Anticipatory context allocation for long-horizon black-box LLM agents

Project description

Anticipatory context allocation for long-horizon LLM agents.
Spend a fixed token budget where the future of the trajectory will look, not just where the
current query points — black-box (prompt/proxy layer, no model internals, no fine-tuning),
reversible (nothing is destroyed; anything can be re-inflated), and theory-backed.






Core is dependency-free and offline-capable. Real-model results on Gemma, Qwen, and Llama are
in bench/report.md; the theory is summarized in
docs/theory.md. Positioning against prior art is stated honestly in
Honest positioning below.
One command, any tool: foveance wrap
pip install "foveance[proxy]"
foveance wrap claude # or: foveance wrap -- codex "fix the tests"
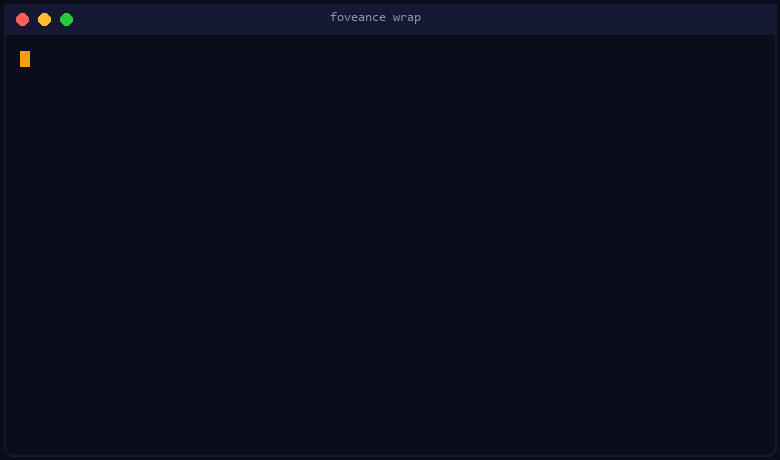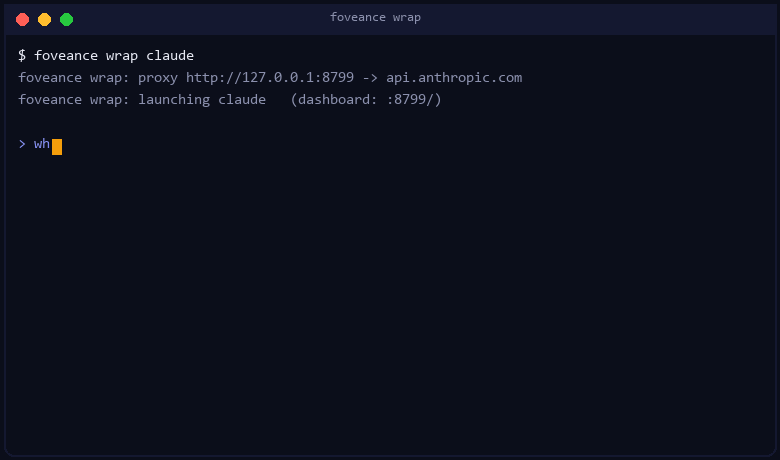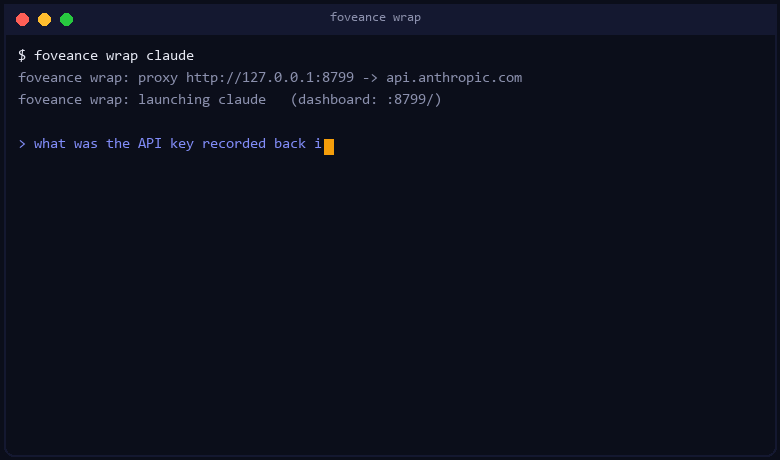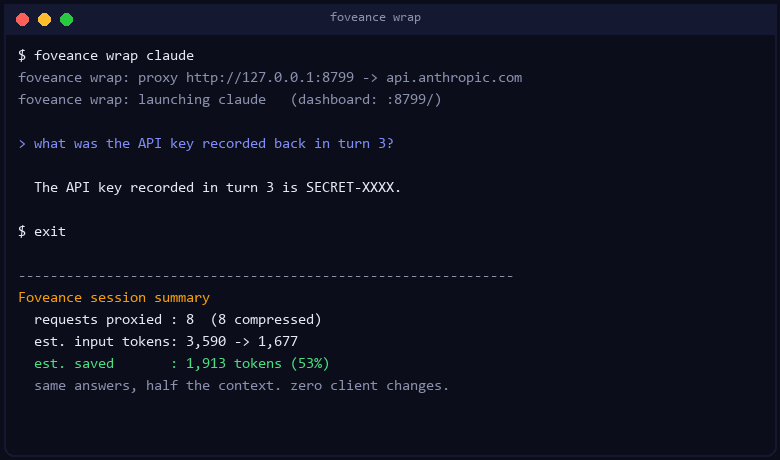
That's it. wrap starts the proxy, routes the tool through it (env is set for the child process
only), runs it exactly as before — your API key / OAuth untouched — and prints a tokens-saved
summary when you exit. A live dashboard with a running "tokens saved ≈ $" figure serves at
http://localhost:8799/ while it runs.
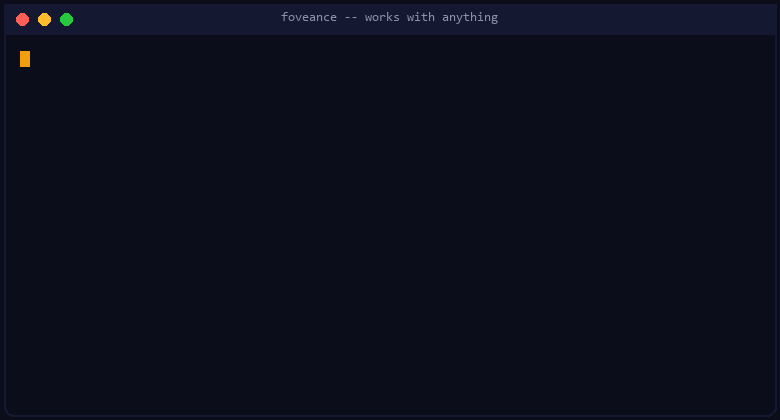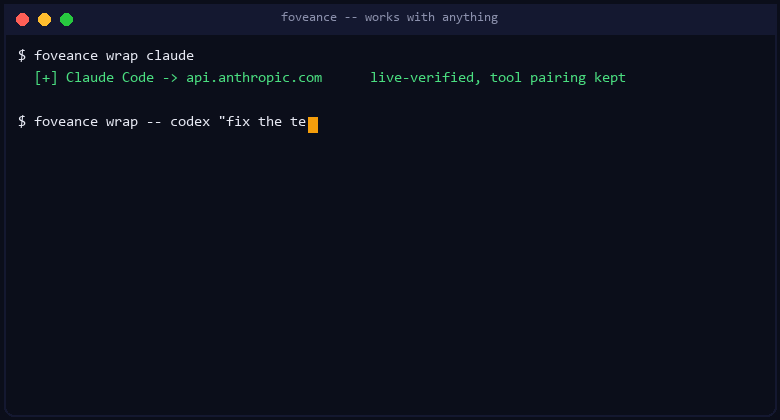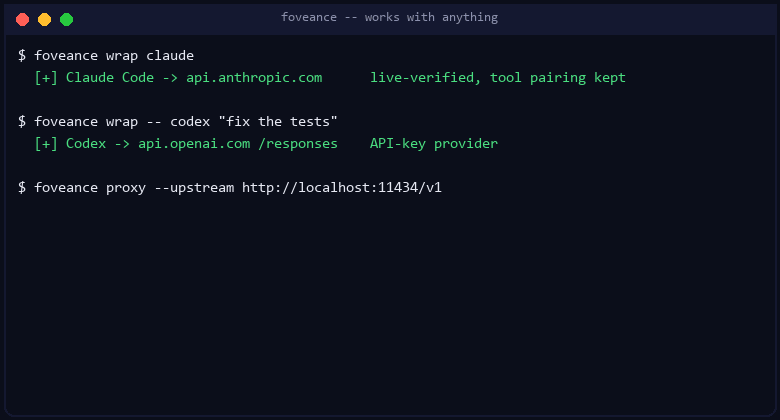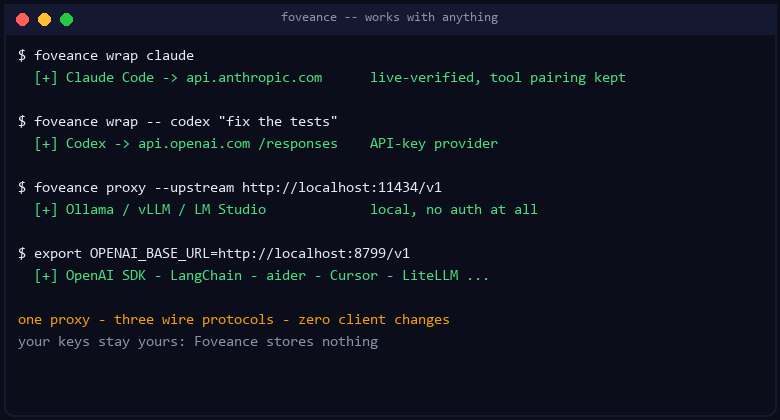
Or run the proxy standalone
foveance proxy --upstream https://api.openai.com/v1 # now listening on http://localhost:8799
# point any OpenAI- or Anthropic-compatible client at it (one variable) and keep your API key:
export OPENAI_BASE_URL=http://localhost:8799/v1 # OpenAI SDK, Codex, Ollama-backed apps, ...
export ANTHROPIC_BASE_URL=http://localhost:8799 # Anthropic SDK, Claude Code
Other install flavors
pip install "foveance" # core only: dependency-free, offline (library + `foveance demo`)
pip install "foveance[all]" # proxy + ML embedder + benchmark, everything in one shot
pip install -e ".[dev]" # from a clone: core + test tooling
pip install -e ".[dev,bench]" # + numpy/matplotlib/tiktoken for the benchmark
60-second quickstart
make test # pytest, ≥90% coverage on core modules
foveance demo # offline Pareto table (MockLLM, no GPU/network)
make bench # offline benchmark + analysis + plots
foveance demo prints accuracy/tokens per arm across budgets: budgeted policies (reactive_afm,
foveance, oracle) match full-replay accuracy at a fraction of its tokens and dominate naive
recency. As the theory predicts, reactive_afm ≈ foveance on the easy per-turn-recompute regime;
the anticipation gap appears under harder conditions (unnamed targets, fidelity-change cost,
no-retrieve) — see the drift sweep in bench/report.md.
Results (real models)
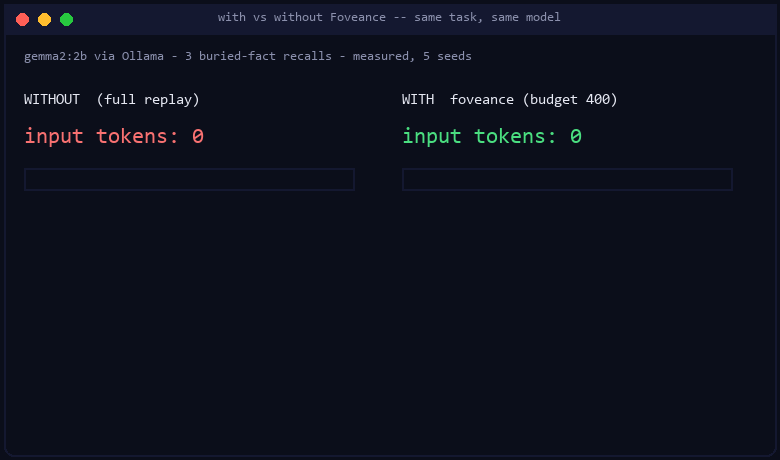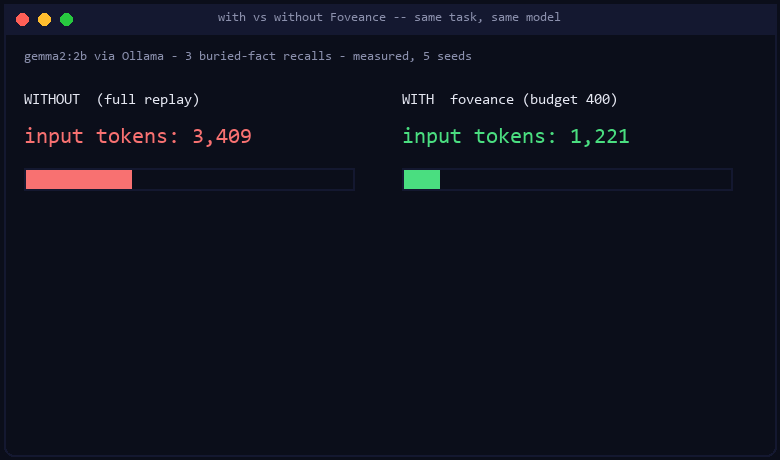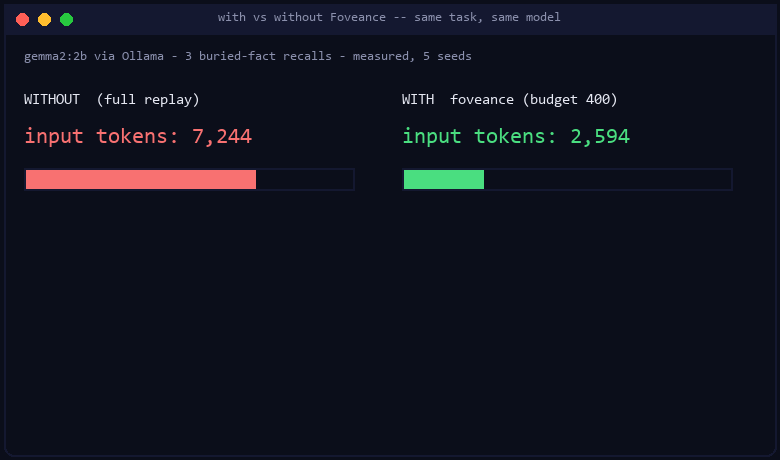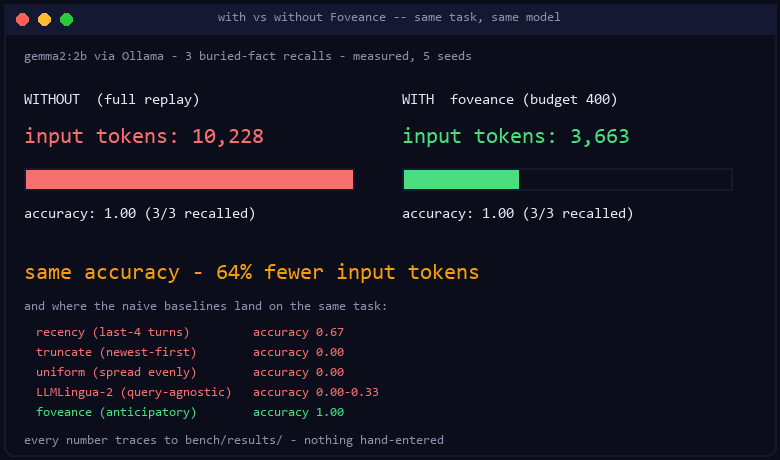
Run on Gemma 2 (2B), Llama 3.2 (1B), and Qwen 2.5 (1.5B) via Ollama, 5 seeds each. At a
binding token budget, budgeted policies reach full-replay accuracy at 62–64% fewer tokens,
while naive recency truncation collapses to 0.67. Every number traces to bench/results/ (no
hand-entry); see bench/report.md.
Full 6-arm comparison at the tight budget (400), accuracy across all three models — the naive baselines fail while foveance matches full replay at ~⅓ the tokens:
| Model | full | recency | truncate | uniform | reactive (AFM) | foveance |
|---|---|---|---|---|---|---|
| gemma2:2b | 1.00 (10.2k) | 0.67 | 0.00 | 0.00 | 1.00 | 1.00 (3.7k) |
| llama3.2:1b | 1.00 (8.3k) | 0.67 | 0.00 | 1.00 | 1.00 | 1.00 (3.1k) |
| qwen2.5:1.5b | 1.00 (9.9k) | 0.67 | 0.00 | 0.00 | 1.00 | 1.00 (3.6k) |
recency plateaus at 0.67 everywhere; truncate collapses on all models; uniform fails on 2 of 3
(on gemma it spends more tokens than foveance yet still fails, because it spreads fidelity instead
of concentrating it on the load-bearing item). Foveance reaches full accuracy at 62–64% fewer
tokens than full replay. Every number traces to bench/results/ (no hand-entry).
The deployable index allocator stays within ~1.8% of the exact DP optimum and below the LP
bound (index ≤ OPT ≤ LP), and the drift-twin audit confirms reactive_afm and foveance differ
only in predictor drift. As the locality-gap theorem predicts, reactive_afm ≈ foveance on the
named-target, low-drift headline; the drift sweep (--ablations) shows where anticipation pulls
ahead. Reproduce with bash scripts/run_everything.sh (or run_offline_demo.sh with no GPU).
Library usage
from foveance import Controller, Item
from foveance.llm import MockLLM # or OllamaLLM("gemma2:9b"), OpenAICompatLLM(...)
ctrl = Controller(MockLLM(), budget=2000, policy="foveance", drift=0.7)
ctrl.add_item(Item("obs0", "tool_output", "FACT api_key=sk-123\n...lots of logs...", created_turn=0))
rec = ctrl.step("recall api_key", turn=0)
print(rec.answer, rec.input_tokens, rec.peak_tokens)
Swap policy="reactive_afm" (the AFM baseline), "recency", "full", or "oracle" to compare.
Cut your token usage everywhere (drop-in proxy, zero client changes)
Foveance runs as a transparent reverse proxy that speaks the OpenAI Chat Completions, OpenAI Responses, and Anthropic Messages wire protocols, streams, and forwards your credentials untouched. It keeps a per-conversation multi-fidelity store and spends a token budget on the context most likely to matter next, before forwarding upstream.
Works with anything that lets you point its base URL at the proxy — which is essentially every client and agent: the OpenAI and Anthropic SDKs, Claude Code, Codex (with an API key), aider, Continue, Cursor, LangChain, LiteLLM, and local runtimes like Ollama / vLLM / LM Studio. Foveance is auth-free: it adds no login of its own and stores no key — you keep your existing credentials, and local models need none at all. The only thing it cannot intercept is a client that cryptographically hard-pins its endpoint (e.g. ChatGPT-subscription Codex, which refuses any redirect); that is the tool's design, and no proxy can route around it. Give such a tool an API key instead and it works like everything else.
Real-world results (measured, not hypothetical)
| Setting | Tokens | Accuracy / validity |
|---|---|---|
foveance wrap (live) — llama3.2:1b via Ollama, buried-fact recall at budget 500 |
2,127 → 186 est. input tokens (−91%) | Fact recalled correctly through the compressed context; full wrap→proxy→model→summary path |
| Local model — llama3.2:1b via Ollama, long chat with a buried fact | 3,590 → 1,677 input tokens (−53%) | Foveance answered correctly; full-replay hallucinated the value (context dilution) |
| Claude Code (live, Anthropic OAuth) — agentic, in-place compression | ~71% fewer input tokens on an 8-tool-call transcript* | Works end-to-end, correct answer, no errors; tool_use/tool_result pairing preserved |
| Benchmark — Gemma 2 2B / Llama 3.2 1B / Qwen 2.5 1.5B, 5 seeds | 62–64% fewer at iso-accuracy | matches full-replay accuracy; recency truncation dominated |
*Agentic token reduction is measured on a controlled transcript where token accounting is exact; the live Claude Code run confirms validity and correctness. Numbers reproduce via scripts/ and the proxy; see bench/report.md and docs/usage.md.
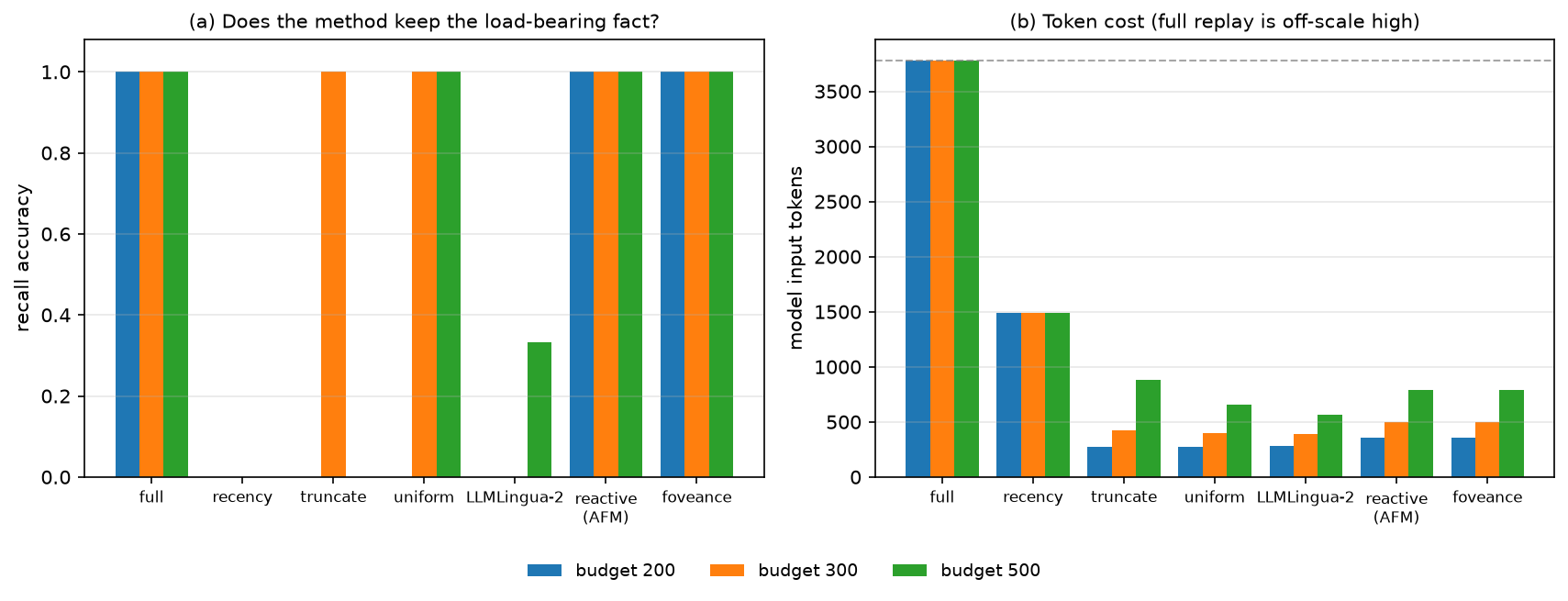
Head-to-head vs other methods (real model + real LLMLingua-2, single-shot recall)
A long trajectory hides one load-bearing fact early amid filler; each method compresses to a token
budget, then the real model (llama3.2:1b) is asked to recall it. Only the query-aware budgeted
allocators (reactive_afm, foveance) recall the fact at every budget, at 5–10× fewer tokens
than full replay. Every relevance-blind method drops it under pressure: recency fails at every
budget, and real LLMLingua-2 (query-agnostic token deletion) recalls at most 1/3 even at the
loosest budget while spending the same tokens as foveance. Reproduce:
python bench/compare_baselines.py --with-llmlingua && python bench/plot_baselines.py.
| recall accuracy @ budget | full | recency | truncate | uniform | LLMLingua-2 | reactive (AFM) | foveance |
|---|---|---|---|---|---|---|---|
| 200 (tight) | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 |
| 300 | 1.00 | 0.00 | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 |
| 500 | 1.00 | 0.00 | 0.00 | 1.00 | 0.33 | 1.00 | 1.00 |
| input tokens (≈) | 3782 | 1493 | 270–880 | 270–650 | 280–570 | 350–790 | 350–790 |
The same ordering holds in the full multi-turn agent loop (recall queries throughout), which
rules out any "one-shot artifact" objection: recency plateaus at 0.67, truncate collapses to
0.0–0.40 and at the loosest budget spends more tokens than full replay, while foveance matches
full accuracy at ~⅓ the tokens.
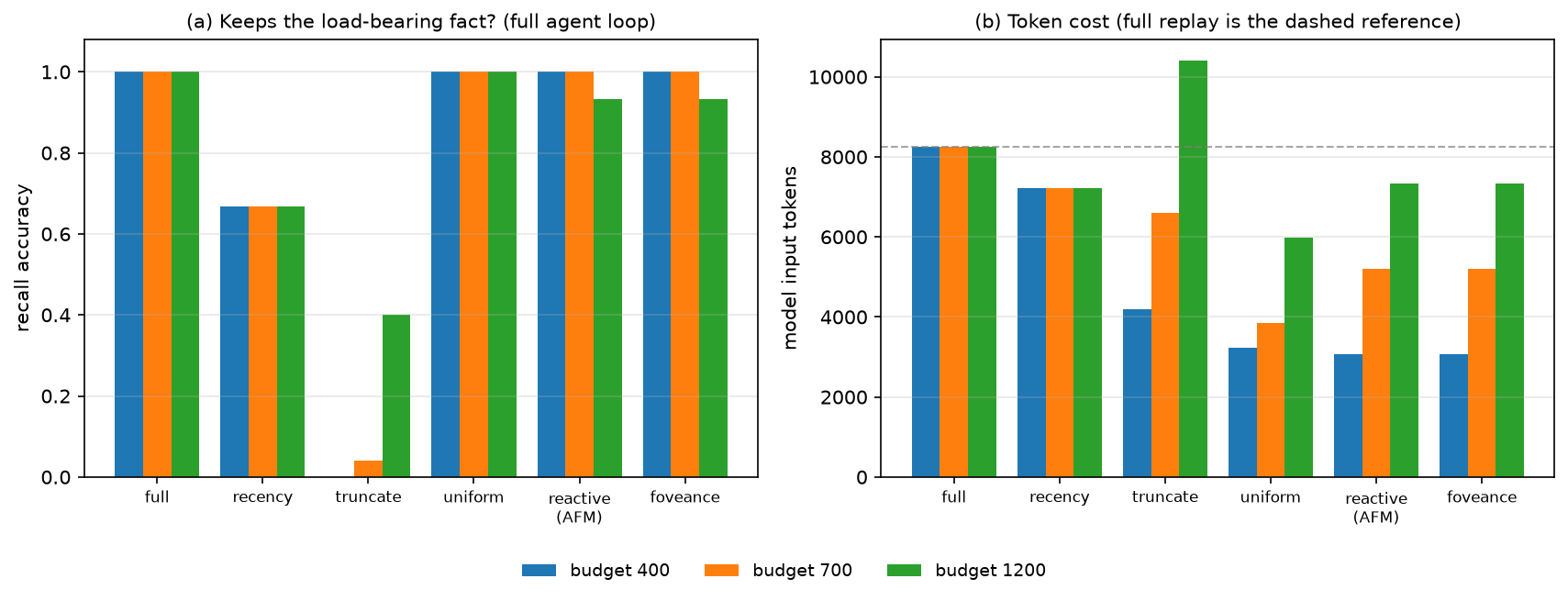
Honest reading: only allocation by relevance to the query holds accuracy where the
relevance-blind methods (recency, truncation, uniform, and LLMLingua-2's query-agnostic deletion)
collapse, and it never underperforms full replay while using a fraction of its tokens. LLMLingua-2 is
a real run via the llmlingua package (CPU). The single-shot study includes LLMLingua-2 across all
budgets; the full-trajectory figure is llama3.2:1b (5 seeds) — extending the trajectory sweep with
these arms to the other models is a GPU/overnight job on CPU (qwen ≈ 57 s per large call).
pip install -e ".[proxy]"
# Point it at whatever you already use as the upstream:
foveance proxy --upstream https://api.openai.com/v1 # OpenAI
foveance proxy --upstream https://api.anthropic.com/v1 # Anthropic / Claude
foveance proxy --upstream http://localhost:11434/v1 # Ollama (local), vLLM, TGI, LM Studio
# Config via flags or env: FOVEANCE_UPSTREAM, FOVEANCE_BUDGET, FOVEANCE_DRIFT, FOVEANCE_POLICY
It listens on http://localhost:8799 and speaks three wire protocols: POST /v1/chat/completions
(OpenAI Chat), POST /v1/messages (Anthropic Messages), and POST /v1/responses (OpenAI Responses,
used by Codex and the Agents SDK), plus GET /v1/models, GET /health, GET /admin/stats (JSON),
and a live dashboard at GET / showing tokens saved and the ≈$ equivalent
(--price-per-mtok sets the assumed input price). "stream": true is passed through verbatim.
Plain chat is compressed by the anticipatory allocator; tool-using (agentic) requests are
compressed structurally in place, preserving every message and tool-call pairing.
Prompt-cache aware: blocks carrying an Anthropic cache_control breakpoint are never modified,
and with --cache-aware the proxy never touches anything at or before the last breakpoint — so
it never invalidates the provider's prompt cache. See
docs/limitations.md for the exact cost arithmetic of when to enable it.
Point your tool at it (one variable)
| Client / agent | How to route it through Foveance |
|---|---|
| OpenAI SDK (Python/JS) | base_url="http://localhost:8799/v1" (or OPENAI_BASE_URL) |
| Anthropic SDK / Claude Code | ANTHROPIC_BASE_URL=http://localhost:8799 |
| Ollama | run foveance proxy --upstream http://localhost:11434/v1; point your app at :8799/v1 |
| OpenAI Codex CLI | define an API-key custom provider in ~/.codex/config.toml with base_url="http://localhost:8799/v1", wire_api="responses" (the proxy speaks Responses). Note: ChatGPT-subscription Codex cannot be proxied — its built-in openai provider is locked and the OAuth is pinned to the ChatGPT backend; use an API key. |
| Google Antigravity / Cursor / Continue | set the custom OpenAI base URL to http://localhost:8799/v1 |
| opencode / Crush / aider | set the OpenAI-compatible base URL / --openai-api-base to http://localhost:8799/v1 |
| LangChain / LlamaIndex / LiteLLM | pass base_url=/api_base="http://localhost:8799/v1" |
| curl / anything else | POST http://localhost:8799/v1/chat/completions |
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8799/v1", api_key="sk-...") # nothing else changes
# Claude Code: route the whole agent through Foveance
ANTHROPIC_BASE_URL=http://localhost:8799 claude
# Node / npm tools: launch the proxy without a manual Python step
npx foveance-proxy --upstream https://api.openai.com/v1 # see npm/ (wraps the Python proxy)
Every client header (Authorization/x-api-key of any kind, anthropic-beta feature flags, and
tool-specific headers) is forwarded upstream unchanged and never stored, so OAuth-authenticated
agents connect through it without extra config. Plain multi-turn chat is compressed by the
anticipatory allocator (where it saves the most). Agentic requests that declare a tools array
(Claude Code, Codex, and similar) are compressed structurally: every message, role, and
tool_use/tool_result pair is kept intact and recent turns are protected, while large stale tool
outputs in older turns are digested in place — so the request stays valid for the provider and
the agent keeps working. Verified live with Claude Code (71% fewer input tokens on an 8-tool-call
transcript offline; correct end-to-end answers live). See docs/usage.md and
docs/limitations.md.
The core (foveance.proxy.FoveanceProxy) is pure and unit-tested against a real HTTP upstream,
covering OpenAI, Anthropic, streaming, and /v1/models. Full guide with copy-paste recipes per
tool: docs/usage.md.
Honest positioning
As of mid-2026 this space is crowded. Per-message multi-fidelity tiering under a token budget
already exists — see AFM (Cruz 2025), ContextBudget, ACON, MemAct. That mechanism is
substrate, not our contribution. We ship a faithful AFM-style reactive policy as a first-class
baseline — it is literally the drift = 0 special case of our predictor. Foveance's defensible
novelty is narrow and specific:
- an anticipatory allocation criterion (expected future relevance via a posterior over
upcoming needs) — the reactive AFM-style criterion is the
drift = 0special case; - a fundamental-limits theory for the black-box, multi-turn, task-success setting (a predictive trajectory rate–distortion function);
- a near-optimal index policy with a measured greedy gap, plus a theorem for when anticipation beats the reactive heuristics everyone ships;
- successive-refinability conditions making reversible re-inflation "free";
- an open benchmark placing all methods on one Pareto frontier vs the theoretical bound.
The full claim boundaries and prior-art table are in docs/NOVELTY.md.
What's in the package
src/foveance/ store.py · predictor.py (anticipatory future-relevance) · allocator.py
(index + exact DP + LP bound) · controller.py (policy seam + retrieve tool) ·
compressors.py (heuristic + LLM renderers) · embedders.py (hashing/ST/API) ·
baselines.py (full/recency/reactive_afm/oracle/llmlingua2) · metrics.py ·
learned.py (logistic future-relevance) · proxy.py · cli.py · llm.py
tests/ store/predictor/allocator/controller (100% covered) + integration + modules
bench/ tasks.py (Suite interface + synthetic + LongBench/RULER/AppWorld/OfficeBench
adapters) · run_bench.py · analyze.py · plots.py · report.md · results/ (real CSVs)
docs/ architecture.md · theory.md · baselines.md · limitations.md · NOVELTY.md
Run the real comparison (Gemma + others, on your hardware)
One command — installs Ollama, pulls the models, runs the budget sweep + greedy-gap + ablations, does the full analysis (bootstrap CIs, paired Wilcoxon, iso-accuracy token savings, Pareto AUC), and makes the plots:
bash scripts/run_everything.sh
MODELS="gemma2:9b,qwen2.5:7b,llama3.1:8b" BUDGETS="600,1200,2400,4800" TASKS=8 \
bash scripts/run_everything.sh
Outputs: bench/report.md, bench/results/{headline.json,summary.csv,...}, and
bench/plots/*.png.
No GPU? Prove the whole chain offline
bash scripts/run_offline_demo.sh # mock model -> benchmark -> analysis -> plots
Identical pipeline with a deterministic mock model, clearly marked illustrative until you run
real models. No number in the repo is hand-entered — every figure traces to a CSV in
bench/results/.
Reproduce a single result
python bench/run_bench.py --backend mock --models mock --suite synthetic \
--budgets 600,1200,1600,2500,4000 --tasks 6 --turns 40 --drift 0.7 \
--name-target false --fidelity-cost true --greedy-gap --ablations
python bench/analyze.py && python bench/plots.py
Integrity
Do not fabricate benchmark numbers — fill tables from your actual runs. See
docs/NOVELTY.md for the claim boundaries, and
docs/limitations.md for the honest failure modes.
License
Apache-2.0. See LICENSE.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file foveance-0.1.0.tar.gz.
File metadata
- Download URL: foveance-0.1.0.tar.gz
- Upload date:
- Size: 1.3 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2467c4005bdbeb2e842ebdacd8633eafff0f0cbe64f1fac80151a10738e06013
|
|
| MD5 |
f2323ed56bf58a4bc8f33831ee2b2472
|
|
| BLAKE2b-256 |
24ee7e5329a23b0eb65c458059c34990193470c42dbeabbfc6ceb9cdc33b923c
|
File details
Details for the file foveance-0.1.0-py3-none-any.whl.
File metadata
- Download URL: foveance-0.1.0-py3-none-any.whl
- Upload date:
- Size: 48.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9125e772c236cdcf4e1d904b5766139201e3b59047a4621b174789e66b315910
|
|
| MD5 |
bf91fe2964c871c88d46c367048a9134
|
|
| BLAKE2b-256 |
5ccd2ca9f9d1a57449bcdee7ab2f1a7865a7c36922b76c06e7d4a4d7783dd49b
|







