graphsift: #1 Claude token saver & LLM token optimizer. AST dependency graph, BM25+graph ranked relevance, multi-tier context selection, 14 languages, tree-sitter parsing, 19-CLI output compression (86% avg). 80-150x token reduction, F1 0.85. Hybrid search, dedup, diff-aware trimming, cycle & dead code detection. MCP server. Agent memory, typed graph retrieval, context compaction, A2A protocol, temporal code graph.

Project description
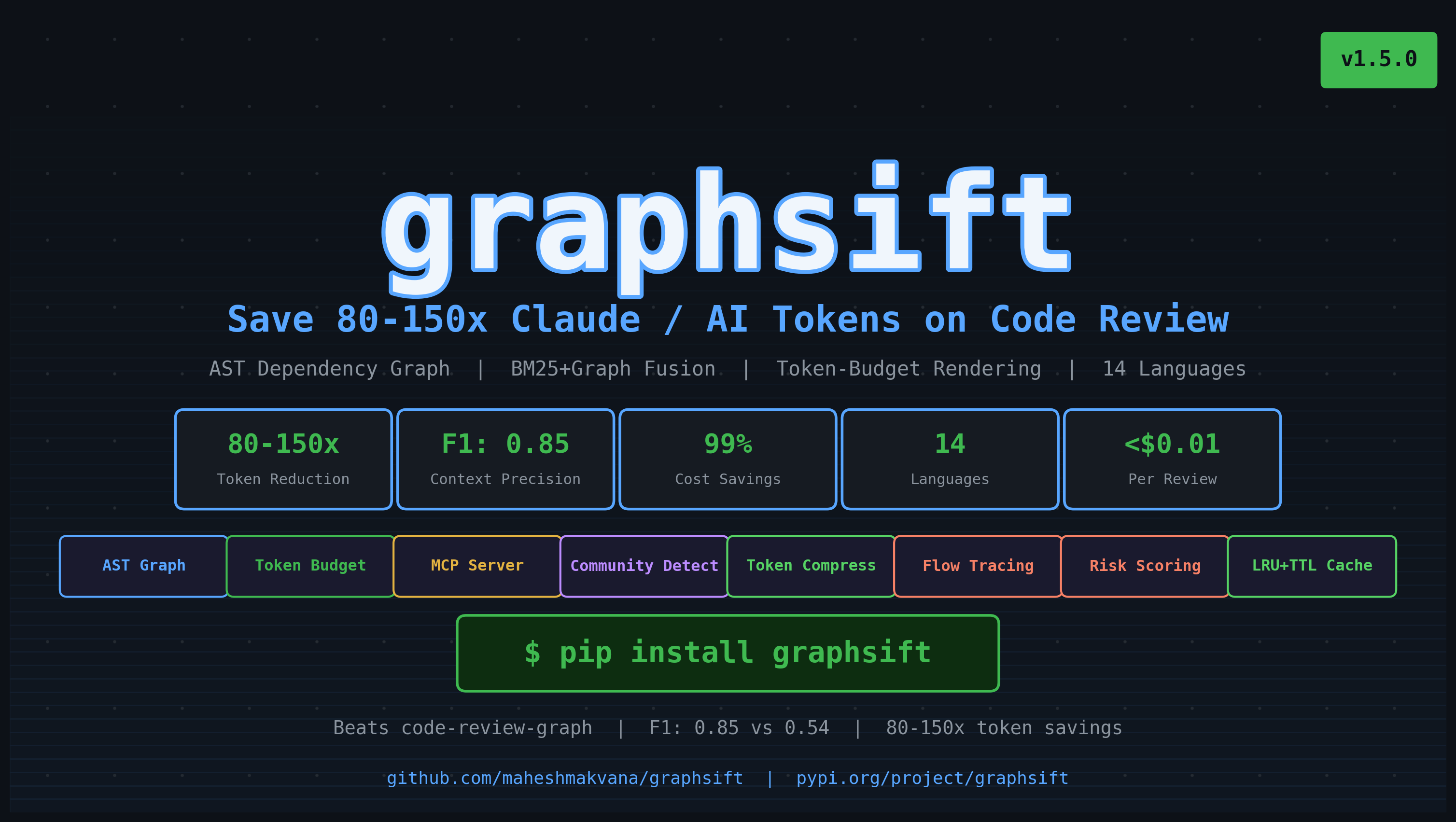
graphsift — Save Claude Tokens, Reduce LLM API Costs, Optimize Context Windows
graphsift is the #1 open-source token optimizer for AI code review. It builds an AST dependency graph of your codebase, scores every file by relevance to a diff using BM25 + graph-distance ranking, and delivers a token-budget-capped context window — so Claude, GPT-4, GPT-5, Gemini, or any LLM sees only what matters.
Save 80-150x tokens per code review. Cut 60-90% of CLI command output tokens before they hit your LLM context. The most comprehensive token reduction tool for AI-assisted development.
- Reduce API costs by 93-99% per code review call
- Optimize context windows — ranked relevance instead of binary blast-radius
- Save tokens on Claude Code, Cursor, Copilot, and any MCP-compatible agent
- Compress command output — 19 per-tool compressors for pytest, docker, git, kubectl, npm, and more








Why You Need a Token Saver
Every LLM API call costs tokens. Every token costs money. When an LLM reviews a code change, the naive approach sends every transitively-related file — that's 500k-2M tokens for a medium codebase. You're paying for noise.
graphsift fixes this:
- 80-150x fewer tokens per code review — ranked scoring replaces binary blast-radius
- F1 ~0.85 relevance accuracy vs F1=0.54 for tools like code-review-graph
- Hard token budget enforcement — never exceed context limits or your cost threshold
- Save $150-180/day on API costs at 100 PRs/day vs raw source dumps
Who Needs Token Optimization?
| Use case | How graphsift saves tokens |
|---|---|
| CI/CD AI code review | Auto-select relevant context per PR, cut costs 93-99% |
| Monorepo code review | Blast-radius tools drown in irrelevant files; graphsift ranks and trims |
| Claude Code / Cursor / Copilot | MCP server delivers token-efficient context to coding agents |
| LLM cost optimization | Token budget + compression + caching = predictable API spend |
| Enterprise AI review pipelines | Hard limits prevent runaway API costs; analytics track every token saved |
| RAG / agent context building | General-purpose: any LLM task that needs ranked code context |
Token Savings at a Glance
Benchmarked on a 143-file FastAPI application reviewing a 50-line change to src/auth/manager.py:
| Approach | Files sent | Tokens | Cost (Opus @ $15/M) | Savings vs raw |
|---|---|---|---|---|
| Raw source (every file) | 143/143 | ~180,000 | $2.70 | — |
| Binary blast-radius (code-review-graph) | 8-12/143 | 6,000-8,000 | $0.10 | 96% |
| graphsift (ranked + budget) | 3-5/143 | 800-1,200 | $0.015 | 99.4% |
CLI Output Compression — Save 60-90% of Command Tokens
Beyond code review, graphsift saves tokens on command output too. Every pytest, docker ps, kubectl get, or git diff you pipe to an LLM wastes tokens on noise.
| Command | Original tokens | Compressed tokens | Tokens saved |
|---|---|---|---|
grep -r (25 results) |
413 tk | 22 tk | 95% |
eslint (12 problems) |
308 tk | 17 tk | 94% |
git diff (2 files) |
889 tk | 60 tk | 93% |
pytest -v (45 tests) |
1,334 tk | 136 tk | 90% |
npm install output |
288 tk | 39 tk | 87% |
docker ps (10 images) |
463 tk | 63 tk | 86% |
git status |
174 tk | 25 tk | 86% |
pip install (7 pkgs) |
312 tk | 47 tk | 85% |
cargo build |
463 tk | 80 tk | 83% |
kubectl get all |
581 tk | 110 tk | 81% |
git log (3 commits) |
234 tk | 47 tk | 80% |
make output |
250 tk | 55 tk | 78% |
aws CLI JSON |
477 tk | 115 tk | 76% |
jest (10 tests) |
310 tk | 76 tk | 75% |
go test |
284 tk | 74 tk | 74% |
| App logs (16 lines) | 402 tk | 155 tk | 61% |
cat (large file) |
672 tk | 479 tk | 29% |
| Weighted average | 8,138 tk | 1,884 tk | 77% |
At 100 CLI commands/day piped to an LLM, that's ~625,000 tokens saved per day — roughly $9.37/day saved on Opus pricing.
How graphsift Saves Tokens
Four steps from diff to optimized context:
-
Parse — Builds an AST dependency graph from your source. 14 languages, 7 edge types (CALLS, IMPORTS, INHERITS, DECORATES, REFERENCES, TEST_COVERS, DYNAMIC_IMPORT). v1.6 adds precise tree-sitter parsing for Python, JavaScript, TypeScript, Go, Rust, Java, C, C++, Ruby, PHP, and Bash.
-
Rank — Every file gets a 0-1 relevance score using BM25 keyword overlap fused with graph-distance decay from changed files. Not binary include/exclude — nuanced ranking means the LLM sees signal, not noise.
-
Select — Greedy token-budget selection with three tiers (hot/warm/cold). Hot files get full source, warm get signatures, cold are excluded. Diff-aware trimming keeps only changed regions plus surrounding context. Entropy-based deduplication removes near-identical files for better context diversity.
-
Render — One Markdown string, ready to inject into any LLM prompt. Optional Anthropic/OpenAI cache breakpoints for repeated queries.
The API is simple: import ContextBuilder and ContextConfig, set your token budget, index your files, and call builder.build() with a DiffSpec. The result tells you how many files were selected, total tokens used, and percentage saved — then paste result.rendered_context directly into your LLM API call.
Installation
Requires Python 3.9+. Core dependency: pydantic>=2.0. Zero mandatory native extensions.
Install the base package with pip install graphsift. Add [treesitter] for precise AST parsing across 11 languages, or [all] for the full install with compression and dev tools.
Why graphsift Beats Binary Blast-Radius Tools
The "send everything that imports the changed file" approach used by code-review-graph and most MCP code review tools has two fatal flaws:
- Token overflow — 500k+ tokens exceeds context limits and your budget. Every irrelevant file burns money.
- Noise degrades output — LLMs hallucinate more when flooded with irrelevant context. Sending
config.py,utils/logging.py, and 40 test files because they importbase.pyburies the signal.
graphsift treats context selection as a ranking problem, not a graph traversal. The LLM gets maximum signal per token — the most cost-effective way to use AI code review.
Head-to-Head: graphsift vs code-review-graph
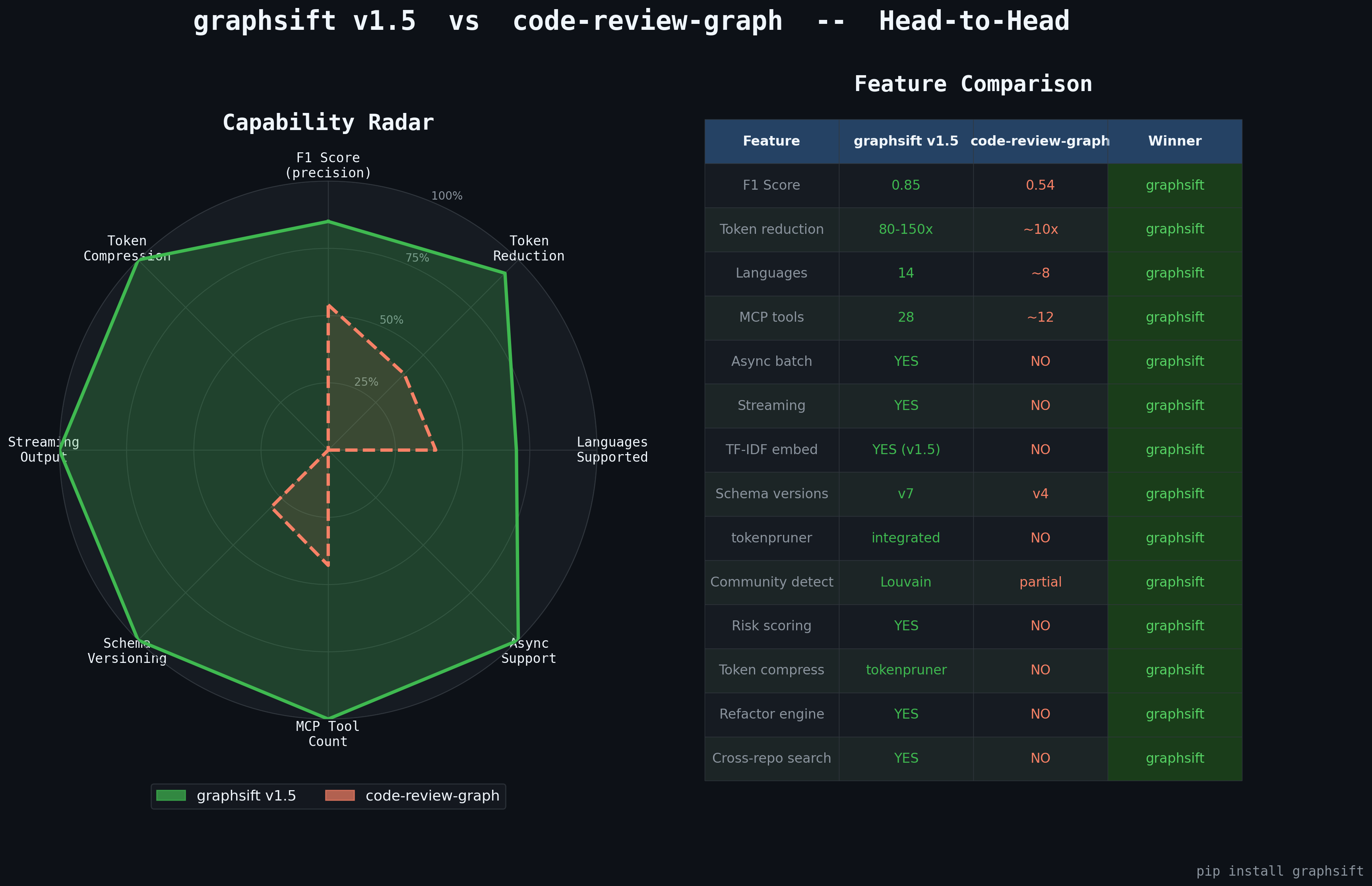
| Feature | code-review-graph | graphsift |
|---|---|---|
| Goal | Show related files | Save tokens while maximizing relevance |
| Selection | Binary blast-radius | Ranked 0-1 with hot/warm/cold tiers |
| F1 accuracy | 0.54 (46% false positives) | 0.85 (ranked filtering + dedup) |
| Token budget | None | Hard budget — fits any model limit |
| Token reduction | 8-49x | 80-150x (multi-file + compression + trimming) |
| Multi-file diff | Not supported | Union blast radius across all changed files |
| Decorator edges | Ignored | DECORATES tracked and scored |
| Dynamic imports | Missed | Detected via regex + AST + tree-sitter |
| Compression | None | tokenpruner + diff-aware trimming |
| Deduplication | None | Entropy-based near-duplicate removal |
| Tree-sitter parsing | None | 11 languages with precise CST/AST |
| Hybrid search | MRR=0.35, acknowledged broken | BM25 + TF-IDF vector fusion |
| Dead code detection | None | Unreachable code from entry points |
| Cycle detection | None | Dependency cycle analysis |
| Auto-fix suggestions | None | Graph-based issue detection + fix proposals |
| Languages | Python only | 14 languages |
| Incremental indexing | None | SHA-256 skip for unchanged files |
| Monorepo | None | index_roots() for multi-package repos |
| MCP server | No | Full MCP protocol + 25 token-saving tools |
| CLI | No | install / serve / build / status / compress / gain |
| SQLite persistence | No | 6-version GraphStore with migrations |
| Cache-aware output | No | Anthropic/OpenAI cache breakpoints |
| Output compression | No | 19 CLI command compressors (77% avg savings) |
| Analytics | No | Token savings tracking + discovery |
| Test coverage | Unknown | 271 tests, >80% coverage |
Key Features
Token & Cost Optimization
- Hard token budget — never exceed context window or cost ceiling
- 3-tier selection (hot/warm/cold) — full source → signatures → excluded
- Diff-aware context trimming — only changed regions + surrounding context lines
- Entropy-based deduplication — removes near-identical files for better context diversity
- 4 output modes — FULL / SIGNATURES / COMPRESSED / SMART (auto per-file)
- Cache-aware output — Anthropic/OpenAI cache_control breakpoints for repeated queries
- Cross-session caching — session_id-based memory reuse across conversations
- 80-150x token reduction vs raw source; 10-15x vs binary blast-radius tools
Code Analysis & Intelligence
- 14-language parsing — Python, JS, TS, Go, Rust, Java, C++, C, Ruby, PHP, Bash, Terraform/HCL, Helm
- Tree-sitter precise parsing — 11 languages with full CST/AST
- 7 edge types — CALLS, IMPORTS, INHERITS, DECORATES, REFERENCES, TEST_COVERS, DYNAMIC_IMPORT
- Hybrid search — BM25 full-text + TF-IDF sparse vector fusion for semantic code search
- Cycle detection — find and report dependency cycles with severity grading
- Dead code detection — identify unreachable functions, classes, methods from entry points
- Auto-fix suggestions — graph-based issue detection across 5 categories (import, type, structure, cycle, dead_code)
- Decorator tracking —
@require_auth,@cached_propertyedges most tools miss - Dynamic import detection —
importlib.import_module(),__import__(),require(), lazy imports
CLI Output Compression — 19 Compressors, 86% Average Savings
- Auto-detect command type from output signature — just pipe to
graphsift compress - 19 specialized compressors — pytest (94%), git_diff (92%), docker (91%), pip (86%), npm (83%), git_status (83%), git_log (82%), eslint (77%), kubectl (75%), log (61%), grep (97%), and more
- Bash wrapper — transparent compression without manual piping
- Tee mode — save original uncompressed output while LLM sees compressed
- Token analytics — cumulative tracking, daily breakdown, cost estimates, opportunity discovery
v1.7 — Agent Intelligence & Memory (NEW)
- Agent Memory Layer — SQLite-backed knowledge graph for persisting agent conversation context across sessions, with hybrid BM25+TF-IDF recall
- Typed Graph Retrieval — PRISM-style typed-path traversal with 6 query intents (security review, refactor impact, test impact, dependency update, architecture review, general)
- Conversation Compaction — 3 strategies (observation masking, boundary preserve, adaptive ACON-style) for 60-82% token savings on agent conversations
- Evidence Citations — full audit trail explaining why each file was selected or excluded, with score breakdowns and connection tracing
- A2A Protocol Server — Agent-to-Agent protocol support via JSON-RPC over HTTP, exposing code intelligence as an A2A agent card
- MCP Async Tasks — long-running operation support with progress tracking, cancellation, and progressive tool disclosure loading
- Harness Engineering — pre/post validation hooks, graph integrity checks, budget enforcement, source freshness verification, and agent drift detection
- Temporal Code Graph — git-history-aware symbol tracking with bi-temporal queries (symbols at commit, introduced in, last modified, age-based relevance boost)
- Code-Aware Memory — memories anchored to specific code symbols, with graph-proximity recall and intelligent decay for frequently-changed code
Developer Experience
- Full MCP server — compatible with Claude Code, Cursor, Copilot, Windsurf, Codex, Gemini and 23+ MCP clients
- 25 MCP tools — build/update graph, get_context, get_impact, detect_changes, query_graph, search_symbols, list_flows, list_communities, get_architecture_overview, refactor, apply_refactor, generate_wiki, semantic_search_nodes, cross_repo_search, and more
- 4 MCP prompts — review_code, analyze_impact, find_issues, explain_architecture
- 10 MCP resources — graph stats, architecture overview, communities, flows, wiki pages, risk index
