Inference-time model selection and ensembling for LLM outputs

Project description

The Problem
Improving the quality of responses generated by Large Language Models (LLMs) for tasks such as question answering, summarization, and content generation remains a key challenge for AI developers.
Common approaches include:
- Fine-tuning models on task-specific datasets
- Prompt engineering and optimization
- Retrieval-Augmented Generation (RAG) pipelines
However, these approaches often require:
- Large training datasets
- Expensive computing resources
- Dependence on large proprietary models or third-party APIs
An alternative and more budget-efficient approach is inference-time scaling.
Instead of modifying the model itself, inference-time scaling improves output quality by:
- Generating multiple candidate responses
- Evaluating them using a scoring function
- Selecting the best response automatically
This approach allows developers to improve response quality without expensive training or larger models, making it particularly attractive for cost-constrained or production environments.
InferScale
InferScale is a lightweight Python library that improves LLM output quality using inference-time scaling techniques such as Best-of-N sampling across multiple models.
Instead of relying on expensive fine-tuning or larger models, InferScale generates multiple candidate responses and automatically selects the best one using lightweight scoring methods.
The goal is to help AI developers focus on building AI applications, while InferScale handles candidate generation and response selection.
Architecture
The current architecture of InferScale is shown below:
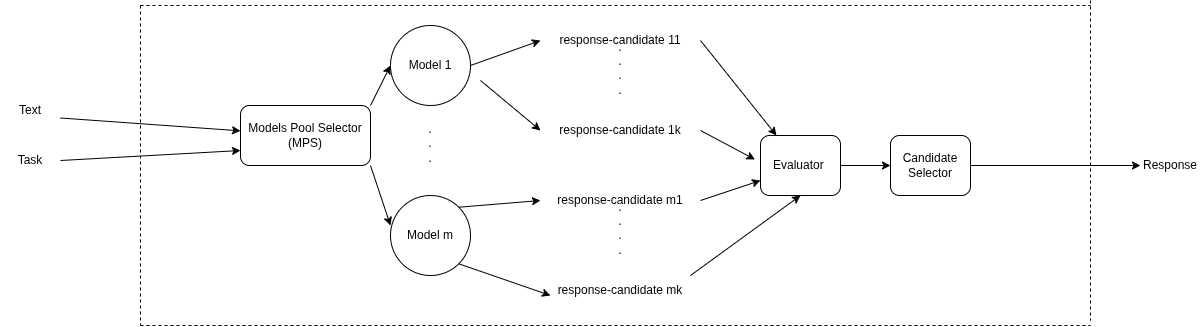
Pipeline overview:
- Multiple LLM models generate candidate responses
- Each model can generate N samples
- All responses are collected
- A scoring mechanism selects the best candidate
How InferScale Works
InferScale implements a simple inference-time scaling strategy to improve LLM response quality without additional training or expensive models.
The core idea is simple:
Generate multiple candidate responses from multiple models and automatically select the best one.
This approach leverages model diversity and response sampling to increase the probability of obtaining a higher-quality output.
Step-by-Step Process
- Load the model
The library loads one of the models from Hugging-Face
- Generate Multiple Responses
Each model generates N candidate responses for the same input.
Example:
Input Article
- Response A1
- Response A2
- Response A3
This creates a pool of candidate outputs.
- Compute Semantic Similarity
All responses are embedded using a sentence embedding model.
InferScale then computes cosine similarity scores to estimate the semantic quality of each response.
- Select the Best Response
The response with the highest similarity score is selected as the final output.
Candidate Responses
↓
Embedding + Cosine Similarity
↓
Best Scoring Response
↓
Final Output
Installation
pip install inferscale datasets sentence-transformers rich
Example
import json
from inferscale.best_of_n import BestOfNSampler
from datasets import load_dataset
from rich import print_json
if __name__ == "__main__":
# Candidate models
model_names = [
"Sachin21112004/distilbart-news-summarizer",
"google/pegasus-xsum"
]
# Initialize Best-of-N sampler
bon = BestOfNSampler(models_names=model_names)
# Load dataset
dataset = load_dataset("cnn_dailymail", "3.0.0")
# Example queries
queries = [
dataset["train"][0]["article"],
dataset["train"][1]["article"],
dataset["train"][2]["article"]
]
# Generate responses
results = bon.generate(queries=queries, n=3)
# Pretty print results
print_json(json.dumps(results, indent=4))
Change Log
If you are intrested in the details of development and changes in each version, check the CHANGE LOG
Main Resources


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file inferscale-0.1.2.tar.gz.
File metadata
- Download URL: inferscale-0.1.2.tar.gz
- Upload date:
- Size: 9.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8813a7b14e681d9d820bdb88cc100d7a60f0ddfdd3d1dac5777a82369ed02467
|
|
| MD5 |
f311b11a2c0cdba87a1f6b11464fea0a
|
|
| BLAKE2b-256 |
c0cd00ef1aa9e861d7d29fde2b3dd602df1d33ec5efaff351bc2a2fdabb8532a
|
File details
Details for the file inferscale-0.1.2-py3-none-any.whl.
File metadata
- Download URL: inferscale-0.1.2-py3-none-any.whl
- Upload date:
- Size: 9.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3fb9712b53e97c67abb3a140ecaa6d288b9dcf4fcff080bc00826582580a56c2
|
|
| MD5 |
7c31fd096b50678b436e957672c08ada
|
|
| BLAKE2b-256 |
177dcdeeb4ca7d88b96b466f6e38825e7b7d571c1930ad8ffbc10729dc9b7813
|







