Parallel Iteration with File-Based Coordination
Project description

Laufband: Embarrassingly parallel, embarrassingly simple!

Laufband enables parallel iteration over a dataset from multiple processes, utilizing file-based locking and communication to ensure each item is processed exactly once.
Installation
Install Laufband using pip:
pip install laufband
Usage
Using Laufband is similar to the familiar tqdm progress bar for sequential iteration.
from laufband import Laufband
data = list(range(100))
for item in Laufband(data):
# Process each item in the dataset
pass
The true power of Laufband emerges when you run your script in parallel. Multiple processes will coordinate using file-based locking to ensure that each item in the dataset is processed by only one process.
Here's a typical example demonstrating parallel processing with Laufband and file-based locking for shared resource access:
import json
import time
from pathlib import Path
from laufband import Laufband
output_file = Path("data.json")
output_file.write_text(json.dumps({"processed_data": []}))
data = list(range(100))
worker = Laufband(data, tqdm_kwargs={"desc": "using Laufband"})
for item in worker:
# Simulate some computationally intensive task
time.sleep(0.1)
with worker.lock:
# Access and modify a shared resource (e.g., a file) safely using the lock
file_content = json.loads(output_file.read_text())
file_content["processed_data"].append(item)
output_file.write_text(json.dumps(file_content))
To execute this script (main.py) in parallel, you can use a command like the following in your terminal (this example launches 10 background processes):
for i in {1..10} ; do python main.py & done
[!IMPORTANT] The different processes may finish at different times. Therefore, the order of items in
file_contentis not guaranteed. If the order is important, you will need to implement sorting logic afterwards.
Failure Policy
In Laufband, a job will be automatically marked as failed if the iteration is interrupted by:
- an unhandled Exception
- or an explicit break.
from laufband import Laufband
data = list(range(100))
# Example 1: break
for item in Laufband(data):
if item == 50:
break # Job 50 will be marked as failed
# Example 2: Exception
for item in Laufband(data):
if item == 70:
raise ValueError("Something went wrong") # Job 70 will be marked as failed
If you want to exit early but still mark the job as successfully completed,
you should use Laufband.close() instead of break:
from laufband import Laufband
data = list(range(100))
worker = Laufband(data)
for item in worker:
if item == 50:
worker.close() # Job 50 will be marked as completed, and iteration will stop cleanly
Examples
ASE Calculator
For atomistic data, the ASE package is widely used to calculate energies and forces of atomic configurations using either ab initio methods or machine-learned interatomic potentials (MLIPs).
You can use Laufband to parallelize these calculations easily without duplication or manual bookkeeping and automatic checkpointing.
The following example uses a MACE foundation model to compute energies and forces on the ASE S22 dataset.
[!TIP] You can safely run this script multiple times — even across multiple SLURM jobs — without any modifications. Laufband will automatically coordinate which configurations are processed. For local parallelization, you can use bash:
for i in {1..10} ; do python main.py & done
import ase.io
from ase.collections import s22
from laufband import Laufband
from mace.calculators import mace_mp
# Initialize calculator
calc = mace_mp(model="medium", dispersion=False, default_dtype="float32")
worker = Laufband(list(s22))
for atoms in worker:
atoms.calc = calc
energy = atoms.get_potential_energy()
worker.iterator.set_description(f"{energy = }")
with worker.lock:
ase.io.write("frames.xyz", atoms, append=True)
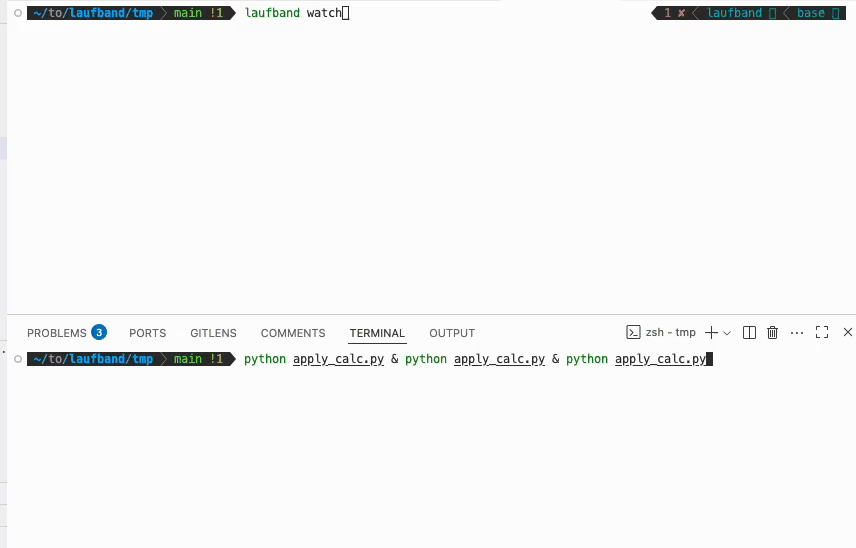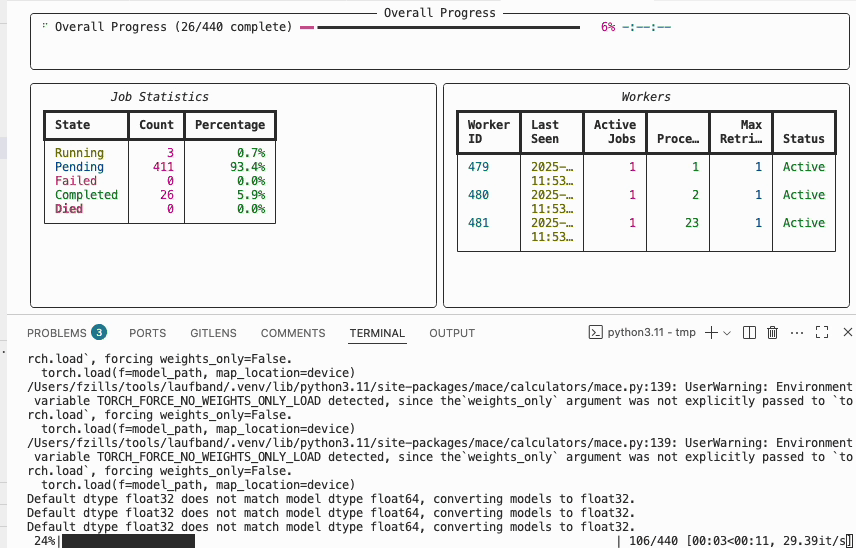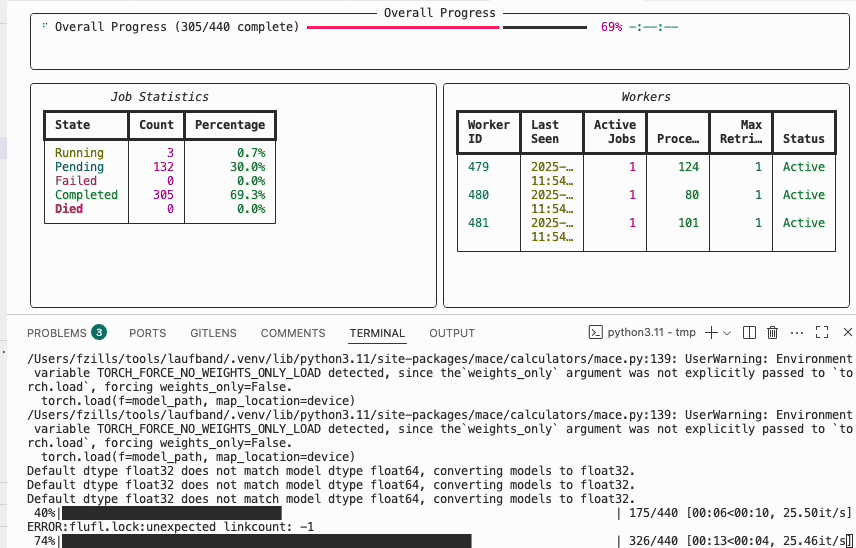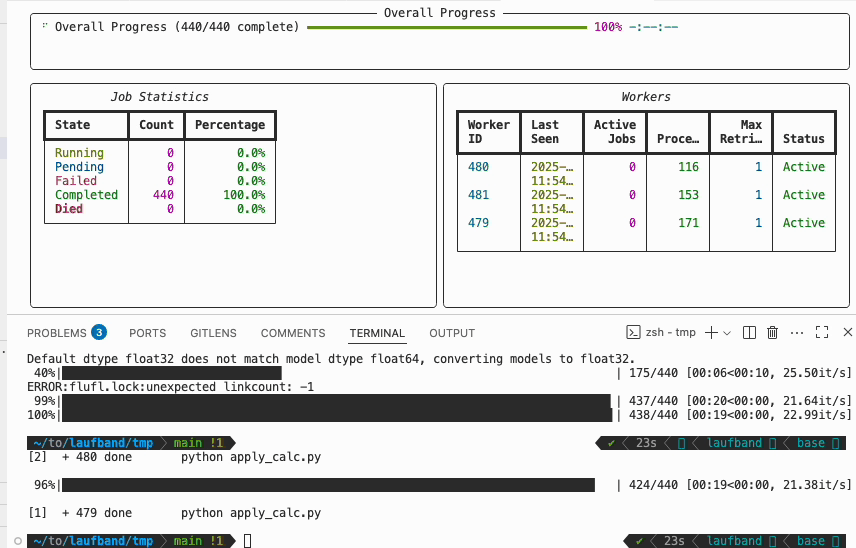
You can use the laufband watch to follow the progress across all active workers.
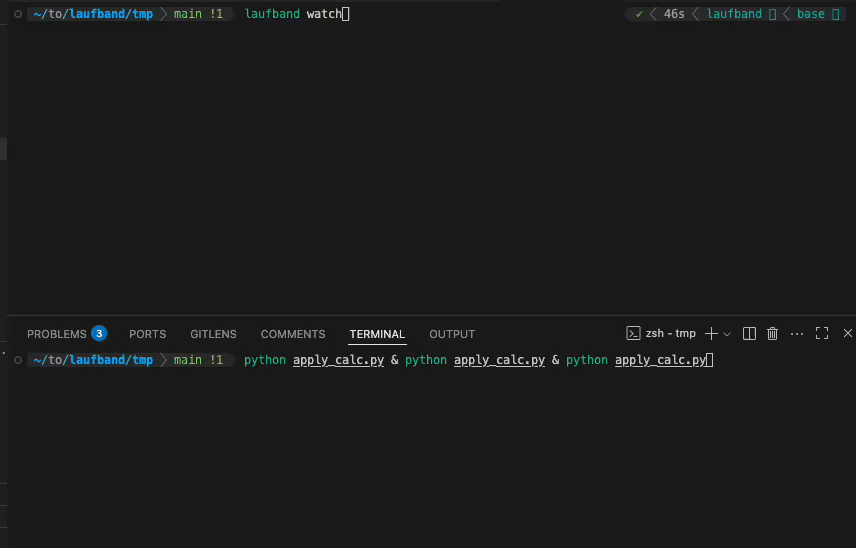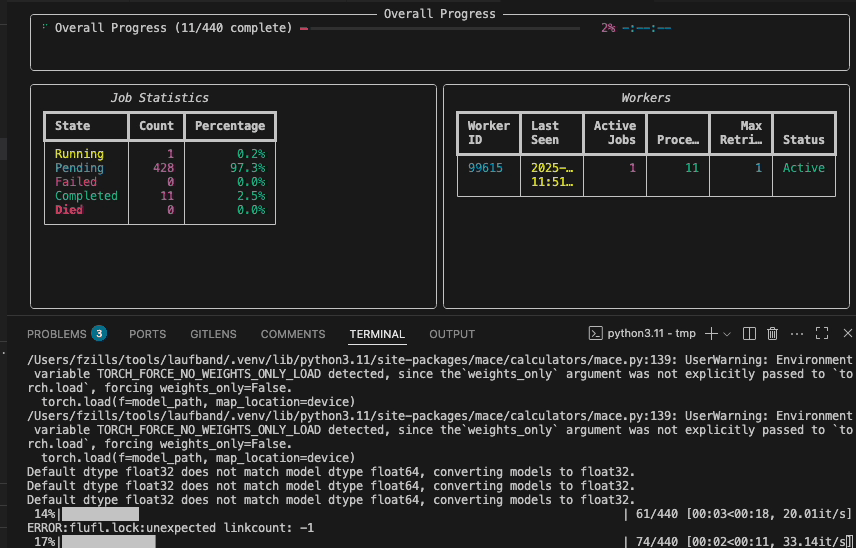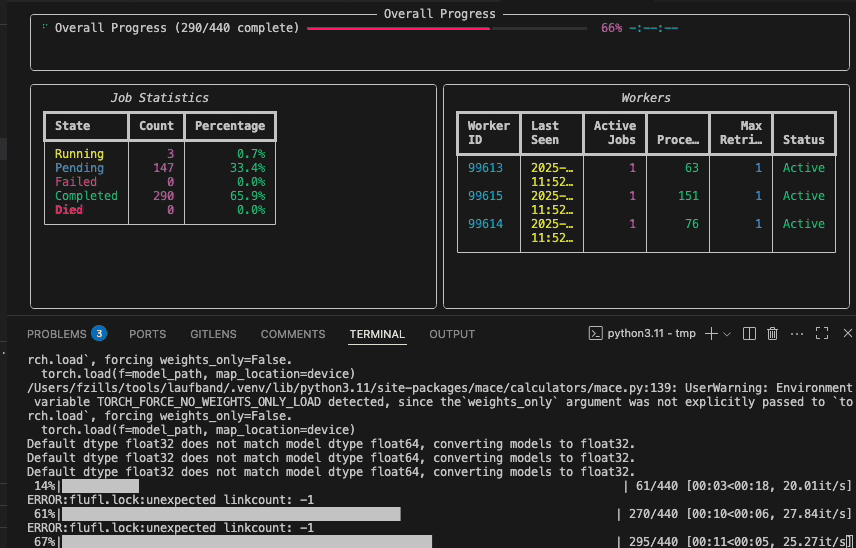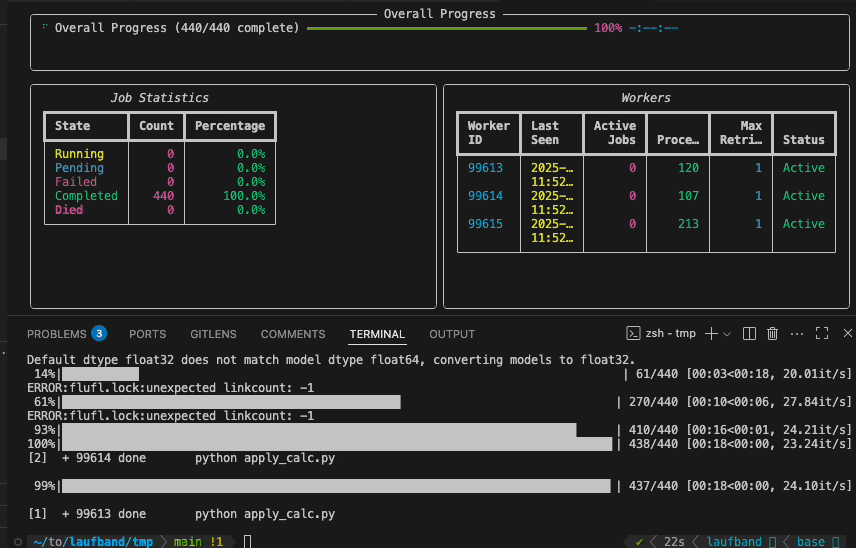
Graphband
Laufband supports dependency-aware tasks through laufband.Graphband.
To use this, provide an iterator that yields tasks in a valid execution order.
[!NOTE]
laufband.Laufbandeffectively uses a directed graph with no edges as the input tolaufband.Graphband.
import networkx as nx
from laufband import Task
def graph_tasks():
digraph = nx.DiGraph()
edges = [
("a", "b"),
("a", "c"),
("b", "d"),
("b", "e"),
("c", "f"),
("c", "g"),
]
digraph.add_edges_from(edges)
for node in nx.topological_sort(digraph):
yield Task(
id=node, # unique string representation of the task
data=node, # optional data associated with the task
dependencies=digraph.predecessors(node), # dependencies of the task
)
Given this generator, you can iterate the graph in parallel using laufband.Graphband.
[!WARNING] Once
laufband.Graphbandhas executed a task, it will not re-execute it, even if a dependency is added later on.
from laufband import Graphband
worker = Graphband(graph_tasks())
for task in worker:
print(task.id, task.data)
Labels, Requirements, and Multiple Workers per Task
You can assign requirements to your tasks and labels to workers to control their execution.
from laufband import Task, Graphband
def iterator():
yield Task(id="task1")
yield Task(id="task2", requirements={"gpu"})
w1 = Graphband(iterator(), identifier="w1")
w2 = Graphband(iterator(), identifier="w2", labels={"gpu"})
print([x.id for x in w1])
# ["task1"]
print([x.id for x in w2])
# ["task2"]
Sometimes a task supports internal parallel execution (e.g., nested use of laufband). In such a case, you can assign multiple workers to one task.
[!NOTE] Keep in mind that
laufbanddoes not actually schedule the execution. The number of available workers per task depends on how many workers are spawned.
from laufband import Task, Graphband
def iterator():
yield Task(id="task1", max_parallel_workers=2)
# At most 2 workers will be assigned to this job until both successfully finish.
worker = Graphband(iterator())
for item in worker:
# Code that can be executed multiple times, e.g., via laufband itself.
...
Project details
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file laufband-0.2.0.tar.gz.
File metadata
- Download URL: laufband-0.2.0.tar.gz
- Upload date:
- Size: 191.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.17
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
986bddd4a6ff1b7d41cb96db98160276773745aecdea6dbbceb9456f04df84ba
|
|
| MD5 |
531e041824c93efd43410717324f4ed9
|
|
| BLAKE2b-256 |
2a998403619cda7d6c7ee6cf389b45abbe32cf9ccdcb5b414a478e0203a3422c
|
File details
Details for the file laufband-0.2.0-py3-none-any.whl.
File metadata
- Download URL: laufband-0.2.0-py3-none-any.whl
- Upload date:
- Size: 18.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.17
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
41eb7381d8841654ec5b97902647007243bcfa2b954f123d7af435164675b388
|
|
| MD5 |
03f6c3b63dddbe0eb31b4f1b4e3ece0f
|
|
| BLAKE2b-256 |
b66bc5e135c57bd885fb0ad0eb86b857bc7dfb62405270ef64b44bb25c7cd6d4
|







