A library for quickly applying symbolic expressions to NumPy arrays

Project description
expressive
A library for quickly applying symbolic expressions to NumPy arrays
By enabling callers to front-load sample data, developers can move the runtime cost of Numba's JIT to the application's initial loading (or an earlier build) and also avoid exec during runtime, which is otherwise needed when lambdifying symbolic expressions
Inspired in part by this Stack Overflow Question Using numba.autojit on a lambdify'd sympy expression
installation
via pip https://pypi.org/project/expressive/
pip install expressive
usage
refer to tests for examples for now
generally follow a workflow like
- create instance
expr = Expressive("a + log(b)") - build instance
expr.build(sample_data) - instance is now callable
expr(full_data)
the data should be provided as dict of NumPy arrays
data_sample = { # simplified data to build and test expr
"a": numpy.array([1,2,3,4], dtype="int64"),
"b": numpy.array([4,3,2,1], dtype="int64"),
}
data = { # real data user wants to process
"a": numpy.array(range(1_000_000), dtype="int64"),
"b": numpy.array(range(1_000_000), dtype="int64"),
}
E = Expressive("expr") # string or SymPy expr
E.build(data_sample) # data's types used to compile a fast version
E(data) # very fast callable
simple demo
import time
import contextlib
import numpy
import matplotlib.pyplot as plt
from expressive import Expressive
# simple projectile motion in a plane
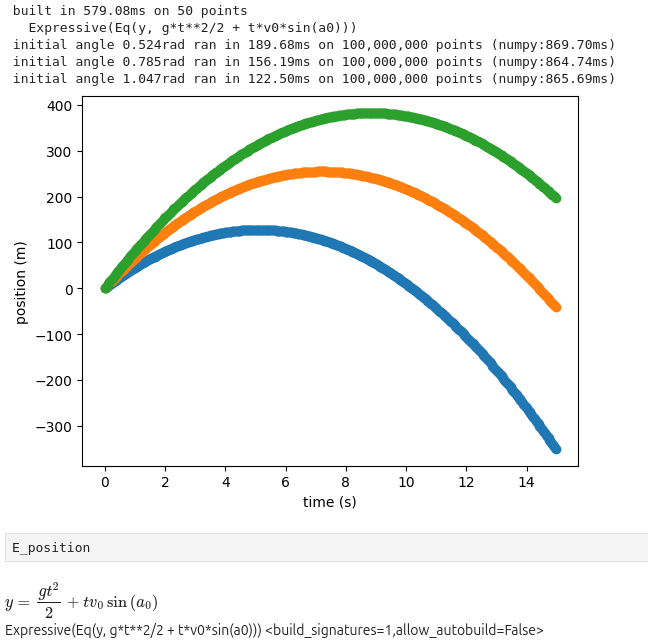
E_position = Expressive("y = v0*t*sin(a0) + 1/2(g*t^2)")
# expr is built early in the process runtime by user
def build():
# create some sample data and build with it
# the types are used to compile a fast version for full data
data_example = {
"v0": 100, # initial velocity m/s
"g": -9.81, # earth gravity m/s/s
"a0": .785, # starting angle ~45° in radians
"t": numpy.linspace(0, 15, dtype="float64"), # 15 seconds is probably enough
}
assert len(data_example["t"]) == 50 # linspace default
time_start = time.perf_counter()
E_position.build(data_example) # verify is implied with little data
time_run = time.perf_counter() - time_start
# provide some extra display details
count = len(data_example["t"])
print(f"built in {time_run*1000:.2f}ms on {count:,} points")
print(f" {E_position}")
def load_data(
point_count=10**8, # 100 million points (*count of angles), maybe 4GiB here
initial_velocity=100, # m/s
):
# manufacture lots of data, which would be loaded in a real example
time_array = numpy.linspace(0, 15, point_count, dtype="float64")
# collect the results
data_collections = []
# process much more data than the build sample
for angle in (.524, .785, 1.047): # initial angles (30°, 45°, 60°)
data = { # data is just generated in this case
"v0": initial_velocity, # NOTE type must match example data
"g": -9.81, # earth gravity m/s/s
"a0": angle, # radians
"t": time_array, # just keep re-using the times for this example
}
data_collections.append(data)
# data collections are now loaded (created)
return data_collections
# later during the process runtime
# user calls the object directly with new data
def runtime(data_collections):
""" whatever the program is normally up to """
# create equivalent function for numpy compare
def numpy_cmp(v0, g, a0, t):
return v0*t*numpy.sin(a0) + 1/2*(g*t**2)
# TODO also compare numexpr demo
# call already-built object directly on each data
results = []
for data in data_collections:
# expressive run
t_start_e = time.perf_counter() # just to show time, prefer timeit for perf
results.append(E_position(data))
t_run_e = time.perf_counter() - t_start_e
# simple numpy run
t_start_n = time.perf_counter()
result_numpy = numpy_cmp(**data)
t_run_n = time.perf_counter() - t_start_n
# provide some extra display details
angle = data["a0"]
count = len(data["t"])
t_run_e = t_run_e * 1000 # convert to ms
t_run_n = t_run_n * 1000
print(f"initial angle {angle}rad ran in {t_run_e:.2f}ms on {count:,} points (numpy:{t_run_n:.2f}ms)")
# decimate to avoid very long matplotlib processing
def sketchy_downsample(ref, count=500):
offset = len(ref) // count
return ref[::offset]
# display results to show it worked
for result, data in zip(results, data_collections):
x = sketchy_downsample(data["t"])
y = sketchy_downsample(result)
plt.scatter(x, y)
plt.xlabel("time (s)")
plt.ylabel("position (m)")
plt.show()
def main():
build()
data_collections = load_data()
runtime(data_collections)
main()
compatibility matrix
generally this strives to only rely on high-level support from SymPy and Numba, though Numba has stricter requirements for NumPy and llvmlite
| Python | Numba | NumPy | SymPy | commit | coverage | trun |
|---|---|---|---|---|---|---|
| 3.7.17 | 0.56.4 | 1.21.6 | 1.6 | 845e68c | {'codegen.py': '🟠 99% m 387'} 🟢 100% (9path) | 86s |
| 3.8.20 | 0.58.1 | 1.24.4 | 1.7 | 845e68c | {'codegen.py': '🟠 99% m 387'} 🟢 100% (9path) | 83s |
| 3.9.19 | 0.53.1 | 1.23.5 | 1.7 | 845e68c | {'codegen.py': '🟠 99% m 387'} 🟢 100% (9path) | 79s |
| 3.9.19 | 0.60.0 | 2.0.1 | 1.13.2 | 845e68c | 🟢 100% (10path) | 84s |
| 3.10.16 | 0.61.0 | 2.1.3 | 1.13.3 | 845e68c | 🟢 100% (10path) | 81s |
| 3.11.11 | 0.61.0 | 2.1.3 | 1.13.3 | 845e68c | 🟢 100% (10path) | 81s |
| 3.12.7 | 0.59.1 | 1.26.4 | 1.13.1 | 845e68c | 🟢 100% (10path) | 74s |
| 3.12.8 | 0.61.0 | 2.1.3 | 1.13.3 | 845e68c | 🟢 100% (10path) | 87s |
| 3.13.1 | 0.61.0 | 2.1.3 | 1.13.3 | 845e68c | 🟢 100% (10path) | 89s |
NOTE differences in test run times are not an indicator of built expr speed, more likely the opposite and more time spent represents additional build step effort, likely improving runtime execution! please consider the values arbitrary and just for development reasons
further compatibility notes
these runs build the package themselves internally, while my publishing environment is currently Python 3.11.2
though my testing indicates that this works under a wide variety of quite old versions of Python/Numba/SymPy, upgrading to the highest dependency versions you can will generally be best
- Python 3 major version status https://devguide.python.org/versions/
- https://numba.readthedocs.io/en/stable/release-notes-overview.html
NumPy 1.x and 2.0 saw some major API changes, so older environments may need to adjust or discover working combinations themselves
- some versions of Numba rely on
numpy.MachAr, which has been deprecated since at least NumPy 1.22 and may result in warnings
TBD publish multi-version test tool
testing
Only docker is required in the host and used to generate and host testing
sudo apt install docker.io # debian/ubuntu
sudo usermod -aG docker $USER
sudo su -l $USER # login shell to self (reboot for all shells)
Run the test script from the root of the repository and it will build the docker test environment and run itself inside it automatically
./test/runtests.sh
build + install locally
Follows the generic build and publish process
- https://packaging.python.org/en/latest/tutorials/packaging-projects/#generating-distribution-archives
- build (builder) https://pypi.org/project/build/
python3 -m build
python3 -m pip install ./dist/*.whl
contributing
The development process is currently private (though most fruits are available here!), largely due to this being my first public project with the potential for other users than myself, and so the potential for more public gaffes is far greater
Please refer to CONTRIBUTING.md and LICENSE.txt and feel free to provide feedback, bug reports, etc. via Issues, subject to the former
additional future intentions for contributing
- improve internal development history as time, popularity, and practicality allows
- move to parallel/multi-version/grid CI over all-in-1, single-version dev+test container (partially done with 2.0.0!)
greatly relax dependency version requirements to improve compatibility- publish majority of ticket ("Issue") history
version history
v3.2.20250425
- improved smaller types handling
- automatic dtype determination with
Pow()is improved - give a dedicated warning when an exception related to setting
dtype_resultto a type with a small width that a function (such asPow()) automatically promotes occurs
- automatic dtype determination with
- improve autobuilding experience with new config tunables
- easily enable autobuild globally
builder.autobuild.allow_autobuild - option to disable build-time usage warning
builder.autobuild.usage_warn_nag
- easily enable autobuild globally
- minor version is now a datestamp
v3.1.0
- instances of
Expressivenow have individual configurations - further config changes
- all configuration keys are now flattened and
.-separated - warn and still handle legacy keys
- include per-instance builder settings
- new UNSET value singleton
- all configuration keys are now flattened and
v3.0.0
- cutover splitting project into numerous files (dbd89cd+)
- improved MathJax reference copy handling
- split out changelog too (truncated view in README)
- add tunables for parallelization and
numba.prange()support - improved a bug where the name literally "row" couldn't be used in
Sum()(now has a dedicated error and uses "rowscalar" name, a future version should avoid this entirely via by-ref handling and/or name mangling) - testing changes
- various pathing and import changes to accomodate file changes
- downgrade to non-root user in test containers
- essential argument features (verbose,
trapEXIT to shell, subset to singleTestCaseorTestCase.test_)
v2.2.0
- added support for the
Sumfunction (SymPy unevaluated summation)- attempts to evaluate/decompose
Suminto an algebraic expression during building.build() - creates a custom function to manage
Suminstances which can't be simplified - spawn a thread to warn user when attempting to simplify a
Sums is taking an excessive amount of time (duration and even halting are unknown, so the user may not know where the issue is .. 20s default)
- attempts to evaluate/decompose
- added basic configuration system
CONFIG- API is unstable and largely featureless, but needed to control/disable
Sumsimplifying - currently a singleton
dictshared by allExpressiveinstances, but a future version/design will accept per-instance configurations and combine them with global defaults
- API is unstable and largely featureless, but needed to control/disable
- generally much better handling for scalars in data
- scalar values are no longer coerced into a 0-dim array
- NumPy scalars (not just Python numbers) are now allowed
v2.1.0 (unreleased)
- added a new
signature_automatic()which (ab)uses the Numba JIT to determine the result'sdtypeeven for indexed exprs
v2.0.0
- enabled matrix/tensor support
- improved/reduced warnings from verify
- tested + greatly reduced dependency version requirements
- added a basic usage example (uses new docs repo https://gitlab.com/expressive-py/docs/ )
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file expressive-3.2.20250425.tar.gz.
File metadata
- Download URL: expressive-3.2.20250425.tar.gz
- Upload date:
- Size: 62.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.11.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e76a203227eb91eee53b576621333318d092019f7b1b1719d7bd190bae0407b6
|
|
| MD5 |
8c7eef414ea86a48b187439016ac7ebd
|
|
| BLAKE2b-256 |
f21a7abf8ac1597959d62731ef7f31b53371b7fb1472fb99e6d80cfd08af084e
|
File details
Details for the file expressive-3.2.20250425-py3-none-any.whl.
File metadata
- Download URL: expressive-3.2.20250425-py3-none-any.whl
- Upload date:
- Size: 43.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.11.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b8f0f6ebdc6d04016ef6fc9749b479029d8eeae68a4dd722626fc7be9967b010
|
|
| MD5 |
39c835cfb7224f797669ba16b676fa03
|
|
| BLAKE2b-256 |
5722b11938ef6fcc297486ee5feca006d00688a4e101db8b3c7e82745175a7e2
|







