Gradient-Efficient Knowledge Optimization - Smart training for any LLM

Project description
GEKO: Gradient-Efficient Knowledge Optimization







A plug-and-play training framework that makes LLM training more efficient.
Like LoRA revolutionized fine-tuning, GEKO revolutionizes training.
Key Insight
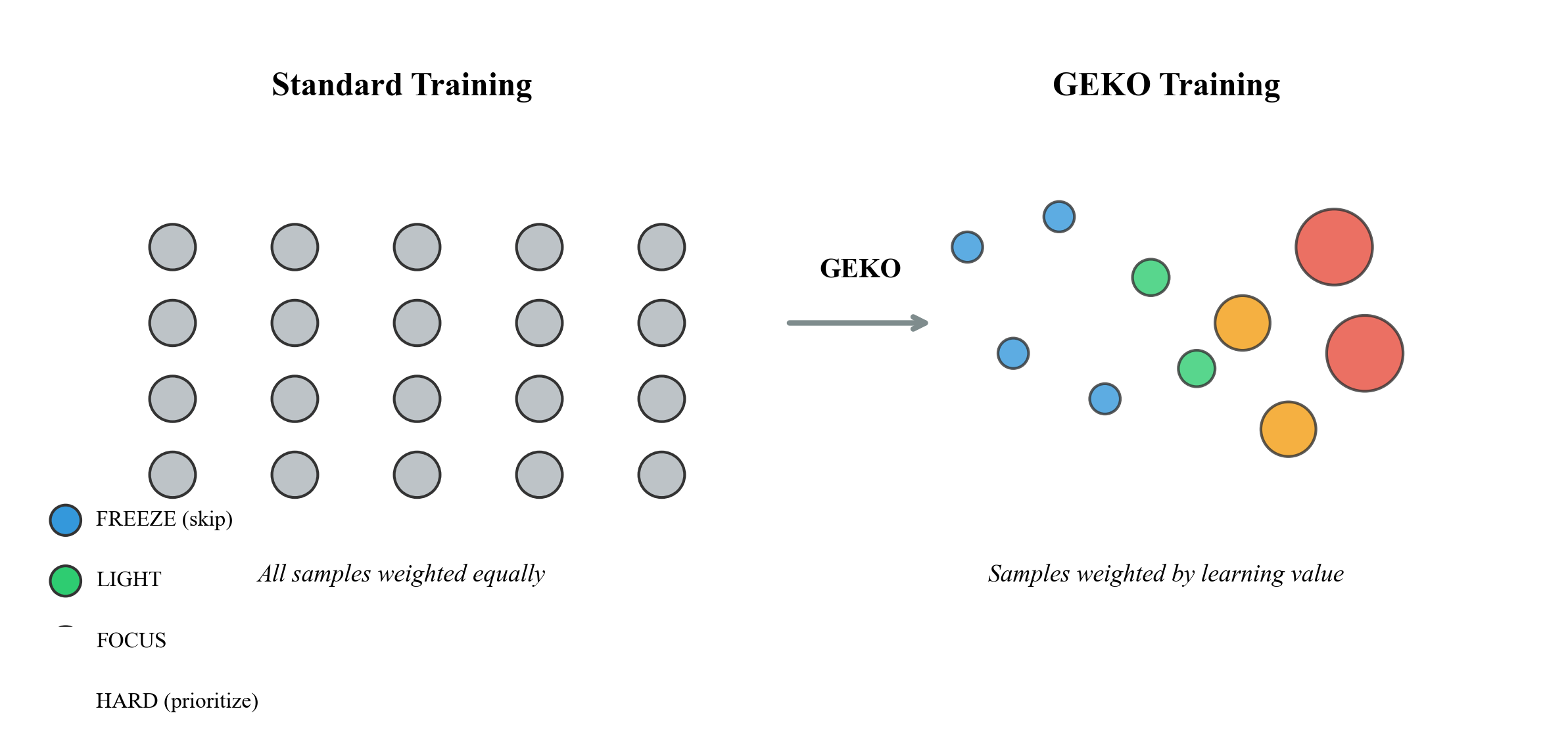
Traditional training treats all samples equally:
$$\mathcal{L}{standard} = \frac{1}{N} \sum{i=1}^{N} \ell(x_i, y_i)$$
GEKO weights samples by their learning value:
$$\mathcal{L}{GEKO} = \frac{1}{N} \sum{i=1}^{N} w_i \cdot \ell(x_i, y_i) \quad \text{where} \quad w_i = f(bucket_i)$$
Installation
pip install gekolib
Quick Start
from geko import GEKOTrainer, GEKOConfig, GEKOTrainingArgs
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
args = GEKOTrainingArgs(
output_dir="./geko_output",
num_epochs=3,
batch_size=16,
learning_rate=5e-5,
warmup_steps=100,
gradient_accumulation_steps=4,
save_steps=500,
eval_steps=500,
)
trainer = GEKOTrainer(
model=model,
train_dataset=your_dataset, # must return dicts with 'input_ids'
eval_dataset=your_eval_dataset, # optional
tokenizer=tokenizer, # optional — stored for your convenience
args=args,
)
trainer.train()
print(trainer.get_efficiency_report())
Requirements: Your dataset's __getitem__ must return a dict with at least an 'input_ids' key (e.g. {'input_ids': x, 'labels': y}). For true per-sample bucketing, override compute_correctness; see API Reference.
API Reference
GEKOTrainer
GEKOTrainer(
model, # Any nn.Module (HuggingFace, custom, etc.)
train_dataset, # Dataset — __getitem__ must return a dict
tokenizer=None, # Optional — stored but not called internally
eval_dataset=None, # Optional evaluation dataset
config=None, # GEKOConfig (defaults to GEKOConfig())
args=None, # GEKOTrainingArgs (defaults to GEKOTrainingArgs())
compute_confidence=None, # fn(outputs, batch) → Tensor[B]; default: max softmax
compute_correctness=None,# fn(outputs, batch) → BoolTensor[B]; default: per-sample when model returns 1D loss, else batch-level (override for per-sample bucketing)
)
Key methods:
| Method | Description |
|---|---|
trainer.train() |
Run the full GEKO training loop |
trainer.get_efficiency_report() |
Print bucket statistics and compute savings |
trainer.save_checkpoint(path) |
Save full GEKO state (model weights + sample states) |
trainer.load_checkpoint(path) |
Restore from a saved checkpoint |
Resume training from checkpoint:
trainer = GEKOTrainer(model=model, train_dataset=dataset)
trainer.load_checkpoint("./geko_output/checkpoint-500")
trainer.train()
GEKOTrainingArgs
| Argument | Default | Description |
|---|---|---|
output_dir |
"./geko_output" |
Directory for checkpoints and logs |
num_epochs |
3 |
Number of training epochs |
batch_size |
32 |
Per-device batch size |
learning_rate |
5e-5 |
AdamW learning rate |
weight_decay |
0.01 |
AdamW weight decay |
warmup_steps |
100 |
Linear warmup steps for LR scheduler |
logging_steps |
100 |
Log metrics every N optimizer steps |
save_steps |
1000 |
Save checkpoint every N optimizer steps |
eval_steps |
500 |
Run evaluation every N optimizer steps |
max_grad_norm |
1.0 |
Gradient clipping norm |
fp16 |
auto |
Mixed precision (auto-detects CUDA) |
gradient_accumulation_steps |
1 |
Accumulate gradients before stepping |
dataloader_num_workers |
0 |
DataLoader workers (0 = main process) |
seed |
42 |
Random seed for reproducibility |
save_at_end |
True |
Save a final checkpoint after training |
Note on steps:
logging_steps,save_steps, andeval_stepsall count optimizer steps (i.e., after gradient accumulation), consistent with HuggingFace conventions.
GEKOConfig
| Field | Default | Description |
|---|---|---|
freeze_confidence |
0.85 |
Confidence threshold to enter FREEZE |
freeze_quality |
0.80 |
Quality threshold to enter FREEZE |
focus_confidence |
0.60 |
Confidence split between FOCUS and HARD |
bucket_weights |
(3, 1, 0) |
Sampling weights: (HARD, FOCUS, LIGHT) |
use_curriculum |
True |
Enable Mountain Curriculum |
q_value_lr |
0.1 |
EMA learning rate for Q-value updates |
min_q_for_freeze |
0.8 |
Minimum Q-value required to FREEZE a sample |
q_value_loss_scale |
10.0 |
Loss normalizer for Q updates (set to your model's typical max loss) |
repartition_every |
1 |
Re-partition samples every N epochs |
log_bucket_stats |
True |
Log bucket distribution each epoch |
max_times_seen |
50 |
Max training passes per sample (prevents overfitting) |
Preset configurations:
from geko.core import GEKO_AGGRESSIVE, GEKO_BALANCED, GEKO_CONSERVATIVE
# GEKO_AGGRESSIVE: freeze_confidence=0.90, weights=(5, 2, 0) — max focus on hard samples
# GEKO_BALANCED: freeze_confidence=0.85, weights=(3, 2, 1) — includes easy samples
# GEKO_CONSERVATIVE: freeze_confidence=0.80, weights=(2, 2, 1) — gentle selection
GEKODataset
Wraps any torch.utils.data.Dataset to inject a sample_id into each item (required for per-sample state tracking). Called automatically by GEKOTrainer — you only need it directly if you want to inspect the wrapped dataset.
from geko import GEKODataset
wrapped = GEKODataset(your_dataset)
item = wrapped[0] # dict with original keys + 'sample_id'
Requirement: Your dataset's
__getitem__must return adictwith at least an'input_ids'key. GEKO raises a clearTypeErrorat construction time if this is not satisfied.
The GEKO Algorithm
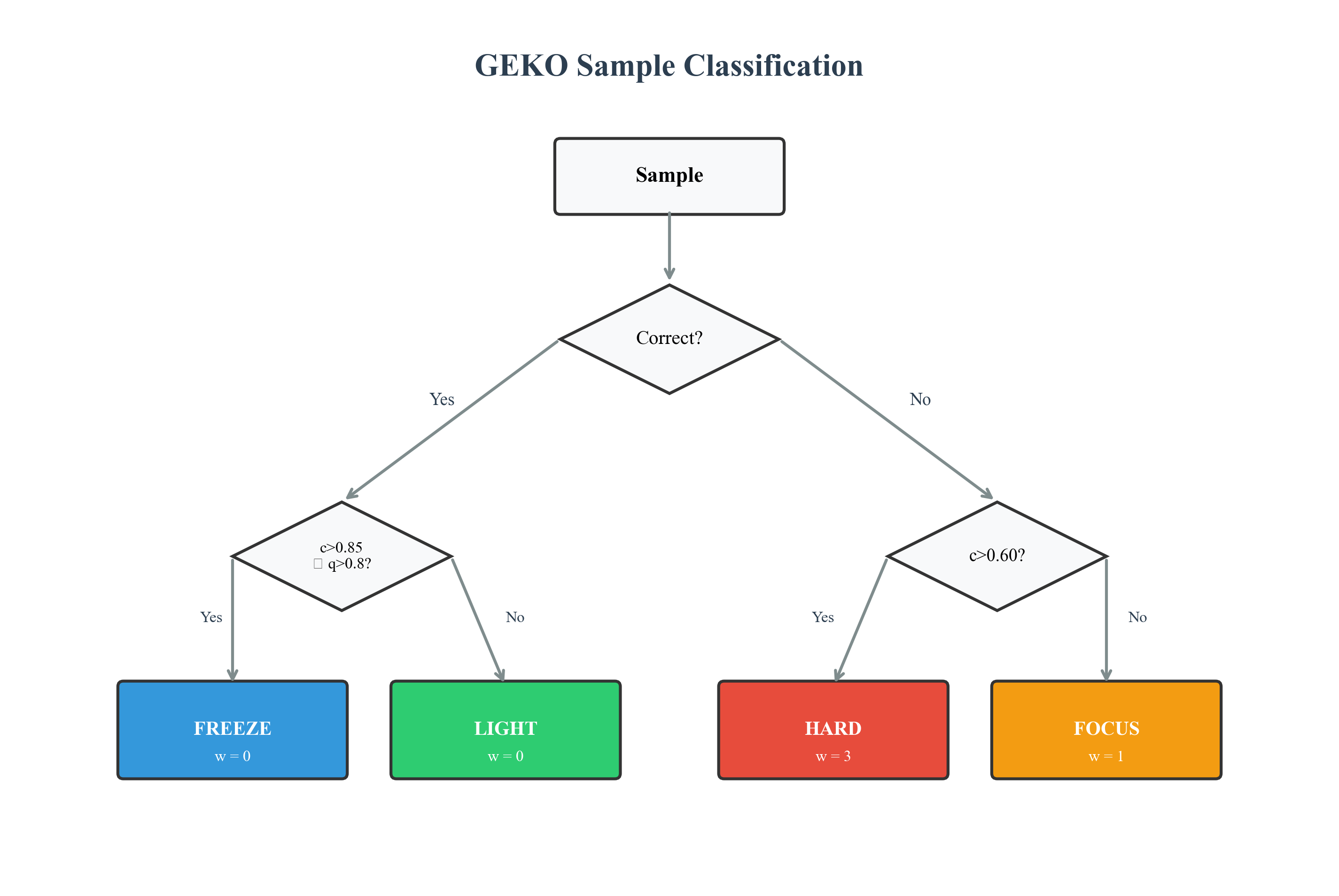
Bucket Definitions
| Bucket | Condition | Weight | Description |
|---|---|---|---|
| 🔵 FREEZE | $correct \land c > 0.85 \land q > 0.80$ | $w = 0$ | Mastered |
| 🟢 LIGHT | $correct \land (c \leq 0.85 \lor q \leq 0.80)$ | varies* | Uncertain |
| 🟠 FOCUS | $\neg correct \land c \leq 0.60$ | $w = 1$ | Wrong |
| 🔴 HARD | $\neg correct \land c > 0.60$ | $w = 3$ | Confident-wrong |
*LIGHT weight varies by curriculum phase: 3 (WARMUP/CONSOLIDATE), 1 (ASCENT/DESCENT), 0 (PEAK).
Mountain Curriculum
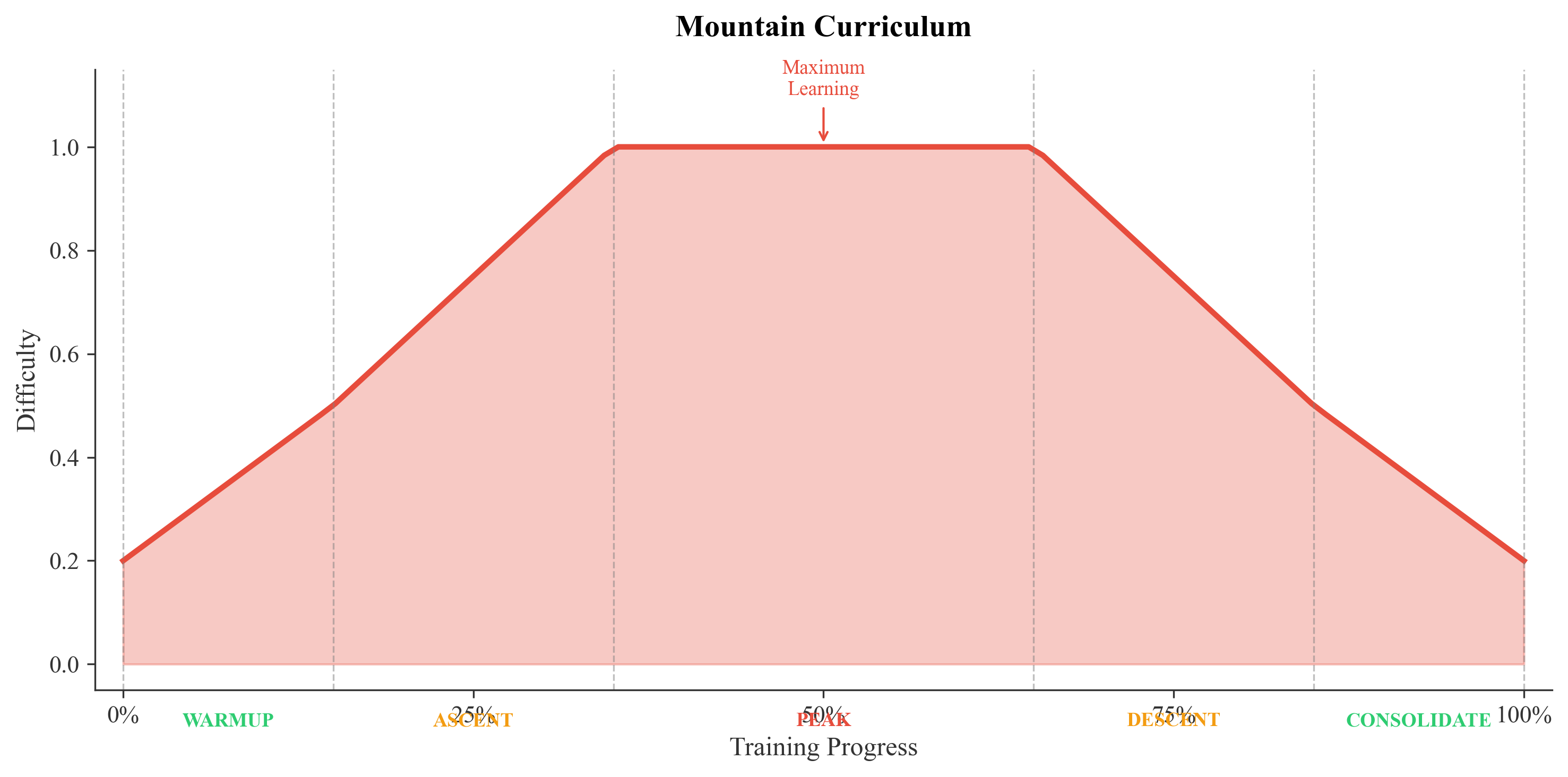
Five Phases
| Phase | Progress | HARD | FOCUS | LIGHT | Strategy |
|---|---|---|---|---|---|
| WARMUP | 0-15% | 1 | 2 | 3 | Build foundation |
| ASCENT | 15-35% | 2 | 3 | 1 | Increase difficulty |
| PEAK | 35-65% | 5 | 2 | 0 | Maximum learning |
| DESCENT | 65-85% | 2 | 3 | 1 | Reduce difficulty |
| CONSOLIDATE | 85-100% | 1 | 2 | 3 | Reinforce |
Q-Value Learning
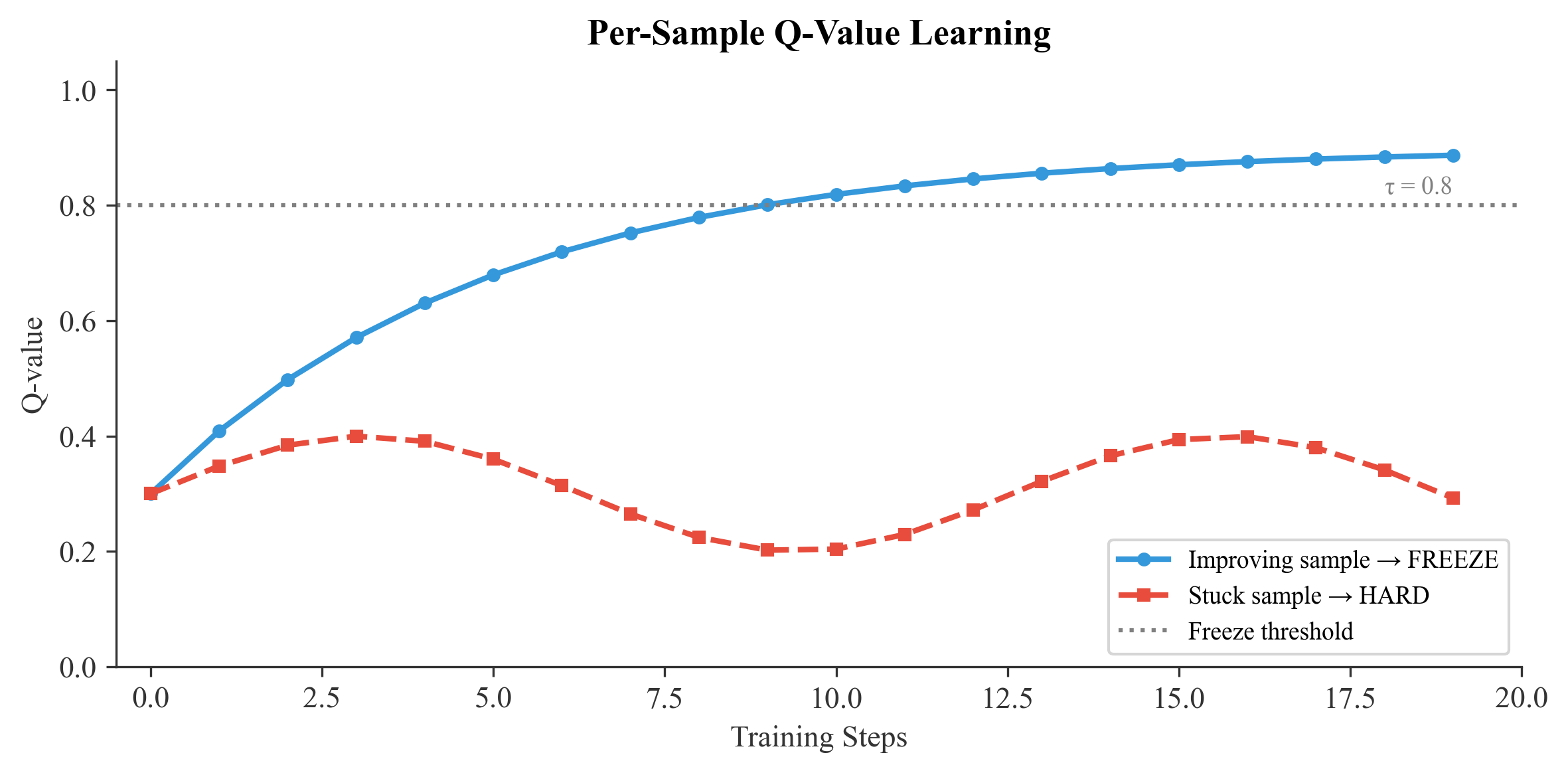
Each sample maintains a Q-value representing "learnability":
$$Q_{t+1}(s) = (1 - \alpha) \cdot Q_t(s) + \alpha \cdot \left(1 - \frac{\ell_t(s)}{\ell_{max}}\right)$$
Where $\ell_{max}$ is q_value_loss_scale (default 10.0). Set this to your model's typical maximum loss for accurate Q-value computation. For example, use q_value_loss_scale=2.0 for cross-entropy losses in the 0–2 range.
Efficiency Analysis
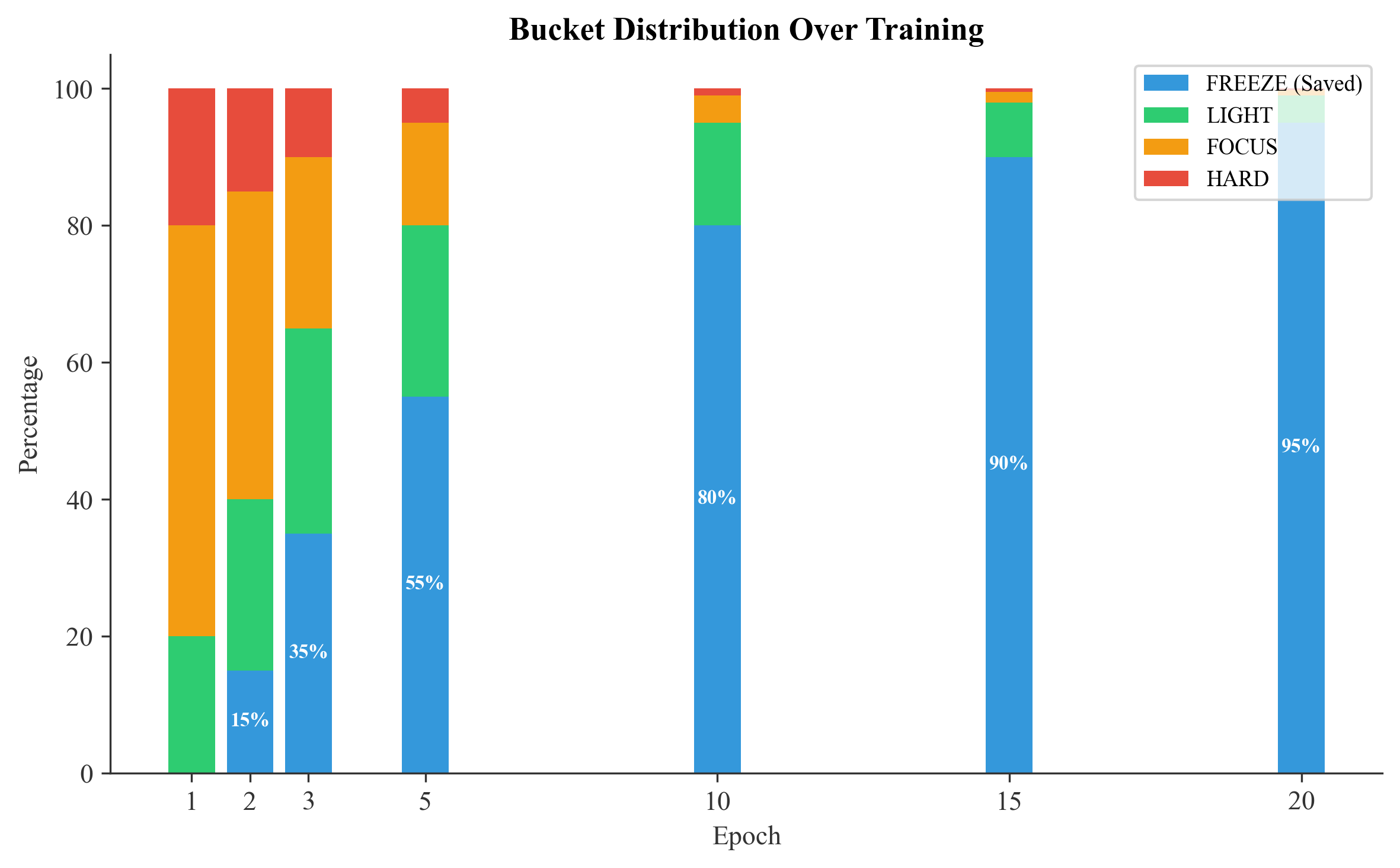
Training Progression
| Epoch | FREEZE | LIGHT | FOCUS | HARD | Compute Saved |
|---|---|---|---|---|---|
| 1 | 0% | 20% | 60% | 20% | 0% |
