Faster DataLoader for datasets that are fully loaded into memory as tensors.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
TensorDataLoader - A faster dataloader for datasets that are fully loaded into memory.
On my laptop pytorch dataloader is 9 times slower at dataloading CIFAR10 preloaded into memory, with random shuffling, and tested with all batch sizes from 1 to 1000.
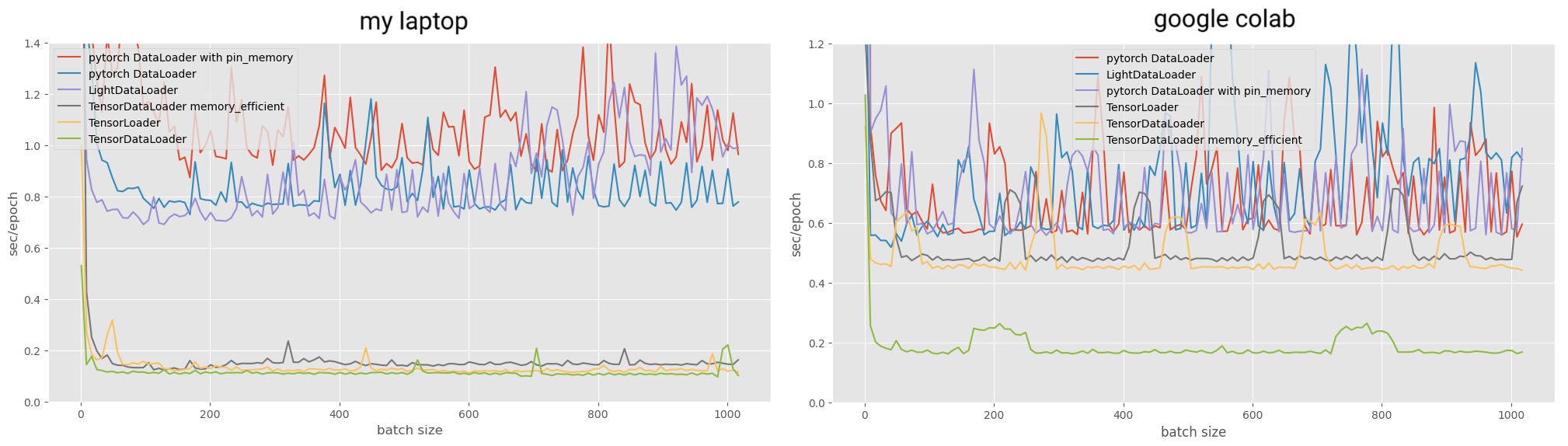
Here is how much time the whole benchmark took for different dataloaders:
my laptop:
pytorch DataLoader with pin_memory 146.8673715000623 sec.
pytorch DataLoader 113.20603140027379 sec.
LightDataLoader 112.37881010014098 sec.
TensorDataLoader memory_efficient 21.554916899913223 sec.
TensorLoader 17.700561700039543 sec.
TensorDataLoader 14.947468700091122 sec.
google colab:
pytorch DataLoader 97.84741502100019 sec.
LightDataLoader 97.33544923200111 sec.
pytorch DataLoader with pin_memory 91.82473706000007 sec.
TensorLoader 67.40266070800055 sec.
TensorDataLoader 62.62979004000067 sec.
TensorDataLoader memory_efficient 24.25830095599804 sec.
TensorLoader is another library that I just found that does the same thing :D https://github.com/zhb2000/tensorloader
I found that pytorch dataloader is slow when benchmarking stuff on mnist1d, and despite my dataset being fully loaded into memory, dataloading took most of the training time (mnist1d training is REALLY quick because it is small enough to be preloaded straight to GPU).
installation
pip install light-dataloader
TensorDataLoader
This dataloader is created similarly to torch.utils.data.TensorDataset.
Stack all of your samples into one or multiple tensors that have the same size of the first dimension.
For example:
cifar = torchvision.datasets.CIFAR10('cifar10', transform = loader, download=True)
stacked_images = torch.stack([i[0] for i in cifar])
stacked_labels = torch.tensor([i[1] for i in cifar])
If you pass a single tensor, the dataloader will yield tensors. If you pass a sequence of one or more tensors, the dataloader will yield lists of tensors.
