Fast asymptotic mannwhitney-u test

Project description
Illico
Overview
illico is a python library performing blazing fast asymptotic wilcoxon rank-sum tests (same as scanpy.tl.rank_genes_groups(…, method="wilcoxon")), useful for single-cell RNASeq data analyses and processing. illico's features are:
- :rocket: Blazing fast: On K562 (essential) dataset (~300k cells, 8k genes, 2k perturbations),
illicocomputes DE genes (withreference="non-targeting") in a mere 30 seconds. That's more than 100 times faster than bothpdexorscanpywith the same compute ressources (8 CPUs). - :diamond_shape_with_a_dot_inside: No compromise: on synthetic data,
illico's p-values matchedscipy.stats.mannwhitneyuup to a relative difference of 1.e-12, and an absolute tolerance of 0. - :zap: Thread-first:
illicoeventually parallelizes the processing (if specified by the user) over threads, never processes. This saves you from all the fixed cost of multiprocessing, such as spanning processes, duplicating data across processes, and communication costs. - :beetle: Data format agnostic: whether your data is dense, sparse along rows, or sparse along columns,
illicowill deal with it while never converting the whole data to whichever format is more optimized. - 🪶 Lightweight:
illicowill process the input data in batches, making any memory allocation needed along the way much smaller than if it processed the whole data at once. - 📈 Scalable: Because thread-first and batchable,
illicoscales reasonably with your compute budget. Tests showed that spanning 8 threads brings a 7-fold speedup over spanning 1 single thread. - :floppy_disk: Out-of-core:
illicosupports h5-based, on-disk-backed, dense and CSC datasets natively. - :fireworks: All-purpose:
illicoperforms both one-versus-reference (useful for perturbation analyses) and one-versus-rest (useful for clustering analyses) wilcoxon rank-sum tests, both equally optimized and fast.
Approximate speed benchmarks ran on k562-essential can be found below. All the code used to generate those numbers can be found in tests/test_asymptotic_wilcoxon.py::test_speed_benchmark.
| Test | Format | Illico | Scanpy | pdex |
|---|---|---|---|---|
| OVO (reference="non-targeting") | Dense | ~30s | ~1h | ~4h |
| OVO (reference="non-targeting") | Sparse | ~30s | ~1h30 | ~4h |
| OVR (reference=None) | Dense | ~30s | ~11h | X |
| OVR (reference=None) | Sparse | ~30s | ~10h | X |
:bulb: Note:
- This library only performs wilcoxon rank-sum tests, also known as Mann-Whitney test, also performed by
scanpy.tl.rank_genes_groups(…, method="wilcoxon"). It does not perform wilcoxon signed-sum tests, those are less often used in for single-cell data analyses as it requires samples to be paired. - Exact benchmarks ran on a subset of the whole k562 can be found at the end of this readme.
- OVO refers to one-versus-one: this test computes u-stats and p-values between control cells and perturbed cells. Equivalent to
scanpy'srank_gene_groups(…, reference="non-targeting"). - OVR refers to one-versus-rest: this test computes u-stats and p-values between each group cells, and all other cells, for each group. Equivalent to
scanpy'srank_gene_groups(…, reference="rest").
Installation
illico can be installed via pip, compatible with Python 3.11 and onward:
pip install illico -U
How to use
This library exposes one single function that returns a pd.DataFrame holding p-value, u-statistic and fold-change for each (group, gene). Except the few points below, the function and its arguments should be self-explanatory:
- It is required to indicate if the data you run the tests on underwent log1p transform. This only impacts the fold-change calculation and not the test results (p-values, u-stats). The choice was made to not try to guess this information, as those often lead to error-prone and potentially harmful rules of thumb.
- By default,
illico.asymptotic_wilcoxonwill use what lies inadata.Xto compute DE genes. If you want a specific layer to be used to perform the tests, you must specify it. - By default again,
illico.asymptotic_wilcoxonwill apply continuity correction and tie correction factors. This is controllable with theuse_continuityandtie_correctarguments.
DE genes compared to control cells
If you are working on single cell perturbation data:
from illico import asymptotic_wilcoxon
adata = ad.read_h5ad('dataset.h5ad') # (n_cells, n_genes)
de_genes = asymptotic_wilcoxon(
adata,
# layer="Y", # <-- If you want tests to run not on .X, but a specific layer
group_keys="perturbation",
reference="non-targeting",
is_log1p=[False|True], # <-- Specify if your data underwent log1p or not
)
The resulting dataframe contains n_perturbations * n_genes rows and three columns: (p_value, statistic, fold_change). In this case, the wilcoxon rank-sum test is performed between cells perturbed with perturbation p_i and control cells, for each p_i.
DE genes for clustering analyses
Let's say your .obs contains a clustering variable, assigning a label to each cell.
from illico import asymptotic_wilcoxon
adata = ad.read_h5ad('dataset.h5ad') # (n_cells, n_genes)
adata.obs["cluster"] = ...
de_genes = asymptotic_wilcoxon(adata, group_keys="cluster", reference=None, is_log1p=[False|True])
In this case, the resulting dataframe contains n_perturbations * n_genes rows and the same three columns: (p_value, statistic, fold_change). In this case, the wilcoxon rank-sum test is performed between cells belonging to cluster c_i and all the other cells (one-versus-the-rest), for all c_i.
illico is not faster than scanpy or pdex, is there a bug ?
illico relies on a few optimization tricks to be faster than other existing tools. It is very possible that for some reason, the specific layout of your dataset (very small control population, very low sparsity, very small amount of distinct values) result in those tricks being effect-less, or less effective than observed on the datasets used to develop & benchmark illico. It is also very possible that because of those, other solutions end up faster than illico ! If this is your case, please open a issue describing your situation.
illico's results (p-values or fold-change) do not match pdex or scanpy.
Test results (p-values)
Please open an issue, but before that: make sure that you are running asymptotic wilcoxon rank-sum tests as this is the only test exposed by illico.
pdexrelies onscipy.stats.mannwhitneyuthat runs exact (non asymptotic) when there are 8 values (or less) in both groups combined, and no ties.scanpyoffers the possibility to run non-tie-corrected wilcoxon rank-sum tests (default behavior). If you come from scanpy, make sure arguments match.- Also,
illicouses continuity correction by default which is the best practice (can be disabled).
The test suite implemented in the CI and used to develop illico targets a precision of 1.e-12 compared to scipy, not scanpy. Consequently, there will be slight disagreement between scanpy's p-values and illico's p-values, as scanpy itself disagrees with scipy.
Fold-change
The fold-change computed by illico is the most naive form of the fold-change:
$$\text{fold-change} = \frac{E[X_{\text{perturbed}}]}{E[X_{\text{control}}]}$$
If your data underwent log1p transform, np.expm1 is applied before computing the expectations (means), in which case the fold change expression becomes:
$$\text{fold-change} = \frac{E[e^{X_{\text{perturbed}}} - 1]}{E[e^{X_{\text{control}}} - 1]}$$
I know several definitions exist, and adding more control over this should not be complicated. If this is your case, please open an issue.
What about normalization and log1p
illicodoes not care about your data being normalized or not, it is up to you to apply the preprocessing of your choice before running the tests. It is expected thatillicois slower if ran on total-count normalized data by a factor ~2. This is because if applied on non total-count normalized data, sorting relies on radix sort which is faster than the usual quicksort (that is used if testing total-count normalized data).- In order to avoid any unintended conversion, or relie on failure-prone rules of thumb,
illicorequires the user to indicate if the input data is log1p or not. This is only used to compute appropriate fold-change, and does not impact test (p-value and statistic) results.
What if my adata does not fit in memory ?
Although not initially designed to run out-of-core rank-sum tests, illico supports some disk-backed expression matrices natively. The slowdown occurred by backing the dataset on disk is hard to estimate as it directly depends on your system's IO. Notably:
- h5-dense (np.ndarray) disk-backed dataset are natively supported
- h5-CSC (sparse along the columns) disk-backed datasets are natively supported
- :warning: h5-CSR (sparse along the rows) disk-backed datasets are not supported
If your data is backed through Dask or another backend, please open an issue as dense and CSC use cases should require very little rework to be supported.
Notes:
- Supporting the CSR use case is highly non trivial, and running
adata[:, idxs]on a backed CSR matrix will load (temporarily) the entirety of the indices in RAM, resulting in a memory footprint almost equivalent to loading everything at once, on top of being extremely slow. - Users struggling with out-of-core single cell RNASeq analyses should visit
rapids-singlecell, which explicitely targets this use-case.
How it works
The rank-sum tests performed by illico are classical, asymptotic, rank-sum tests. No approximation nor assumption is done. Illico relies on a few optimization tricks that are non-exhaustively listed below:
- 🧀 Sparse first: if the input data is sparse, that can be a lot less values to sort. Instead of converting it to dense,
illicowill only sort and rank non-zero values, and adjust rank-sums and tie sums later on with missing zeros. - 🗑️ Memory-conscious: ranking and sorting values across groups often requires to slice and convert the data numerous times, especially for CSC or CSR data. Memory allocations are minimized and optimized so as to ensure better scalability and lower overall memory footprint.
- :brain: Sort controls only once: for the one-versus-reference use case,
illicotakes care of not repeatdly sorting the control values. Controls are sorted only once, after what each "perturbation" chunk is sorted, and the two sorted sub-arrays are merged (linear cost). Because there are often much more control cells than perturbed cells, this is a huge economy of processing. - :loop: Vectorize everything: for the one-versus-ref use case,
illicoperforms one single sorting of the whole batch (all groups combined) and sums ranks for each group in a vectorized manner. This allows to sort only once instead of repeatedly performingscipy.stats.mannwhitneyuon all-but-group-g and group-g, for all g - involving one sorting each. - :snake: Generally speaking,
illicorelies heavily onnumba's JIT kernels to ensure GIL-free operations and efficient vectorization.
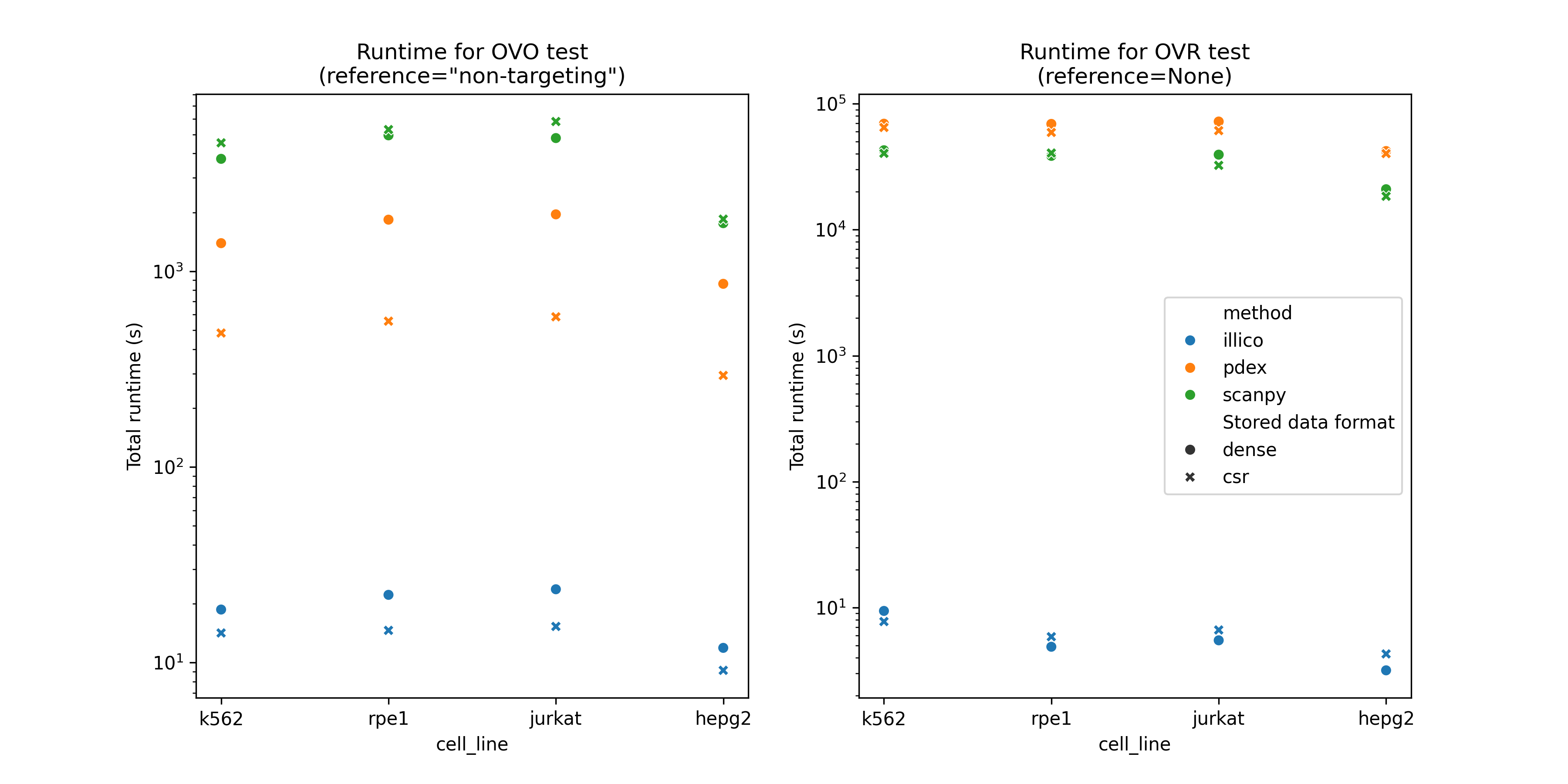
Benchmarks
Benchmarking against other solutions
In order for benchmarks to run in a reasonable amount of time, the timings reported below were obtained by running each solution on a subset of each cell line (20% of the genes). All solutions were find to scale linearly with the number of genes (columns in the adata). Extrapolating (x5) the elapsed times below will approximate runtime of those solutions on the whole datasets. Numbers in parenthesis report the multiplicative factor versus the fastest solution of each benchmark. A "benchmark" is defined by:
- The cell line (K562 essential, RPE1, Hep-G2, Jurkat) used as input.
- The data format (CSR, or dense) used to contain the expression matrix.
- The test performed: OVO (
reference="non-targeting") or OVR (reference=None).
:bulb: Keep in mind that pdex does not implement OVR test.
Scalability
illico scales reasonably well with your compute budget. On the K562-essential dataset spanning 8 threads instead of 1 brings a 7-folds speedup.
---------------------- benchmark 'k562-dense-ovo': 4 tests -----------------------
Name (time in s) Mean
----------------------------------------------------------------------------------
test_speed_benchmark[k562-dense-100%-illico-ovo-nthreads=8] 29.6962 (1.0)
test_speed_benchmark[k562-dense-100%-illico-ovo-nthreads=4] 53.4369 (1.80)
test_speed_benchmark[k562-dense-100%-illico-ovo-nthreads=2] 100.3919 (3.38)
test_speed_benchmark[k562-dense-100%-illico-ovo-nthreads=1] 208.2443 (7.01)
----------------------------------------------------------------------------------
Why illico
The name illico is a wordplay inspired by the R package presto (now the Wilcoxon rank-sum test backend in Seurat). Aside from this naming reference, there is no affiliation or intended equivalence between the two. illico was developed independently, and although the statistical methodology may be similar, it was not designed to reproduce presto’s results.
Contributing
All contributions are welcome through merge requests. Developers are highly encouraged to rely on tox as the testing process is quite cumbersome.
Testing
The reason to be of this package is its speed, hence the need for extensive speed benchmarks in order to compare it exhaustively and accurately against existing solutions. tox is used to manage tests and testing environments.
pip install tox # this can be system-wide, no need to install it within an environment
:bulb: The test suite below can be very long, especially the benchmarks (up to 48 hours). All "bench-" tox commands can be appended with the -quick suffix ensuring they are ran on 1 gene (column) of the benchmark data, just to make sure everything runs correctly. Example:
tox -e bench-all-quick # This will run speed and memory benchmarks for illico, scanpy and pdex
# OR: tox -e bench-illico-quick # This will run speed and memory benchmarks for illico only
# OR :tox -e bench-ref-quick # This will run speed and memory benchmarks for scanpy and pdex only
Appending the -quick suffix will not write any result file or json inside the .benchmarks or .memray folders (that are versioned). Instead, benchmark result files will be written to /tmp.
In this case, make sure to run tox -e memray-stats /tmp
Unit testing
Those tests are simply used to ensure the p-values and fold-change returned by illico are correct, should be quick to run:
tox -e unit-tests
:warning: Those tests do not run -quick as they use synthetic data that results in much shorter runtime.
Speed benchmarks
Speed benchmarks are ran against: pdex and scanpy as references. Those benchmarks take a lot of time (>10 hours on 8 CPUs) so they should not be re-ran for every new PR or release. However, if needed:
tox -e speed-bench-ref # Run speed benchmarks for scanpy and pdex, should not be re-ran, ideally.
Before issuing a new PR, in order to see if the updated code does not decrease speed performance, make sure to run:
tox -e speed-bench-illico #-quick
:bulb: Because benchmark performance depends on the testing environment (type of machine or OS), it is recommended to run this benchmark from main on your machine as well. This will give you a clear comparison point apple-to-apple.
Once the benchmarks have ran, you can cat the benchmark results in terminal with:
tox -e speed-bench-compare
Memory benchmark
Similar remarks as for the speed benchmarks:
tox -e memory-bench-ref # Should not be re-ran, ideally
tox -e memory-bench-illico # Should be re-ran before every new PR
tox -e memray-stats
Other tools available
scanpyalso implements OVO and OVR asymptotic wilcoxon rank-sum tests.pdexonly implements OVO wilcoxon rank-sum tests.- As of December 2025,
rapids-singlecellhas a pending PR adding arank_genes_groupsfeature. I could not benchmark this solution as I had no GPU available, but it is expected that it runs at least as fast asillico, because GPU-based.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file illico-0.2.0.tar.gz.
File metadata
- Download URL: illico-0.2.0.tar.gz
- Upload date:
- Size: 35.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.2.1 CPython/3.11.14 Linux/6.11.0-1018-azure
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f2c43076782451aebdf2e373ccfe9a93c9f90881bbfe090169cd39831a9a720f
|
|
| MD5 |
6fc04c1978e65f75b60cdb7f749181d7
|
|
| BLAKE2b-256 |
fa00661f5277c0ec1eb4b9815ea72f7c118c90e9d2987793ffd82a55686821bc
|
File details
Details for the file illico-0.2.0-py3-none-any.whl.
File metadata
- Download URL: illico-0.2.0-py3-none-any.whl
- Upload date:
- Size: 38.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.2.1 CPython/3.11.14 Linux/6.11.0-1018-azure
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
97b22e72ac82c1238c9529a8a3bb6664bc10099ec3a61f7f75d79bd77d1434c4
|
|
| MD5 |
b5450fd32e1781949d31e13d0f67734c
|
|
| BLAKE2b-256 |
7f4525e23d37b4ec1030493034bdd5e31578a48e10accb773b3dedf56b391f45
|







