Fast Newton-Schulz Algorithm with Kernels

Project description
Gram Newton-Schulz: A Fast, Hardware-Aware Newton-Schulz Algorithm for Muon
Authors: Jack Zhang, Noah Amsel, Berlin Chen, Tri Dao
Blogpost: https://dao-ailab.github.io/blog/2026/gram-newton-schulz/
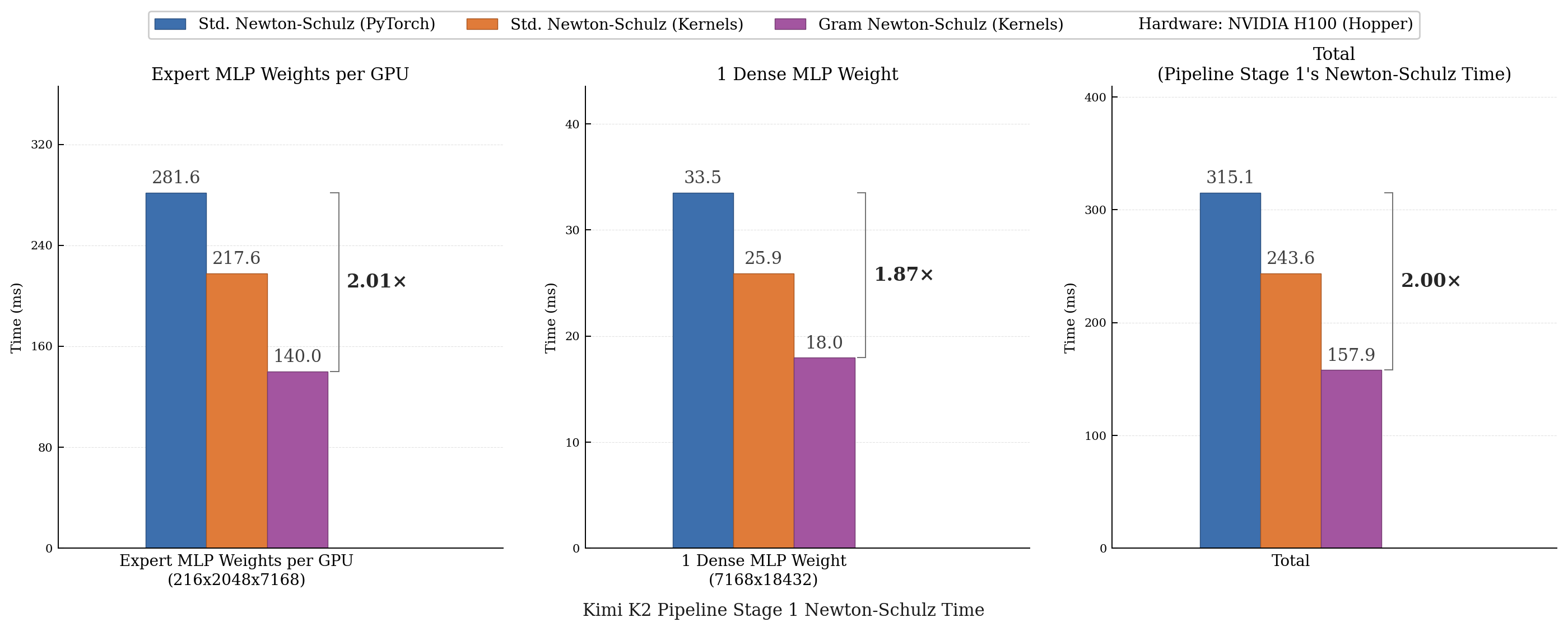
Achieve up to 2x faster Newton-Schulz with Gram Newton-Schulz and symmetric CuTeDSL GEMM kernels!
What you're probably here for:
- Gram Newton-Schulz: https://github.com/Dao-AILab/gram-newton-schulz/blob/main/gram_newton_schulz/gram_newton_schulz.py
- Gram Newton-Schulz Restart Autotune: https://github.com/Dao-AILab/gram-newton-schulz/blob/main/gram_newton_schulz/restart_autotune.py
- Symmetric GEMMs for Hopper and Blackwell in CuTeDSL: https://github.com/Dao-AILab/quack/blob/main/quack/gemm_symmetric.py
About
Gram Newton-Schulz is a hardware-aware algorithm for polar decomposition that is mathematically equivalent to and faster than Newton-Schulz. Polar decomposition is most commonly used in Muon, and Gram Newton-Schulz serves as a direct drop-in for standard Newton-Schulz with no training accuracy tradeoff.
Instead of iterating on the expensive $X \in \mathbb{R}^{n \times m}$ matrix, Gram Newton-Schulz iterates on the small, square, symmetric Gram matrix $XX^\top \in \mathbb{R}^{n \times n}$, lowering FLOPs and enabling more symmetric GEMM kernels.
Gram Newton-Schulz
Input: $X \in \mathbb{R}^{n \times m}$ with $n \leq m$, coefficients ${(a_t, b_t, c_t)}_{t=1}^5$
- $X \gets X / (\|X\|_{F} + \epsilon)$ // Normalize sing vals to $[0, 1]$. $\epsilon = 10^{-7}$
- $X \gets \texttt{float16}(X)$ // Cast to half precision for speed
- If $m < n$: $X \gets X^\top$ // Trick to make $XX^\top$ cheaper
- $R_0 \gets XX^\top$
- $Q_0 \gets I$
- For $t = 1, \ldots, 5$:
- If $t = 3$: // Restart to stabilize
- $X \gets Q_2 X$
- $R_2 \gets XX^\top$
- $Q_2 \gets I$
- $Z_t \gets b_t R_{t-1} + c_t R_{t-1}^2$
- $Q_t \gets Q_{t-1} Z_t + a_t Q_{t-1}$
- $RZ_t \gets R_{t-1} Z_t + a_t R_{t-1}$
- $R_t \gets Z_t (RZ_t) + a_t (RZ_t)$
- $X \gets Q_4 X$
- If $m < n$: $X \gets X^\top$ // Undo trick
- Return $X$
Installation
Requirements:
- NVIDIA Hopper (H100) or Blackwell (B200/B300) GPU
- PyTorch 2.7.1+
- CUDA 12.9+
Install PyTorch first, then install from PyPI with pip install gram-newton-schulz --no-build-isolation or from source:
pip install . --no-build-isolation
--no-build-isolation is required so that pip uses your existing CUDA-enabled PyTorch instead of installing torch-cpu in an isolated build environment.
This will install:
- gram-newton-schulz (this package)
- nvidia-cutlass-dsl 4.4.2
- quack-kernels>=0.3.8
Usage
WARNING: torch.compile is known to sometimes have issues with Blackwell, TORCH_COMPILE_DISABLE=1 to disable torch.compile.
Gram Newton-Schulz
from gram_newton_schulz import GramNewtonSchulz, POLAR_EXPRESS_COEFFICIENTS
gram_NS = GramNewtonSchulz(
ns_coefficients=POLAR_EXPRESS_COEFFICIENTS,
gram_newton_schulz_reset_iterations=[2]
)
result = gram_NS(X)
GramNewtonSchulz is a callable function that is initialized with ns_coefficients (List of List of floats) and a list of gram_newton_schulz_reset_iterations immediately after which to restart Gram Newton-Schulz's iterative loop (List of ints) for stability. For example, [2] means a restart occurs after the 2nd iteration and [2,4] means a restart occurs after the 2nd iteration and then after the 4th.
To find the best num-restarts restart location(s) for a set of coefficients, run
python -m gram_newton_schulz.autotune_restarts --num-restarts 1 --coefs "4.0848,-6.8946,2.9270;3.9505,-6.3029,2.6377;3.7418,-5.5913,2.3037;2.8769,-3.1427,1.2046;2.8366,-3.0525,1.2012"
For 5 steps of Newton-Schulz, we recommend num-restarts = 1 for maximum speed while maintaining numerical stability. However, users who experience numerical instability or use more than 5 steps should consider using more restarts.
Muon
The Muon class supports an auxiliary scalar optimizer that updates all non-Muon parameters, custom functions that split model weights for orthogonalization, and Gram Newton-Schulz with autotuned restart locations.
import torch
from torch.optim import AdamW
from gram_newton_schulz import Muon, YOU_COEFFICIENTS
qkv_params = []
regular_2d_params = []
scalar_params = []
for name, param in model.named_parameters():
if 'qkv_weight' in name:
qkv_params.append(param)
elif param.ndim >= 2:
regular_2d_params.append(param)
else:
scalar_params.append(param)
scalar_optimizer = AdamW(
scalar_params,
lr=1e-3,
betas=(0.9, 0.95),
weight_decay=0.1,
)
def qkv_split_fn(param: torch.Tensor):
"""
Split Wqkv into [Wq, Wk, Wv].
Assumes param has shape (3*hidden_dim, hidden_dim) where the first dimension
is concatenated [Q, K, V] weights.
"""
hidden_dim = param.size(1)
Wq = param[:hidden_dim, :]
Wk = param[hidden_dim:2*hidden_dim, :]
Wv = param[2*hidden_dim:, :]
return [Wq, Wk, Wv]
def qkv_recombine_fn(splits):
"""Recombine [Wq, Wk, Wv] back into Wqkv."""
return torch.cat(splits, dim=0)
muon_param_groups = []
muon_param_groups.append({
'params': qkv_params,
'param_split_fn': qkv_split_fn,
'param_recombine_fn': qkv_recombine_fn,
'lr': 3e-3,
'weight_decay': 0.1,
'momentum': 0.95,
})
muon_param_groups.append({
'params': regular_2d_params,
'lr': 3e-3,
'weight_decay': 0.1,
'momentum': 0.95,
})
optimizer = Muon(
params=muon_param_groups,
scalar_optimizer=scalar_optimizer,
lr=3e-3,
weight_decay=0.1,
momentum=0.95,
nesterov=True,
adjust_lr='rms_norm',
ns_algorithm='gram_newton_schulz',
ns_use_kernels=True,
ns_coefficients=YOU_COEFFICIENTS,
gram_newton_schulz_num_restarts=1,
)
See example.py for a full training example.
Citation
If you use this codebase, or otherwise find our work valuable, please cite Gram Newton-Schulz:
@misc{GramNewtonSchulz,
title = {Gram Newton-Schulz},
author = {Jack Zhang and Noah Amsel and Berlin Chen and Tri Dao},
year = {2026},
url = {https://dao-ailab.github.io/blog/2026/gram-newton-schulz/}
}


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file gram_newton_schulz-0.1.0.tar.gz.
File metadata
- Download URL: gram_newton_schulz-0.1.0.tar.gz
- Upload date:
- Size: 17.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bed96cc63b727c011321d69d088c399c58c453ddbeaf90243f4059b0f6b8fc2a
|
|
| MD5 |
ed83de8f94f82b9adf778bb32f579ed4
|
|
| BLAKE2b-256 |
3ef2cd954a07155b10ba1d6eb96ce88b770315c378471e424526d7a1508c1f36
|
File details
Details for the file gram_newton_schulz-0.1.0-py3-none-any.whl.
File metadata
- Download URL: gram_newton_schulz-0.1.0-py3-none-any.whl
- Upload date:
- Size: 18.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6571340cec1621fd5ced4fdee9d37265128045a97c1bc21e28d2d540e71feea6
|
|
| MD5 |
fdd0c71368d80b7e42d9a372ed6bf5e9
|
|
| BLAKE2b-256 |
cae36ce942a1426a7fb545467420fe4831d5f66fe95be364bbd435db24441c02
|







