A Flake8 plugin to check for PySpark withColumn usage in loops
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
Flake8-pyspark-with-column


Getting started
pip install flake8-pyspark-with-column
flake8 --select PSRPK001,PSPRT002,PSPRK003,PSPRK004
Alternatively you can add the following tox.ini file to the root of your project:
[flake8]
select =
PSPRK001,
PSPRK002,
PSPRK003,
PSPRK004
About
A flake8 plugin that detects of usage withColumn in a loop or inside reduce. From the PySpark documentation about withColumn method:
This method introduces a projection internally. Therefore, calling it multiple times, for instance, via loops in order to add multiple columns can generate big plans which can cause performance issues and even StackOverflowException. To avoid this, use select() with multiple columns at once.
What happens under the hood?
When you run a PySpark application the following happens:
- Spark creates
Unresolved Logical Planthat is a result of parsing SQL - Spark do analysis of this plan to create an
Analyzed Logical Plan - Spark apply optimization rules to create an
Optimized Logical Plan
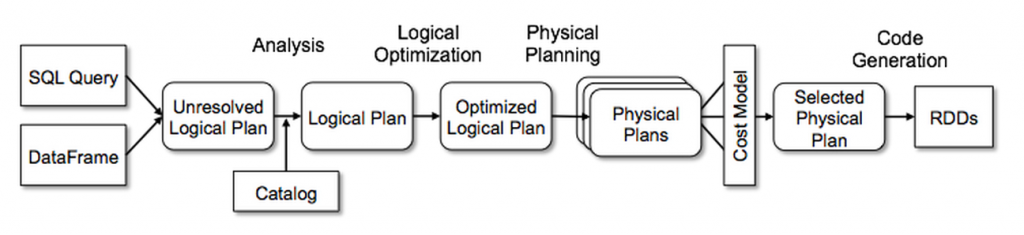
What is the problem with withColumn? It creates a single node in the unresolved plan. So, calling withColumn 500 times will create an unresolved plan with 500 nodes. During the analysis Spark should visit each node to check that column exists and has a right data type. After that Spark will start applying rules, but rules are applyed once per plan recursively, so concatenation of 500 calls to withColumn will require 500 applies of the corresponding rule. All of that may significantly increase the amount of time from Unresolved Logical Plan to Optimized Logical Plan:
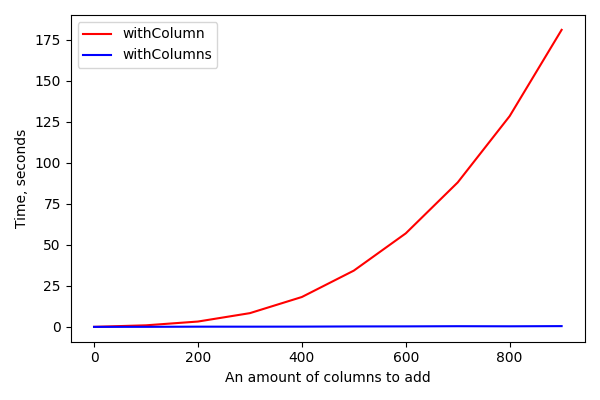
From the other side, both withColumns and select(*cols) create only one node in the plan doesn't matter how many columns we want to add.
Rules
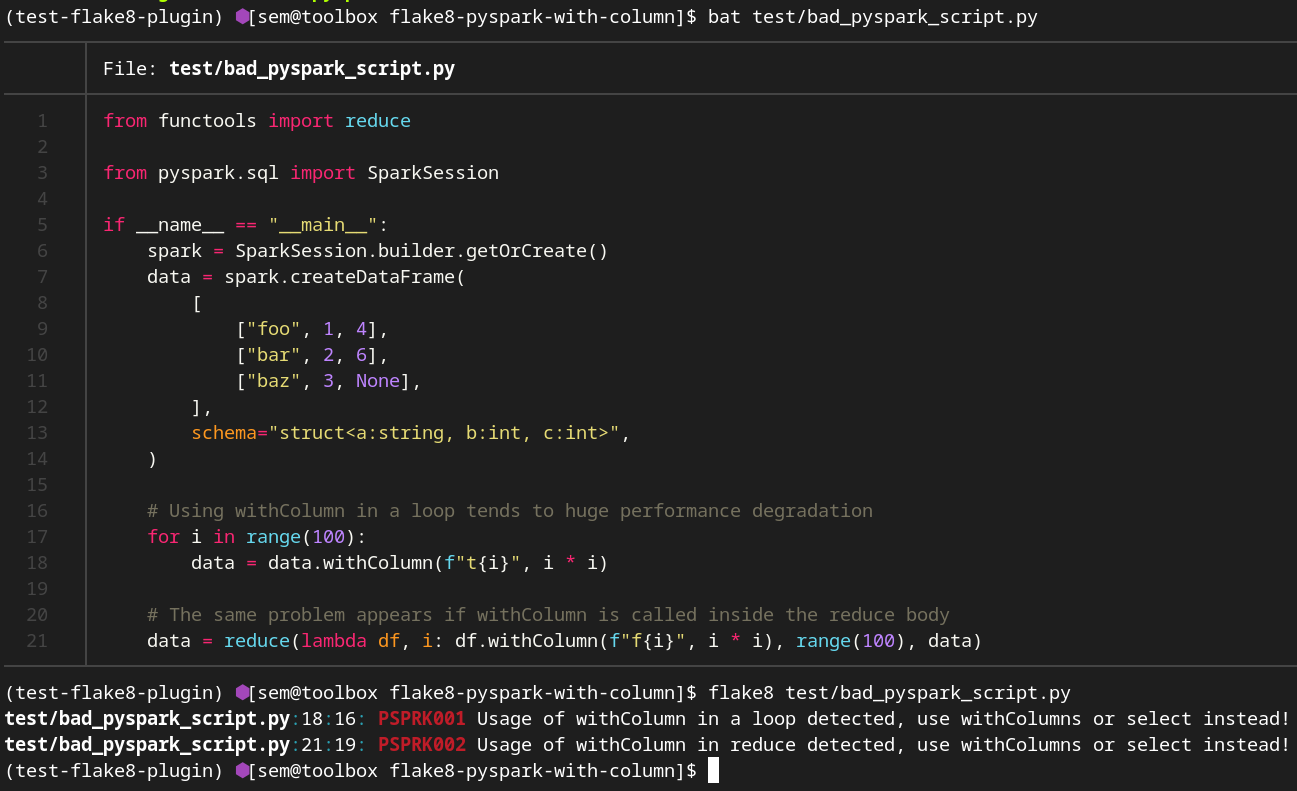
This plugin contains the following rules:
PSPRK001: Usage of withColumn in a loop detectedPSPRK002: Usage of withColumn inside reduce is detectedPSPRK003: Usage of withColumnRenamed in a loop detectedPSPRK004: Usage of withColumnRenamed inside reduce is detected
Examples
Let's imagine we want to apply an ML model to our data but our Model expects double values and our table contain decimal values. The goal is to cast all Decimal columns to Double.
Implementation with withColumn (bad example):
def cast_to_double(df: DataFrame) -> DataFrame:
for field in df.schema.fields:
if isinstance(field.dataType, DecimalType):
df = df.withColumn(field.name, col(field.name).cast(DoubleType()))
return df
Implementation without withColumn (good example):
def cast_to_double(df: DataFrame) -> DataFrame:
cols_to_select = []
for field in df.schema.fields:
if isinstance(field.dataType, DecimalType):
cols_to_select.append(col(field.name).cast(DoubleType()).alias(field.name))
else:
cols_to_select.append(col(field.name))
return df.select(*cols_to_select)
Usage
flake8 %your-code-here%
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file flake8_pyspark_with_column-0.0.5.tar.gz.
File metadata
- Download URL: flake8_pyspark_with_column-0.0.5.tar.gz
- Upload date:
- Size: 8.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.0.1 CPython/3.12.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
31d7f1753898d176783e044189b2313abd0f91d2b9769118482f0367b86db703
|
|
| MD5 |
c169083ed66a5538cbb5b0c9c426fb1d
|
|
| BLAKE2b-256 |
7636a3c92ea2c709f1005769403ad3200d653e3c5cfc12ae7aa8bb03f321ecc4
|
Provenance
The following attestation bundles were made for flake8_pyspark_with_column-0.0.5.tar.gz:
Publisher:
python-publish.yml on SemyonSinchenko/flake8-pyspark-with-column
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
flake8_pyspark_with_column-0.0.5.tar.gz -
Subject digest:
31d7f1753898d176783e044189b2313abd0f91d2b9769118482f0367b86db703 - Sigstore transparency entry: 162555019
- Sigstore integration time:
-
Permalink:
SemyonSinchenko/flake8-pyspark-with-column@f0b327c6e2904694b997438760bb17507f90b106 -
Branch / Tag:
refs/tags/0.0.5 - Owner: https://github.com/SemyonSinchenko
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
python-publish.yml@f0b327c6e2904694b997438760bb17507f90b106 -
Trigger Event:
release
-
Statement type:
File details
Details for the file flake8_pyspark_with_column-0.0.5-py2.py3-none-any.whl.
File metadata
- Download URL: flake8_pyspark_with_column-0.0.5-py2.py3-none-any.whl
- Upload date:
- Size: 8.2 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.0.1 CPython/3.12.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cf7326fac2ccc85520a3d55bd69057bea1f810ab13e098066a23094300365662
|
|
| MD5 |
2c8c2e4e411ec6cb1da3bf8e442c2978
|
|
| BLAKE2b-256 |
5d475808db024a41366ecd8d537f222f2fc932122e9d561d7daa0a06dbf6b497
|
Provenance
The following attestation bundles were made for flake8_pyspark_with_column-0.0.5-py2.py3-none-any.whl:
Publisher:
python-publish.yml on SemyonSinchenko/flake8-pyspark-with-column
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
flake8_pyspark_with_column-0.0.5-py2.py3-none-any.whl -
Subject digest:
cf7326fac2ccc85520a3d55bd69057bea1f810ab13e098066a23094300365662 - Sigstore transparency entry: 162555022
- Sigstore integration time:
-
Permalink:
SemyonSinchenko/flake8-pyspark-with-column@f0b327c6e2904694b997438760bb17507f90b106 -
Branch / Tag:
refs/tags/0.0.5 - Owner: https://github.com/SemyonSinchenko
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
python-publish.yml@f0b327c6e2904694b997438760bb17507f90b106 -
Trigger Event:
release
-
Statement type:







