Token-efficient MCP server for source code exploration via tree-sitter AST parsing

Project description
Quickstart - https://github.com/jgravelle/jcodemunch-mcp/blob/main/QUICKSTART.md
FREE FOR PERSONAL USE
Use it to make money, and Uncle J. gets a taste. Fair enough? details
Cut code-reading token usage by 95% or more
Most AI agents explore repositories the expensive way:
open entire files → skim thousands of irrelevant lines → repeat.
That is not “a little inefficient.” That is a token incinerator.
jCodeMunch indexes a codebase once and lets agents retrieve only the exact code they need: functions, classes, methods, constants, outlines, and tightly scoped context bundles, with byte-level precision.
In retrieval-heavy workflows, that routinely cuts code-reading token usage by 95%+ because the agent stops brute-reading giant files just to find one useful implementation.
| Task | Traditional approach | With jCodeMunch |
|---|---|---|
| Find a function | Open and scan large files | Search symbol → fetch exact implementation |
| Understand a module | Read broad file regions | Pull only relevant symbols and imports |
| Explore repo structure | Traverse file after file | Query outlines, trees, and targeted bundles |
Index once. Query cheaply. Keep moving. Precision context beats brute-force context.
jCodeMunch MCP
Structured code retrieval for serious AI agents







Commercial licenses
jCodeMunch-MCP is free for non-commercial use.
Commercial use requires a paid license.
jCodeMunch-only licenses
- Builder — $79 — 1 developer
- Studio — $349 — up to 5 developers
- Platform — $1,999 — org-wide internal deployment
Want both code and docs retrieval?
Stop paying your model to read the whole damn file.
jCodeMunch turns repo exploration into structured retrieval.
Instead of forcing an agent to open giant files, wade through imports, boilerplate, comments, helpers, and unrelated code, jCodeMunch lets it navigate by what the code is and retrieve only what matters.
That means:
- 95%+ lower code-reading token usage in many retrieval-heavy workflows
- less irrelevant context polluting the prompt
- faster repo exploration
- more accurate code lookup
- less repeated file-scanning nonsense
It indexes your codebase once using tree-sitter, stores structured symbol metadata plus byte offsets into the original source, and retrieves exact implementations on demand instead of re-reading entire files over and over.
Recent releases have also made that retrieval workflow sharper and more useful in real engineering work, with BM25-based symbol search, context bundles, compact search modes, query suggestions for unfamiliar repos, dependency graphs, class hierarchy traversal, blast-radius analysis, multi-symbol bundles, live watch-based reindexing, automatic Claude Code worktree discovery (watch-claude), and benchmark reproducibility improvements.
Real-world results
Independent 50-iteration A/B test on a real Vue 3 + Firebase production codebase — JCodeMunch vs native tools (Grep/Glob/Read), Claude Sonnet 4.6, fresh session per iteration:
| Metric | Native | JCodeMunch |
|---|---|---|
| Success rate | 72% | 80% |
| Timeout rate | 40% | 32% |
| Mean cost/iteration | $0.783 | $0.738 |
| Mean cache creation | 104,135 | 93,178 (−10.5%) |
Tool-layer savings isolated from fixed overhead: 15–25%. One finding category appeared exclusively in the JCodeMunch variant: orphaned file detection via find_importers — a structural query native tools cannot answer without scripting.
Full report: benchmarks/ab-test-naming-audit-2026-03-18.md
Why agents need this
Most agents still inspect codebases like tourists trapped in an airport gift shop:
- open entire files to find one function
- re-read the same code repeatedly
- consume imports, boilerplate, and unrelated helpers
- burn context window on material they never needed in the first place
jCodeMunch fixes that by giving them a structured way to:
- search symbols by name, kind, or language
- inspect file and repo outlines before pulling source
- retrieve exact symbol implementations only
- grab a context bundle when surrounding imports matter
- fall back to text search when structure alone is not enough
Agents do not need bigger and bigger context windows.
They need better aim.
What you get
Symbol-level retrieval
Find and fetch functions, classes, methods, constants, and more without opening entire files.
Faster repo understanding
Inspect repository structure and file outlines before asking for source.
Lower token spend
Send the model the code it needs, not 1,500 lines of collateral damage.
Structural queries native tools can't answer
find_importers tells you what imports a file. get_blast_radius tells you what breaks if you change a symbol. get_class_hierarchy traverses inheritance chains. These are not "faster grep" — they are questions grep cannot answer at all.
Better engineering workflows
Useful for onboarding, debugging, refactoring, impact analysis, and exploring unfamiliar repos without brute-force file reading.
Local-first speed
Indexes are stored locally for fast repeated access.
How it works
jCodeMunch indexes local folders or GitHub repos, parses source with tree-sitter, extracts symbols, and stores structured metadata alongside raw file content in a local index. Each symbol includes enough information to be found cheaply and retrieved precisely later.
That includes metadata like:
- signature
- kind
- qualified name
- one-line summary
- byte offsets into the original file
So when the agent wants a symbol, jCodeMunch can fetch the exact source directly instead of loading and rescanning the full file.
Start fast
1. Install it
pip install jcodemunch-mcp
2. Add it to your MCP client
If you’re using Claude Code:
claude mcp add jcodemunch uvx jcodemunch-mcp
3. Tell your agent to actually use it
This matters more than people think.
Installing jCodeMunch makes the tools available. It does not guarantee the agent will stop its bad habit of brute-reading files unless you instruct it to prefer symbol search, outlines, and targeted retrieval. The changelog specifically calls out improved onboarding around this because it is a real source of confusion for first-time users.
A simple instruction like this helps:
Use jcodemunch-mcp for code lookup whenever available. Prefer symbol search, outlines, and targeted retrieval over reading full files.
Best for
- large repositories
- unfamiliar codebases
- agent-driven code exploration
- refactoring and impact analysis
- teams trying to cut AI token costs without making agents dumber
- developers who are tired of paying premium rates for glorified file scrolling
New here?
Start with QUICKSTART.md for the fastest setup path.
Then index a repo, ask your agent what it has indexed, and have it retrieve code by symbol instead of reading entire files. That is where the savings start.
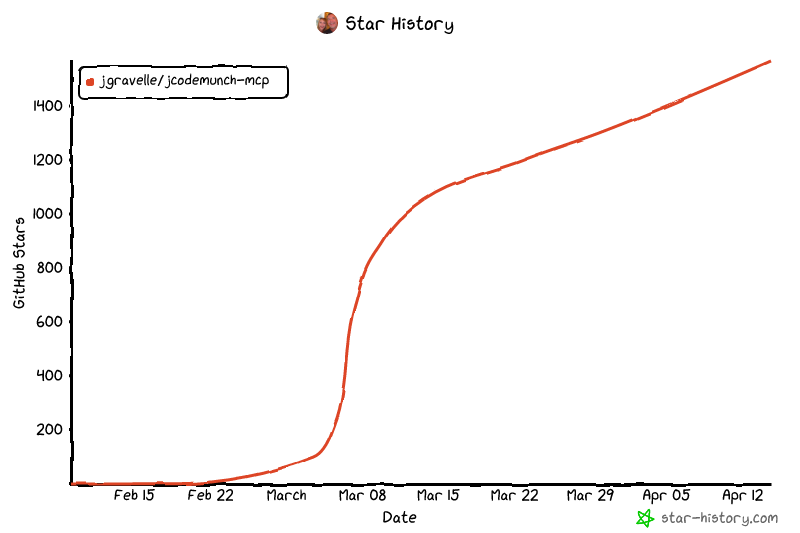
Star History
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file jcodemunch_mcp-1.8.3.tar.gz.
File metadata
- Download URL: jcodemunch_mcp-1.8.3.tar.gz
- Upload date:
- Size: 595.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
de3d7c034e596e789ff22aa0abe30eaf992366e9d13c01f7740ed8f4e5182f8a
|
|
| MD5 |
e10b9de960428da6a95c78d6f1fa659a
|
|
| BLAKE2b-256 |
c4314b2476eed7450c7e652c713359fd3526788f0e1f56c704ccac02d22a585d
|
File details
Details for the file jcodemunch_mcp-1.8.3-py3-none-any.whl.
File metadata
- Download URL: jcodemunch_mcp-1.8.3-py3-none-any.whl
- Upload date:
- Size: 173.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cca2991b36b690337d44cba472f476fbb64c4770939f5bd044a2b81e588a23d2
|
|
| MD5 |
e5c88ee00cc2f8ddb2c3e0dfb3384e6e
|
|
| BLAKE2b-256 |
67ff53327fe0d81f458dacf1b6e3fe75ec315c4bfe2824aad0377bf8ee339c84
|







