A tool to fit data to many distributions and get the best one(s)

Project description





Compatible with Python 3.7, and 3.8, 3.9
What is it ?
The fitter package is a Python library used for fitting probability distributions to data. It provides a straightforward and and intuitive interface to estimate parameters for various types of distributions, both continuous and discrete. Using fitter, you can easily fit a range of distributions to your data and compare their fit, aiding in the selection of the most suitable distribution. The package is designed to be user-friendly and requires minimal setup, making it a useful tool for data scientists and statisticians working with probability distributions.
Installation
pip install fitter
fitter is also available on conda (bioconda channel):
conda install fitter
Usage
standalone
A standalone application (very simple) is also provided and works with input CSV files:
fitter fitdist data.csv --column-number 1 --distributions gamma,normal
It creates a file called fitter.png and a log fitter.log
From Python shell
First, let us create a data samples with N = 10,000 points from a gamma distribution:
from scipy import stats data = stats.gamma.rvs(2, loc=1.5, scale=2, size=10000)
Now, without any knowledge about the distribution or its parameter, what is the distribution that fits the data best ? Scipy has 80 distributions and the Fitter class will scan all of them, call the fit function for you, ignoring those that fail or run forever and finally give you a summary of the best distributions in the sense of sum of the square errors. The best is to give an example:
from fitter import Fitter f = Fitter(data) f.fit() # may take some time since by default, all distributions are tried # but you call manually provide a smaller set of distributions f.summary()
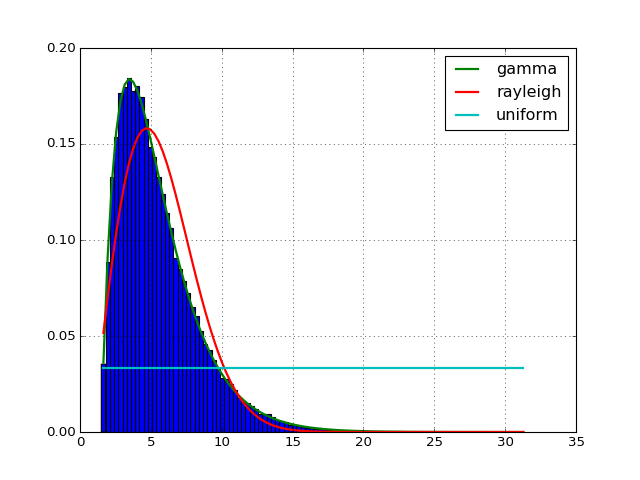
See the online documentation for details.
Contributors
Setting up and maintaining Fitter has been possible thanks to users and contributors. Thanks to all:

Changelog
Version |
Description |
|---|---|
1.7.1 |
|
1.7.0 |
|
1.6.0 |
|
1.5.2 |
|
1.5.1 |
|
1.5.0 |
|
1.4.1 |
|
1.4.0 |
|
1.3.0 |
|
1.2.3 |
|
1.2.2 |
was not released |
1.2.1 |
adding new class called histfit (see documentation) |
1.2 |
|
1.1 |
|
1.0.9 |
|
1.0.6 |
|
1.0.5 |
|
1.0.2 |
add manifest to fix missing source in the pypi repository. |
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file fitter-1.7.1.tar.gz.
File metadata
- Download URL: fitter-1.7.1.tar.gz
- Upload date:
- Size: 26.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.8.2 CPython/3.10.14 Linux/6.8.9-300.fc40.x86_64
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d9df8885f106d911c3a7ed97949b3cf3c29ec2464c529244f2434738dd6b0e50
|
|
| MD5 |
bdb812450ae863b7bff7648037f11446
|
|
| BLAKE2b-256 |
fae243c5db5bd54ab13b6535859f01e340e19e775fe0b78c299966948cfca089
|
File details
Details for the file fitter-1.7.1-py3-none-any.whl.
File metadata
- Download URL: fitter-1.7.1-py3-none-any.whl
- Upload date:
- Size: 26.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.8.2 CPython/3.10.14 Linux/6.8.9-300.fc40.x86_64
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f8419787482a4964ad33839277f056e07d08e436f7d125e713aa886403e4ad05
|
|
| MD5 |
ac402e745f87bf7f51da1a17f80b4bae
|
|
| BLAKE2b-256 |
f920e0526cff78b376e74f9e153d66b946650068bc9ff24864023a85ec963f99
|







