Jupyter notebooks as Markdown documents, Julia, Python or R scripts

Project description
Jupyter notebooks as Markdown documents, Julia, Python or R scripts







You've always wanted to
- edit Jupyter notebooks as e.g. plain Python scripts in your favorite editor?
- do version control of Jupyter notebooks with clear and meaningful diffs?
- collaborate on Jupyter notebooks using standard (text oriented) merge tools?
Jupytext can convert notebooks to and from
- Markdown and R Markdown documents (extensions
.mdand.Rmd) - Julia, Python, R, Scheme and C++ scripts (extensions
.jl,.py,.R, etc).
Jupytext is available from within Jupyter. You can work as usual on your notebook in Jupyter, and save and read it in the formats you choose. The text representations can be edited outside of Jupyter (see our demo below). When the notebook is refreshed in Jupyter, input cells are loaded from the script or Markdown document. Kernel variables are preserved. Outputs are not stored in such text documents, and are therefore lost when the notebook is refreshed. To avoid this, we recommend to pair the text notebook with a traditional .ipynb notebook (both files are saved and loaded together).
| Format | Extension | Text editor friendly | IDE friendly | Git friendly | Preserve outputs |
|---|---|---|---|---|---|
| Jupyter notebook | .ipynb |
✔ | |||
| Markdown or R Markdown | .md/.Rmd |
✔ | ✔ | ||
| Julia, Python or R script | .jl/.py/.R/... |
✔ | ✔ | ✔ | |
| Paired notebook | (.jl/.py/.R/.../.md/.Rmd) + .ipynb |
✔ | (✔) | ✔ | ✔ |
Note that Jupytext implements a few different formats for notebooks as scripts:
- the
lightformat allows to open arbitrary scripts as notebooks. Reversely, use it to save notebooks as scripts with very few cell markers. - the
percentformat with explicit# %%cells is compatible with various Python editors. - the
sphinxformat produces Sphinx gallery scripts (Python only). - and the
spinformat is compatible with Knitr's spin function (R only).
Example usage
Writing notebooks as plain text
You like to work with scripts? The good news is that plain scripts, which you can draft and test in your favorite IDE, open transparently as notebooks in Jupyter when using Jupytext. Run the notebook in Jupyter to generate the outputs, associate an .ipynb representation, save and share your research as either a plain script or as a traditional Jupyter notebook with outputs.
Collaborating on Jupyter Notebooks
With Jupytext, collaborating on Jupyter notebooks with Git becomes as easy as collaborating on text files.
The setup is straightforward:
- Open your favorite notebook in Jupyter notebook
- Associate a
.pyrepresentation (for instance) to that notebook - Save the notebook, and put the Python script under Git control. Sharing the
.ipynbfile is possible, but not required.
Collaborating then works as follows:
- Your collaborator pulls your script. The script opens as a notebook in Jupyter, with no outputs.
- They run the notebook and save it. Outputs are regenerated, and a local
.ipynbfile is created. - They change the notebook, and push their updated script. The diff is nothing else than a standard diff on a Python script.
- You pull the changed script, and refresh your browser. Input cells are updated. The outputs from cells that were changed are removed. Your variables are untouched, so you have the option to run only the modified cells to get the new outputs.
Code refactoring
In the animation below we propose a quick demo of Jupytext. While the example remains simple, it shows how your favorite text editor or IDE can be used to edit your Jupyter notebooks. IDEs are more convenient than Jupyter for navigating through code, editing and executing cells or fractions of cells, and debugging.
- We start with a Jupyter notebook.
- The notebook includes a plot of the world population. The plot legend is not in order of decreasing population, we'll fix this.
- We want the notebook to be saved as both a
.ipynband a.pyfile: we add a"jupytext": {"formats": "ipynb,py"},entry to the notebook metadata. - The Python script can be opened with PyCharm:
- Navigating in the code and documentation is easier than in Jupyter.
- The console is convenient for quick tests. We don't need to create cells for this.
- We find out that the columns of the data frame were not in the correct order. We update the corresponding cell, and get the correct plot.
- The Jupyter notebook is refreshed in the browser. Modified inputs are loaded from the Python script. Outputs and variables are preserved. We finally rerun the code and get the correct plot.
Installation
Install or update Jupytext with
pip install jupytext --upgrade
Then, configure Jupyter to use Jupytext:
- generate a Jupyter config, if you don't have one yet, with
jupyter notebook --generate-config - edit
.jupyter/jupyter_notebook_config.pyand append the following:
c.NotebookApp.contents_manager_class = "jupytext.TextFileContentsManager"
- and restart Jupyter, i.e. run
jupyter notebook
Paired notebooks
The idea of paired notebooks is to store an .ipynb file alongside other formats. This lets us get the best of both worlds: an easily sharable notebook that stores the outputs, and one or more text-only files that can for instance be put under version control.
You can edit text-only files outside of Jupyter (first deactivate Jupyter's autosave by running %autosave 0 in a cell), and then get the updated version in Jupyter by refreshing your browser.
When loading or refreshing an .ipynb file, the input cells of the notebook are read from the first non-.ipynb file among the associated formats.
When loading or refreshing a non-.ipynb file, the outputs are read from the .ipynb file (if ipynb is listed in the formats).
To enable paired notebooks, one option is to set the output formats by adding a "jupytext": {"formats": "ipynb,py"}, entry to the notebook metadata with Edit/Edit Notebook Metadata in Jupyter's menu:
{
"jupytext": {"formats": "ipynb,py"},
"kernelspec": {
(...)
},
"language_info": {
(...)
}
}
Accepted formats are composed of an extension, like ipynb, md, Rmd, jl, py, R, and an optional format name among light (default for Julia, Python), percent, sphinx, spin (default for R). Use ipynb,py:percent if you want to pair the .ipynb notebook with a .py script in the percent format. To have the script extension chosen according to the Jupyter kernel, use the auto extension.
Alternatively, it is also possible to set a default format pairing. Say you want to always associate .ipynb notebooks with an .md file (and reciprocally). This is simply done by adding the following to your Jupyter configuration file:
c.NotebookApp.contents_manager_class = "jupytext.TextFileContentsManager"
c.ContentsManager.default_jupytext_formats = "ipynb,md"
(and similarly for the other formats).
In case the percent format is your favorite, add the following to your .jupyter/jupyter_notebook_config.py file:
c.ContentsManager.preferred_jupytext_formats_save = "py:percent"
and then, Jupytext will understand "jupytext": {"formats": "ipynb,py"}, as an instruction to create the paired Python script in the percent format.
Command line conversion
The package provides a jupytext script for command line conversion between the various notebook extensions:
jupytext --to python notebook.ipynb # create a notebook.py file
jupytext --to py:percent notebook.ipynb # create a notebook.py file in the double percent format
jupytext --to markdown notebook.ipynb # create a notebook.md file
jupytext --output script.py notebook.ipynb # create a script.py file
jupytext --to notebook notebook.py # overwrite notebook.ipynb (remove outputs)
jupytext --to notebook --update notebook.py # update notebook.ipynb (preserve outputs)
jupytext --to ipynb notebook1.md notebook2.py # overwrite notebook1.ipynb and notebook2.ipynb
jupytext --to md --test notebook.ipynb # Test round trip conversion
jupytext --to md --output - notebook.ipynb # display the markdown version on screen
jupytext --from ipynb --to py:percent # read ipynb from stdin and write double percent script on stdout
Reading notebooks in Python
Manipulate notebooks in a Python shell or script using jupytext's main functions:
# Read notebook from file, given format name (guess format when `format_name` is None)
readf(nb_file, format_name=None)
# Read notebook from text, given extension and format name
reads(text, ext, format_name=None, [...])
# Return the text representation for the notebook, given extension and format name
writes(notebook, ext, format_name=None, [...])
# Write notebook to file in desired format
writef(notebook, nb_file, format_name=None)
Round-trip conversion
Representing Jupyter notebooks as scripts requires a solid round trip conversion. You don't want your notebooks (nor your scripts) to be modified because you are converting them to the other form. A few hundred tests ensure that round trip conversion is safe.
You can easily test that the round trip conversion preserves your Jupyter notebooks and scripts. Run for instance:
# Test the ipynb -> py:percent -> ipynb round trip conversion
jupytext --test notebook.ipynb -to py:percent
# Test the ipynb -> (py:percent + ipynb) -> ipynb (à la paired notebook) conversion
jupytext --test --update notebook.ipynb -to py:percent
Note that jupytext --test compares the resulting notebooks according to its expectations. If you wish to proceed to a strict comparison of the two notebooks, use jupytext --test-strict, and use the flag -x to report with more details on the first difference, if any.
Please note that
- When you associate a Jupyter kernel with your text notebook, that information goes to a YAML header at the top of your script or Markdown document. And Jupytext itself may create a
jupytextentry in the notebook metadata. - Cell metadata are available in
lightandpercentformats for all cell types. Sphinx Gallery scripts insphinxformat do not support cell metadata. R Markdown and R scripts inspinformat support cell metadata for code cells only. Markdown documents do not support cell metadata. - By default, a few cell metadata are not included in the text representation of the notebook. And only the most standard notebook metadata are exported. Learn more on this in this in the metadata filtering section.
- Representing a Jupyter notebook as a Markdown or R Markdown document has the effect of splitting markdown cells with two consecutive blank lines into multiple cells (as the two blank line pattern is used to separate cells).
Format specifications
Markdown and R Markdown
Our implementation for Jupyter notebooks as Markdown or R Markdown documents is straightforward:
- A YAML header contains the notebook metadata (Jupyter kernel, etc)
- Markdown cells are inserted verbatim, and separated with two blank lines
- Code and raw cells start with triple backticks collated with cell language, and end with triple backticks. Cell metadata are not available in the Markdown format. The code cell options in the R Markdown format are mapped to the corresponding Jupyter cell metadata options, when available.
See how our World population.ipynb notebook in the demo folder is represented in Markdown or R Markdown.
The light format for notebooks as scripts
The light format was created for this project. It is the default format for Python and Julia scripts. That format can read any script as a Jupyter notebook, even scripts which were never prepared to become a notebook. When a notebook is written as a script using this format, only a few cells markers are introduced—none if possible.
The light format has:
- A (commented) YAML header, that contains the notebook metadata.
- Markdown cells are commented, and separated with a blank line.
- Code cells are exported verbatim (except for Jupyter magics, which are commented), and separated with blank lines. Code cells are reconstructed from consistent Python paragraphs (no function, class or multiline comment will be broken).
- Cells that contain more than one Python paragraphs need an explicit start-of-cell delimiter
# +(// +in C++, etc). Cells that have explicit metadata have a cell header# + {JSON}where the metadata is represented, in JSON format. The end of cell delimiter is# -, and is omitted when followed by another explicit start of cell marker.
The light format is currently available for Python, Julia, R, Scheme and C++. Open our sample notebook in the light format here.
The percent format
The percent format is a representation of Jupyter notebooks as scripts, in which cells are delimited with a commented double percent sign # %%. The format was introduced by Spyder five years ago, and is now supported by many editors, including
- Spyder IDE,
- Hydrogen, a package for Atom,
- VS Code with the vscodeJupyter extension,
- Python Tools for Visual Studio,
- and PyCharm Professional.
Our implementation of the percent format is compatible with the original specifications by Spyder. We extended the format to allow markdown cells and cell metadata. Cell headers have the following structure:
# %% Optional text [cell type] {optional JSON metadata}
where cell type is either omitted (code cells), or [markdown] or [raw]. The content of markdown and raw cells is commented out in the resulting script.
Percent scripts created by Jupytext have a header with an explicit format information. The format of scripts with no header is inferred automatically: scripts with at least one # %% cell are identified as percent scripts.
The percent format is currently available for Python, Julia, R, Scheme and C++. Open our sample notebook in the percent format here.
If the percent format is your favorite, add the following to your .jupyter/jupyter_notebook_config.py file:
c.ContentsManager.preferred_jupytext_formats_save = "py:percent" # or "auto:percent"
Then, Jupytext's content manager will understand "jupytext": {"formats": "ipynb,py"}, as an instruction to create the paired Python script in the percent format.
Sphinx-gallery scripts
Another popular notebook-like format for Python script is the Sphinx-gallery format. Scripts that contain at least two lines with more than twenty hash signs are classified as Sphinx-Gallery notebooks by Jupytext.
Comments in Sphinx-Gallery scripts are formatted using reStructuredText rather than markdown. They can be converted to markdown for a nicer display in Jupyter by adding a c.ContentsManager.sphinx_convert_rst2md = True line to your Jupyter configuration file. Please note that this is a non-reversible transformation—use this only with Binder. Revert to the default value sphinx_convert_rst2md = False when you edit Sphinx-Gallery files with Jupytext.
Turn a GitHub repository containing Sphinx-Gallery scripts into a live notebook repository with Binder and Jupytext by adding only two files to the repo:
binder/requirements.txt, a list of the required packages (includingjupytext).jupyter/jupyter_notebook_config.pywith the following contents:
c.NotebookApp.contents_manager_class = "jupytext.TextFileContentsManager"
c.ContentsManager.preferred_jupytext_formats_read = "py:sphinx"
c.ContentsManager.sphinx_convert_rst2md = True
Our sample notebook is also represented in sphinx format here.
R knitr::spin scripts
The spin format implements these specifications:
- Jupyter metadata are in YAML format, in a
#'-commented header. - Markdown cells are commented with
#'. - Code cells are exported verbatim. Cell metadata are signalled with
#+. Cells end with a blank line, an explicit start of cell marker, or a markdown cell.
Jupyter Notebook or Jupyter Lab?
Jupytext works very well with the Jupyter Notebook editor, and we recommend that you get used to Jupytext within jupyter notebook first.
That being said, Jupytext also works well from Jupyter Lab. Please note that:
- Jupytext's installation is identical in both Jupyter Notebook and Jupyter Lab
- Jupyter Lab can open any paired notebook with
.ipynbextension. Paired notebooks work exactly as in Jupyter Notebook: input cells are taken from the text notebook, and outputs from the.ipynbfile. Both files are updated when the notebook is saved. - Pairing notebooks is slightly less convenient in Jupyter Lab than in Jupyter Notebook as Jupyter Lab has no notebook metadata editor yet. You will have to open the JSON representation of the notebook in an editor, find the notebook metadata and add the
"jupytext" : {"formats": "ipynb,py"},entry manually. - In Jupyter Lab, scripts or Markdown documents open as text by default. Open them as notebooks with the Open With -> Notebook context menu (available in Jupyter Lab 0.35 and above) as shown below:
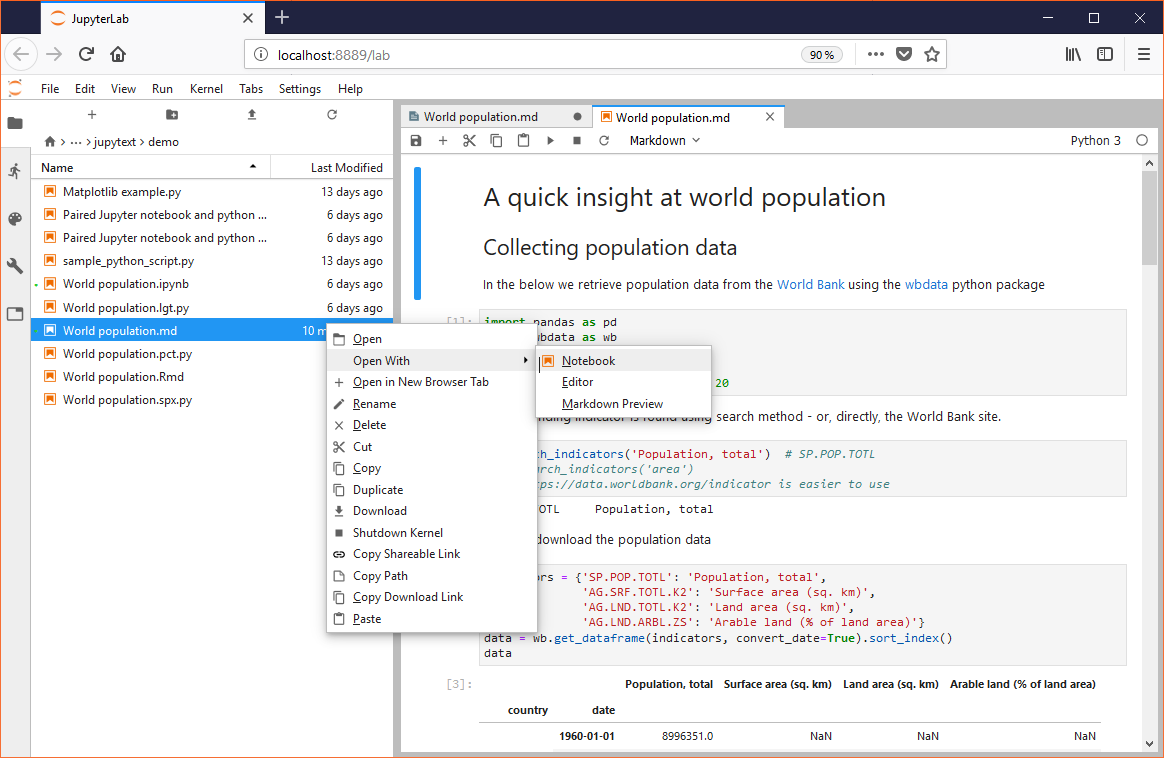
Will my notebook really run in an IDE?
Well, that's what we expect. There's however a big difference in the python environments between Python IDEs and Jupyter: in most IDEs the code is executed with python and not in a Jupyter kernel. For this reason, jupytext comments Jupyter magics found in your notebook when exporting to R Markdown, and to scripts in all format but the percent one. Magics are not commented in the plain Markdown representation, nor in the percent format, as some editors use that format in combination with Jupyter kernels. Change this by adding a #escape or #noescape flag on the same line as the magic, or a "comment_magics": true or false entry in the notebook metadata, in the "jupytext" section. Or set your preference globally on the contents manager by adding this line to .jupyter/jupyter_notebook_config.py:
c.ContentsManager.comment_magics = True # or False
Also, you may want some cells to be active only in the Python, or R Markdown representation. For this, use the active cell metadata. Set "active": "ipynb" if you want that cell to be active only in the Jupyter notebook. And "active": "py" if you want it to be active only in the Python script. And "active": "ipynb,py" if you want it to be active in both, but not in the R Markdown representation...
Cell and notebook metadata filtering
The text representation of the notebook focuses on the part of the notebook that you have written, and that should go under version control. Outputs and metadata that are (re)-constructed automatically when the notebook is executed do not need to enter the text representation.
To that aim, cell metadata autoscroll, collapsed, scrolled, trusted and ExecuteTime are not included in the text representation. And only the most standard notebook metadata (kernelspec, language_info and jupytext) are saved when a notebook is exported as text.
When a paired notebook is loaded, Jupytext loads the filtered metadata from the .ipynb file. Please keep in mind that the .ipynb file is typically not distributed accross contributors, and that the cell metadata may be lost when an input cell changes (cells are matched according to their contents). If you happen to miss a notebook or cell metadata, you can change the default filtering as follows. If you want to preserve all the notebook metadata but widget and varInspector, set a notebook metadata
"jupytext": {"metadata_filter": {"notebook": "all-widget,varInspector"}}
If you want to preserve the toc section (in addition to the default YAML header), use
"jupytext": {"metadata_filter": {"notebook": "toc"}}
At last, if you want to modify the default cell filter and allow ExecuteTime and autoscroll, but not hide_ouput, use
"jupytext": {"metadata_filter": {"cells": "ExecuteTime,autoscroll-hide_ouput"}}
A default value for these configuration options can be set on Jupytext's content manager using, for instance
c.default_notebook_metadata_filter = "all-widget,varInspector"
c.default_cell_metadata_filter = "ExecuteTime,autoscroll-hide_ouput"
If you are aware of a notebook metadata that should not be filtered, or of a cell metadata that should be filtered, please open an issue and let us know.
Finally, if you prefer that scripts and markdown files with no YAML header do not get one (nor additional cell metadata) when opened and saved in Jupyter, set the following option on Jupytext's content manager:
c.ContentsManager.additional_metadata_on_text_files = False
Extending the light and percent formats to more languages
You want to extend the light and percent format to another language? Please let us know! In principle that is easy, and you will only have to:
- document the language extension and comment by adding one line to
_SCRIPT_EXTENSIONSinlanguages.py. - contribute a sample notebook in
tests\notebooks\ipynb_[language]. - add two tests in
test_mirror.py: one for thelightformat, and another one for thepercentformat. - Make sure that the tests pass, and that the text representations of your notebook, found in
tests\notebooks\mirror\ipynb_to_scriptandtests\notebooks\mirror\ipynb_to_percent, are valid scripts.
Jupytext's releases and backward compatibility
Jupytext will continue to evolve as we collect more feedback, and discover more ways to represent notebooks as text files. When a new release of Jupytext comes out, we make our best to ensure that it will not break your notebooks. Format changes will not happen often, and we try hard not to introduce breaking changes.
Jupytext tests the version format for paired notebook only. If the format version of the text representation is not the current one, Jupytext will refuse to open the paired notebook. You may want to update Jupytext if the format version of the file is newer than the one available in the installed Jupytext. Otherwise, you will have to choose between deleting (or renaming) either the .ipynb, or its paired text representation. Keep the one that is up-to-date, re-open your notebook, and Jupytext will regenerate the other file.
We also recommend that people who use Jupytext to collaborate on notebooks use identical versions of Jupytext.
I like this, how can I contribute?
Your feedback is precious to us: please let us know how we can improve jupytext. With enough feedback we will be able to transition from the current beta phase to a stable phase. Thanks for staring the project on GitHub. Sharing it is also very helpful! By the way: stay tuned for announcements and demos on medium and twitter!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file jupytext-0.8.4rc0.tar.gz.
File metadata
- Download URL: jupytext-0.8.4rc0.tar.gz
- Upload date:
- Size: 68.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.11.0 pkginfo/1.4.2 requests/2.19.1 setuptools/39.2.0 requests-toolbelt/0.8.0 tqdm/4.23.4 CPython/3.6.6
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d3c387e697574ddf555fa46fcf10d8984aee18e609f1de2844f404b045e2f4b6
|
|
| MD5 |
46fd6005968d728f33605956bcaec574
|
|
| BLAKE2b-256 |
d1fc9fe4efc876a49e22efd13a8093add5bd01443de2339550be08c224a001a3
|







