Extended XYZ file format tools

Project description
Extended XYZ specification and parsing tools
This repository contains a specification of the extended XYZ (extxyz) file format, and tools for reading and writing to it from programs written in C, Fortran, Python and Julia.
Using ASE? As of v0.3.0,
extxyzis the standalone C parser with no ASE dependency, and a separatease-extxyzpackage registers it as an ASE I/O plugin. Install both withpip install ase-extxyzand usease.io.read("file.xyz", format="cextxyz").
Installation
Python
The latest development version can be installed via
pip install git+https://github.com/libAtoms/extxyz
This requires Python 3.10+ and a working C compiler, plus the PCRE2 and libcleri libraries. libcleri is included here as a submodule and will be compiled automatically, but you may need to install PCRE2 with something similar to one of the following commands. NumPy is also needed at build time (it is already a runtime dependency): its C headers build the _extxyz extension's fast read path. A build without NumPy headers still works — it falls back to the slower ctypes read path.
brew install pcre2 # macOS with Homebrew
sudo apt-get install libpcre2-dev # Ubuntu / Debian
vcpkg install pcre2:x64-windows # Windows (via vcpkg)
Binary wheels for Linux, macOS (arm64 and x86_64), and Windows are built in the GitHub CI for each tagged release and bundle PCRE2 and libcleri, so an end-user pip install extxyz does not need either system library.
Stable releases are made to PyPI, so you can install with
pip install extxyz # standalone parser, no ASE
pip install ase-extxyz # ASE plugin (pulls in extxyz + ase)
The Python API on extxyz itself is the dict/array based Frame parser:
import extxyz
for frame in extxyz.iread_dicts('trajectory.xyz'):
print(frame.natoms, frame.cell, list(frame.arrays))
For ASE-aware reading/writing see the ase-extxyz sibling package.
Performance: cextxyz vs ASE built-in extxyz reader
ASE already ships a regex-based extxyz reader. The cextxyz plugin
re-parses with the libcleri-based C grammar, with PCRE2 JIT
compilation enabled both on the per-atom data regex
(PCRE2_JIT_COMPLETE + PCRE2_ANCHORED) and on libcleri's internal
regexes (so the comment-line grammar walk also runs JIT'd code).
Benchmark on a single-frame file with N Cu atoms (positions,
forces, and a couple of info keys):
| atoms / frame | file size | ASE built-in extxyz |
cextxyz plugin |
extxyz.read_dicts (no Atoms) |
speedup, plugin / built-in | speedup, parser / built-in |
|---|---|---|---|---|---|---|
| 10 | 0.00 MB | 0.107 ms | 0.074 ms | 0.119 ms | 1.46× | 0.90× |
| 100 | 0.01 MB | 0.203 ms | 0.096 ms | 0.145 ms | 2.11× | 1.41× |
| 1 000 | 0.11 MB | 1.170 ms | 0.277 ms | 0.367 ms | 4.23× | 3.18× |