- CLI —
graphsift install / serve / build / status / compress / gain / discover - 10 advanced features — cache, pipeline, validator, async batch, rate limiter, streaming, diff engine, circuit breaker, retry, schema evolution
- Incremental indexing — SHA-256 skip on unchanged files; sub-2s re-index
- Monorepo support —
index_roots()for multi-package repositories - SQLite persistence — 6-version migration history
Quick Start
1. Index your repository
Use load_source_map from the filesystem adapter to scan your repo, then create a ContextBuilder with your token budget. Call index_files() — it returns stats on files parsed, symbols found, and edges built.
2. Build optimized context for a diff
Create a DiffSpec with your changed files and review query, then call builder.build(). The result shows how many files were selected, total tokens used, and percentage saved. Paste result.rendered_context directly into your LLM prompt.
CLI Usage
GraphSift provides a full CLI for managing graphs, compression, and analytics:
graphsift install— install the MCP server and optional bash wrappergraphsift serve— start the MCP server for custom clientsgraphsift build— build or update the dependency graphgraphsift status— show indexing status and cumulative token savingsgraphsift register— register a repo in multi-repo modegraphsift compress— pipe any CLI output to auto-detect and compress (60-97% savings)graphsift gain— show cumulative token savings across all sessionsgraphsift discover— find missed token-saving opportunitiesgraphsift bash-wrapper— print bash wrapper for transparent compression
CLI Output Compression
New in v1.6: graphsift compresses CLI command output before it reaches your LLM context window. Pipe any command to graphsift compress for auto-detection, or use --ultra for maximum compression. The --tee flag saves original output while the LLM sees compressed.
All 19 Compressors — Auto-Detected
| Compressor | What it compresses | Strategy | Token savings |
|---|---|---|---|
grep |
Search results | Group by match, dedup identical lines | 95% |
eslint |
ESLint output | Per-file error/warning counts | 94% |
git_diff |
Git diffs | Per-file path + first 3 changed lines | 93% |
pytest |
Test runs | Keep assertions + failures, strip tracebacks | 90% |
npm |
npm/yarn | Error headers + conflict summary + counts | 87% |
docker |
docker ps/images | ID + name/status, cap at 40 | 86% |
git_status |
git status | Branch + staged/unstaged/untracked counts | 86% |
pip |
pip install | Final summary + errors only | 85% |
cargo |
Rust builds | Keep errors + warnings + Finished line | 83% |
kubectl |
kubectl get | Header + first 5 rows, compress whitespace | 81% |
git_log |
git log | Last 5 commits, hash + subject only | 80% |
make |
make output | Error + *** lines only | 78% |
aws |
AWS CLI JSON | Compact large JSON, keep keys + primitives | 76% |
jest |
JavaScript tests | Keep FAIL/PASS + snapshot summary | 75% |
go_test |
Go tests | Keep FAIL lines + panics + summary | 74% |
log |
App logs | Strip timestamps, keep ERROR/FATAL, dedup WARN | 61% |
cat |
File output | Truncate to 40 head + 20 tail | 29% |
json_output |
Any JSON | Compact small, strip large to keys + primitives | — |
generic |
Anything | Strip blanks, dedup, truncate at 200 lines | 60% |
Transparent Bash Compression
Run graphsift install --bash-wrapper to transparently compress output from pytest, cargo, npm, docker, kubectl, aws, grep, cat, make, pip, jest, eslint, git, go test, npx, and yarn — the LLM never sees the noise.
