FlashBertTokenizer implementation with C++ backend

Project description

Tokenizer Library for LLM Serving
EFFICIENT AND OPTIMIZED TOKENIZER ENGINE FOR LLM INFERENCE SERVING
FlashTokenizer is a high-performance tokenizer implementation in C++ of the BertTokenizer used for LLM inference. It has the highest speed and accuracy of any tokenizer, such as FlashAttention and FlashInfer, and is 4-5 times faster than BertTokenizerFast in transformers.
[!NOTE]
FlashBertTokenizeris 4x faster thantransformers.BertTokenizerFastand 15.5x faster thantransformers.BertTokenizer.




FlashTokenizer includes the following core features
[!TIP]
Implemented in C++17 and is fastest when built with GNUC.
- MacOS:
g++(14.2.0)is faster thanclang++(16.0.0).- Windows:
g++(8.1.0)-MinGW64is faster thanVisual Studio 2019.- Ubuntu:
g++(11.4.0)is faster thanclang++(14.0.0).Equally fast in Python via pybind11.
Blingfire was difficult to use in practice due to its low accuracy, but FlashBertTokenizer has both high accuracy and high speed.
Although it's only implemented as a single thread, it's capable of 40K RPS in C++ and 25K RPS in Python, and it's thread-safe, so you can go even faster with multi-threading if you need to.
News
[!IMPORTANT]
[Mar 10 2025] Performance improvements through faster token mapping with robin_hood and memory copy minimization with std::list.
Container Elapsed Time Max RPS Description std::list 10.3458 39660.5 When combining containers, std::list is the fastest because it doesn't allocate extra memory and just appends to the end. std::deque 15.3494 26473.1 Because it is organized in chunks, it requires memory allocation even when combining containers and has the slowest performance due to its low cache hit rather than contiguous memory. std::vector 11.9718 33913.3 It allocates new memory each time when combining containers, but it has a high cache hit for fast performance. Token Ids Map Table Performance Test.
Token and Ids Map used the fastest unordered_flat_map as shown in the test results below.
Map Elapsed Time(Access) ✅ robin_hood::unordered_flat_map<std::string, int> 0.914775 robin_hood::unordered_node_map<std::string, int> 0.961003 robin_hood::unordered_map<std::string, int> 0.917136 std::unordered_map<std::string, int, XXHash> 1.1506 std::unordered_map<std::string, int> 1.20015 XXHash is implemented as follows.
#define XXH_STATIC_LINKING_ONLY #define XXH_INLINE_ALL #include "xxhash.h" struct XXHash { size_t operator()(const std::string &s) const { return XXH3_64bits(s.data(), s.size()); } };[Mar 09 2025] Completed development of flash-tokenizer for BertTokenizer.
1. Installation
Requirements
- g++ / clang++ / MSVC
- python3.9 ~ 3.13
Install from PIP
pip install -U flash-tokenizer
Install from Source
git clone https://github.com/NLPOptimize/flash-tokenizer
cd flash-tokenizer
pip install -r requirements.txt
python -m build # `*.whl` file will be created in the `dist` folder.
2. Usage
from flash_tokenizer import FlashBertTokenizer
tokenizer = FlashBertTokenizer("path/to/vocab.txt", do_lower_case=True)
# Tokenize text
ids = tokenizer("Hello, world!")
print(ids)
3. Other Implementations





Most BERT-based models use the WordPiece Tokenizer, whose code can be found here. (A simple implementation of Huggingface can be found here).
Since the BertTokenizer is a CPU intensive algorithm, inference can be a bottleneck, and unoptimized tokenizers can be severely slow. A good example is the BidirectionalWordpieceTokenizer introduced in KR-BERT. Most of the code is the same, but the algorithm traverses the sub token backwards and writes a larger value compared to the forward traversal. The paper claims accuracy improvements, but it's hard to find other quantitative metrics, and the accuracy improvements aren't significant, and the tokenizer is seriously slowed down.
- transformers (Rust Impl, PyO3)
- paddlenlp (C++ Impl, pybind)
- tensorflow-text (C++ Impl, pybind)
- blingfire (C++ Impl, Native binary call)
Most developers will either use transformers.BertTokenizer or transformers.AutoTokenizer, but using AutoTokenizer will return transformers.BertTokenizerFast.
Naturally, it's faster than BertTokenizer, but the results aren't exactly the same, which means you're already giving up 100% accuracy starting with the tokenizer.
BertTokenizer is not only provided by transformers. PaddleNLP and tensorflow-text also provide BertTokenizer.
Then there's Blingfire, which is developed by Microsoft and is being abandoned.
PaddleNLP requires PaddlePaddle and provides tokenizer functionality starting with version 3.0rc. You can install it as follows
##### Install PaddlePaddle, PaddleNLP
python -m pip install paddlepaddle==3.0.0b1 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
pip install --upgrade paddlenlp==3.0.0b3
##### Install transformers
pip install transformers==4.47.1
##### Install tf-text
pip install tensorflow-text==2.18.1
##### Install blingfire
pip install blingfire
With the exception of blingfire, vocab.txt is all you need to run the tokenizer right away. (blingfire also requires only vocab.txt and can be used after 8 hours of learning).
The implementations we'll look at in detail are PaddleNLP's BertTokenizerFast and blingfire.
blingfire: Uses a Deterministic Finite State Machine (DFSM) to eliminate one linear scan and unnecessary comparisons, resulting in a time of O(n), which is impressive.- Advantages: 5-10x faster than other implementations.
- Disadvantages: Long training time (8 hours) and lower accuracy than other implementations. (+Difficult to get help due to de facto development hiatus).
PaddleNLP: As shown in the experiments below, PaddleNLP is always faster than BertTokenizerFast (HF) to the same number of decimal places, and is always faster on any OS, whether X86 or Arm.- Advantages: Internal implementation is in C++ Compared to
transformers.BertTokenizerFastimplemented in Rust, it is 1.2x faster while outputting exactly the same values.- You can't specify
pt(pytorch tensor)inreturn_tensors, but this is not a problem.[^1]
- You can't specify
- Disadvantages: none, other than the need to install PaddlePaddle and PaddleNLP.
- Advantages: Internal implementation is in C++ Compared to
4. Performance test
4.1 Performance test (Batch text encoding)
The graph below compares transformers.BertTokenizerFast and paddlenlp.transformers.bert.tokenizer_fast.BertTokenizerFast for batch size.
Both libraries are faster to return as np.ndarray. Perhaps the implementations have logic to convert to pt or pd at the end, which takes longer.
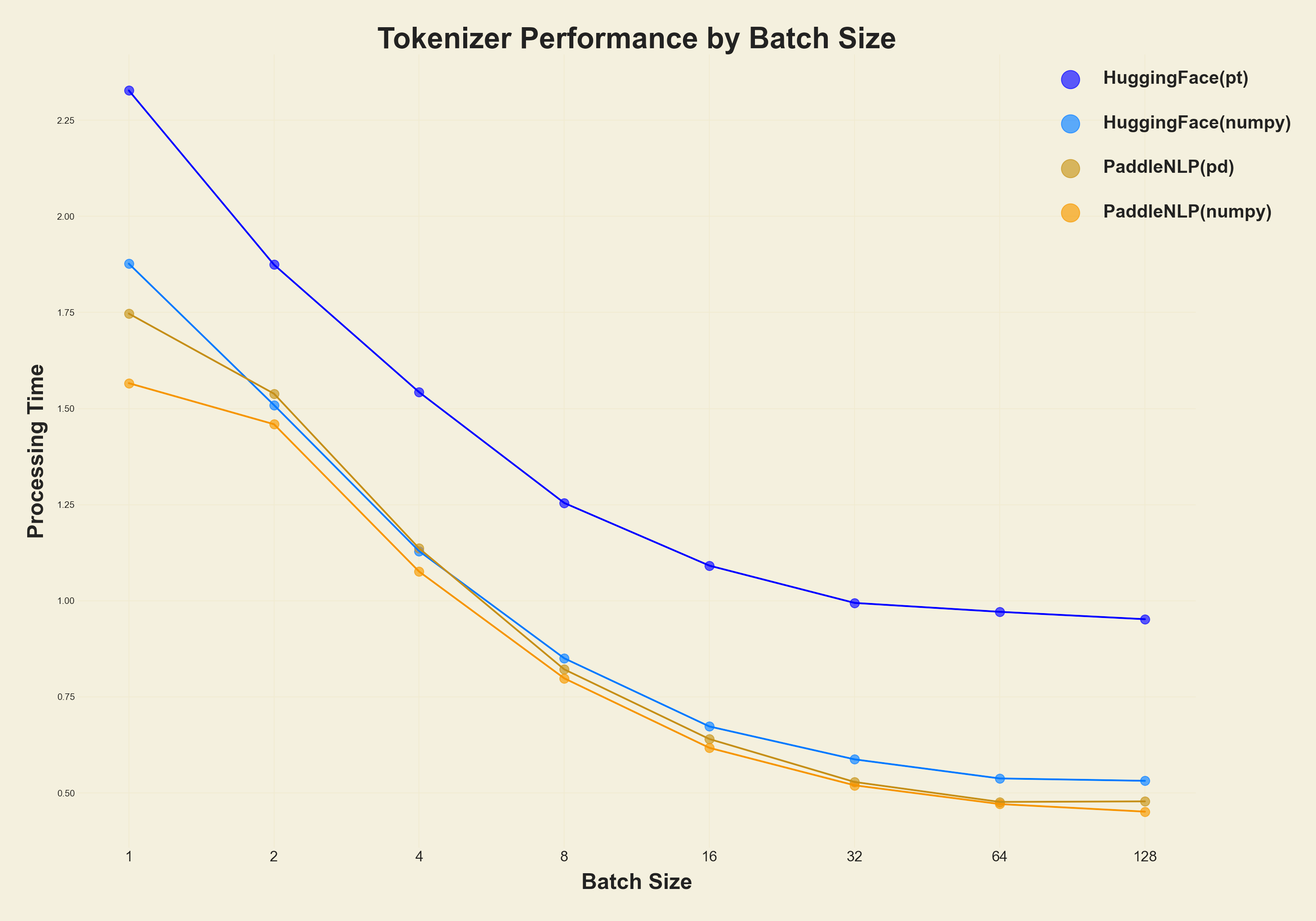
| BatchSize | transformers(pt) | paddlenlp(pd) | transformers(np) | paddlenlp(np) |
|---|---|---|---|---|
| 1 | 2.32744 | 1.74695 | 1.87685 | 1.56597 |
| 2 | 1.87427 | 1.53865 | 1.50911 | 1.45918 |
| 4 | 1.54254 | 1.13622 | 1.12902 | 1.07593 |
| 8 | 1.25432 | 0.821463 | 0.850269 | 0.798163 |
| 16 | 1.09129 | 0.640243 | 0.67293 | 0.617309 |
| 32 | 0.994335 | 0.528553 | 0.587379 | 0.519887 |
| 64 | 0.971175 | 0.476652 | 0.537753 | 0.471145 |
| 128 | 0.952003 | 0.478113 | 0.531592 | 0.451384 |
[^1]: As you can see in the graph above, returning to pt(pytorch tensor)' becomes very slow.
4.2 Performance test (Single text encoding)
Accuracy is the result of measuring transformers.BertTokenizer as a baseline. If even one of the input_ids is incorrect, the answer is considered incorrect.
Surprisingly, the performance of tensorflow-text is much faster than before. However, there is still no advantage for `tensorflow-text' when comparing the four libraries.
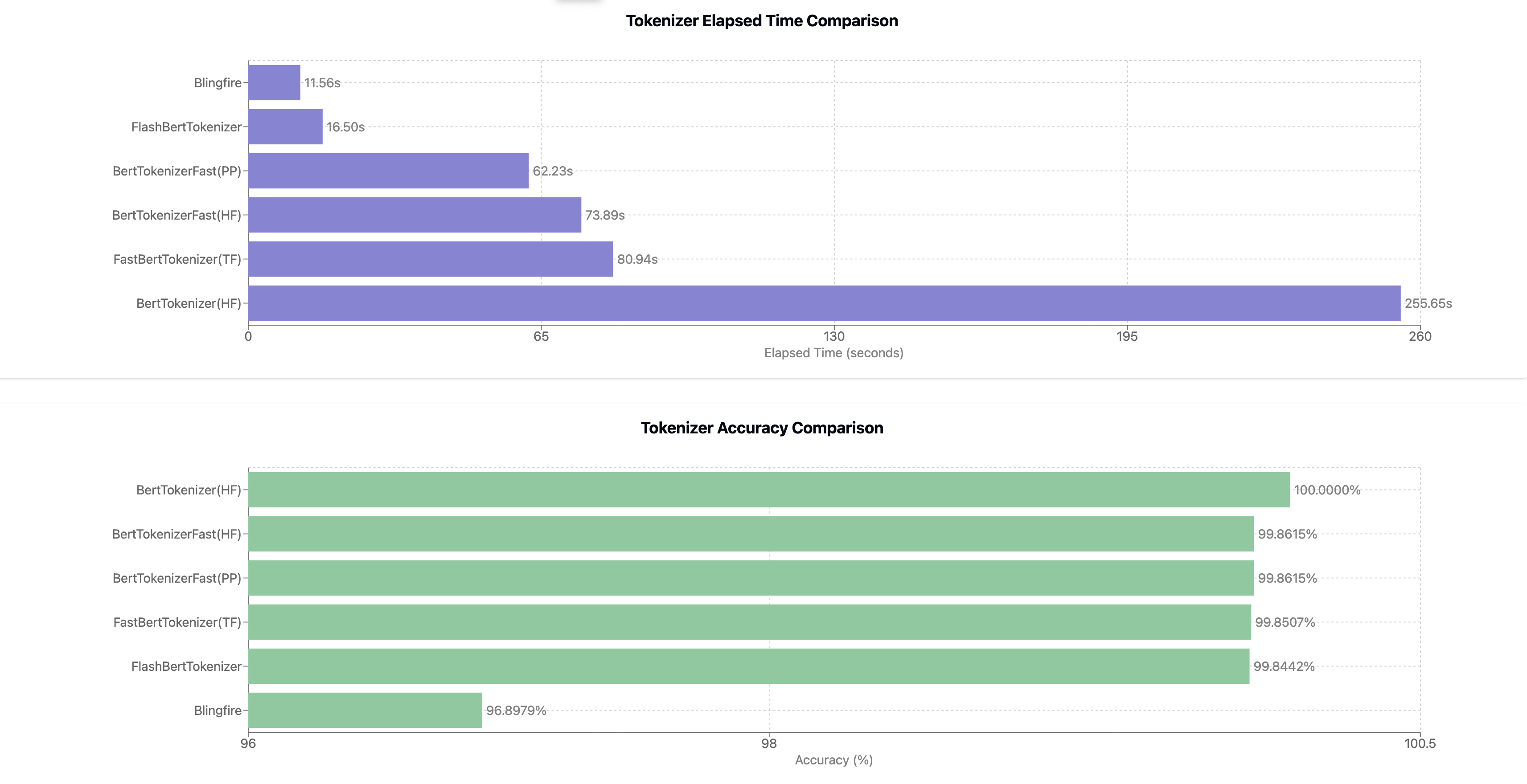
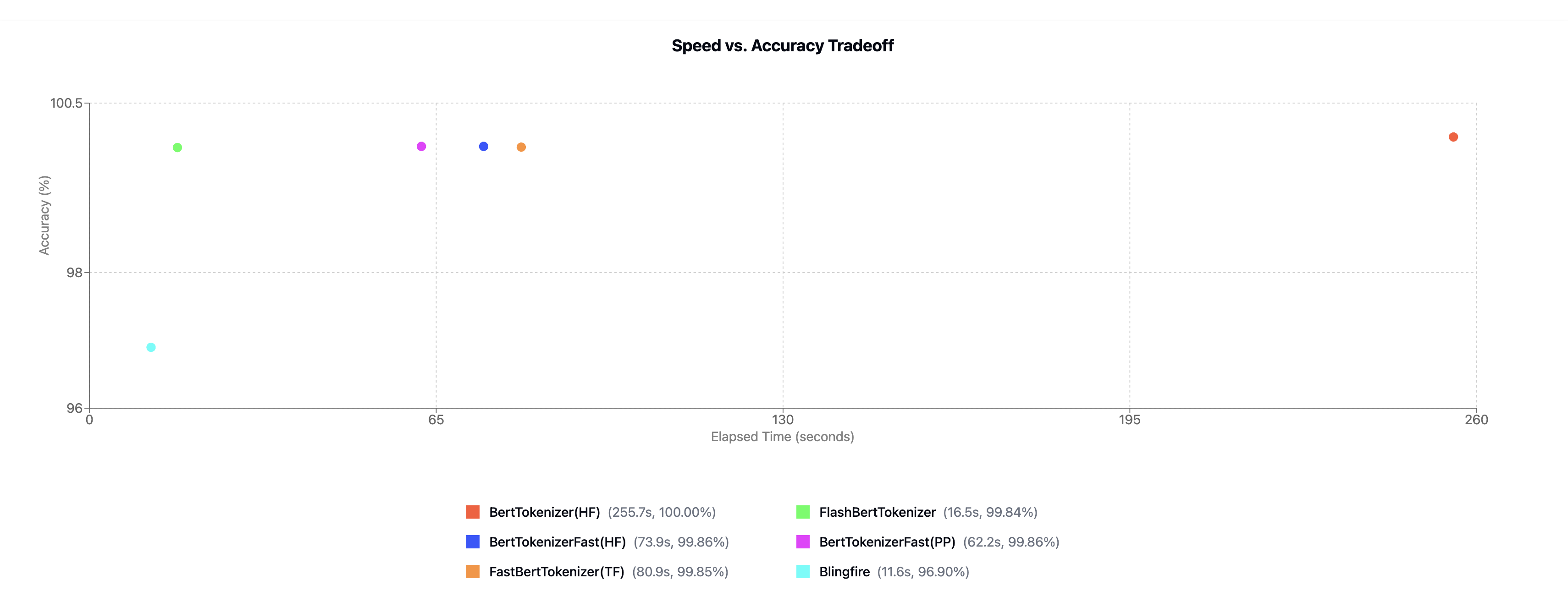
DeepCT (BertTokenizer)
| Tokenizer | Elapsed Time (s) | titles | Accuracy (%) |
|---|---|---|---|
| BertTokenizer(Huggingface) | 255.651 | 404,464 | 100 (Baseline) |
| ✨ BertTokenizerFlash | 404,464 | ||
| BertTokenizerFast(PP) | 64.6828 | 404,464 | 99.8615 |
| BertTokenizerFast(HF) | 69.6647 | 404,464 | 99.8615 |
| FastBertTokenizer(TF) | 85.5056 | 404,464 | 99.8507 |
| Blingfire | 12.1941 | 404,464 | 96.8979 |
DeepCT (BidirectionalBertTokenizer)
| Tokenizer | Elapsed Time (s) | titles | Accuracy (%) |
|---|---|---|---|
| BidirectionalBertTokenizer | 193.1238 | 404,464 | 100(baseline) |
| FlashBertTokenizerBidirectional | 17.8542 | 404,464 | 99.9913 |
KcBert_base
| Tokenizer | Elapsed Time | titles | Accuracy |
|---|---|---|---|
| ✨ BertTokenizerFlash | 7.9542 | 1,000,000 | 99.5792 |
| BertTokenizerFast(PP) | 38.3839 | 1,000,000 | 99.9995 |
| BertTokenizerFast(HF) | 49.0197 | 1,000,000 | 99.9995 |
| FastBertTokenizer(TF) | 188.633 | 1,000,000 | 99.9826 |
| Blingfire | 13.454 | 1,000,000 | 99.9244 |
For both single text and batch text, PaddleNLP's implementation is always faster than HuggingFace's implementation, and the results are exactly the same, so there is no unique advantage of HuggingFace's transformers.BertTokenizerFast.