| 4 000 | 0.44 MB | 4.414 ms | 0.908 ms | 1.122 ms | 4.86× | 3.93× |
| 16 000 | 1.74 MB | 17.5 ms | 3.40 ms | 3.96 ms | 5.15× | 4.42× |
| 64 000 | 6.98 MB | 69.9 ms | 13.5 ms | 15.6 ms | 5.17× | 4.48× |
| 200 000 | 21.80 MB | 218.8 ms | 42.8 ms | 49.4 ms | 5.12× | 4.43× |
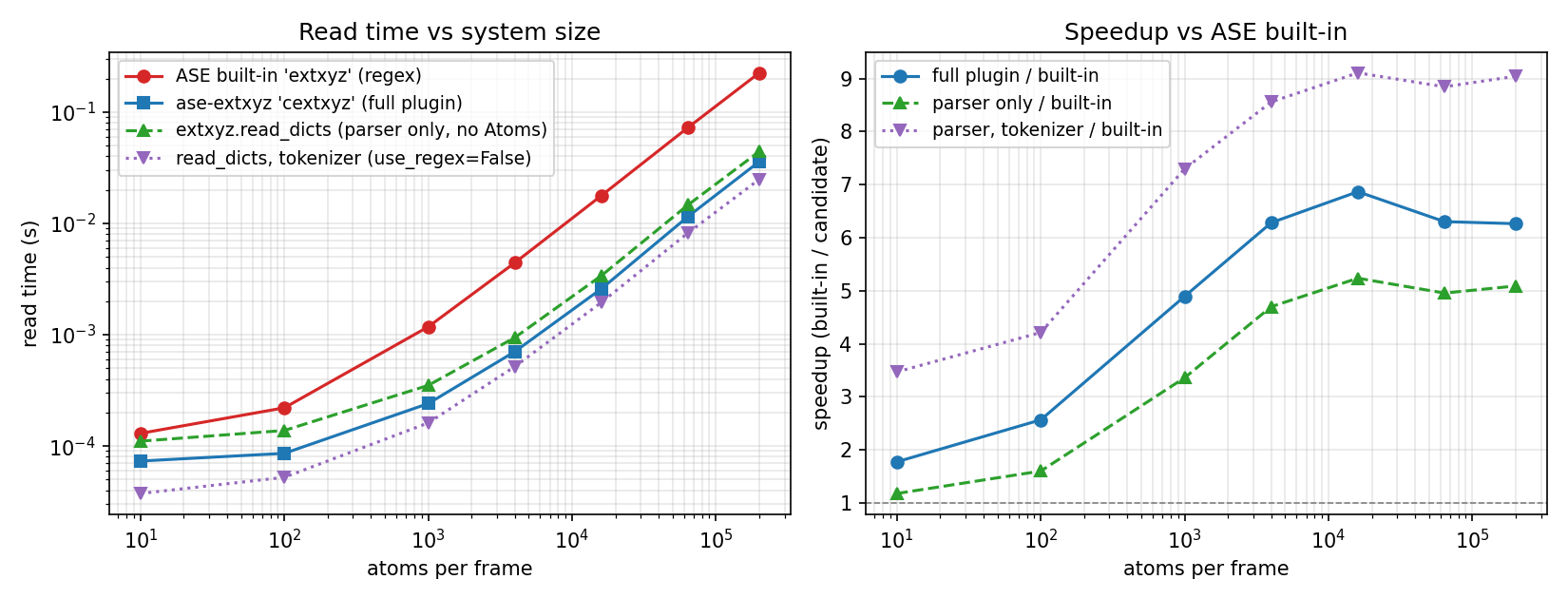
Below ~100 atoms per frame the per-call setup (file open, PCRE2 JIT
compile, libcleri grammar walk for the comment line) is larger than
the regex match itself, so the built-in is faster on tiny files. From
~1 000 atoms upwards the parser dominates and cextxyz runs at a
steady ~5× over the built-in end-to-end (~4.4× for the parser alone).
The two cextxyz curves track each other closely: the Frame → Atoms
translation in the ASE plugin is kept cheap by aliasing the parser's
per-atom buffers directly into atoms.arrays (so Atoms.__init__
doesn't memcpy positions) and vectorising the species → atomic-number
lookup with np.unique instead of a per-atom dict walk.
The parser-side numbers also reflect three later read-path changes:
dropping a redundant per-frame array copy; storing each per-atom
string column as one contiguous fixed-width buffer (so the C reader
does a single allocation per column instead of one malloc per atom,
and Python decodes the whole column with a single np.frombuffer
instead of a per-atom loop); and a fast path for parsing the per-atom
floats — a plain [+-]?int[.frac] with ≤ 15 significant digits is
parsed as one correctly-rounded mant / 10^frac division (bit-exact
with strtod, falling back to strtod for exponents or higher
precision). Together these are worth ~40% on a 200k-atom read (the
float fast path alone ~1.4×).
Default tokenizer (use_regex=False)
The single biggest remaining cost is the per-line pcre2_match. The default
use_regex=False in read_dicts/iread_dicts (C backend only) skips it: the
per-atom lines are split on whitespace and each field is parsed and validated by
its column type, with no regex compile or match. It is the default since
v0.4.2 (pass use_regex=True for the strict regex parser), and a further
~1.5× on top of everything above:
| atoms / frame | read_dicts (regex) |
read_dicts (use_regex=False) |
tokenizer / regex | tokenizer / built-in |
|---|---|---|---|---|
| 1 000 | 0.367 ms | 0.219 ms | 1.68× | 5.34× |
| 16 000 | 3.96 ms | 2.63 ms | 1.50× | 6.66× |
| 64 000 | 15.6 ms | 10.4 ms | 1.50× | 6.70× |
| 200 000 | 49.4 ms | 32.9 ms | 1.50× | 6.64× |
It validates each field (a malformed numeric/bool or the wrong field count is a
clear parse error, not a silent 0) and is bit-identical to the regex parser on
valid input. The trade-off is that it is marginally more lenient than the grammar
on a few numeric edge cases (e.g. leading-zero integers 007, 1./.5); pass
use_regex=True if you need the grammar enforced exactly.
