The official llm2vec library


Project description
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders



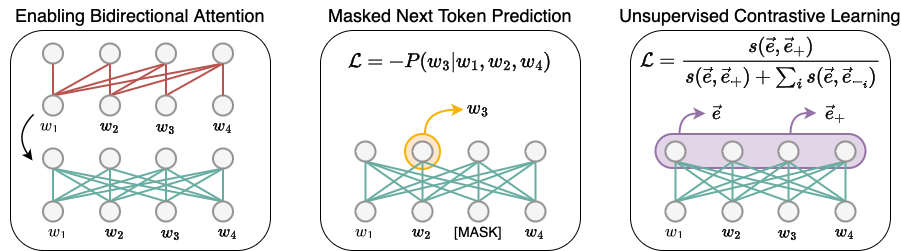
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.
Installation
To use LLM2Vec, first install the llm2vec package from PyPI.
pip install llm2vec
You can also directly install it from our code by cloning the repository and:
pip install -e .
Getting Started
LLM2Vec class is a wrapper on top of HuggingFace models to support sequence encoding and pooling operations. The steps below showcase an example on how to use the library.
Preparing the model
Initializing LLM2Vec model using pretrained LLMs is straightforward. The from_pretrained method of LLM2Vec takes a base model identifier/path and an optional PEFT model identifier/path. All HuggingFace model loading arguments can be passed to from_pretrained method (make sure the llm2vec package version is >=0.1.3).
Here, we first initialize the Mistral MNTP base model and load the unsupervised-trained LoRA weights (trained with SimCSE objective and wiki corpus).
import torch
from llm2vec import LLM2Vec
l2v = LLM2Vec.from_pretrained(
"McGill-NLP/LLM2Vec-Mistral-7B-Instruct-v2-mntp",
peft_model_name_or_path="McGill-NLP/LLM2Vec-Mistral-7B-Instruct-v2-mntp-unsup-simcse",
device_map="cuda" if torch.cuda.is_available() else "cpu",
torch_dtype=torch.bfloat16,
)
We can also load the model with supervised-trained LoRA weights (trained with contrastive learning and public E5 data) by changing the peft_model_name_or_path.
import torch
from llm2vec import LLM2Vec
l2v = LLM2Vec.from_pretrained(
"McGill-NLP/LLM2Vec-Mistral-7B-Instruct-v2-mntp",
peft_model_name_or_path="McGill-NLP/LLM2Vec-Mistral-7B-Instruct-v2-mntp-supervised",
device_map="cuda" if torch.cuda.is_available() else "cpu",
torch_dtype=torch.bfloat16,
)
By default the LLM2Vec model uses the mean pooling strategy. You can change the pooling strategy by passing the pooling_mode argument to the from_pretrained method. Similarly, you can change the maximum sequence length by passing the max_length argument (default is 512).
Inference
This model now returns the text embedding for any input in the form of [[instruction1, text1], [instruction2, text2]] or [text1, text2]. While training, we provide instructions for both sentences in symmetric tasks, and only for for queries in asymmetric tasks.
# Encoding queries using instructions
instruction = (
"Given a web search query, retrieve relevant passages that answer the query:"
)
queries = [
[instruction, "how much protein should a female eat"],
[instruction, "summit define"],
]
q_reps = l2v.encode(queries)
# Encoding documents. Instruction are not required for documents
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments.",
]
d_reps = l2v.encode(documents)
# Compute cosine similarity
q_reps_norm = torch.nn.functional.normalize(q_reps, p=2, dim=1)
d_reps_norm = torch.nn.functional.normalize(d_reps, p=2, dim=1)
cos_sim = torch.mm(q_reps_norm, d_reps_norm.transpose(0, 1))
print(cos_sim)
"""
tensor([[0.5485, 0.0551],
[0.0565, 0.5425]])
"""
Model List
-
Mistral-7B
-
Bi + MNTP
-
Bi + MNTP + SimCSE (Unsupervised state-of-the-art on MTEB)
-
Bi + MNTP + Supervised (state-of-the-art on MTEB among models trained on public data)
-
-
Llama-2-7B
-
Sheared-Llama-1.3B
Training
Training code will be available soon.
Citation
If you find our work helpful, please cite us:
@article{llm2vec,
title={{LLM2Vec}: {L}arge Language Models Are Secretly Powerful Text Encoders},
author={Parishad BehnamGhader and Vaibhav Adlakha and Marius Mosbach and Dzmitry Bahdanau and Nicolas Chapados and Siva Reddy},
year={2024},
journal={arXiv preprint},
url={https://arxiv.org/abs/2404.05961}
}
Bugs or questions?
If you have any questions about the code, feel free to open an issue on the GitHub repository.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file llm2vec-0.1.3.tar.gz.
File metadata
- Download URL: llm2vec-0.1.3.tar.gz
- Upload date:
- Size: 16.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.11.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d8f3eb4a2ddf5e5d96302a3ac26adced210be2b841c81e325e5d832676403654
|
|
| MD5 |
c36d6685606f6cf088da1887f67bffaf
|
|
| BLAKE2b-256 |
0a1804a688d9977c62c590b07772b141d432e6f5e122228eafd44da9c796c716
|
File details
Details for the file llm2vec-0.1.3-py2.py3-none-any.whl.
File metadata
- Download URL: llm2vec-0.1.3-py2.py3-none-any.whl
- Upload date:
- Size: 16.1 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.0.0 CPython/3.11.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
803cb8f58d356b3ea759abe3b7eb0e9f1f4d51a23a607ca442126572f7edf7f5
|
|
| MD5 |
1660d80f7949454df5abe9c928e63a43
|
|
| BLAKE2b-256 |
7d28d1ec771a5e59a13a5063b8f6b71de24ff13f9a6e257a85c25ff7d70447cf
|