Now you may have to make a decision between speed (blingfire) vs balance (PaddleNLP).
BertTokenizer requires a fast single-core CPU to get fast results.
The flash-tokenizer, which I implemented because I didn't like the other tokenizers, has a clear advantage in both speed and accuracy.
%%{ init: { "er" : { "layoutDirection" : "LR" } } }%%
erDiagram
Text ||--o{ Preprocess : tokenize
Preprocess o{--|| Inference : memcpy_h2d
Inference o{--|| Postprocess : memcpy_d2h
5. Case where the result is different from BertTokenizer
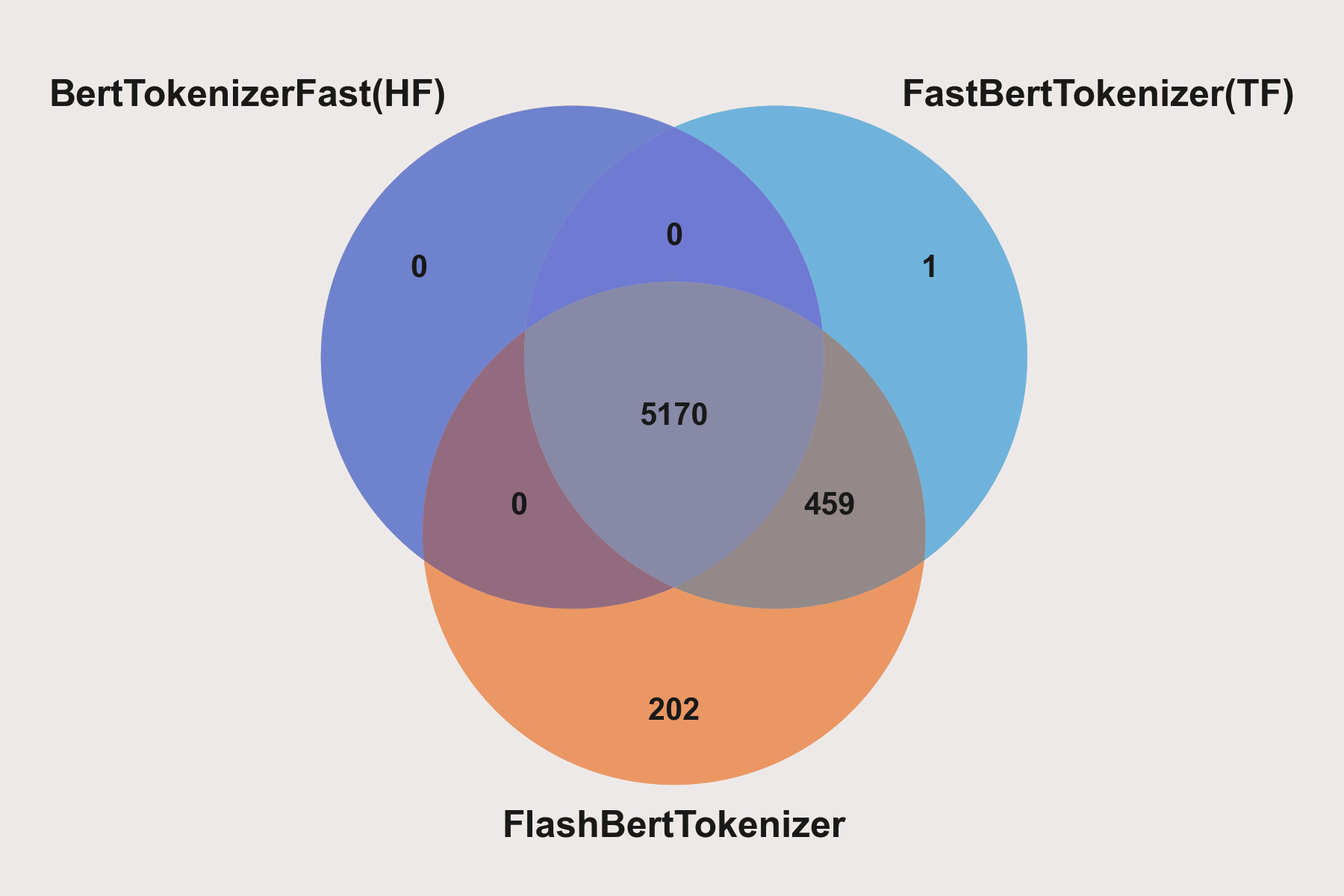
As can be seen from the above relationship, if transformers.BertTokenizerFast is wrong, then tensorflow-text's FastBertTokenizer and FlashBertTokenizer are also wrong, and the difference set between FlashBertTokenizer and FastBertTokenizer(TF) is different.
6. Compatibility
FlashBertTokenizer can be used with any framework. CUDA version compatibility for each framework is also important for fast inference of LLMs.
- PyTorch no longer supports installation using conda.
- ONNXRUNTIME is separated by CUDA version.
- PyTorch is also looking to ditch CUDA 12.x in favor of the newer CUDA 12.8. However, the trend is to keep CUDA 11.8 in all frameworks.
- CUDA 12.x was made for the newest GPUs, Hopper and Blackwell, and on GPUs like Volta, CUDA 11.8 is faster than CUDA 12.x.
