entropy, tremor_data
└── utils/ array, dataframe, date_utils, formatting, ml,
pathutils, validation, window
Full directory tree, class relationships, and per-component details: wiki/Architecture.md
Pipeline Overview
┌──────────────┐ ┌────────────────────┐ ┌─────────────────┐
│ Seismic │ │ CalculateTremor │ │ TremorData │
│ archive │ ──► │ rsam/dsar/ │ ─► │ (CSV wrapper) │
│ (SDS|FDSN) │ │ entropy + bands │ │ │
└──────────────┘ └────────────────────┘ └────────┬────────┘
│
┌─────────── feature pipeline ──────────────────────────┴─────┐
│ LabelBuilder / DynamicLabelBuilder │
│ → TremorMatrixBuilder → FeaturesBuilder (tsfresh) │
│ → FeatureSelector (tsfresh FDR + RF importance) │
└────────────────────────────┬────────────────────────────────┘
▼
┌────────────────────────┐
│ TrainingModel │
│ build_label → │
│ extract_features → │
│ fit (N seeds × M cv) │
└──┬───────────────────┬─┘
│ │
▼ ▼
┌────────────────┐ ┌────────────────────────┐
│ SeedEnsemble × │ ─► │ ClassifierEnsemble │
│ N classifiers │ │ (all SeedEnsembles) │
└────────────────┘ └──────────┬─────────────┘
│
▼
┌──────────────────────────────┐
│ PredictionModel │
│ build_label → │
│ extract_features → │
│ forecast (per-seed proba) │
└──────────┬───────────────────┘
│
┌────────────────────────────────┴──────────────────────┐
▼ ▼
┌──────────────────────┐ ┌────────────────────────┐
│ EvaluationModel │ │ forecast-results_ │
│ training | predict │ ── MetricsEnsemble ──► │ *.csv + forecast │
│ │ │ PNG/PDF │
└──────────┬───────────┘ └────────────────────────┘
│ writes (n_samples × n_seeds) y_proba / y_pred CSVs
│
▼
┌──────────────────────┐
│ ClassifierComparator │ ranking_*.csv + comparison figures
└──────────────────────┘
┌──────────────────────────────────────────────────────────────┐
│ ExplanationModel (BaseModel + CacheModel) │
│ ExplainerEnsemble │
│ ── per-seed shap.TreeExplainer (RF / lite-rf / GB /XGB)│
│ ── ClassifierExplanation.pkl per classifier │
│ ── per-seed bar + beeswarm, per-eruption waterfall │
└──────────────────────────────────────────────────────────────┘
ForecastModel.calculate() → train() → predict() → evaluate() → explain() is the fluent entry point. Each stage caches and persists, so a repeated run with identical kwargs short-circuits via the on-disk cache.
Installation
This project uses uv as the package manager.
# Clone the repository
git clone https://github.com/martanto/eruption-forecast.git
cd eruption-forecast
# Install dependencies
uv sync
# Install with dev dependencies (ruff, ty, pytest)
uv sync --group dev
Data Sources
The package reads seismic data from two sources, both routed through CalculateTremor.
SDS — SeisComP Data Structure
SDS is the layout used by SeisComP to store waveform data portably. See the official specification for full details.
Directory layout:
<sds_dir>/
└── YEAR/
└── NET/
└── STA/
└── CHAN.TYPE/
└── NET.STA.LOC.CHAN.TYPE.YEAR.DAY
Example for network VG, station OJN, channel EHZ, day 075 of 2025:
/data/
└── 2025/
└── VG/
└── OJN/
└── EHZ.D/
└── VG.OJN.00.EHZ.D.2025.075
| Field | Description | Example |
|---|---|---|
YEAR |
Four-digit year | 2025 |
NET |
Network code | VG |
STA |
Station code | OJN |
CHAN |
Channel code | EHZ |
LOC |
Location code (may be empty) | 00 |
TYPE |
Data type (D = waveform data) |
D |
DAY |
Three-digit day-of-year | 075 |
Files are miniSEED format.
FDSN — Web Service
FDSN downloads waveform data from any FDSN-compatible web service (IRIS, GEOFON, etc.) and caches it locally as SDS miniSEED, so subsequent runs skip the network.
from eruption_forecast import ForecastModel
fm = ForecastModel(station="OJN", channel="EHZ", network="VG", location="00").calculate(
start_date="2025-01-01", end_date="2025-01-31",
source="fdsn", client_url="https://service.iris.edu",
)
SDS vs FDSN read-path diagram and adapter internals: wiki/Data-Sources.md
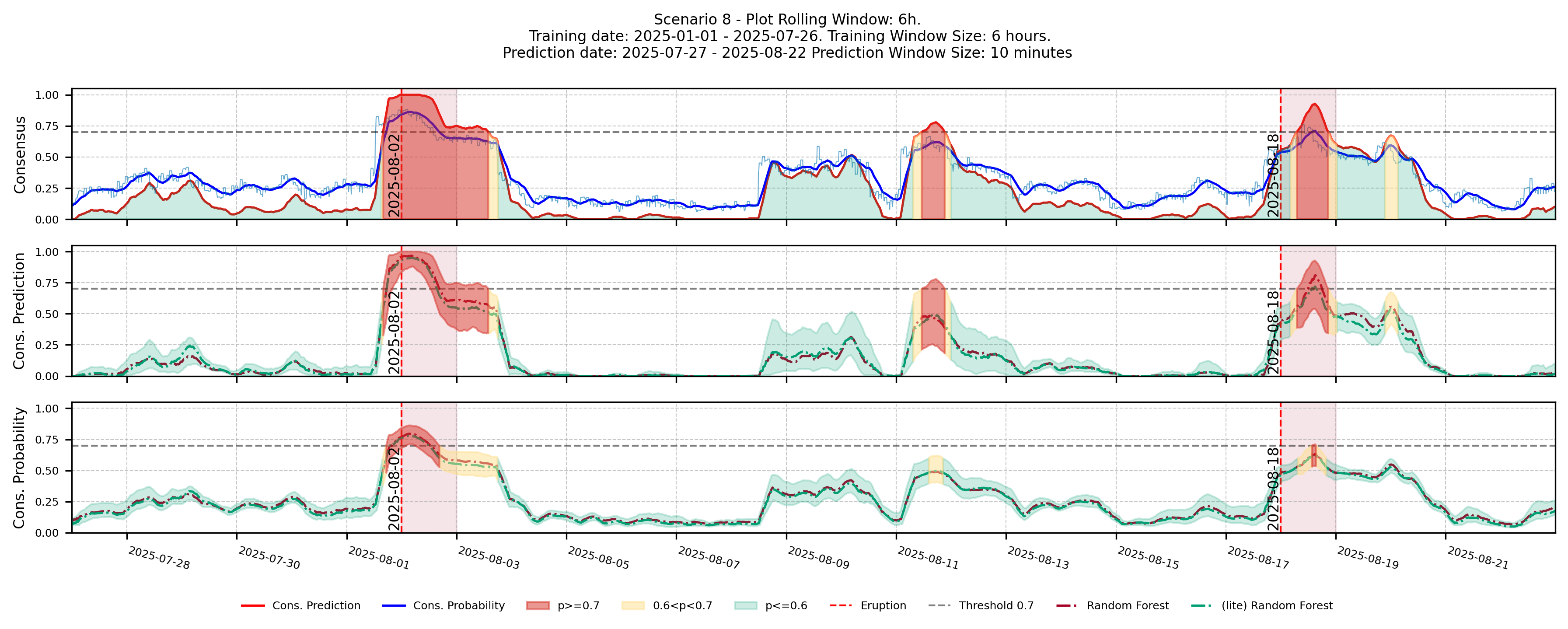
Quick Start
End-to-end pipeline from raw seismic data to forecast — train on Jan–Jul, predict Jul–Aug, evaluate against known eruption dates.
from eruption_forecast import ForecastModel
fm = ForecastModel(
station="OJN",
channel="EHZ",
network="VG",
location="00",
day_to_forecast=2, # look-ahead window in days
root_dir="/path/to/project",
n_jobs=4,
verbose=True,
)
(
fm.calculate(
start_date="2025-01-01", end_date="2025-08-31",
source="sds", sds_dir="/path/to/sds",
methods=["rsam", "dsar", "entropy"],
plot_daily=True, save_plot=True,
)
.train(
start_date="2025-01-01", end_date="2025-07-26",
eruption_dates=[
"2025-03-20",
"2025-04-22",
"2025-05-18",
"2025-06-17",
"2025-07-07",
],
window_step=6, window_step_unit="hours",
classifiers=["lite-rf", "rf", "gb", "xgb"],
cv_strategy="shuffle-stratified",
cv_splits=5,
seeds=25,
top_n_features=20,
select_tremor_columns=["rsam_f2", "rsam_f3", "rsam_f4", "dsar_f3-f4", "entropy"],
resample_method="auto",
use_cache=True,
)
.predict(
start_date="2025-07-27", end_date="2025-08-22",
window_step=10, window_step_unit="minutes",
plot_threshold=0.7,
plot_pdf=True,
)
.evaluate(
model="prediction",
eruption_dates=["2025-08-02"], # falls back to train() dates when omitted
plot_aggregate=True,
)
.explain(
model="prediction",
eruption_dates=["2025-08-02"], # falls back to train() dates when omitted
plot_per_seed=True,
plot_aggregate=True, # per-classifier aggregate bar + beeswarm
max_display=20,
)
)
# Pipeline outputs
print(fm.results) # forecast DataFrame
print(fm.evaluation_results) # per-classifier per-seed metrics
print(fm.ExplanationModel.explanations) # list[ClassifierExplanation]
print(fm.TrainingModel.classifier_ensemble_path)
What this pipeline does:
- Calculate tremor — RSAM, DSAR, and Shannon Entropy from raw seismic, with outlier removal and daily plots.
- Train — build labels around the 5 eruption dates, extract tsfresh features over a 6-hour window grid, fit 25 seeds × 4 classifiers under stratified-shuffle CV with
"auto"imbalance handling. - Predict — apply the bundled
ClassifierEnsembleto a fresh 10-minute window grid over the forecast period and emit per-classifier + consensus probabilities. - Evaluate — score the forecast against the held-out eruption date by writing
(n_samples, n_seeds)y_proba/y_predmatrices per classifier and aggregate metric plots; cross-classifier ranking viaClassifierComparator. - Explain — produce per-seed SHAP explanations for the tree classifiers in the ensemble, bundled into
ClassifierExplanation_*.pklper classifier and rendered as per-seed bar / beeswarm, per-classifier aggregate bar / beeswarm (NaN-padded union feature space), and per-eruption waterfall plots.
See main.py for the full working example and scenarios.py for the multi-scenario variant.
Full per-stage guide: wiki/Pipeline-Walkthrough.md
Common Patterns
Use FDSN instead of a local SDS archive
fm.calculate(
start_date="2025-01-01", end_date="2025-01-31",
source="fdsn",
client_url="https://service.iris.edu",
)
# Downloaded miniSEED is cached locally as SDS so subsequent runs skip the network.
Skip tremor calculation when the CSV already exists
TrainingModel and PredictionModel both accept either a pd.DataFrame or a tremor CSV path directly — handy when iterating on training kwargs without re-running calculate().
from eruption_forecast import TrainingModel
tm = (
TrainingModel(
tremor_data="output/VG.OJN.00.EHZ/tremor/VG.OJN.00.EHZ_2025-01-01_2025-08-31.csv",
start_date="2025-01-01", end_date="2025-07-26",
classifiers=["rf", "xgb"],
eruption_dates=["2025-03-20"],
window_size=2,
top_n_features=20,
)
.build_label(window_step=6, window_step_unit="hours")
.extract_features(select_tremor_columns=["rsam_f2", "rsam_f3", "dsar_f3-f4", "entropy"])
.fit(seeds=25, resample_method="auto", plot_features=True)
)
Reuse curated features (skip full tsfresh re-extraction)
Once a TrainingModel run has persisted its features-matrix_*.csv and top_{N}_features.csv, two shortcuts let later runs reuse that work:
# Reuse features (fastest — tremor matrix unchanged)
(
TrainingModel(...)
.load_features(
select_features="output/.../training/features/.../top_20_features.csv",
)
.fit(seeds=25)
)
# Or re-run tsfresh on the curated columns only
(
TrainingModel(...)
.build_label(window_step=6, window_step_unit="hours")
.extract_features(
select_features="output/.../training/features/.../top_20_features.csv",
)
.fit(seeds=25)
)
select_features accepts a CSV path or an explicit list[str] of fully-qualified tsfresh feature names. Per-seed selection inside fit() still runs; when the curated list is already ≤ top_n_features, it's effectively a no-op.
Forecast from a saved ClassifierEnsemble
from eruption_forecast import PredictionModel
pm = (
PredictionModel(
model="output/.../training/classifiers/ClassifierEnsemble_stratified-shuffle-split.pkl",
tremor_data="output/.../tremor/VG.OJN.00.EHZ_2025-01-01_2025-08-31.csv",
start_date="2025-07-27", end_date="2025-08-22",
window_size=2,
)
.build_label(window_step=10, window_step_unit="minutes")
.extract_features()
)
results = pm.forecast(plot_threshold=0.7, plot_pdf=True)
PredictionModel(model=...) also accepts a live ClassifierEnsemble / SeedEnsemble, a ClassifierEnsemble.json, a SeedEnsemble_*.pkl, or a trained-model registry CSV — resolved via ClassifierEnsemble.from_any(...).
Evaluate from a saved .pkl
from eruption_forecast import EvaluationModel
em = EvaluationModel.from_file(
"output/.../PredictionModel_2025-07-27_2025-08-22.pkl",
eruption_dates=["2025-08-02"], # required for prediction reuse
)
metrics = em.evaluate(plot_aggregate=True)
comparator = em.compare()
print(comparator.get_ranking())
Save and replay the pipeline configuration
fm.evaluate(...) auto-calls save_config(). Call it manually at earlier stages to checkpoint partial runs.
fm.save_config() # → {station_dir}/forecast.config.yaml
fm.save_config(fmt="json") # → forecast.config.json
# Replay
fm2 = ForecastModel.from_config("output/VG.OJN.00.EHZ/forecast.config.yaml")
fm2.run() # replays every captured non-None stage
Persist stage outputs explicitly
fm.TrainingModel.save() # → {output_dir}/TrainingModel_{basename}.pkl
fm.PredictionModel.save() # → {output_dir}/PredictionModel_{basename}.pkl
fm.EvaluationModel.save() # → {output_dir}/EvaluationModel_{basename}.pkl
Silence logging during batch jobs
from eruption_forecast import disable_logging, enable_logging
from eruption_forecast.logger import set_log_level, set_log_directory
disable_logging()
fm.calculate(...).train(...).predict(...) # silent
enable_logging()
set_log_level("WARNING") # console-only level
set_log_directory("logs/2026-06-10") # move file handler
Telegram + logging full reference: wiki/Configuration.md
Supported Classifiers
| Key | sklearn class | Imbalance handling | Notes |
|---|---|---|---|
rf |
RandomForestClassifier |
class_weight="balanced" |
Default; robust baseline |
lite-rf |
RandomForestClassifier |
class_weight="balanced" |
Smaller grid for faster training |
gb |
GradientBoostingClassifier |
natural | — |
xgb |
XGBClassifier |
scale_pos_weight grid |
— |
svm |
SVC |
class_weight="balanced" |
— |
lr |
LogisticRegression |
class_weight="balanced" |
Fast, interpretable |
nn |
MLPClassifier |
none | — |
dt |
DecisionTreeClassifier |
class_weight="balanced" |
Interpretable baseline |
knn |
KNeighborsClassifier |
none | — |
nb |
GaussianNB |
none | Fast baseline |
voting |
VotingClassifier (RF + XGBoost soft vote) |
combined | — |
classifiers= accepts str or list[str]. One SeedEnsemble is built per classifier and bundled into a single ClassifierEnsemble for consensus forecasting.
Hyperparameter grids and tuning: wiki/Training-Workflow.md
Cross-Validation Strategies
cv_strategy |
sklearn class | Best for |
|---|---|---|
shuffle-stratified (default) |
StratifiedShuffleSplit |
Random splits with stratification |
stratified |
StratifiedKFold |
Strict k-fold with class-distribution preservation |
shuffle |
ShuffleSplit |
Random splits without stratification |
timeseries (TimeSeriesSplit) is available via the lower-level ClassifierModel directly but is not exposed on fm.train(...).
Imbalance Handling
resample_method |
Behaviour |
|---|---|
"auto" (default) |
Apply "under" (RandomUnderSampler) when the minority-class share is below minority_threshold (default 0.15), otherwise skip |
"under" |
Always apply RandomUnderSampler |
"over" |
Always apply RandomOverSampler |
None |
Skip resampling entirely |
sampling_strategy=0.75 (default) is the target ratio passed to the resampler.
Output Directory Structure
All outputs land under {output_dir}/{network}.{station}.{location}.{channel}/ (e.g., output/VG.OJN.00.EHZ/).
{station_dir}/
├── tremor/ # CalculateTremor
│ ├── daily/ # per-day CSVs (removed when cleanup_daily_dir=True)
│ ├── figures/ # daily plots (plot_daily=True)
│ └── {nslc}_{start}_{end}.csv # merged tremor CSV
│
├── training/ # TrainingModel
│ ├── features/{cv-slug}/ # tsfresh matrix, per-seed CSVs, top-N features
│ └── classifiers/
│ ├── ClassifierEnsemble_{cv}.{pkl,json}
│ └── {clf-slug}/{cv-slug}/
│ ├── models/{seed:05d}.pkl
│ ├── trained-model__{suffix}.json
│ └── SeedEnsemble_{suffix}.pkl
│
├── prediction/ # PredictionModel
│ ├── features/ # forecast-grid features
│ ├── results/{clf-slug}/{seed:05d}.csv # per-seed probabilities (save_seed_result=True)
│ └── figures/forecast_{basename}.{png,pdf}
│
├── evaluation/ # EvaluationModel
│ ├── training/ # when model="training"
│ └── prediction/ # when model="prediction"
│ ├── classifiers/{ClfName}/
│ │ ├── predictions/{y_proba,y_pred}.csv # (n_samples × n_seeds)
│ │ └── figures/
│ │ ├── aggregate/{plot_name}.{png,csv}
│ │ └── {plot_name}/{seed:05d}.png # plot_per_seed=True
│ ├── labels/y_true.csv # prediction reuse only
│ └── comparison/ # ClassifierComparator
│
├── explanation/ # ExplanationModel
│ ├── training/ # when upstream model.kind=="training"
│ └── prediction/ # when upstream model.kind=="prediction"
│ ├── classifiers/{ClfName}/
│ │ ├── ClassifierExplanation_{ClfName}.pkl
│ │ ├── shap_values/{seed:05d}.pkl
│ │ └── figures/
│ │ ├── {bar,beeswarm}/{seed:05d}.png # plot_per_seed=True
│ │ └── aggregate/{bar,beeswarm}.{png,csv} # plot_aggregate=True
│ └── eruptions/{YYYY-MM-DD}/
│ └── {ClfName}_{datetime}_seed=_index=.png
│
├── cache/ # CacheModel
│ ├── TrainingModel/{hash}.pkl + {hash}.params.json
│ ├── PredictionModel/{hash}.pkl + {hash}.params.json
│ └── ExplanationModel/{hash}.pkl + {hash}.params.json
│
├── forecast.config.yaml # fm.save_config()
├── forecast-results_{basename}.csv
└── {Training,Prediction,Evaluation}Model_*.pkl # optional, via .save()