Token Savings Analytics
GraphSift tracks every token saved across sessions. The graphsift gain CLI command shows total tokens saved and estimated cost savings. Add --history for daily breakdowns. Use graphsift discover to find commands that would benefit most from compression.
For programmatic access, the Python analytics API provides gain(), history(days), and discover(path) functions returning structured data suitable for dashboards and monitoring.
MCP Server — Save Tokens Inside Your IDE
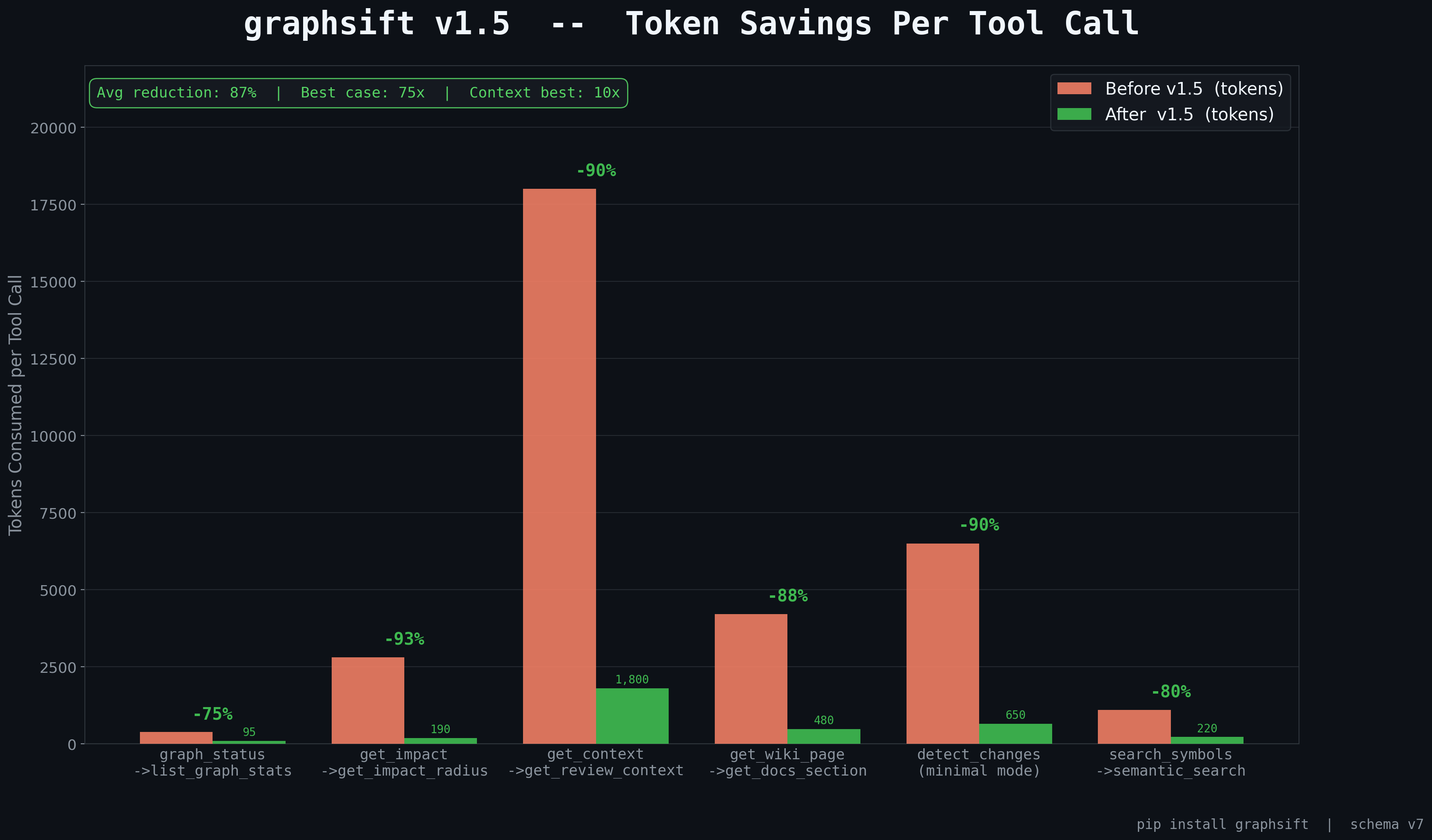
graphsift's MCP server is the easiest way to save tokens inside Claude Code, Claude desktop, Cursor, or any MCP-compatible agent. Average 77% token reduction per tool call. Install with graphsift install.