| DL Framework | Version | OS | CPU | CUDA 11.8 | CUDA 12.3 | CUDA 12.4 | CUDA 12.6 | CUDA 12.8 |
|---|---|---|---|---|---|---|---|---|
| PyTorch | 2.6 | Linux, Windows | ⚪ | ⚪ | ❌ | ⚪ | ⚪ | ❌ |
| PyTorch | 2.7 | Linux, Windows | ⚪ | ⚪ | ❌ | ❌ | ⚪ | ⚪ |
| ONNXRUNTIME(11) | 1.20.x | Linux, Windows | ⚪ | ⚪ | ❌ | ❌ | ❌ | ❌ |
| ONNXRUNTIME(12) | 1.20.x | Linux, Windows | ⚪ | ❌ | ⚪ | ⚪ | ⚪ | ⚪ |
| PaddlePaddle | 3.0-beta | Linux, Windows | ⚪ | ⚪ | ❌ | ❌ | ❌ | ❌ |
7. GPU Tokenizer
You can run WordPiece Tokenizer on GPUs on rapids(cudf).
As you can see in how to install rapids, it only supports Linux and the CUDA version is not the same as other frameworks, so docker is the best choice, which is faster than CPU for batch processing but slower than CPU for streaming processing.
TODO
- BidirectionalWordPieceTokenizer
- BatchEncoder with Multithreading.
- CUDA Version.
- Replace
std::listtoboost::intrusive::list.
Implemention Problem
[!WARNING]
The following data structures are not applicable or are slower.
std::list<std::reference_wrapper<std::string>>std::string_viewstd::pmr::list<std::pmr::string>Using robbin_hood's fastest unordered_flat_map as a cache for BasicTokenizer and WordpieceTokenizer actually makes them slower, despite 95% cache hits, due to access time.