| 2 | 15% | 25% | 45% | 15% | 15% |
| 3 | 35% | 30% | 25% | 10% | 35% |
| 5 | 55% | 25% | 15% | 5% | 55% |
| 10 | 80% | 15% | 4% | 1% | 80% |
Architecture
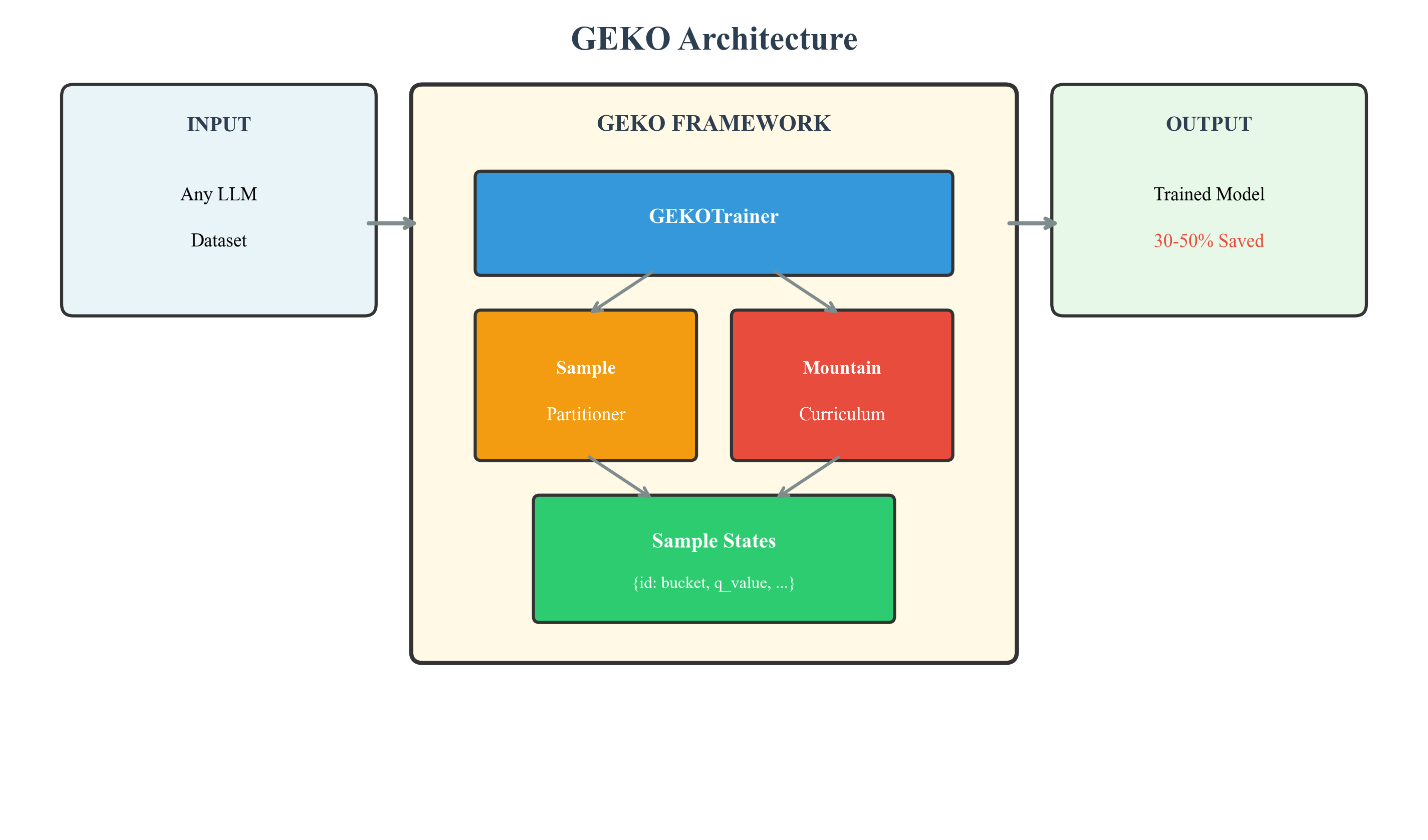
Theoretical Guarantees
Convergence
Under standard assumptions, GEKO converges:
$$\sum_{t=1}^{\infty} w_t^{(s)} = \infty \quad \forall s \notin \text{FREEZE}$$
Efficiency Bound
$$T_{GEKO} \leq T_{standard} \cdot (1 - \mathbb{E}[F])$$
Where $\mathbb{E}[F]$ = expected freeze fraction.
Results
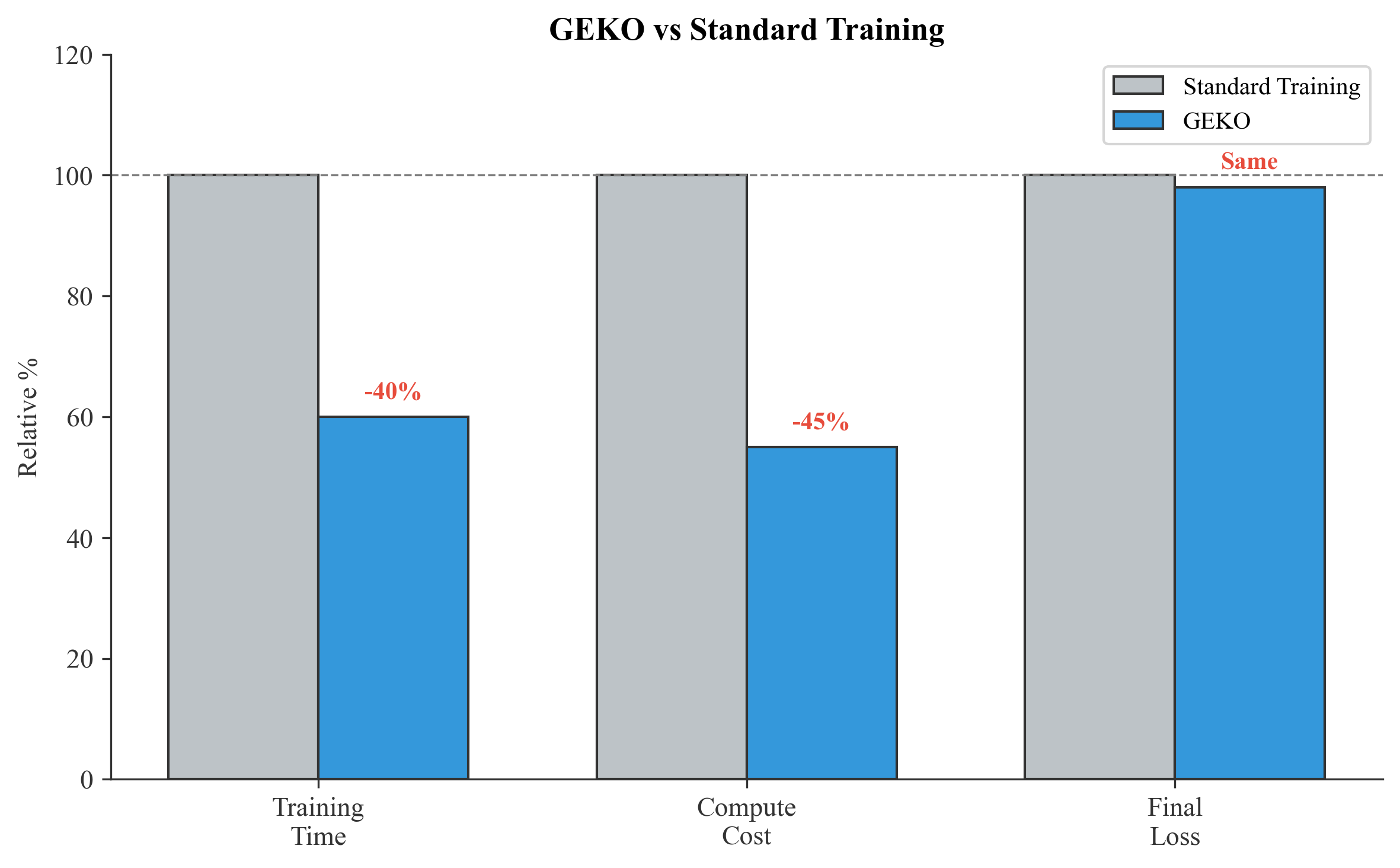
| Metric | Standard | GEKO | Improvement |
|---|---|---|---|
| Training Time | 100% | 50-70% | 30-50% faster |
| Compute Cost | 100% | 50-70% | 30-50% cheaper |
| Final Loss | $\ell^*$ | $\leq \ell^*$ | Equal or better |
GPT-2 Verification (90 samples, 5 epochs, CPU)
Bucket distribution observed during a real GEKO + GPT-2 training run:
| Epoch | FREEZE | LIGHT | FOCUS | HARD | Compute Saved |
|---|---|---|---|---|---|
| 0 | 0% | 0% | 100% | 0% | 0% |
| 1 | 0% | 0% | 67.8% | 32.2% | 0% |
