A lightweight OCR library for Khmer and English documents

Project description
Kiri OCR 📄






Kiri OCR is a lightweight OCR library for English and Khmer documents. It provides document-level text detection, recognition, and rendering capabilities in a compact package.

✨ Key Features
- High Accuracy: Transformer model with hybrid CTC + attention decoder
- Bi-lingual: Native support for English and Khmer (and mixed text)
- Document Processing: Automatic text line and word detection
- Easy to Use: Simple Python API and CLI
- Lightweight: Compact model with efficient inference
📊 Dataset
The model is trained on the mrrtmob/khmer_english_ocr_image_line dataset, which contains 12 million synthetic images of Khmer and English text lines.
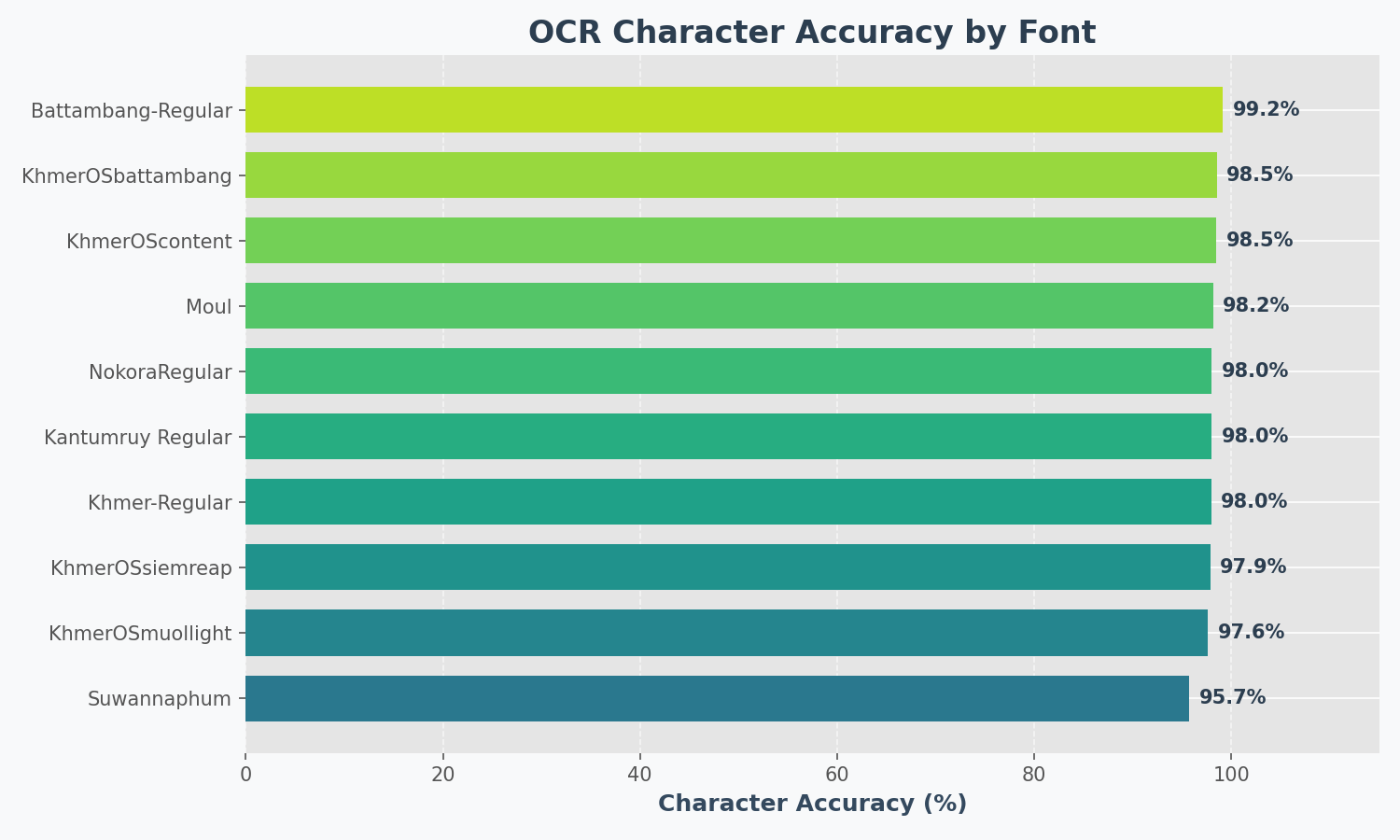
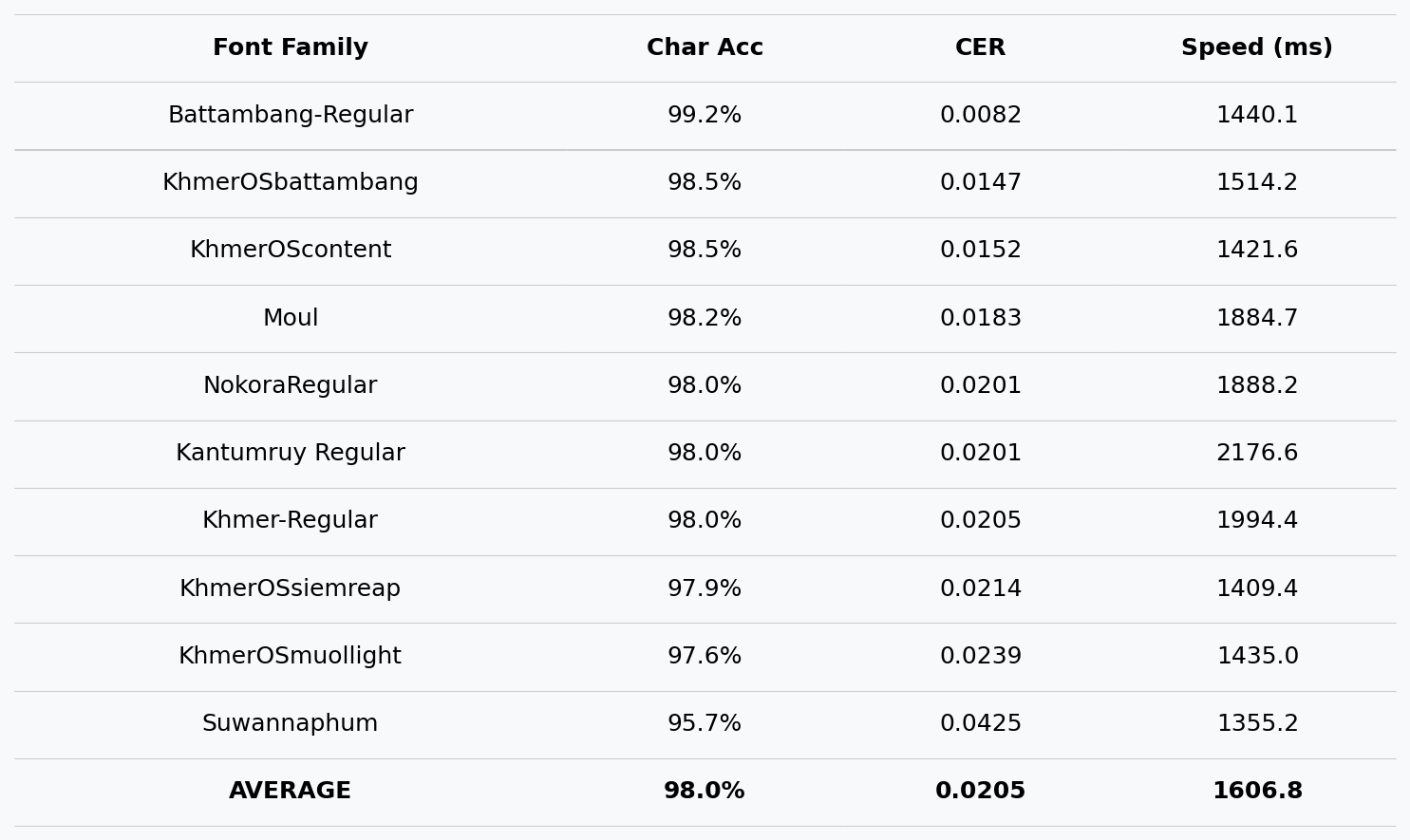
📈 Benchmark
Results on synthetic test images (10 popular fonts):
📦 Installation
Install via pip:
pip install kiri-ocr
Or install from source:
git clone https://github.com/mrrtmob/kiri-ocr.git
cd kiri-ocr
pip install -e .
💻 Quick Start
CLI Tool
# Run OCR on an image
kiri-ocr predict document.jpg --output results/
# Or simply
kiri-ocr document.jpg
# Stream text character-by-character (LLM style) ⚡
kiri-ocr predict document.jpg --stream
Python API
from kiri_ocr import OCR
# Initialize (auto-downloads from Hugging Face)
ocr = OCR()
# Extract text from document
text, results = ocr.extract_text('document.jpg')
print(text)
# Get detailed results with confidence scores
for line in results:
print(f"{line['text']} (confidence: {line['confidence']:.1%})")
Single Line Recognition
from kiri_ocr import OCR
ocr = OCR(device='cuda')
# Recognize a single text line image
text, confidence = ocr.recognize_single_line_image('text_line.png')
print(f"'{text}' ({confidence:.1%})")
Streaming API (Real-time)
Stream output character-by-character, similar to LLM text generation:
from kiri_ocr import OCR
ocr = OCR()
# Stream full document
for chunk in ocr.extract_text_stream_chars('document.jpg'):
if chunk['region_start']:
print(f"\n[Region {chunk['region_number']}] ", end='')
print(chunk['token'], end='', flush=True)
# Stream single line image
for chunk in ocr.recognize_streaming('line.png'):
print(chunk['token'], end='', flush=True)
🎓 Training Models
Kiri OCR uses a Transformer architecture with:
- CNN backbone for visual feature extraction
- Transformer encoder for contextual understanding
- CTC head for fast alignment-free decoding
- Attention decoder for accurate sequence generation
- CNN backbone for visual feature extraction
- Transformer encoder for contextual understanding
- CTC head for fast alignment-free decoding
- Attention decoder for accurate sequence generation
Basic Training
kiri-ocr train \
--hf-dataset mrrtmob/khmer_english_ocr_image_line \
--output-dir output \
--epochs 100 \
--batch-size 32 \
--device cuda
Full Configuration
kiri-ocr train \
--hf-dataset mrrtmob/khmer_english_ocr_image_line \
--output-dir output \
--height 48 \
--width 640 \
--batch-size 32 \
--epochs 100 \
--lr 0.0003 \
--weight-decay 0.01 \
--ctc-weight 0.5 \
--dec-weight 0.5 \
--max-seq-len 512 \
--save-steps 5000 \
--device cuda
Training Arguments
| Argument | Default | Description |
|---|---|---|
--height |
48 | Image height |
--width |
640 | Image width |
--batch-size |
32 | Training batch size |
--epochs |
100 | Number of training epochs |
--lr |
0.0003 | Learning rate |
--ctc-weight |
0.5 | Weight for CTC loss |
--dec-weight |
0.5 | Weight for decoder loss |
--vocab |
Auto | Path to vocab.json (auto-generated if not provided) |
--save-steps |
1000 | Save checkpoint every N steps |
--max-seq-len |
512 | Maximum decoder sequence length (prevents OOM) |
--resume |
False | Resume from latest checkpoint |
Resume Training
If training is interrupted:
kiri-ocr train \
--hf-dataset mrrtmob/khmer_english_ocr_image_line \
--output-dir output \
--epochs 100 \
--resume \
--device cuda
☁️ Google Colab Training

# Cell 1: Setup
!pip install -q kiri-ocr datasets
from google.colab import drive
drive.mount('/content/drive')
# Cell 2: Train
!kiri-ocr train \
--hf-dataset mrrtmob/khmer_english_ocr_image_line \
--output-dir /content/drive/MyDrive/kiri_models/v1 \
--height 48 \
--width 640 \
--batch-size 32 \
--epochs 100 \
--lr 0.0003 \
--ctc-weight 0.5 \
--dec-weight 0.5 \
--save-steps 5000 \
--device cuda
# Cell 3: Test
from kiri_ocr import OCR
ocr = OCR(
model_path="/content/drive/MyDrive/kiri_models/v1/model.safetensors",
device="cuda"
)
text, confidence = ocr.recognize_single_line_image("test.png")
print(f"'{text}' ({confidence:.1%})")
Training Time Estimates (Colab T4 GPU)
| Dataset Size | Epochs | Time |
|---|---|---|
| 10K samples | 100 | ~10 hours |
| 50K samples | 100 | ~24 hours |
| 100K samples | 100 | ~48 hours |
📁 Output Files
After training, your output directory will contain:
output/
├── vocab.json # Vocabulary (required for inference!)
├── model.safetensors # Best model weights (safetensors format)
├── model_meta.json # Model config metadata
├── model_optim.pt # Optimizer state
├── latest.safetensors # Latest checkpoint (for resume)
├── latest_meta.json # Latest config metadata
├── latest_optim.pt # Latest optimizer state
└── history.json # Training metrics
Note: Safetensors format is used for model weights with separate JSON metadata files. Legacy .pt format is still supported for loading.
🔧 Using Custom Models
Load Custom Model
from kiri_ocr import OCR
# Load your trained model (safetensors format)
ocr = OCR(
model_path="output/model.safetensors",
device="cuda"
)
# Also supports legacy .pt format
ocr = OCR(
model_path="output/model.pt",
device="cuda"
)
# Works the same as default model
text, confidence = ocr.recognize_single_line_image("image.png")
print(f"'{text}' ({confidence:.1%})")
Load from Hugging Face
from kiri_ocr import OCR
# Default model (CRNN)
ocr = OCR(model_path="mrrtmob/kiri-ocr")
# Or specify explicitly
ocr = OCR(model_path="your-username/your-model")
🎨 Generate Synthetic Data
Create training data from text files:
kiri-ocr generate \
--train-file data/textlines.txt \
--output data \
--fonts-dir fonts \
--augment 2 \
--random-augment \
--height 32 \
--width 512
Arguments:
| Argument | Description |
|---|---|
--train-file |
Source text file (one line per sample) |
--fonts-dir |
Directory with .ttf font files |
--augment |
Augmentation factor per line |
--random-augment |
Apply random noise/rotation |
--height |
Image height (32 for CRNN, 48 for Transformer) |
🎯 Train Text Detector (Optional)
Kiri OCR uses CRAFT for text detection. Train a custom detector:
1. Generate Detector Dataset
kiri-ocr generate-detector \
--text-file data/textlines.txt \
--fonts-dir fonts \
--output detector_dataset \
--num-train 1000 \
--num-val 200
2. Train Detector
kiri-ocr train-detector \
--epochs 50 \
--batch-size 8 \
--name my_craft_detector
3. Use Custom Detector
from kiri_ocr import OCR
ocr = OCR(
det_model_path="runs/detect/my_craft_detector/weights/best.pth",
det_method="craft"
)
⚙️ Configuration File
Use a YAML config file for complex setups:
# Generate default config
kiri-ocr init-config -o config.yaml
# Train with config
kiri-ocr train --config config.yaml
Example config.yaml:
# Image dimensions
height: 48
width: 640
# Training
batch_size: 32
epochs: 100
lr: 0.0003
weight_decay: 0.01
# Loss weights
ctc_weight: 0.5
dec_weight: 0.5
# Sequence length limit (prevents OOM with long texts)
max_seq_len: 512
# Paths
output_dir: output
save_steps: 5000
# Device
device: cuda
# Dataset (HuggingFace)
hf_dataset: mrrtmob/khmer_english_ocr_image_line
hf_train_split: train
hf_image_col: image
hf_text_col: text
# Resume training
resume: false
🔍 HuggingFace Dataset Options
| Argument | Default | Description |
|---|---|---|
--hf-dataset |
- | Dataset ID (e.g.,username/dataset) |
--hf-train-split |
train | Training split name |
--hf-val-split |
- | Validation split (auto-detected if not set) |
--hf-val-percent |
0.1 | Val split from train if no val split exists |
--hf-image-col |
image | Column name for images |
--hf-text-col |
text | Column name for text labels |
--hf-subset |
- | Dataset subset/config name |
--hf-streaming |
False | Stream instead of download |
📊 Expected Training Progress
Epoch 1/100 | Loss: 4.50 (CTC: 5.0, Dec: 4.0) | Val Acc: 2%
Epoch 10/100 | Loss: 2.10 (CTC: 2.3, Dec: 1.9) | Val Acc: 25%
Epoch 25/100 | Loss: 1.20 (CTC: 1.3, Dec: 1.1) | Val Acc: 55%
Epoch 50/100 | Loss: 0.60 (CTC: 0.7, Dec: 0.5) | Val Acc: 78%
Epoch 100/100 | Loss: 0.25 (CTC: 0.3, Dec: 0.2) | Val Acc: 92%
🐛 Troubleshooting
Model outputs garbage/random characters
Cause: Model not trained enough (need 50-100 epochs minimum)
# Check your model metadata
python -c "
import json
with open('model_meta.json') as f:
meta = json.load(f)
print(f\"Epoch: {meta.get('epoch', 'unknown')}\")
print(f\"Step: {meta.get('step', 'unknown')}\")
"
# Or for legacy .pt format
python -c "
import torch
ckpt = torch.load('model.pt', map_location='cpu')
print(f\"Epoch: {ckpt.get('epoch', 'unknown')}\")
print(f\"Step: {ckpt.get('step', 'unknown')}\")
"
Vocab file not found
Cause: vocab.json must be in the same directory as the model
# Check files
ls output/
# Should show: vocab.json, model.safetensors, model_meta.json, etc.
CUDA out of memory
Cause 1: Batch size too large for GPU memory
# Fix: Reduce batch size
kiri-ocr train --batch-size 16 ...
Cause 2: Dataset contains very long text sequences (100k+ characters)
# Fix: Limit maximum sequence length (default: 512)
kiri-ocr train --max-seq-len 256 ...
# For more VRAM, you can increase it
kiri-ocr train --max-seq-len 1024 ...
The --max-seq-len parameter truncates sequences that exceed the limit, preventing the decoder's causal attention mask from consuming excessive memory.
Low confidence scores
Cause: Use CTC decoding for inference (more reliable)
# In OCR initialization
ocr = OCR(model_path="model.pt", use_beam_search=False)
📁 Project Structure
kiri_ocr/
├── __init__.py # Main exports
├── core.py # OCR class
├── model.py # Transformer model
├── training.py # Training code
├── renderer.py # Document rendering
├── generator.py # Synthetic data generation
├── cli.py # Command-line interface
└── detector/ # Text detection
├── base.py
├── db/ # DB detector
└── craft/ # CRAFT detector
☕ Support
If you find this project useful:
- ⭐ Star this repository
- Buy Me a Coffee
- ABA Payway
⚖️ License
📚 Citation
@software{kiri_ocr,
author = {mrrtmob},
title = {Kiri OCR: Lightweight Khmer and English OCR},
year = {2026},
url = {https://github.com/mrrtmob/kiri-ocr}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file kiri_ocr-0.2.5.tar.gz.
File metadata
- Download URL: kiri_ocr-0.2.5.tar.gz
- Upload date:
- Size: 83.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a926deb67e8abb3fab64a297e3a20c3e6d5d48b249f02f453e45cd1d36a384f7
|
|
| MD5 |
31b4d8219df9e80c6695b3f196df646c
|
|
| BLAKE2b-256 |
fc4c54dea6f66d0c5aec1952feacb124266c9e8b0af87b8c41073a0708ee2065
|
File details
Details for the file kiri_ocr-0.2.5-py3-none-any.whl.
File metadata
- Download URL: kiri_ocr-0.2.5-py3-none-any.whl
- Upload date:
- Size: 86.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7f444e1e4b4bdecc1894944bf46c4c2c322f3836d0fd6a5fc54d993f58372b5d
|
|
| MD5 |
474da9c0bbf5e796c3833bec04aae259
|
|
| BLAKE2b-256 |
5af3e0d00dedcbe0ce14a80c4b0937de9db4641be8694c12a0a95d5086607a7e
|