Acknowledgement
FlashTokenizer is inspired by FlashAttention, FlashInfer, FastBertTokenizer and tokenizers-cpp projects.
References
- https://medium.com/@techhara/which-bert-tokenizer-is-faster-b832aa978b46
- https://medium.com/@atharv6f_47401/wordpiece-tokenization-a-bpe-variant-73cc48865cbf
- https://www.restack.io/p/transformer-models-bert-answer-fast-berttokenizerfast-cat-ai
- https://medium.com/@anmolkohli/my-notes-on-bert-tokenizer-and-model-98dc22d0b64
- https://nocomplexity.com/documents/fossml/nlpframeworks.html
- https://github.com/martinus/robin-hood-hashing
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file flash_tokenizer-0.9.7.tar.gz.
File metadata
- Download URL: flash_tokenizer-0.9.7.tar.gz
- Upload date:
- Size: 5.4 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
86de47a5e0bf517f62d028367590a2148f8ba20ed12ad4be2bcb25d269c0555d
|
|
| MD5 |
45391492270352514fd39d46711a7c64
|
|
| BLAKE2b-256 |
1137d70a1139716e0d695c04c8efb164e4d2e4e7995c33fcd44b75720a8ecf41
|
File details
Details for the file flash_tokenizer-0.9.7-cp312-cp312-macosx_15_0_arm64.whl.
File metadata
- Download URL: flash_tokenizer-0.9.7-cp312-cp312-macosx_15_0_arm64.whl
- Upload date:
- Size: 149.7 kB
- Tags: CPython 3.12, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4301c242e5326b8884ea97a26ebca915c560c7a10084d4e0b37e67927cc9121d
|
|
| MD5 |
f346480049bf1824c7a2f4550360570b
|
|
| BLAKE2b-256 |
6c7db4913e9a068d97d96c717ee12d811776b639558fefbfebffbf4f09f3d024
|
File details
Details for the file flash_tokenizer-0.9.7-cp311-cp311-macosx_15_0_arm64.whl.
File metadata
- Download URL: flash_tokenizer-0.9.7-cp311-cp311-macosx_15_0_arm64.whl
- Upload date:
- Size: 150.4 kB
- Tags: CPython 3.11, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
deb760cd54183d00e149a467d9516ca76da46b5a52a1d72796436d812af23876
|
|
| MD5 |
1d7db0746f66cccf59ef8385dfea0d82
|
|
| BLAKE2b-256 |
3a86e1a3ba0e9cebabe596c5cfb05cef14444589a14ccb88cfeb6d8ddc5fe1bd
|
File details
Details for the file flash_tokenizer-0.9.7-cp310-cp310-macosx_15_0_arm64.whl.
File metadata
- Download URL: flash_tokenizer-0.9.7-cp310-cp310-macosx_15_0_arm64.whl
- Upload date:
- Size: 148.7 kB
- Tags: CPython 3.10, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
38b56d11244fe4f1356e3593767652a7c45bb64b0e465583efcbceb158799208
|
|
| MD5 |
9438ab59becd7aa7414496507e26a208
|
|
| BLAKE2b-256 |
62aeaa6e7b336fc736a610a149033b0d3ae4f1cea6b689a9c7031a1f15fd4653
|
File details
Details for the file flash_tokenizer-0.9.7-cp39-cp39-macosx_15_0_arm64.whl.
File metadata
- Download URL: flash_tokenizer-0.9.7-cp39-cp39-macosx_15_0_arm64.whl
- Upload date:
- Size: 149.0 kB
- Tags: CPython 3.9, macOS 15.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
673a624c64f044564f3d0b44603fb2785fc2ece00234eebd86312f6a522756d4
|
|
| MD5 |
bb0674ee36f1c0506f187339db19c691
|
|
| BLAKE2b-256 |
28249f0176e5df847cbcdf6b59d950d245d5ca572695dfcd213d0acbaa791007
|







