A CLI to estimate inference memory requirements for Hugging Face models, written in Python.

Project description

[!WARNING]
hf-memis still experimental and therefore subject to major changes across releases, so please keep in mind that breaking changes may occur until v1.0.0.
hf-mem is a CLI to estimate inference memory requirements for Hugging Face models, written in Python.
hf-mem is lightweight, only depends on httpx, as it pulls the Safetensors metadata via HTTP Range requests. It's recommended to run with uv for a better experience.
hf-mem lets you estimate the inference requirements to run any model from the Hugging Face Hub, including Transformers, Diffusers and Sentence Transformers models, as well as any model that contains Safetensors compatible weights.
$ uvx hf-mem --help
usage: hf-mem [-h] --model-id MODEL_ID [--revision REVISION] [--experimental]
[--max-model-len MAX_MODEL_LEN] [--batch-size BATCH_SIZE]
[--kv-cache-dtype {fp8,fp8_e5m2,fp8_e4m3,bfloat16,fp8_ds_mla,auto,fp8_inc}]
[--json-output] [--ignore-table-width]
options:
-h, --help show this help message and exit
--model-id MODEL_ID Model ID on the Hugging Face Hub
--revision REVISION Model revision on the Hugging Face Hub
--experimental Whether to enable the experimental KV Cache estimation
or not. Only applies to `...ForCausalLM` and
`...ForConditionalGeneration` models from
Transformers.
--max-model-len MAX_MODEL_LEN
Model context length (prompt and output). If
unspecified, will be automatically derived from the
model config.
--batch-size BATCH_SIZE
Batch size to help estimate the required RAM for
caching when running the inference. Defaults to 1.
--kv-cache-dtype {fp8,fp8_e5m2,fp8_e4m3,bfloat16,fp8_ds_mla,auto,fp8_inc}
Data type for the KV cache storage. If `auto` is
specified, it will use the default model dtype
specified in the `config.json` (if available). Despite
the FP8 data types having different formats, all those
take 1 byte, meaning that the calculation would lead
to the same results. Defaults to `auto`.
--json-output Whether to provide the output as a JSON instead of
printed as table.
--ignore-table-width Whether to ignore the maximum recommended table width,
in case the `--model-id` and/or `--revision` cause a
row overflow when printing those.
Read more information about hf-mem in this short-form post.
Usage
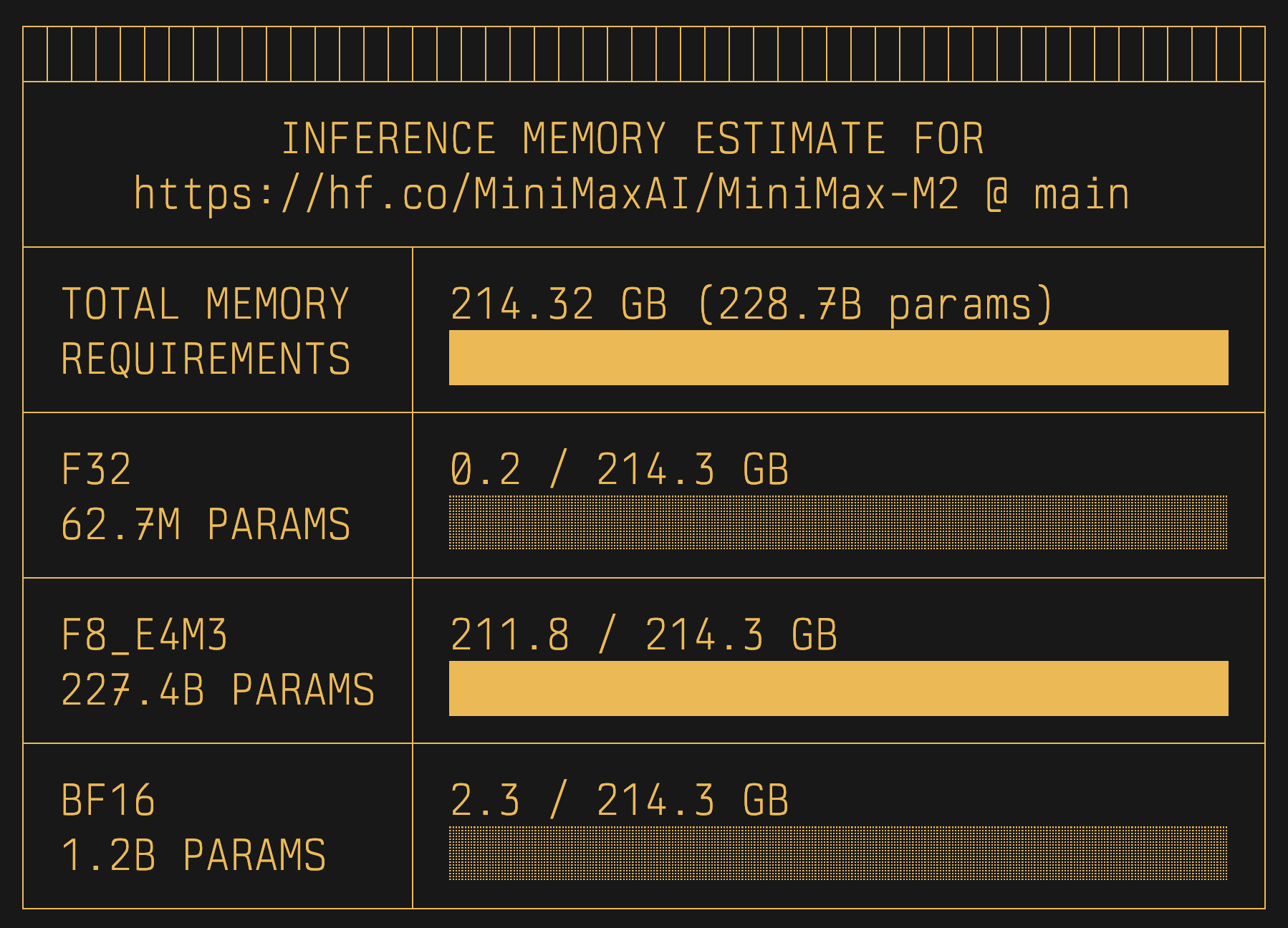
Transformers
uvx hf-mem --model-id MiniMaxAI/MiniMax-M2
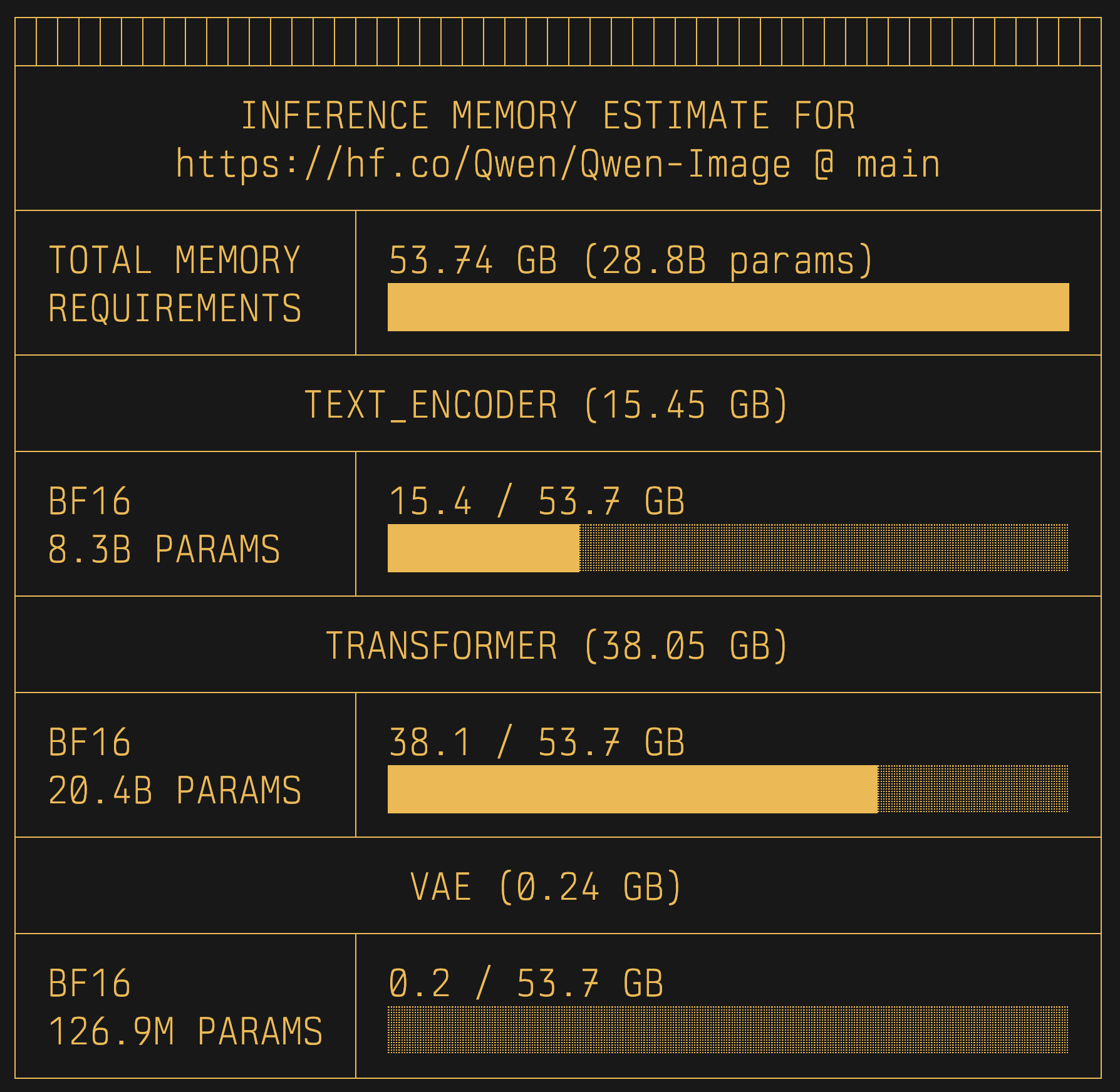
Diffusers
uvx hf-mem --model-id Qwen/Qwen-Image
Sentence Transformers
uvx hf-mem --model-id google/embeddinggemma-300m

Experimental