# passing a list
from light_dataloader import TensorDataLoader
dataloader = TensorDataLoader([stacked_images, stacked_labels], batch_size = 128, shuffle = True)
for images, labels in dataloader:
...
# passing a tensor
dataloader = TensorDataLoader(stacked_images, batch_size = 128, shuffle = True)
for tensor in dataloader:
...
LightDataLoader
LightDataLoader is a very lightweight version of normal pytorch dataloader, it functions in the same way and collates the dataset. On a dataset that is fully preloaded into memory, compared to normal pytorch dataloader it is slightly faster with batch size under 64, but lacks many features. The reason you might consider this is when the dataset is just big enough to fit into memory, but too big to run torch.stack operations to use TensorDataLoader.
from light_dataloader import LightDataLoader
loader = v2.Compose([v2.ToImage(), v2.ToDtype(torch.float32), v2.Normalize(0.4914, 0.4822, 0.4465), (0.247, 0.243, 0.261)])
cifar = torchvision.datasets.CIFAR10('cifar10', transform = loader, download=True)
# usage is the same as torch.utils.data.DataLoader
# and like pytorch dataloader, it converts everything into tensors and collates the batch
dataloader = LightDataLoader(cifar, batch_size = 128, shuffle = True)
for images, labels in dataloader:
...
Other
memory_efficient option
During shuffling at the start of each epoch, TensorDataLoader has to use 2 times the memory of whatever tensors were passed to it. With memory_efficient=True it usually becomes slightly slower, but doesn't use any additional memory. However as I found out when benchmarking, memory_efficient=True is actually much faster then False when on google colab.
reproducibility
Both TensorDataLoader and LightDataLoader accept seed argument. It is None by default, but if you set it to any integer, that integer will be used as seed for random shuffling, ensuring reproducible results.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file light_dataloader-1.0.8.tar.gz.
File metadata
- Download URL: light_dataloader-1.0.8.tar.gz
- Upload date:
- Size: 5.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
84eeeafbedb8f4b0d5812334f9977bfe696e508ac2b6ae2fdfb6b1ac871a9900
|
|
| MD5 |
92255c6be1ae3bafd562f4a431cc7d3c
|
|
| BLAKE2b-256 |
936f57af0663c74b590b1f93c3320755a7ef4f9ffc4ebc88178585723c91e656
|
Provenance
The following attestation bundles were made for light_dataloader-1.0.8.tar.gz:
Publisher:
python-publish.yml on inikishev/light-dataloader
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
light_dataloader-1.0.8.tar.gz -
Subject digest:
84eeeafbedb8f4b0d5812334f9977bfe696e508ac2b6ae2fdfb6b1ac871a9900 - Sigstore transparency entry: 434686991
- Sigstore integration time:
-
Permalink:
inikishev/light-dataloader@a5378f4de728ddba2a9485bff43a91b5c5361436 -
Branch / Tag:
refs/tags/1.0.8 - Owner: https://github.com/inikishev
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
python-publish.yml@a5378f4de728ddba2a9485bff43a91b5c5361436 -
Trigger Event:
push
-
Statement type:
File details
Details for the file light_dataloader-1.0.8-py3-none-any.whl.
File metadata
- Download URL: light_dataloader-1.0.8-py3-none-any.whl
- Upload date:
- Size: 6.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
91f7dd45c3289836d3cd611d4651453ca538c408e6071ea86713c160f29c9a8c
|
|
| MD5 |
56e3769b0b756706fce5c1d161547ea6
|
|
| BLAKE2b-256 |
276465f5539362f223ed2d27281dbb2acba9b65a710fde67de066752b5f02c22
|
Provenance
The following attestation bundles were made for light_dataloader-1.0.8-py3-none-any.whl:
Publisher:
python-publish.yml on inikishev/light-dataloader
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
light_dataloader-1.0.8-py3-none-any.whl -
Subject digest:
91f7dd45c3289836d3cd611d4651453ca538c408e6071ea86713c160f29c9a8c - Sigstore transparency entry: 434687011
- Sigstore integration time:
-
Permalink:
inikishev/light-dataloader@a5378f4de728ddba2a9485bff43a91b5c5361436 -
Branch / Tag:
refs/tags/1.0.8 - Owner: https://github.com/inikishev
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
python-publish.yml@a5378f4de728ddba2a9485bff43a91b5c5361436 -
Trigger Event:
push
-
Statement type:







