MLflow integration for Inspect AI: experiment tracking, execution tracing, evaluation comparison, and Scout analysis
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
inspect-mlflow









MLflow integration for Inspect AI. Provides experiment tracking, execution tracing, evaluation comparison, and artifact logging for Inspect AI evaluations.
Install
pip install inspect-mlflow
Quick Start
Hooks auto-register via entry points when the package is installed. No code changes needed.
# Start MLflow server
mlflow server --port 5000
# Set env vars
export MLFLOW_TRACKING_URI="http://localhost:5000"
export MLFLOW_INSPECT_TRACING="true"
# Run evals as usual. Both hooks activate automatically.
inspect eval my_task.py --model openai/gpt-4o
Then open http://localhost:5000 to see runs and traces.
What it does
This package provides two hooks that run automatically during Inspect AI evaluations. Both hooks use the MlflowClient API for full isolation from user MLflow state (no global mlflow.start_run calls). Thread-safe for concurrent sample processing.
Tracking Hook
Activated when MLFLOW_TRACKING_URI is set. Creates hierarchical MLflow runs with full evaluation telemetry.
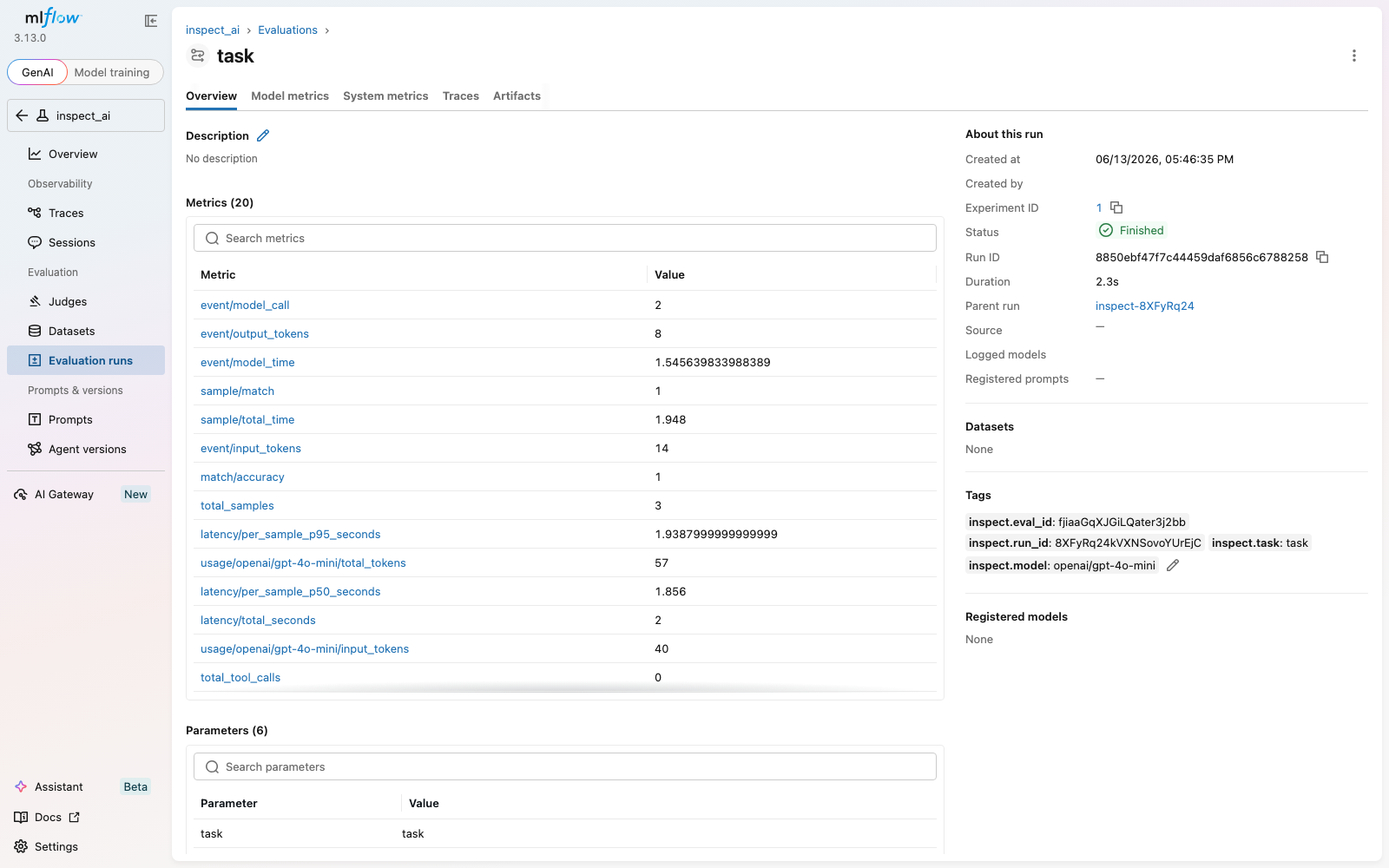
What gets logged:
- Parent run per eval invocation with nested child runs per task
- Task configuration as parameters (model, dataset, solver, temperature, top_p, max_tokens)
- Per-sample scores as step metrics (accuracy, timing per sample)
- Aggregate metrics (total_samples, completed_samples, match/accuracy, match/stderr)
- Model token usage (input/output/total tokens per model)
- Cost per model (
usage/<model>/total_cost_usd) and aggregatecost/total_usdwhen the inspect_ai provider surfaces cost (new in v0.8.0) - Latency aggregates (
latency/per_sample_mean_seconds,latency/per_sample_p50_seconds,latency/per_sample_p95_seconds,latency/total_seconds) for SLA tracking (new in v0.8.0) - Real-time event counting (total_model_calls, total_tool_calls)
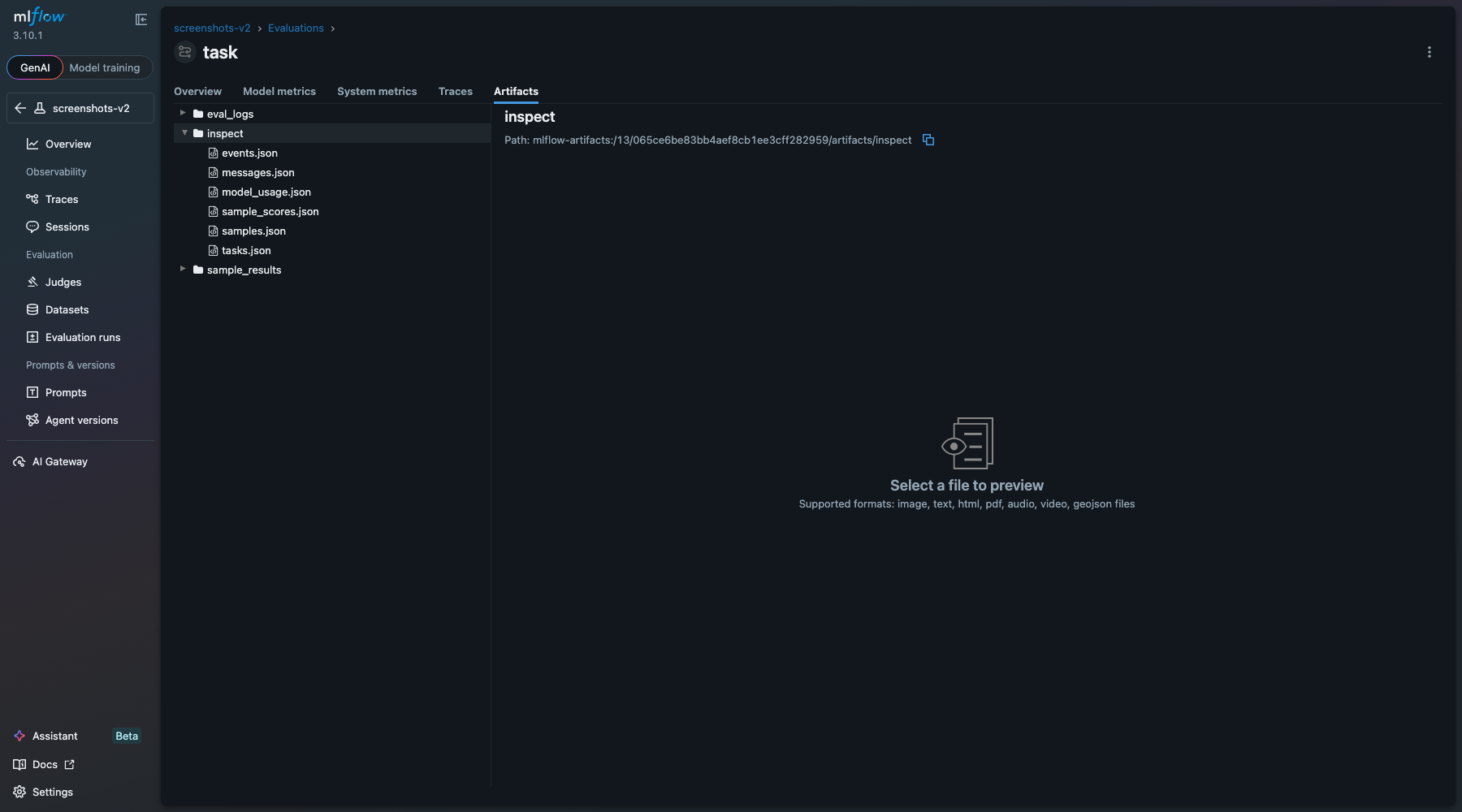
- Eval artifacts: per-sample results JSON + full eval log JSON
- Additional rich table artifacts for analysis (
inspect/*.json)
Task run with metrics including the v0.8.0 latency aggregates and per-model token usage:
Artifact tables (inspect/) with structured eval data:
Tracing Hook
Activated when MLFLOW_INSPECT_TRACING=true is also set. Maps eval execution to MLflow trace spans, giving you a visual debugging view of every model call, tool invocation, and scoring step. Eval scores are logged as MLflow trace assessments via mlflow.log_feedback(), visible in the Traces UI assessment column.
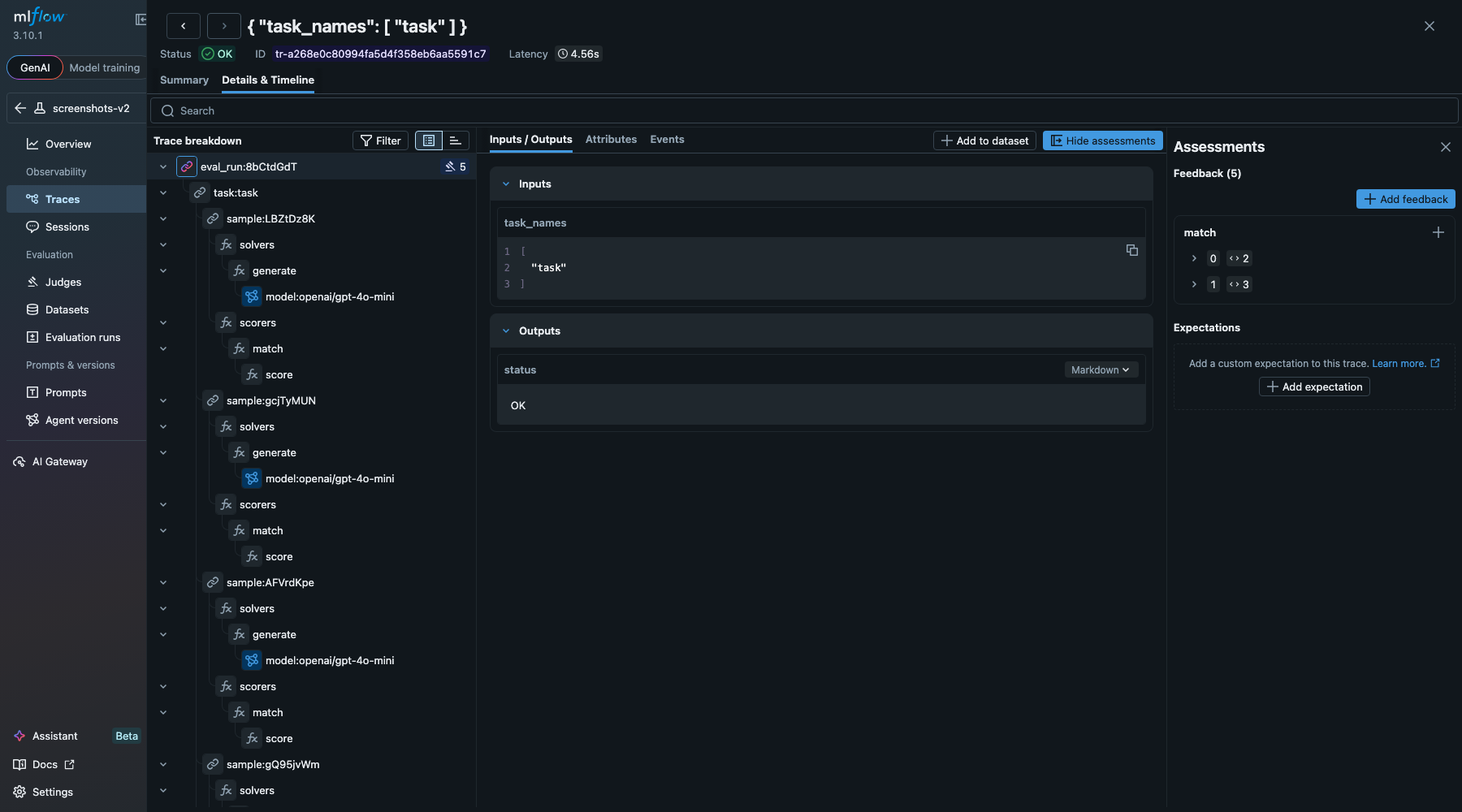
Span hierarchy:
eval_run:98h4b4KN (CHAIN)
task:task (CHAIN)
sample:keAdeL1U (CHAIN)
solvers (from SpanBeginEvent)
use_tools (solver span)
model:openai/gpt-4o-mini (LLM) - 5,167 tokens
tool:calculator (TOOL) - args: {"expression": "47 * 89"}, result: "4183"
model:openai/gpt-4o-mini (LLM) - 5,263 tokens
generate (solver span)
model:openai/gpt-4o-mini (LLM) - 182 tokens
scorers (from SpanBeginEvent)
match (scorer span)
score (EVALUATOR) - value: C
sample:HWl2wp2B (CHAIN)
...
Each span type captures different data:
| Span Type | Data Captured |
|---|---|
| CHAIN | eval run, task, and sample lifecycle with scores and timing |
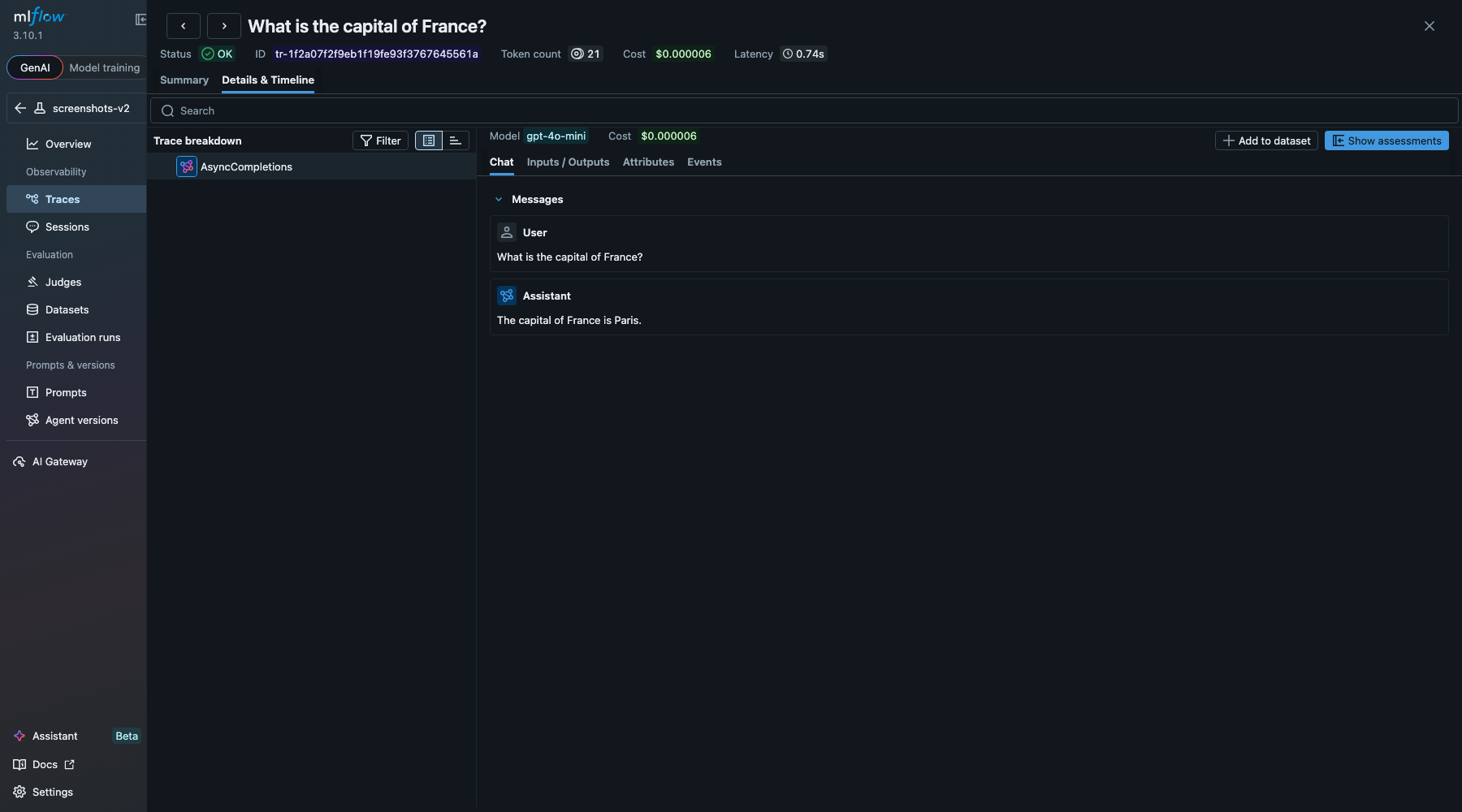
| LLM | model name, input/output token counts, temperature, cache status, response text |
| TOOL | function name, arguments, result, working time, errors |
| EVALUATOR | score value, explanation, target |
Full span tree with solver/scorer hierarchy and assessments panel:
LLM span detail with model name, token counts, and response:
Autolog
Autolog enables MLflow provider integrations at run start.
Supported providers are: openai, anthropic, langchain, litellm,
mistral, groq, cohere, gemini, bedrock.
Each provider is enabled only when both the MLflow flavor module and provider SDK are installed.
Artifact Tables
When artifact logging is enabled (INSPECT_MLFLOW_LOG_ARTIFACTS=true or
MLFLOW_INSPECT_LOG_ARTIFACTS=true), the tracking hook logs the following artifacts:
inspect/tasks.jsoninspect/samples.jsoninspect/messages.jsoninspect/sample_scores.jsoninspect/events.jsoninspect/model_usage.jsonsample_results/*.jsoneval_logs/*.json
Evaluation Comparison
Compare results from two evaluation runs to detect score regressions with statistical significance testing.
from inspect_mlflow.comparison import compare_evals
result = compare_evals("logs/baseline.eval", "logs/candidate.eval")
print(result.summary())
# Per-sample regressions
for r in result.regressions:
print(f"Sample {r.id}: {r.baseline_score} -> {r.candidate_score}")
Output:
Baseline: openai/gpt-4 (math_task)
Candidate: openai/gpt-4o-mini (math_task)
Samples: 5 aligned, 0 missing, 0 new
Metric Baseline Candidate Delta Sig.
-------------------------------------------------------------------
match/accuracy 0.6000 0.5000 -0.1000 (-16.7%) p=0.421
Effect size (match/accuracy): Cohen's d = -0.32 (small effect)
Regressions: 1, Improvements: 0, Unchanged: 4
Candidate won on 0 of 5 samples (0.0%)
Cost: $0.1234 -> $0.0210 (-$0.1024 (-83.0%))
Latency p95: 4.521s -> 1.937s (-2.584s (-57.2%))
The summary answers the "cheaper but how much worse?" question in one screen. Use this when picking between a stronger model and a cheaper one.
The comparison module aligns samples by (id, epoch), automatically selects the right significance test (McNemar's for binary scores, bootstrap CI for continuous), and computes Cohen's d effect size. No scipy required.
Features:
- Sample alignment with string/int ID normalization and multi-epoch support
- Regression threshold to filter noise (
regression_threshold=0.05) - Sample filtering (
sample_filter=lambda s: s.id in subset) - Win rate tracking across aligned samples
- Cost and latency deltas when the underlying logs carry cost or per-sample timing data (new in v0.8.0)
- Works with file paths or
EvalLogobjects directly
Configuration
Configuration is loaded from environment variables. When pydantic-settings is installed (pip install inspect-mlflow[config]), settings are typed and validated with the INSPECT_MLFLOW_ prefix. Without it, standard os.getenv() is used.
| Env var | Required | Default | Description |
|---|---|---|---|
MLFLOW_TRACKING_URI |
Yes | - | MLflow server URL |
MLFLOW_EXPERIMENT_NAME |
No | inspect_ai |
Experiment name |
MLFLOW_INSPECT_TRACING |
No | false |
Enable execution tracing |
MLFLOW_INSPECT_LOG_ARTIFACTS |
No | true |
Log eval artifacts |
INSPECT_MLFLOW_LOG_ARTIFACTS |
No | true |
Same as above (new prefix, takes priority) |
INSPECT_MLFLOW_AUTOLOG_ENABLED |
No | true |
Enable MLflow provider autolog integrations |
INSPECT_MLFLOW_AUTOLOG_MODELS |
No | openai,anthropic,langchain,litellm |
CSV or JSON array of providers to autolog |
Examples
Basic eval (tracking + tracing)
from inspect_ai import Task, eval
from inspect_ai.dataset import Sample
from inspect_ai.scorer import match
from inspect_ai.solver import generate
# No special imports needed. Hooks auto-register on install.
task = Task(
dataset=[
Sample(input="What is 2 + 2?", target="4"),
Sample(input="What is 3 * 5?", target="15"),
Sample(input="What is 10 - 7?", target="3"),
],
solver=generate(),
scorer=match(),
)
logs = eval(task, model="openai/gpt-4o-mini")
# MLflow now has: runs with metrics + traces with span tree
Eval with tool calls
from inspect_ai import Task, eval
from inspect_ai.dataset import Sample
from inspect_ai.scorer import match
from inspect_ai.solver import generate, use_tools
from inspect_ai.tool import tool
@tool
def calculator():
"""Perform arithmetic calculations."""
async def run(expression: str) -> str:
"""Evaluate a math expression.
Args:
expression: A math expression to evaluate, e.g. "47 * 89"
"""
allowed = {"__builtins__": {}}
return str(eval(expression, allowed))
return run
task = Task(
dataset=[
Sample(
input="Use the calculator to compute 47 * 89.",
target="4183",
),
Sample(
input="Use the calculator to compute 1024 / 16.",
target="64",
),
],
solver=[use_tools([calculator()]), generate()],
scorer=match(),
)
logs = eval(task, model="openai/gpt-4o-mini")
# Traces now include TOOL spans for each calculator() call
# with function name, arguments, and result
Development
git clone https://github.com/debu-sinha/inspect-mlflow.git
cd inspect-mlflow
uv sync --group dev
uv run pre-commit install
uv run pytest tests/ -v
See CONTRIBUTING.md for integration testing and PR guidelines.
Related
- Documentation - Full API reference and usage guide
- Inspect AI - AI evaluation framework by UK AI Security Institute
- MLflow - ML experiment tracking and model management
- Inspect AI hooks docs - How hooks work
- Issue #3547 - Original proposal
- Vector Institute inspect-mlflow - Related extension whose features are being consolidated here
Contributors
- Debu Sinha - Creator and maintainer
- Vector Institute / National Research Council of Canada (NRC) - Autolog provider support and structured Inspect artifact table logging, contributed on behalf of the Canadian AI Safety Institute (CAISI). Consolidated from VectorInstitute/inspect-mlflow.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file inspect_mlflow-0.8.0.tar.gz.
File metadata
- Download URL: inspect_mlflow-0.8.0.tar.gz
- Upload date:
- Size: 2.5 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fbb806d478ee08fba4b979951af72f2f840bee25890e48e9553662d20fdae293
|
|
| MD5 |
20f0b54a770d0e9c6f7c60f4c9b198de
|
|
| BLAKE2b-256 |
3609b6ead8c7a05e8fffccd4217122870c4ee24bf813284a9868d98f670f6016
|
Provenance
The following attestation bundles were made for inspect_mlflow-0.8.0.tar.gz:
Publisher:
release.yml on debu-sinha/inspect-mlflow
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
inspect_mlflow-0.8.0.tar.gz -
Subject digest:
fbb806d478ee08fba4b979951af72f2f840bee25890e48e9553662d20fdae293 - Sigstore transparency entry: 1810380014
- Sigstore integration time:
-
Permalink:
debu-sinha/inspect-mlflow@a3575fda50e580a3c09f830d310c556dcae7a61b -
Branch / Tag:
refs/tags/v0.8.0 - Owner: https://github.com/debu-sinha
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@a3575fda50e580a3c09f830d310c556dcae7a61b -
Trigger Event:
push
-
Statement type:
File details
Details for the file inspect_mlflow-0.8.0-py3-none-any.whl.
File metadata
- Download URL: inspect_mlflow-0.8.0-py3-none-any.whl
- Upload date:
- Size: 37.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
df718e4ee275d518e339d483a849a1731ddef25c356886936600c65a7690d987
|
|
| MD5 |
d823b0d3e91f366a2049c7d4329bca7f
|
|
| BLAKE2b-256 |
84b9acd5eb73af1dc03013560f92109a414d3d4a63e3153c8c25c2775d53a33e
|
Provenance
The following attestation bundles were made for inspect_mlflow-0.8.0-py3-none-any.whl:
Publisher:
release.yml on debu-sinha/inspect-mlflow
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
inspect_mlflow-0.8.0-py3-none-any.whl -
Subject digest:
df718e4ee275d518e339d483a849a1731ddef25c356886936600c65a7690d987 - Sigstore transparency entry: 1810380017
- Sigstore integration time:
-
Permalink:
debu-sinha/inspect-mlflow@a3575fda50e580a3c09f830d310c556dcae7a61b -
Branch / Tag:
refs/tags/v0.8.0 - Owner: https://github.com/debu-sinha
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@a3575fda50e580a3c09f830d310c556dcae7a61b -
Trigger Event:
push
-
Statement type:







