Inference-time model selection and ensembling for LLM outputs

Project description

What is InferScale
InferScale is a Python package that provides a unified and practical framework for applying inference-time scaling to large language models (LLMs).
At its core, InferScale moves beyond single-shot generation. It produces multiple candidate responses—either complete or partial—from one or more LLMs, and then intelligently selects or aggregates them to yield a higher-quality final output.
This strategy allows developers to enhance performance across a variety of tasks—including text summarization, question answering, information extraction, and paraphrasing—without the need for model fine-tuning or retraining.
By optimizing at inference time, InferScale offers a scalable and cost-efficient alternative to traditional training-heavy approaches. We view this paradigm as a highly practical and impactful way to improve LLM applications in real-world settings. This approach leverages model diversity and response sampling to increase the probability of obtaining a higher-quality output.
Architecture
The current architecture of InferScale is shown below:
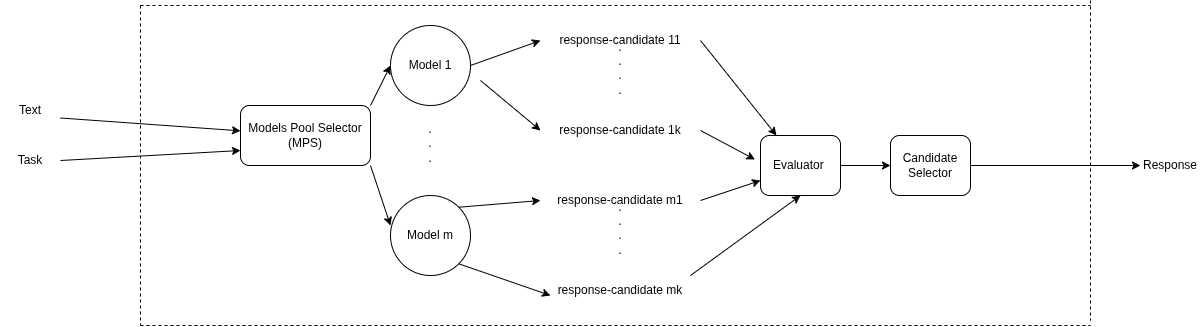
Pipeline overview:
- Multiple LLM models generate candidate responses
- Each model can generate N samples
- All responses are collected
- A scoring mechanism selects the best candidate
Proces overview
-
Model Loading : The library loads one model from a set predefind models for the given task (Text Summarization, Question Answering, Information Extraction, etc...). Currently we support generating different samples of responses from one model , we plan at some point to add a model selector layer, generate and blend reponses from different models.
-
Generate Multiple Responses : Each model generates N candidate responses for the same input. The library is designed to get a batch of queries / input pieces of text.
-
Compute Semantic Similarity :All responses are evaluated using an evaluation metric that tries to mimic the human evaluation as much as possible
-
Generate the final response :The response with the highest score is selected as the final output. (In the future we will implement appraoches the blend top K responses from one or differnet models stay tuned!!)
Details
Currently we support the following Tasks to be done using InferScale
- Text Summarization
We plan to support the following tasks in the following releases
- Question-Answering
- Information Extraction
- Paraphrasing
▶ Text Summarization + Inference-Scaling
The models we support currently (from the pool of models in Hugging Face) are facebook/bart-large-cnn, sshleifer/distilbart-cnn-12-6. Why ? If you see the list of Hugging-Face summarization models, you will find that these are the most liked ones. We know this might be a naive approach for selecting the models to support, in the future we plan a more rigorous benchmarking.
As InferScale is designed to be "scalable", we focus , in the beginning, on the reference-free metrics for Automateed-Summarization Evaluation . You can check this simple article for more information. We support two metrics :
-
Cosine Similarity : We simple embed the query and result summarization using
all-MiniLM-L6-v2then calculateCos(embedding(query),embedding(response)) -
ROUGE : This is one of the most classical metrics in text-summarization tasks . We apply ROUGE in and unsupervised (reference-free) fashion : we calculate ROUGE based on the input query as a reference text against the response as the predicted text. We use the
rouge-scorelibrary in our current implementation. In the future, we will create our own to control the calculation poroces.
Installation
pip install inferscale datasets sentence-transformers rich
Example
import json
from inferscale.best_of_n import BestOfNSampler
from datasets import load_dataset
from rich import print_json
if __name__ == "__main__":
# Candidate models
model_names = [
"Sachin21112004/distilbart-news-summarizer",
"google/pegasus-xsum"
]
# Initialize Best-of-N sampler
bon = BestOfNSampler(models_names=model_names)
# Load dataset
dataset = load_dataset("cnn_dailymail", "3.0.0")
# Example queries
queries = [
dataset["train"][0]["article"],
dataset["train"][1]["article"],
dataset["train"][2]["article"]
]
# Generate responses
results = bon.generate(queries=queries, n=3)
# Pretty print results
print_json(json.dumps(results, indent=4))
Change Log
If you are intrested in the details of development and changes in each version, check the CHANGE LOG
Main Resources


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file inferscale-0.1.3.tar.gz.
File metadata
- Download URL: inferscale-0.1.3.tar.gz
- Upload date:
- Size: 10.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
644fc83f8f5842dd5338692be147e3017cde97809e266eafab9d9202d71ca12b
|
|
| MD5 |
17a90f8ac74882a3282afe9d248d0391
|
|
| BLAKE2b-256 |
2cd2d9342f5d8743a1d653030c4cbc5ccaba6bf58bb86f28477e4b93842b0cc1
|
File details
Details for the file inferscale-0.1.3-py3-none-any.whl.
File metadata
- Download URL: inferscale-0.1.3-py3-none-any.whl
- Upload date:
- Size: 10.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9c3055dc7f34a8db4ab5be8556a1d8fc76e6b8177c1e55391bb6edad46b80754
|
|
| MD5 |
c5e3ab467f87d4575bf8ce0850d65bd9
|
|
| BLAKE2b-256 |
2f18c0b5f54cd59b4f2ff9d1c7714a68d49120c4090dcb89e40043faa679f6c7
|