| 2 | 0% | 13.3% | 21.1% | 65.6% | 0% |
| 3 | 6.7% | 52.2% | 10.0% | 31.1% | 6.7% |
| 4 | 25.6% | 68.9% | 3.3% | 2.2% | 25.6% |
| 5 | 25.6% | 68.9% | 3.3% | 2.2% | 25.6% |
Loss progression: 5.89 → 0.87 → 0.41 → 0.17 → 0.13. Final accuracy: 94.4%. All 5 Mountain Curriculum phases triggered in order. Checkpoint round-trip verified.
Changelog
v0.2.0
- Per-sample correctness and loss tracking when model returns 1D loss — true per-sample bucketing
- One-time warning when falling back to batch-level correctness (model returns scalar loss)
GEKODatasetnow requires'input_ids'key — clearTypeErrorat construction with fix exampleeval_datasetvalidated at trainer init (must return dicts)- All-FREEZE epoch skip — detects zero weights and skips the epoch entirely instead of running uniform
- Division-by-zero guards for empty datasets, empty epochs, and efficiency report
PartitionStats.to_dict()/from_dict()— partition history now fully serialized to checkpointsload_checkpoint()restores partition history —get_efficiency_report()works correctly after resume- Graceful old-format checkpoint handling (friendly message, continues cleanly)
- Added
load_checkpoint()/save_checkpoint()for full training resumption - Added linear warmup LR scheduler (
warmup_steps) - Added optional evaluation loop (
eval_dataset,eval_steps) - Fixed
global_stepto count optimizer steps (consistent with gradient accumulation) - Added
max_times_seenenforcement in weighted sampler - Added
q_value_loss_scalefor accurate Q-value normalization - Added GitHub Actions CI (Python 3.9 / 3.10 / 3.11)
- Exported
GEKOTrainingArgsandGEKODatasetfrom top-levelgekopackage - Removed dead config fields (
warmup_epochs,curriculum_phases)
v0.1.1
- Mixed-precision training via
torch.amp(fp16 auto-detects CUDA) - Gradient accumulation support
- Per-sample state updates inside the training loop (not post-epoch)
- Clear
TypeErrorfor datasets that don't return dicts - Startup summary printed before training begins
v0.1.0
- Initial release: GEKO algorithm, Mountain Curriculum, Q-value tracking
Citation
@software{geko2026,
author = {Syed Abdur Rehman},
title = {GEKO: Gradient-Efficient Knowledge Optimization},
year = {2026},
url = {https://github.com/ra2157218-boop/GEKO},
doi = {10.5281/zenodo.18750303}
}
License
Apache 2.0
GEKO - Train smarter, not harder.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file gekolib-0.2.0.tar.gz.
File metadata
- Download URL: gekolib-0.2.0.tar.gz
- Upload date:
- Size: 37.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0d42158ba7f4d150a7832c40c7c1bab2f25c66cea02370f81614752094e7b70a
|
|
| MD5 |
32871563877ac708bc232711b5b63795
|
|
| BLAKE2b-256 |
5a912f1a88b8dd6179511fb8e1dab92d4058dff54a505004210bc692a219d717
|
File details
Details for the file gekolib-0.2.0-py3-none-any.whl.
File metadata
- Download URL: gekolib-0.2.0-py3-none-any.whl
- Upload date:
- Size: 36.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dcf5833a035972513e01b5516b1fc35595ab6a4b2fff897f09b312aa2b920446
|
|
| MD5 |
9913c4afe484c63eb4fb2b459be8a6c3
|
|
| BLAKE2b-256 |
2d530c221da8861810118b1d66ee274f0a82465484c905a3cc23df4875d8a7e7
|