Marshalling in C
Once the C reader has parsed a frame it has to hand the info/arrays data
back to Python. This is done inside the _extxyz extension (numpy C-API):
each frame's dict of scalars and numpy arrays is built directly in C, rather
than walking the C linked list one field at a time through ctypes. It is
bit-identical to the previous path (and falls back to it automatically if the
extension was built without numpy). The win is per-frame, so it matters most on
files with many small frames and/or rich comment lines, where per-frame
overhead — not per-atom parsing — dominates. On the large single-frame Cu
benchmark above the effect is small; on a 76k-frame, ~27-atom-per-frame training
set it cut the dict-level parse from ~3.6 s to ~2.3 s (~1.5×) and the
full ASE read from ~4.8 s to ~3.3 s, removing essentially all of the
former per-field ctypes cost.
The big parser-side lever was PCRE2 JIT (pcre2_jit_compile(re, PCRE2_JIT_COMPLETE) after pcre2_compile); a sample-based profile
of the pre-JIT code attributed ~38 % of CPU to the per-atom
pcre2_match and another ~14 % to libcleri's regex matching during
the comment-line grammar walk. The same JIT call now wraps both call
sites (the libcleri side via libAtoms/libcleri PR #2). On Linux,
both call sites detect when running under valgrind via the
LD_PRELOAD it injects and skip JIT compilation — PCRE2 JIT
intentionally reads bytes past the input end as a speed trick, which
valgrind reports as uninitialised-value warnings (PCRE2 docs
explicitly call this out).
Reproduce locally (requires extxyz, ase-extxyz, ase, matplotlib):
python benchmarks/bench_read.py --max-atoms 200000 --repeats 3
python benchmarks/plot_bench.py
# writing (see below):
python benchmarks/bench_write.py --max-atoms 200000 --repeats 5
python benchmarks/plot_bench.py --in benchmarks/write_results.csv --out benchmarks/write_speedup.png
Writing
The same cextxyz machinery writes too, a steady ~5–6× faster than ASE's
built-in extxyz writer across the same single-frame Cu files (and ~3× faster
than extxyz-ng):
| atoms / frame | file size | ASE built-in extxyz |
cextxyz plugin |
extxyz.write_dicts (no Atoms) |
speedup, plugin / built-in | speedup, writer / built-in |
|---|---|---|---|---|---|---|
| 1 000 | 0.11 MB | 2.800 ms | 0.639 ms | 0.547 ms | 4.39× | 5.11× |
| 4 000 | 0.44 MB | 10.9 ms | 2.391 ms | 2.163 ms | 4.55× | 5.03× |
| 16 000 | 1.74 MB | 43.9 ms | 8.426 ms | 7.273 ms | 5.21× | 6.03× |
| 64 000 | 6.98 MB | 166.6 ms | 31.6 ms | 28.2 ms | 5.26× | 5.92× |
| 200 000 | 21.80 MB | 521.3 ms | 106.7 ms | 92.5 ms | 4.88× | 5.64× |
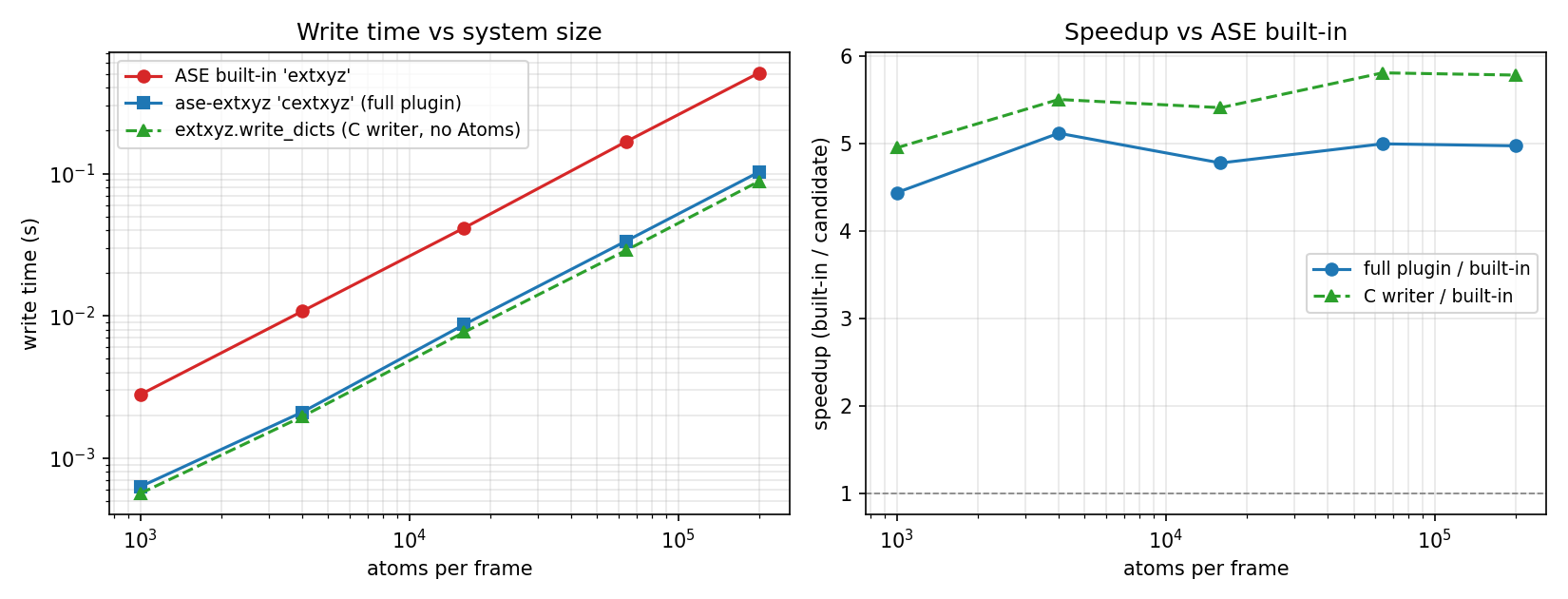
Writing is bounded by formatting the per-atom floats, not I/O. The C writer (a)
builds each line in a memory buffer and fwrites it in blocks rather than one
fprintf per value, and (b) formats the default "%16.8f" floats with a custom
exact integer routine instead of snprintf. A double is m·2^e exactly and
10^8 = 2^8·5^8, so v·10^8 = m·390625·2^(e+8) is an exact rational that we round
to nearest (ties to even) with integer-only arithmetic — bit-for-bit identical
to printf, validated against snprintf over tens of millions of values
(libextxyz/test_fmt_float.c, run by meson test). It falls back to snprintf
for non-finite / very large values, for any custom format_dict, and on compilers
without 128-bit ints (MSVC). The pure-Python (np.savetxt) writer matches ASE;
benchmarks/bench_write.py reproduces the comparison (and times extxyz-ng if
EXTXYZ_NG_PYTHON points at a venv with it).
libextxyz C library and standalone executables
The C parser, the standalone libextxyz shared library, and the C-only
cextxyz test driver are all Meson targets. To build them outside of the
Python wheel flow:
meson setup builddir
meson compile -C builddir extxyz cextxyz # libextxyz.{so,dylib,dll} + cextxyz
meson install -C builddir # installs libextxyz under --prefix
The Meson build picks up PCRE2 via pkg-config, falling back to a bundled WrapDB build of PCRE2 if no system copy is found.
Fortran bindings
To build the fextxyz executable demonstrating the Fortran bindings, you
first need to compile QUIP's libAtoms
library. QUIP now uses Meson too:
git clone --recursive https://github.com/libAtoms/QUIP
meson setup QUIP/builddir QUIP -Dgap=true -Dmpi=false
meson compile -C QUIP/builddir libAtoms f90wrap_stub
Then point this project's Meson build at the resulting library and module
directories — the fextxyz target is opt-in via the quip_lib_dir and
quip_mod_dir options:
QUIP_LIB_DIR=$PWD/QUIP/builddir/src/libAtoms
QUIP_MOD_DIR=$(find "$QUIP_LIB_DIR" -iname 'libatoms_module.mod' -printf '%h\n' | head -1)
meson setup builddir \
-Dquip_lib_dir="$QUIP_LIB_DIR" \
-Dquip_mod_dir="$QUIP_MOD_DIR"
meson compile -C builddir fextxyz
The Fortran bindings will later be moved to QUIP, since they are tied to QUIP's Dictionary and Atoms types.
Julia bindings
Julia bindings are distributed in a separate package, named ExtXYZ.jl. See its documentation for further details.
Usage
As of v0.3.0 the extxyz package is a standalone parser with no ASE
dependency; ASE integration lives in the separate
ase-extxyz plugin.
Native API — Frame dicts (no ASE)
read_dicts / iread_dicts / write_dicts work with lightweight Frame
objects exposing .natoms, .cell, .pbc, .info and .arrays:
import extxyz
# read every frame (eager) or stream them lazily
frames = extxyz.read_dicts("filename.xyz") # Frame, or list[Frame]
for frame in extxyz.iread_dicts("trajectory.xyz"):
print(frame.natoms, frame.cell, frame.info, list(frame.arrays))
# read just the first frame, then write it back out
frame = extxyz.read_dicts("filename.xyz", index=0)
extxyz.write_dicts("newfile.xyz", frame)
index accepts an int, a slice, or ':' (negative indices are not
supported). Pass use_cextxyz=False for the pure-Python parser, or
use_regex=True (C backend) for the strict regex parser instead of the
default whitespace tokenizer.
With ASE — the ase-extxyz plugin
Once ase-extxyz is installed, ASE discovers the cextxyz format
automatically (no explicit import needed):
import ase.io
from ase.build import bulk
frames = [bulk("Cu") * 3 for _ in range(3)]
for f in frames:
f.rattle()
ase.io.write("filename.xyz", frames, format="cextxyz")
atoms = ase.io.read("filename.xyz", format="cextxyz", index=0) # first frame
images = ase.io.read("filename.xyz", format="cextxyz", index=":") # all frames
To attach to an ASE optimizer or dynamics (keeps the file open across steps
instead of re-opening it each iteration), use ExtXYZTrajectoryWriter:
from ase_extxyz.io import ExtXYZTrajectoryWriter
from ase.optimize import LBFGS
with ExtXYZTrajectoryWriter("opt.xyz", atoms=atoms) as traj:
opt = LBFGS(atoms)
opt.attach(traj, interval=1)
opt.run(fmax=1e-3)
Command-line tool
The extxyz package installs an extxyz command-line tool (equivalently
python -m extxyz) for quick reading and round-tripping; see extxyz -h.
Remaining issues
make treatement of 9 elem old-1d consistent: now extxyz.py always reshapes (not just Lattice) to 3x3, but extxyz.c does not.- Since we're using python regexp/PCRE, we could make per-atom strings be more complex, e.g. bare or quoted strings from key-value pairs. Should we?
- Decide what to do about unparseable comment lines. Just assume an old fashioned xyz with an arbitrary line, or fail? I don't think we really want every parsing breaking typo to result in plain xyz.
- Used to be able to quote with {}. Do we want to support this?
Extended XYZ specification
General formatting
- Allowed characters: printable subset of ASCII, single byte
- Allowed whitespace: plain space and tab (no fancy unicode nonbreaking space, etc)
- Allowed end-of line (EOL) characters set by implementation + OS
- pure python: whatever is used to return lines by file object iterator
- low level c: fgets()
- Blank lines: allowed only as 2nd line of each frame (for plain xyz) and at end of file
General definitions
- regex: PCRE/python regular expression
- Whitespace: regex \s, i.e. space and tab
Primitive Data Types
String
Sequence of one or more allowed characters, optionally quoted, but must be quoted in some circumstances.
- Allowed characters - all except newline
- Entire string may be surrounded by double quotes, as first and last characters (must match). Quotes inside string that are same as containing quotes must be escaped with backslash. Outermost double quotes are not considered part of string value.
- Strings that contain any of the following characters must be quoted (not just backslash escaped)
- whitespace (regex \s)
- equals =
- double quote ", must be represented by \"
- comma ,
- open or close square bracket [ ] or curly brackets { }
- backslash, must be represented by double backslash \\
- newline, must be represented by \n
- Backslash \: only present in quoted strings, only used for escaping next character. All backslash escaped characters are the following character itself except \n, which encodes a newline.
- Must conform to one of the following regex
- quoted string: (")(?:(?=(\\?))\2.)*?\1
- bare (unquoted) string: (?:[^\s=",}{\]\[\\]|(?:\\[\s=",}{\]\[\\]))+
- only used in comment line key-value pairs, not per-atom data
Simple string
Sequence of one or more allowed characters, unquoted (so even outermost quotes are part of string), and without whitespace
- allowed characters - regex \S, i.e. all except newline and whitespace
- regex \S+
- only used in per-atom data, not comment line key-value pairs
Logical/boolean
- T or F or [tT]rue or [fF]alse or TRUE or FALSE
- regex
- true: (?:[tT]rue|TRUE|T)\b
- false: (?:[fF]alse|FALSE|F)\b
Integer number
string of one or more decimal digits, optionally preceded by sign
- regex [+-]?+(?:0|[1-9][0-9]*)+\b
Floating point number
- optional leading sign [+-], decimal number including optional decimal point ., optional [dDeE] folllowed by exponent consisting of optional sign followed by string of one or more digits
- regex
- integer without leading sign bare_int = '(?:0|[1-9][0-9]*)'
- optional sign opt_sign = '[+-]?'
- floating number with decimal point float_dec = '(?:' + bare_int + '\.|\.)[0-9]*'
- exponent exp = '(?:[dDeE]'+opt_sign+'[0-9]+)?'
- end of number num_end = '(?:\b|(?=\W)|$)'
- combined float regexp opt_sign + '(?:' + float_dec + exp + '|' + bare_int + exp + '|' + bare_int + ')' + num_end
Order for identifying primitive data types, accept first one that matches
- int
- float
- bool
- bare string (containing no whitespace or special characters)
- quoted string (starting and ending with double quote and containing only allowed characters)
one dimensional array (vector)
sequence of one or more of the same primitive type
- new style: opens with [, one or more of the same primitive type separated by commas and optional whitespace, ends with ]
- backward compatible: opens with ", ' or {, one or more of the same primitive types (all types allowed in {}, all except string in "" and '') separated by whitespace, ends with matching ", ' or }. Single and double quotes are equivalent containers (ints/floats/bools, no strings). For backward compatibility, a single element backward compatible array is interpreted as a scalar of the same type.
- primitive data type is determined by same priority as single primitive item, but must be satisfied by entire list simultaneously. E.g. all integers will result in an integer array, but a mix of integer and float will result in a float array, and a mix of integer and valid strings will results in a string array.
two dimensional array (matrix)
sequence of one or more new style one dimensional arrays of the same length and type
- opens with [, one or more new style one dimensional arrays separated by commas, ends with ]
- all contained one dimensional arrays in a single two dimensional array must have same number and primitive data type elements, and will be promoted to other possible types if necessary to parse entire array. E.g. a row of integers followed by a row of strings will be promoted to a 2-d string array.
XYZ file
A concatenation of 1 or more FRAMES (below), with optional blank lines at the end (but not between frames)
FRAME
- Line 1: a single integer <N> preceded and followed by optional whitespace
- Line 2: zero or more per-config key=value pairs (see key-value pairs below)
- Lines 3..N+2: per-atom data lines with M columns each (see Properties and Per-Atom Data below)
key=value pairs on second ("comment") line
Associates per-configuration value with key. Spaces are allowed around = sign, which do not become part of the key or value.
Key: bare or quoted string
Value: primitive type, 1-D array, or 2-D array. Type is determined from context according to order specified above.
Special key "Properties”: defines the columns in the subsequent lines in the frame.
- Value is a string with the format of a series of triplets, separated by “:”, each triplet having the format: “<name>:<T>:<m>”.
- The <name> (string) names the column(s), <T> is a one of “S”, “I”, “R”, “L”, and indicates the type in the column, “string”, “integer”, “real”, “logical”, respectively. <m> is an integer > 0 specifying how many consecutive columns are being referred to.
- The sum of the counts "m" must equal number of per-atom columns M (as defined in FRAME)
- If after full parsing the key “Properties” is missing, the format is retroactively assumed to be plain xyz (4 columns, Z/species x y z), the entire second line is stored as a per-config “comment” property, and columns beyond the 4th are not read.
Per-atom data lines
Each column contains a sequence of primitive types, except string, which is replaced with simple string, separated by one or more whitespace characters, ending with EOL (optional for last line). The total number of columns in each row must be equal to the M and to the sum of the counts "m" in the "Properties" value string.
READING ase.atoms.Atoms FROM THIS FORMAT
Specific keys indicate special values, with specific order for overriding
Key-value pairs:
- Lattice -> Atoms.cell, optional [do we want to accept "cell" also?]
- 3x3 matrix - rows are cell vectors [preferred]
- 9-vector - 3 cell vectors concatenated [only for backward compat]
- 3-vector - diagonal entries of cell matrix [?]
- pbc -> Atoms.pbc, optional
- 3-vector of bool
- default [False]*3 if no Lattice, otherwise [True]*3
- Calculator results, used to set SinglePointCalculator.results dict
- all per-config properties in ase.calculator.all_properties, with same name
- scalars, vectors - directly stored
- stress
- 6-vector Voigt
- 9-vector, 3x3 matrix, stored as stress Voigt-6, fail if not symmetric
- virial -> stress (to convert multiply by -1/cell_vol), same format as stress [warn/fail if stress also present, perhaps only if inconsistent?]
Properties keys (all types are per-atom), types are simple
- Atoms
- Z -> numbers
- species -> numbers, fail if not valid chemical symbol [warn/fail if conflict with Z?]
- pos -> positions
- mass -> masses
- velo -> momenta (get mass from atomic number if missing)
- same name: initial_charges, initial_magmoms
- Calculator.results
- local_energy -> energies
- forces -> forces [also support “force”? What about overriding, complain if inconsistent?]
- same name: magmoms (scalar or 3-vector), charges
WRITING ase.atoms.Atoms TO THIS FORMAT
General considerations
- platform-appropriate EOL
- [require some specific whitespace convention?]
- scalars
- all strings are quoted
- otherwise stored unquoted
- arrays
- use {} [or []?] container marks, comma separated (not backward compatible " and space separated forms)
- Definitely store (naming as described below)
- all "first-class" Atoms properties (cell, pbc, numbers, masses, positions, momenta [any others?])
- all info keys that are scalar, 1-D, 2-D array of prim type
- all arrays that are scalar (Natoms x 1) or 1-D array( Natoms x (m > 1)) of prim type, shape[1] mapped to number of columns and space separated, not using regular array notation
- [optionally warn about un-representable quantities?]
- all Calculator.results key-value pairs, per-config same as info, per-atom same as arrays
- Perhaps store
- all info keys, per-config calculator results that are not representable (i.e. not prim type scalar, 1-D, or 2-D for per-config only) but can be mapped to JSON, as string starting with "_JSON "
- same for arrays [?]
- In general, keep ASE data type/dimension, invert mapping of names for reading. For quantities that have multiple possible names, use:
- Lattice, not cell, 3x3 matrix
- velo, not momenta
- stress, not virial, as 3x3 matrix [are we OK with this?]
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file extxyz-0.4.3-cp313-cp313-win_amd64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp313-cp313-win_amd64.whl
- Upload date:
- Size: 297.4 kB
- Tags: CPython 3.13, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3005357c10d79f591f40942ee63c36773386bd31313c86332230faea4ca65ad6
|
|
| MD5 |
56cc21a7fea7e6b6426c64c2bdd79526
|
|
| BLAKE2b-256 |
bf58e221179fbdf798442d6590f8dc3f45cc586b15f142c525c0067ba9ac8933
|
File details
Details for the file extxyz-0.4.3-cp313-cp313-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp313-cp313-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 274.7 kB
- Tags: CPython 3.13, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c82e19e9428a40c010d279d8f8cb6a1b22bc4a55a51c8db7524f7bb1f2481466
|
|
| MD5 |
27f49f442f48538adafd435ad1ef45ac
|
|
| BLAKE2b-256 |
01b21a6f6bec4cd204b5e38ec537b796d75c464e9bbb3359193a66cb6d36b850
|
File details
Details for the file extxyz-0.4.3-cp313-cp313-macosx_11_0_x86_64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp313-cp313-macosx_11_0_x86_64.whl
- Upload date:
- Size: 268.0 kB
- Tags: CPython 3.13, macOS 11.0+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4b896b6953b7a5ad9c66731668edad8239125d761b8eddd0d979103d8f5bc582
|
|
| MD5 |
991720f513f08fae5ccbc1b5652d5968
|
|
| BLAKE2b-256 |
4e1f991c8cfaaa768cff4d8551246490269ce2467b938c488180cd2fb85ffcbe
|
File details
Details for the file extxyz-0.4.3-cp313-cp313-macosx_11_0_arm64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp313-cp313-macosx_11_0_arm64.whl
- Upload date:
- Size: 279.1 kB
- Tags: CPython 3.13, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c279e1ee2ccf6ea9fac56d2d05cadbf426212fb27b7f867ea7a8f17d452bb26b
|
|
| MD5 |
77a14c360b3eae713ab9a593f435e036
|
|
| BLAKE2b-256 |
b8b48633ec47aff9663d7b6c65317950474e12e1034a0594903c181fc2009e8b
|
File details
Details for the file extxyz-0.4.3-cp312-cp312-win_amd64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp312-cp312-win_amd64.whl
- Upload date:
- Size: 297.4 kB
- Tags: CPython 3.12, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a0dd392dafb384ac6a1202870b8aec7301eece3d893c1be321215c067b405880
|
|
| MD5 |
03a0a53782b2170c5ef4f75353cbbf58
|
|
| BLAKE2b-256 |
8b862865776831921a96f5d3c9ce730ace34f7f568fa1edf77e96c8ca8ae79ce
|
File details
Details for the file extxyz-0.4.3-cp312-cp312-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp312-cp312-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 274.7 kB
- Tags: CPython 3.12, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d0e39cde1836556204bf6730ba93be2bfafd92484b4c3cec1d16182feb7db97f
|
|
| MD5 |
99e5db9319cbd3cced33d7442ee50bc9
|
|
| BLAKE2b-256 |
b8e9c528f7eb79ff1bcc652dfa626459ffed6875d32070abf921f095d718143d
|
File details
Details for the file extxyz-0.4.3-cp312-cp312-macosx_11_0_x86_64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp312-cp312-macosx_11_0_x86_64.whl
- Upload date:
- Size: 268.0 kB
- Tags: CPython 3.12, macOS 11.0+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
83c26bcc19b63c4871b0bbe08233afc348a33ba4b060130485ef01cc1031cc0b
|
|
| MD5 |
fe1f43c3c5527db8287571deb71b1057
|
|
| BLAKE2b-256 |
66afacd7d8df0f97fe6023e57785aa80865b31c01bc07c425a3a5f88fdf436b9
|
File details
Details for the file extxyz-0.4.3-cp312-cp312-macosx_11_0_arm64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp312-cp312-macosx_11_0_arm64.whl
- Upload date:
- Size: 279.1 kB
- Tags: CPython 3.12, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
59808720e39502e1969b5bf1d44e54b89f968dc9c8a6296aac6981e629a8f47f
|
|
