Anticipatory context allocation for long-horizon black-box LLM agents

Project description

Cut your LLM token bill by 60%+ — without changing your code or your answers.




What is this? (plain English)
When you chat with an AI agent for a while, the conversation history keeps piling up. You pay for every old message on every new turn, and past a point the model actually gets worse because the important facts are buried under clutter.
Foveance fixes that automatically. It keeps the parts of the history that still matter, trims the parts that don't, and hands the model a shorter context — so you get the same answers for a fraction of the tokens. Nothing is deleted forever, and you don't change a single line of your app.
In real tests it kept full accuracy while using 60–64% fewer tokens, and it correctly recalled a buried fact that the full, uncompressed history got wrong.
Get started in 30 seconds
Option A — you use a coding agent (Claude Code, Codex, aider, …)
One command. It runs your tool exactly as before, just cheaper, and prints how much you saved:
pip install "foveance[proxy]"
foveance wrap claude # or: foveance wrap -- codex "fix the tests"
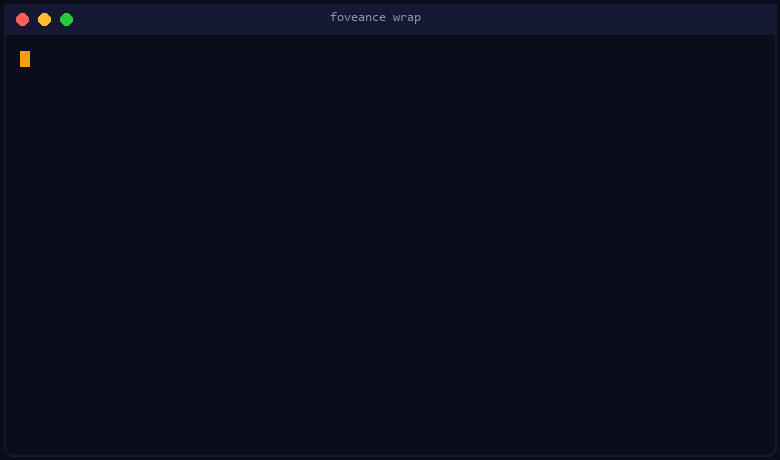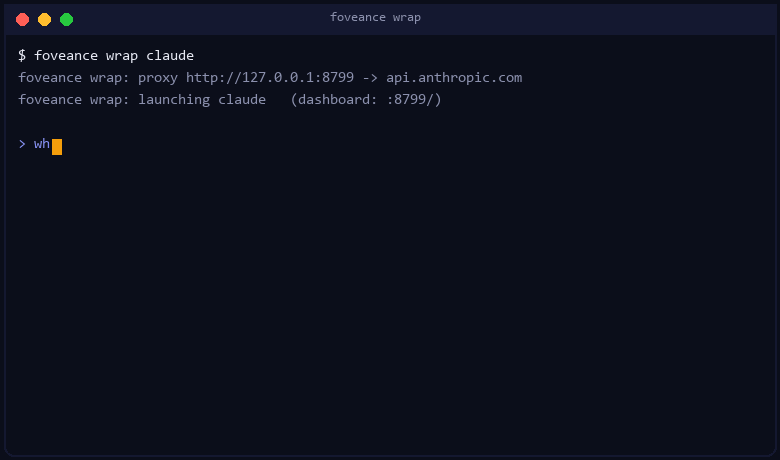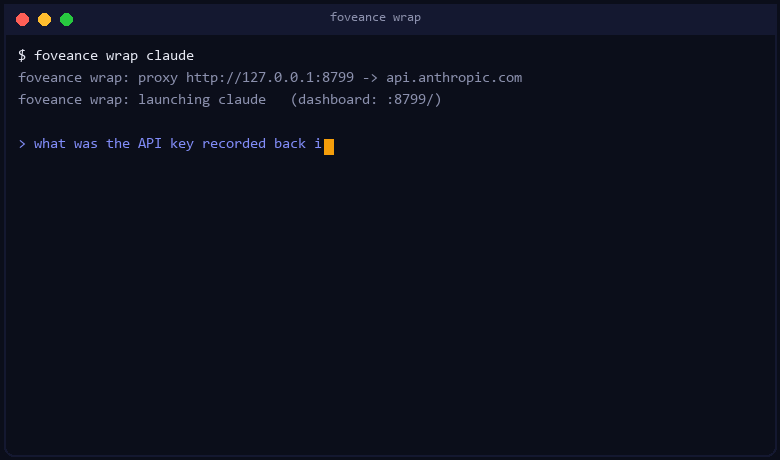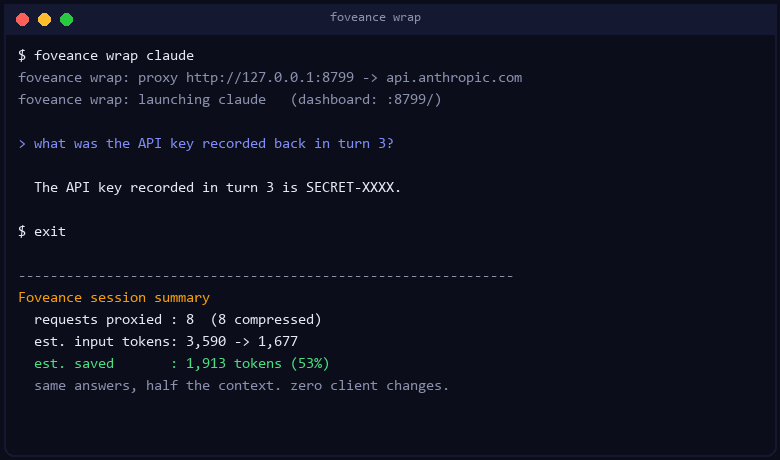
That's the whole thing. Your API key is untouched, nothing is stored, and a live "tokens saved ≈ $" dashboard runs at http://localhost:8799/ while you work.
Option B — you write Python
One install, one function. No server, no config, nothing to run:
pip install foveance
from foveance import shrink
smaller = shrink(messages, budget=2000) # messages = your OpenAI-style list
# ...now send `smaller` to your model instead of `messages`. Same answers, fewer tokens.
shrink keeps your system prompt and your latest message exactly as-is and intelligently
compresses the older turns. That's all you need to start.
Option C — try it right now, no API key, no GPU
pip install foveance
foveance demo
Prints a side-by-side table showing the token savings on a built-in example.
Does it actually work? (real numbers, nothing invented)
Measured on Gemma 2 (2B), Llama 3.2 (1B), and Qwen 2.5 (1.5B) via Ollama, 5 seeds each. At a tight token budget, Foveance matched the full, uncompressed accuracy using ~⅓ of the tokens, while the naive shortcuts (keep-recent, truncate, spread-evenly) failed:
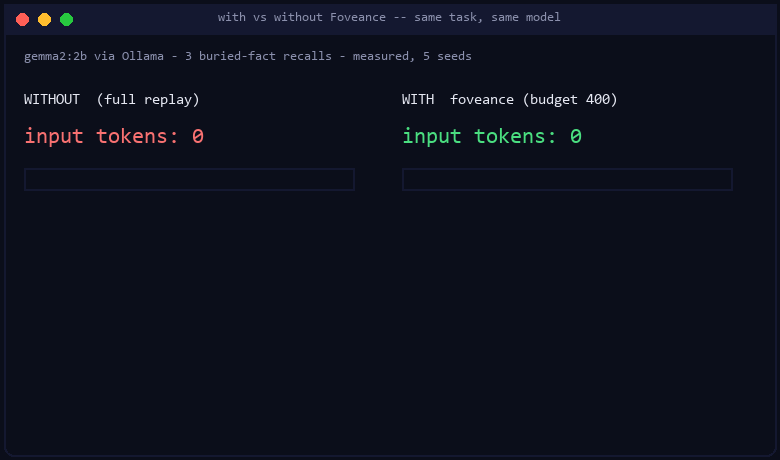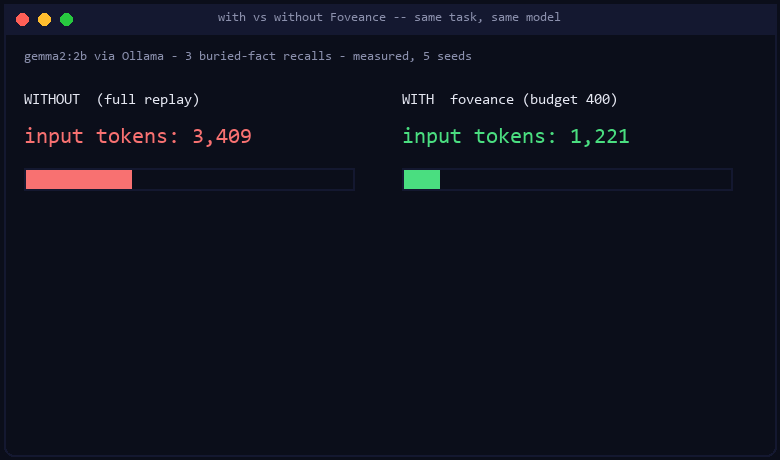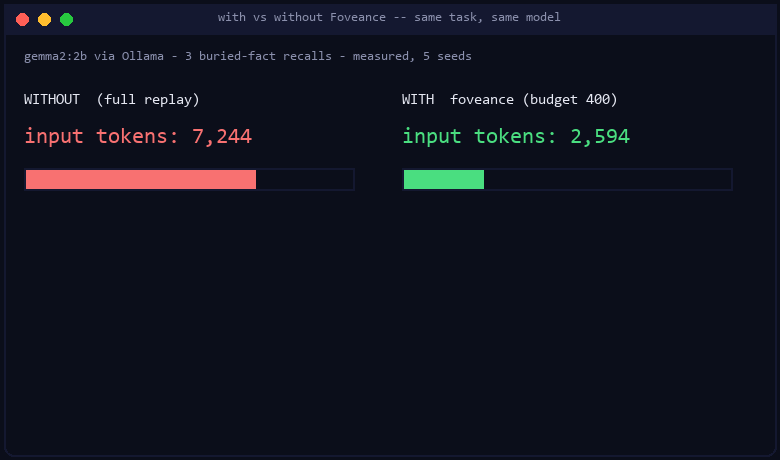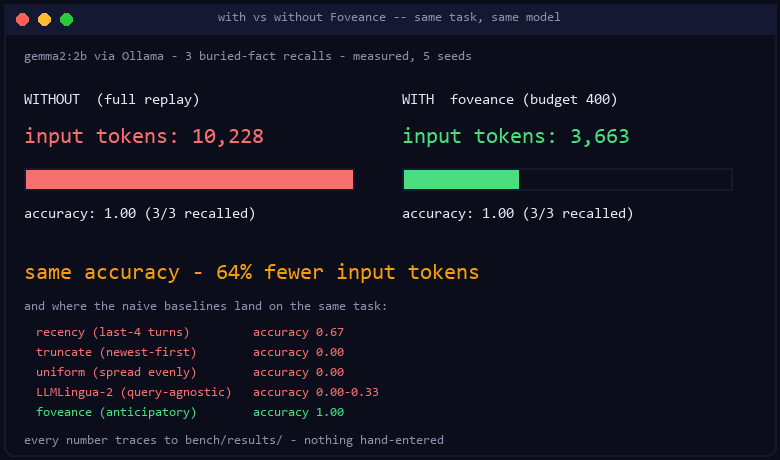
| Model | full (no compression) | keep-recent | truncate | spread-evenly | Foveance |
|---|---|---|---|---|---|
| gemma2:2b | 1.00 (10.2k tok) | 0.67 | 0.00 | 0.00 | 1.00 (3.7k tok) |
| llama3.2:1b | 1.00 (8.3k tok) | 0.67 | 0.00 | 1.00 | 1.00 (3.1k tok) |
| qwen2.5:1.5b | 1.00 (9.9k tok) | 0.67 | 0.00 | 0.00 | 1.00 (3.6k tok) |
Accuracy is "did it recall the buried fact." Foveance holds 1.00 at ~⅓ the tokens on every
model; the shortcuts drop the fact. Every number traces to a CSV in
bench/results/ — nothing is hand-entered.
Full benchmark, head-to-head vs LLMLingua-2, and the theory are further down and in
bench/report.md / docs/.
Install options (click to expand)
pip install foveance # core: the shrink() function + demo, dependency-free, offline
pip install "foveance[proxy]" # + the drop-in proxy and `foveance wrap`
pip install "foveance[all]" # everything: proxy + ML embedder + benchmark tools
Under the hood (the technical part)
Everything above is all most people need. The rest of this document is for people who want the proxy details, the full benchmark, and the theory.
The drop-in proxy — cut tokens for any tool, zero code changes
foveance wrap <tool> is a convenience wrapper around a small reverse proxy you can also run
yourself. It speaks the OpenAI Chat Completions, OpenAI Responses, and Anthropic Messages wire
protocols, streams, and forwards your credentials untouched. It keeps a per-conversation
multi-fidelity store and spends a token budget on the context most likely to matter next, before
forwarding upstream.
foveance proxy --upstream https://api.openai.com/v1 # OpenAI
foveance proxy --upstream https://api.anthropic.com/v1 # Anthropic / Claude
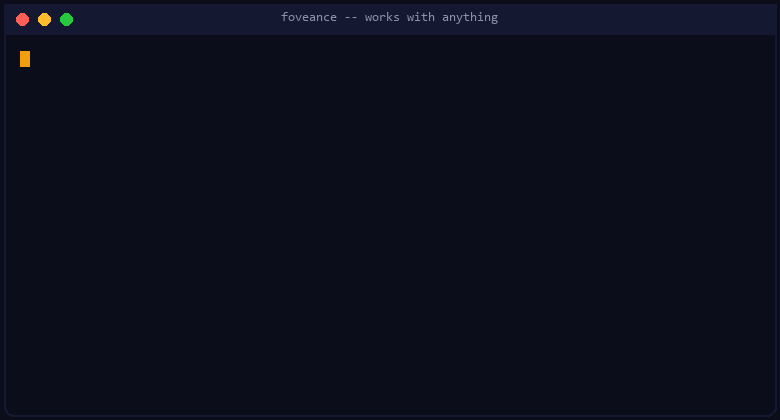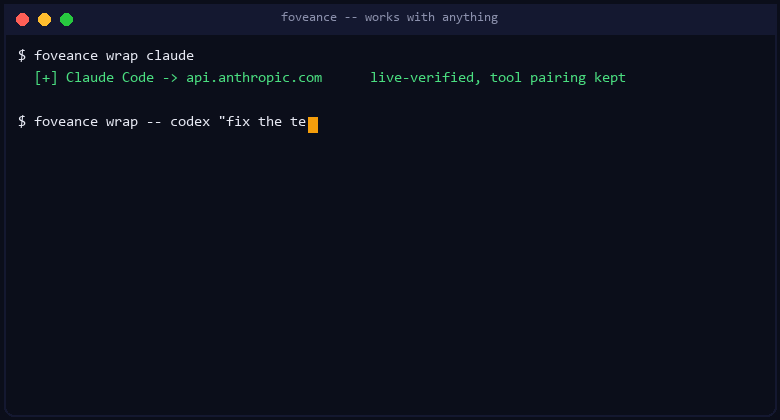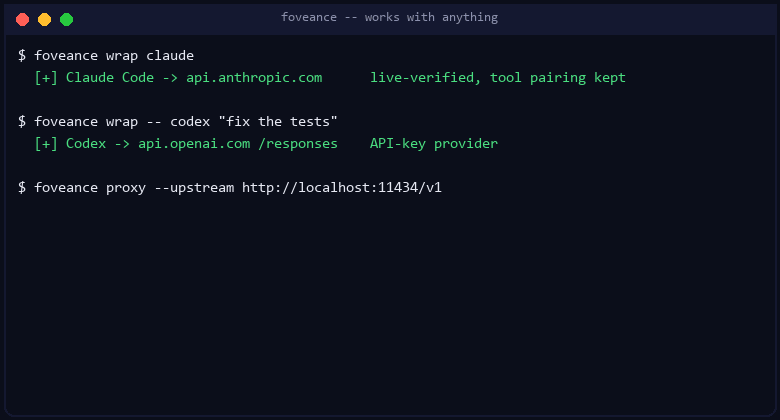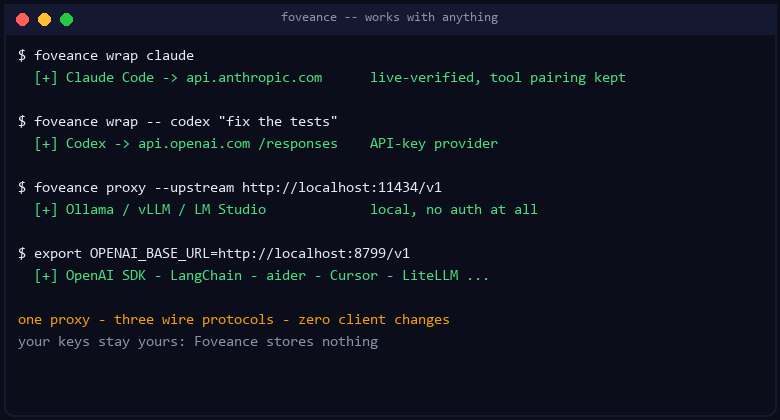
foveance proxy --upstream http://localhost:11434/v1 # Ollama (local), vLLM, TGI, LM Studio
# then point any client at it with one variable (your API key still goes straight upstream):
export OPENAI_BASE_URL=http://localhost:8799/v1 # OpenAI SDK, Codex, Ollama-backed apps
export ANTHROPIC_BASE_URL=http://localhost:8799 # Anthropic SDK, Claude Code
Works with anything that lets you set its base URL — the OpenAI and Anthropic SDKs, Claude Code, Codex (with an API key), aider, Continue, Cursor, LangChain, LiteLLM, and local runtimes like Ollama / vLLM / LM Studio. Foveance is auth-free: it adds no login of its own and stores no key. The only thing it can't intercept is a client that cryptographically hard-pins its endpoint (e.g. ChatGPT-subscription Codex); give such a tool an API key and it works like everything else.
It listens on http://localhost:8799 and exposes POST /v1/chat/completions,
POST /v1/messages, POST /v1/responses, GET /v1/models, GET /health, GET /admin/stats
(JSON), and a live dashboard at GET / (tokens saved and ≈$ at --price-per-mtok).
"stream": true is passed through verbatim. Plain chat is compressed by the anticipatory
allocator; tool-using (agentic) requests are compressed structurally in place, preserving
every message and tool-call pairing.
Prompt-cache aware: blocks carrying an Anthropic cache_control breakpoint are never
modified, and with --cache-aware the proxy never touches anything at or before the last
breakpoint — so it never invalidates the provider's prompt cache. See
docs/limitations.md for the cost arithmetic.
| Client / agent | How to route it through Foveance |
|---|---|
| OpenAI SDK (Python/JS) | base_url="http://localhost:8799/v1" (or OPENAI_BASE_URL) |
| Anthropic SDK / Claude Code | ANTHROPIC_BASE_URL=http://localhost:8799 |
| Ollama | foveance proxy --upstream http://localhost:11434/v1; point your app at :8799/v1 |
| OpenAI Codex CLI | API-key custom provider in ~/.codex/config.toml: base_url="http://localhost:8799/v1", wire_api="responses" (subscription Codex can't be proxied — use an API key) |
| Cursor / Continue / Antigravity | set the custom OpenAI base URL to http://localhost:8799/v1 |
| aider / opencode / Crush | set the OpenAI-compatible base URL to http://localhost:8799/v1 |
| LangChain / LlamaIndex / LiteLLM | pass base_url=/api_base="http://localhost:8799/v1" |
| Node / npm tools | npx foveance-proxy --upstream https://api.openai.com/v1 |
Measured real-world results
| Setting | Tokens | Outcome |
|---|---|---|
foveance wrap (live) — llama3.2:1b via Ollama, buried-fact recall |
2,127 → 186 est. tokens (−91%) | fact recalled correctly through the compressed context |
| Local model — llama3.2:1b, long chat with a buried fact | 3,590 → 1,677 tokens (−53%) | Foveance correct; full replay hallucinated the value |
| Claude Code (live, Anthropic OAuth) — agentic in-place compression | ~71% fewer tokens on an 8-tool-call transcript | works end-to-end, tool pairing preserved |
| Benchmark — Gemma/Llama/Qwen, 5 seeds | 62–64% fewer at iso-accuracy | matches full-replay accuracy |
Head-to-head vs other methods (real model + real LLMLingua-2)
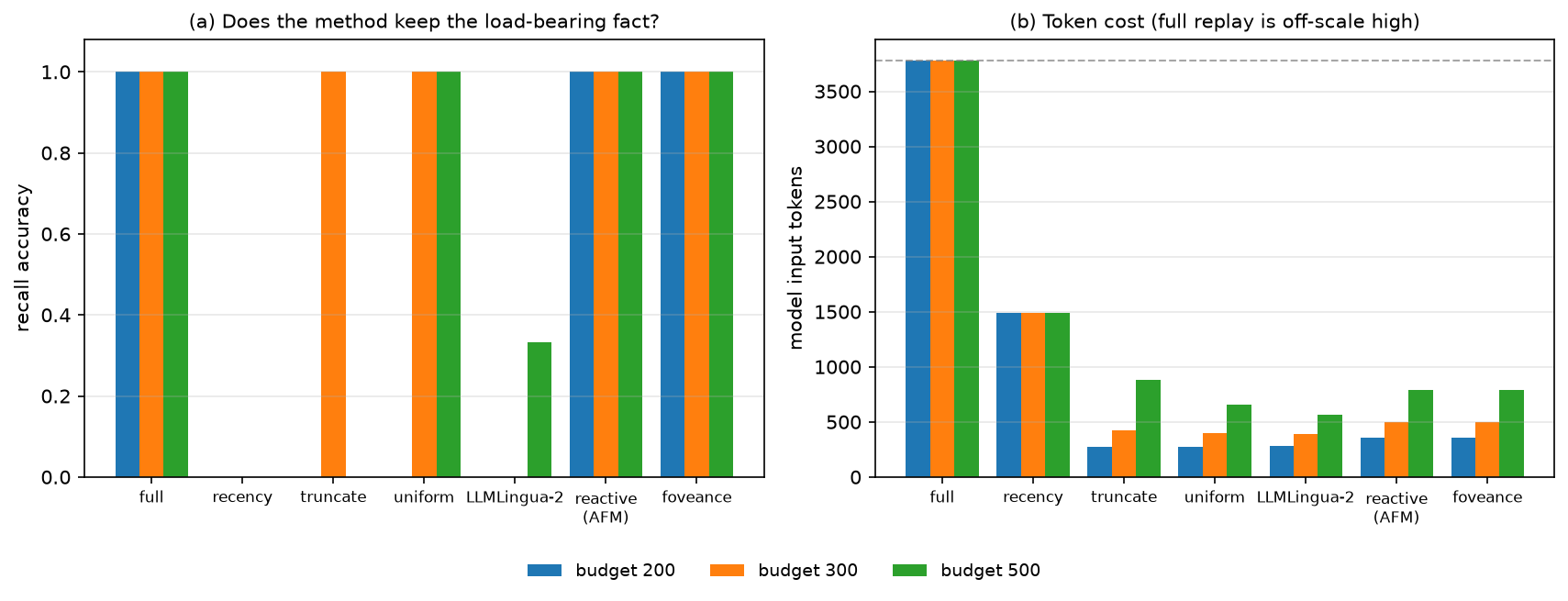
A long trajectory hides one load-bearing fact early amid filler; each method compresses to a budget, then the real model (llama3.2:1b) is asked to recall it. Only the query-aware allocators recall it at every budget, at 5–10× fewer tokens than full replay:
| recall @ budget | full | keep-recent | truncate | spread-evenly | LLMLingua-2 | reactive (AFM) | Foveance |
|---|---|---|---|---|---|---|---|
| 200 (tight) | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 1.00 |
| 300 | 1.00 | 0.00 | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 |
| 500 | 1.00 | 0.00 | 0.00 | 1.00 | 0.33 | 1.00 | 1.00 |
The same ordering holds in the full multi-turn agent loop, ruling out a one-shot artifact:
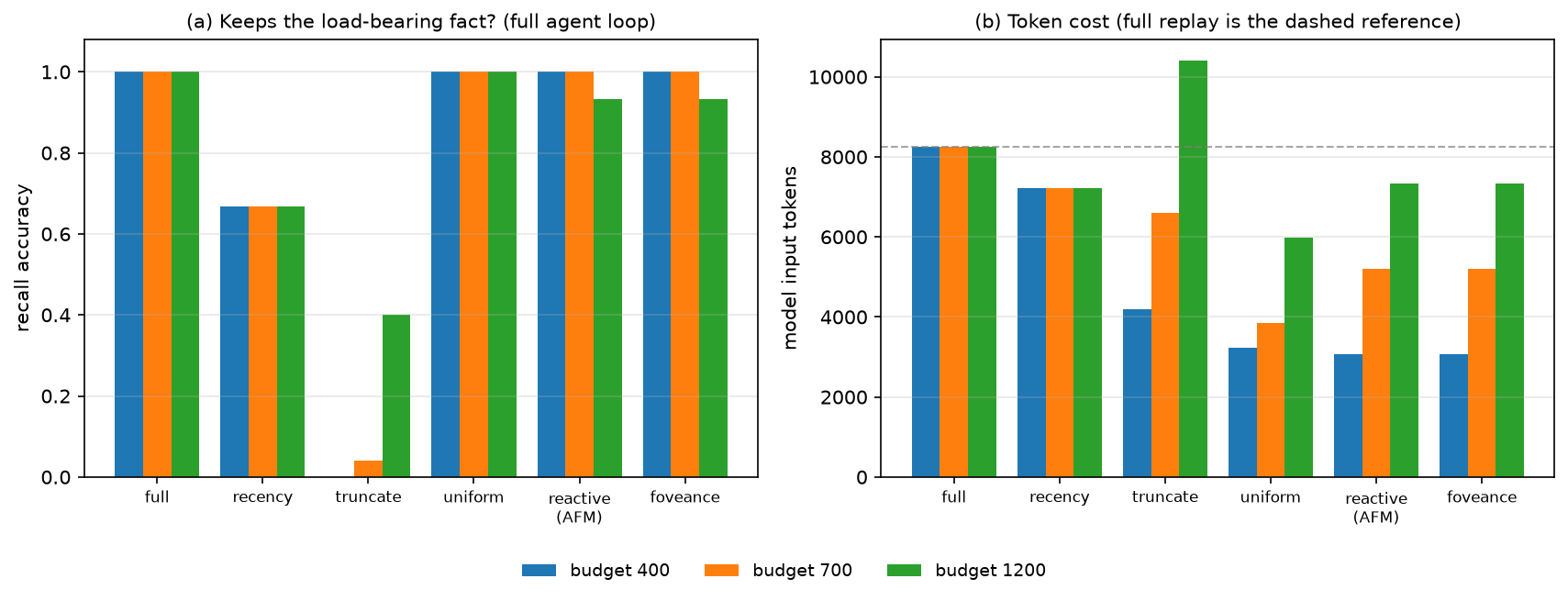
Reproduce: python bench/compare_baselines.py --with-llmlingua && python bench/plot_baselines.py.
LLMLingua-2 is a real run via the llmlingua package (CPU).
Library usage (beyond shrink)
from foveance import Controller, Item
from foveance.llm import MockLLM # or OllamaLLM("gemma2:9b"), OpenAICompatLLM(...)
ctrl = Controller(MockLLM(), budget=2000, policy="foveance", drift=0.7)
ctrl.add_item(Item("obs0", "tool_output", "FACT api_key=sk-123\n...lots of logs...", created_turn=0))
rec = ctrl.step("recall api_key", turn=0)
print(rec.answer, rec.input_tokens, rec.peak_tokens)
Swap policy="reactive_afm" (the AFM baseline), "recency", "full", or "oracle" to compare.
Honest positioning
As of mid-2026 this space is crowded. Per-message multi-fidelity tiering under a token budget
already exists — see AFM (Cruz 2025), ContextBudget, ACON, MemAct. That mechanism is
substrate, not the contribution here. Foveance ships a faithful AFM-style reactive policy as a
first-class baseline — it is literally the drift = 0 special case of the predictor. The
defensible novelty is narrow and specific:
- an anticipatory allocation criterion (expected future relevance) — the reactive
AFM-style criterion is the
drift = 0special case; - a fundamental-limits theory for the black-box, multi-turn, task-success setting;
- a near-optimal index policy with a measured greedy gap, plus a theorem for when anticipation beats the reactive heuristics everyone ships;
- successive-refinability conditions making reversible re-inflation "free";
- an open benchmark placing all methods on one accuracy–token frontier vs the bound.
The deployable index allocator stays within ~1.8% of the exact DP optimum and below the LP
bound (index ≤ OPT ≤ LP). Full claim boundaries and the prior-art table are in
docs/NOVELTY.md.
What's in the package
src/foveance/ store.py · predictor.py (anticipatory future-relevance) · allocator.py
(index + exact DP + LP bound) · controller.py · compressors.py · embedders.py ·
baselines.py · metrics.py · learned.py · proxy.py · cli.py · llm.py
tests/ store/predictor/allocator/controller (100% covered) + integration
bench/ run_bench.py · analyze.py · plots.py · report.md · results/ (real CSVs)
docs/ architecture.md · theory.md · baselines.md · limitations.md · NOVELTY.md
Reproduce the benchmark
bash scripts/run_everything.sh # real models via Ollama (installs + pulls + runs + plots)
bash scripts/run_offline_demo.sh # no GPU: identical chain with a deterministic mock model
Outputs land in bench/report.md, bench/results/, and bench/plots/. No number is
hand-entered; every figure traces to a CSV.
License
Apache-2.0. See LICENSE.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file foveance-0.1.1.tar.gz.
File metadata
- Download URL: foveance-0.1.1.tar.gz
- Upload date:
- Size: 1.3 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5a9d948f3fa29b3371ee127fdca1aa805a0cac5be83895a5f3c49f30868ddbac
|
|
| MD5 |
c1b322a9def5ca2fb45c5e17952ebf80
|
|
| BLAKE2b-256 |
065f66edfc9a79faa1b1096912934cee8000f74bb9226fe6b0423d657508dc2c
|
File details
Details for the file foveance-0.1.1-py3-none-any.whl.
File metadata
- Download URL: foveance-0.1.1-py3-none-any.whl
- Upload date:
- Size: 46.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f0302055244970f71a8c288084561aff3617145f40e4e3b89824925b2e51bb9e
|
|
| MD5 |
002989d01c4f09ee9a84815e517d590c
|
|
| BLAKE2b-256 |
313c0e6d4fee53dfc40554ae161860f91d193b3c31e9d2a5bcc08b7ddeb124e7
|