By enabling the --experimental flag, you can enable the KV Cache memory estimation for LLMs (...ForCausalLM) and VLMs (...ForConditionalGeneration), even including a custom --max-model-len (defaults to the config.json default), --batch-size (defaults to 1), and the --kv-cache-dtype (defaults to auto which means it uses the default data type set in config.json under torch_dtype or dtype, or rather from quantization_config when applicable).
uvx hf-mem --model-id MiniMaxAI/MiniMax-M2 --experimental

References
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file hf_mem-0.4.0.tar.gz.
File metadata
- Download URL: hf_mem-0.4.0.tar.gz
- Upload date:
- Size: 11.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: uv/0.9.27 {"installer":{"name":"uv","version":"0.9.27","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6dc8cdc25bae7f0b93b488cc2a6ebfb2031d14e7a4aef2bfd81f0d1b2a5d4877
|
|
| MD5 |
daca0689b8c223aa8c545568bdbfcb47
|
|
| BLAKE2b-256 |
52fcd75a90f0cc496840ef4ff0af8cc9965dc8e6a6b4ad9776402b99f9c170d8
|
File details
Details for the file hf_mem-0.4.0-py3-none-any.whl.
File metadata
- Download URL: hf_mem-0.4.0-py3-none-any.whl
- Upload date:
- Size: 14.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: uv/0.9.27 {"installer":{"name":"uv","version":"0.9.27","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f9a1acd2c747bc47abd5be397bb27fbaf7a32377cbbfe2027ef92e02152d0d78
|
|
| MD5 |
3776facdc8ce3abdf303047c3aed0013
|
|
| BLAKE2b-256 |
0b4f939e80efaab8f617870e39d912a811bc366df8a7afdd492c4c2b1e1348ff
|