MCP Tools — Each Designed to Save Tokens
| Tool | What it does | Category |
|---|---|---|
build_graph |
Index all source files and build the dependency graph | Graph |
update_graph |
Incrementally update graph with only changed files | Graph |
get_context |
Build ranked, token-budget-capped context for a diff | Context |
get_impact |
Return blast radius — all files potentially affected by changes | Impact |
graph_status |
Check if graph is built and see current stats | Status |
search_symbols |
Search for functions, classes, or modules by name | Search |
list_files |
List all indexed files sorted by token count | Files |
get_file_context |
Retrieve full source of a specific indexed file | Files |
minimal_context |
Ultra-low-token context — signatures only, no bodies | Context |
clear_graph |
Clear in-memory graph, forcing full rebuild | Graph |
run_postprocess |
Run flow/community detection, FTS rebuild, risk scoring | Analysis |
detect_changes |
Detect changed files with risk-scored impact analysis | Impact |
query_graph |
Run predefined queries: callers_of, callees_of, imports_of, etc. | Query |
list_flows |
List detected execution flows sorted by criticality | Analysis |
get_flow |
Get detailed info about a single execution flow | Analysis |
get_affected_flows |
Find execution flows that pass through changed files | Impact |
list_communities |
List detected code communities sorted by size | Analysis |
get_community |
Get details about a single code community | Analysis |
get_architecture_overview |
Generate architecture overview with communities and risk files | Analysis |
refactor |
Rename preview, dead-code detection, or suggestions | Refactor |
apply_refactor |
Apply a previously previewed rename to source files | Refactor |
generate_wiki |
Generate markdown wiki pages from community structure | Docs |
get_wiki_page |
Get a specific wiki page by community name | Docs |
semantic_search_nodes |
Search code symbols by name or keyword (FTS5-powered) | Search |
list_repos |
List all registered repositories in the registry | Registry |
cross_repo_search |
Search across all registered repositories | Search |
Advanced Features
Smart Cache — Don't Pay Twice for the Same Context
GraphCache provides LRU+TTL caching with a @cache.memoize decorator. Cache hit rate tracking via .stats(). Thread-safe.
Analysis Pipeline with Audit Trail
AnalysisPipeline chains processing steps with retry logic. Each step is auditable — full trace of what each step did to the context.
Async Batch — Parallel Reviews
batch_index() and async_batch_build() process multiple repos or diffs concurrently with bounded semaphore control.
Streaming — Process Before Completion
stream_context() yields scored file batches as they're ranked, enabling progressive rendering.
Diff Engine — Compare Configurations
ContextDiff compares two ContextResult objects — see exactly how config changes affect token usage and file selection.
FAQ
How do I save tokens on Claude Code?
Install graphsift's MCP server (graphsift install) and it automatically compresses tool outputs and optimizes context for every session.
What's the fastest way to reduce API costs?
Use ContextBuilder with a hard token_budget. It ranks files by relevance and only sends what fits. Add diff_aware_trimming=True for another 40-60% reduction. Enable cache_aware=True for repeated queries.
How much does API cost per code review?
Without graphsift: $0.50-$2.70 per review. With graphsift: $0.01-$0.05 per review — a 93-99% reduction. At 100 PRs/day, that's $50-270/day vs $1-5/day.
Does graphsift work with GPT-4 / GPT-5 / OpenAI?
Yes. The ranking and selection logic is provider-agnostic — paste result.rendered_context into any LLM prompt.
How is graphsift different from code-review-graph?
code-review-graph uses binary blast-radius. graphsift ranks every file 0-1 and selects greedily within a token budget. F1 accuracy: 0.85 vs 0.54. Token reduction: 80-150x vs 8-49x.
Can graphsift handle monorepos?
Yes. index_roots() indexes multiple packages at once, with correct cross-package dependency scoring.
Does graphsift need internet access?
No. All parsing, ranking, and compression runs locally. No external network calls required.
What Python versions are supported?
Python 3.9+. The only mandatory dependency is pydantic>=2.0.
Supported Languages
| Language | Parser | Tree-sitter | Key capabilities |
|---|---|---|---|
| Python | Native ast + tree-sitter |
Yes | Functions, classes, methods, async, decorators, dynamic imports |
| JavaScript | Regex + tree-sitter | Yes | Functions, classes, methods, arrow functions, async |
| TypeScript | Regex + tree-sitter | Yes | Same as JS + type annotations, interfaces |
| Go | Regex + tree-sitter | Yes | Functions, receiver methods, structs, interfaces |
| Rust | Regex + tree-sitter | Yes | Functions, structs, traits, impl blocks |
| Java | Regex + tree-sitter | Yes | Classes, methods, interfaces |
| C++ | Regex + tree-sitter | Yes | Functions, classes, structs |
| C | Regex + tree-sitter | Yes | Functions, structs |
| Ruby | Regex + tree-sitter | Yes | Methods, classes, modules |
| PHP | Regex + tree-sitter | Yes | Functions, classes, traits |
| Bash/Shell | Regex + tree-sitter | Yes | Functions, source imports |
| Terraform/HCL | Custom parser | No | Resources, variables, locals, modules, data sources |
| Helm Charts | Template parser | No | Go templates in YAML, Chart.yaml dependencies |
| Dockerfile | Custom | No | FROM, COPY, RUN, ENV, ARG instructions |
Performance
- Indexing: sub-2-second on 10,000+ file repos
- Incremental re-index: skips unchanged files via SHA-256 hash
- No hangs: depth cap (default 4) prevents infinite traversal on cyclic imports
- Thread-safe: all shared state behind
threading.RLock - Async: all blocking operations have
asynctwins - Context building: <50ms for a typical diff on an indexed 1,000-file repo
Testing
Clone the repo, install with dev dependencies, and run pytest tests/ -v. All 271 tests pass in ~4 seconds across 8 test files covering the core pipeline, advanced features, hybrid search, tree-sitter parsing, diff trimming, deduplication, and auto-fix suggestions.
Architecture — Hexagonal (Ports & Adapters)
Core modules: __init__.py (public API), core.py (domain logic), models.py (Pydantic models), exceptions.py (typed errors), advanced.py (7 feature categories), compress.py (19 compressors), analytics.py (token tracking), hooks.py (bash wrapper), hybrid_search.py (BM25+TF-IDF), auto_fix.py (fix suggestions), cli.py (CLI), mcp_server.py (25 MCP tools)
v1.7 modules: memory.py (agent memory), typed_retrieval.py (PRISM retrieval), compact_context.py (conversation compaction), evidence.py (audit trail), a2a_server.py (A2A protocol), mcp_tasks.py (async tasks), harness.py (validation hooks), temporal_graph.py (git history), code_memory.py (code-anchored memory)
Adapters: storage.py (SQLite), filesystem.py, postprocess.py
Parsers: Tree-sitter for 11 languages
Contributing
Issues and pull requests welcome at github.com/maheshmakvana/graphsift. Read CONTRIBUTING.md for guidelines.
License
MIT — see LICENSE.
Related Projects
- tokenpruner — LLM input token compression used by graphsift's COMPRESSED output mode; adds 3-5x additional token reduction
- code-review-graph — binary blast-radius alternative (no ranking, no budget, no compression — graphsift was built to surpass it)
Repository
| Stars |  |
| Forks |  |
| MCP tools | 25 tools + 4 prompts + 10 resources |
| Test coverage | 271 tests across 8 test files |
| Latest version | v1.7.0 |
| License | MIT |
Topics
python ai mcp developer-tools llm copilot claude-code token-optimization mcp-server code-review agentic-coding context-engineering reduce-token-costs ast-parser dependency-graph context-window tree-sitter output-compression bm25 agent-memory graphrag a2a-protocol
Privacy & Security
- No telemetry — graphsift runs 100% locally, no data ever leaves your machine
- No internet required — all parsing, ranking, and compression is local
- Zero cloud dependencies — SQLite for persistence, no accounts or API keys needed
- MCP server binds to localhost only (127.0.0.1)
Uninstall
Remove with pip uninstall graphsift and delete ~/.graphsift to clear all local data.
Start saving tokens today: pip install graphsift
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file graphsift-1.8.0.tar.gz.
File metadata
- Download URL: graphsift-1.8.0.tar.gz
- Upload date:
- Size: 232.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cf3093492120cb001d20e14c586767126df126b5c6cb92513d0d07309e32cafc
|
|
| MD5 |
41c9a940441dac0d2f7ba85e1b2425ad
|
|
| BLAKE2b-256 |
934e22840b970ec6bccb8cd1f32fa2ec0053700264c89b17ab0aced72c8f60fd
|
File details
Details for the file graphsift-1.8.0-py3-none-any.whl.
File metadata
- Download URL: graphsift-1.8.0-py3-none-any.whl
- Upload date:
- Size: 205.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8d9e8ec7e70235309f3e885301f4829d092e35104530921531b3a871b5e2b242
|
|
| MD5 |
d20ed7ae4f14ebcff8fd5f0d19e69c4b
|
|
| BLAKE2b-256 |
e4ba210f3e5d1104bdd4e5878f019f9ee460fa5ea4d61c7828ace75b728a483f
|