Full tree with slug tables and filename conventions: wiki/Output-Structure.md
Requirements
Core dependencies
- Python ≥ 3.11
- pandas ≥ 3.0.0, numpy, scipy
- obspy (seismic data processing)
- tsfresh (time-series feature extraction)
- scikit-learn, imbalanced-learn
- xgboost ≥ 3.x
- shap ≥ 0.46
- joblib
- matplotlib, seaborn
- loguru
- python-dotenv (Telegram credentials)
Development dependencies
Development
# Lint and auto-fix
uv run ruff check --fix src/
# Type check
uvx ty check src/
# Run tests
uv run pytest tests/
# Circular-import check (run after any module move)
uv run pytest tests/test_imports.py -v
# Run the end-to-end pipeline
uv run python main.py
Project rules are documented in CLAUDE.md — including the new-branch-before-any-commit convention, the comprehensive doc-update rule, and the config.example.yaml sync requirement.
Contributing
- Fork the repository.
- Create a feature branch from the latest target:
fix/<name>— bug fixesft/<name>— new featuresdev/<name>— refactors, docs, tooling
- Make changes with tests and updated wiki pages.
- Pass linting + type checks:
uv run ruff check --fix src/ && uvx ty check src/. - Run the circular-import test:
uv run pytest tests/test_imports.py -v. - Submit a pull request against the configured base branch.
Code style: PEP 8, Google-style docstrings with explicit types, type hints on all public functions, no inline imports.
License
MIT License — see LICENSE for details.
Disclaimer of Liability: This software is provided "as is" without warranty of any kind, express or implied. The authors and contributors shall not be liable for any damages or losses arising from the use of this software. Volcanic eruption forecasting is inherently uncertain, and this software should be used only as a research tool, not for operational volcano monitoring or public safety decisions.
Version: 0.3.2 Status: Active Development Last Updated: 2026-06-20


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file eruption_forecast-0.3.2.tar.gz.
File metadata
- Download URL: eruption_forecast-0.3.2.tar.gz
- Upload date:
- Size: 268.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.11.7 {"installer":{"name":"uv","version":"0.11.7","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
41c85390f3f049941b0b8c518592d535d2403594bcdd1e34fbc5156b4d7685d9
|
|
| MD5 |
cb6a3ed8784d05b1bfd5b4e6f19b75dd
|
|
| BLAKE2b-256 |
2e18b63bf54bd51de16c6d0243153eec218ba2f21a5887ffd42af1f09a43296e
|
File details
Details for the file eruption_forecast-0.3.2-py3-none-any.whl.
File metadata
- Download URL: eruption_forecast-0.3.2-py3-none-any.whl
- Upload date:
- Size: 307.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.11.7 {"installer":{"name":"uv","version":"0.11.7","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":null,"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6c694ebe6ea717dea22d1f26af55296f90911c6359fca2e54488742e2f4cb8c5
|
|
| MD5 |
d1b8d713f43b79682331b88163572c56
|
|
| BLAKE2b-256 |
0a345083cc4f9e700cc419de676c7bdc08b7fd921d90f08b3635f173f2067676
|