| MD5 |
f31f21e1c4a07c14571a88fb0e0e3c7a
|
|
| BLAKE2b-256 |
149b0a1451a6a821833502e4ed40ed2502f8722d3affe8cc6b310ee9e758dc8c
|
File details
Details for the file extxyz-0.4.3-cp311-cp311-win_amd64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp311-cp311-win_amd64.whl
- Upload date:
- Size: 297.4 kB
- Tags: CPython 3.11, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4e384f4bcb8397328bc736f630561c385feb8764ee34c543c7f0ae02211d0baf
|
|
| MD5 |
459531f41273d1d4ac45de98daa44d0d
|
|
| BLAKE2b-256 |
6dcc78fcfab0804f9f4244da363e3904cd7ddb0fe7de929369a5909f3454aae8
|
File details
Details for the file extxyz-0.4.3-cp311-cp311-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp311-cp311-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 274.6 kB
- Tags: CPython 3.11, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1fa488b8b3e435b87578d76849cda05be26734278d4486623a05ede3043d1f55
|
|
| MD5 |
91c03794ba1d5a1486a13cbc5b79cfbe
|
|
| BLAKE2b-256 |
500b647f9030dab9fd200b27264eb9e8ebb4364815cac66122a7d6f29bc7a260
|
File details
Details for the file extxyz-0.4.3-cp311-cp311-macosx_11_0_x86_64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp311-cp311-macosx_11_0_x86_64.whl
- Upload date:
- Size: 267.9 kB
- Tags: CPython 3.11, macOS 11.0+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
75c9c00b6a4b24082956e129ac26153daaffd6a4d35fe27663034bc61ef701f2
|
|
| MD5 |
6349b72bb8a35954d139fa058fda4b24
|
|
| BLAKE2b-256 |
c11b4f456bf73a2b2deefb035c0032c4417399a5386eca2bf3eca024b714b9b1
|
File details
Details for the file extxyz-0.4.3-cp311-cp311-macosx_11_0_arm64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp311-cp311-macosx_11_0_arm64.whl
- Upload date:
- Size: 279.0 kB
- Tags: CPython 3.11, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
79f0e44a87c32869ff62b11c6a89e417bfa924e47014c790a2ed10991b362d8b
|
|
| MD5 |
5c7f3f7f4a3f69de175c754b88da7fdc
|
|
| BLAKE2b-256 |
03ba232bfdf469da33f8b84014b13209a65b818b86ac7ad151d5e645c0969250
|
File details
Details for the file extxyz-0.4.3-cp310-cp310-win_amd64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp310-cp310-win_amd64.whl
- Upload date:
- Size: 297.4 kB
- Tags: CPython 3.10, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4a2d1bfa6a555c0e72af3de7fa8990404960c03189030f571a2a70dbf44c48a6
|
|
| MD5 |
567a0cc6f7d87b9213dee395e8867a79
|
|
| BLAKE2b-256 |
ca8e029b82966c3e7964f6a06eaa0807535067ad20bb33b20ccd84ea44c8dcfc
|
File details
Details for the file extxyz-0.4.3-cp310-cp310-manylinux_2_28_x86_64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp310-cp310-manylinux_2_28_x86_64.whl
- Upload date:
- Size: 274.6 kB
- Tags: CPython 3.10, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5311aeeed480d24dfc890217c874cf6faa316007fb74bd06bcf43ddd460c27f5
|
|
| MD5 |
ac94fbfea3cfff515612219bba2debc3
|
|
| BLAKE2b-256 |
076a3375986646d5e84202f6b563dff44ea9b432f248a15d3f09ef4c312440cf
|
File details
Details for the file extxyz-0.4.3-cp310-cp310-macosx_11_0_x86_64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp310-cp310-macosx_11_0_x86_64.whl
- Upload date:
- Size: 267.9 kB
- Tags: CPython 3.10, macOS 11.0+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cbb5cfc5255e6d3f4e7df2946806477df16a068d3b53924ee60c6ddcdb3eca99
|
|
| MD5 |
a68a684af9eb6d8f71e8f8012ec1c5f9
|
|
| BLAKE2b-256 |
258e20909f3ac2f3544a92237555553236bb2aa01f54dd83d91ef30fc36c7282
|
File details
Details for the file extxyz-0.4.3-cp310-cp310-macosx_11_0_arm64.whl.
File metadata
- Download URL: extxyz-0.4.3-cp310-cp310-macosx_11_0_arm64.whl
- Upload date:
- Size: 279.0 kB
- Tags: CPython 3.10, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8c59f1ec3acc9daa7c0948b74603ec561fe1891677cd97d3ccd34978de4012f2
|
|
| MD5 |
2e4c1856583bcb4aef89833f15b5d5ad
|
|
| BLAKE2b-256 |
43cc671a561010711f772d81703ac3b770f5cf69d88fddbe8e58695b4d50eb47
|







