Design and build LLMs.txt knowledge structures by extracting and summarizing web content

Project description
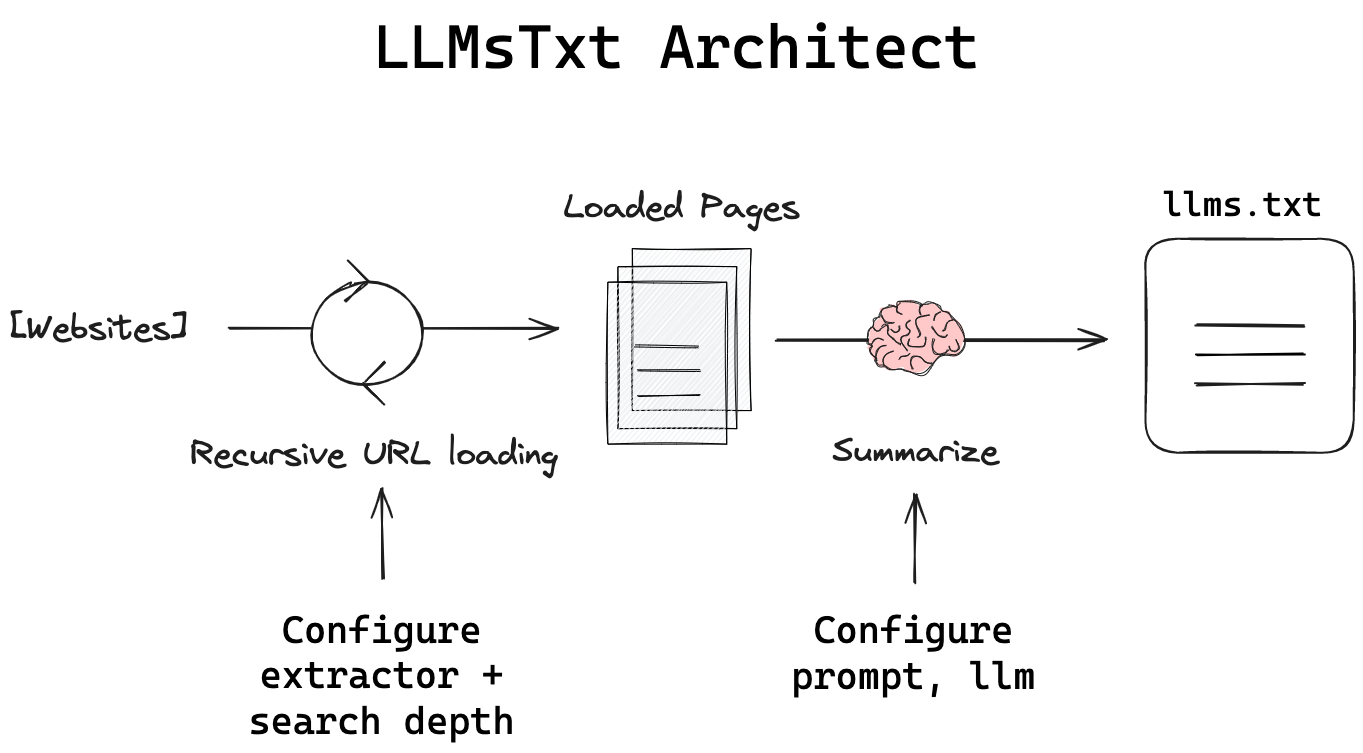
LLMsTxt Architect
llms.txt is an emerging standard for communicating website contents to LLMs, often as a markdown file listing URLs within a site and their descriptions. This has potential to support context retrieval, allowing LLMs to reflect on llms.txt files and then fetch / read pages needed to accomplish tasks. However, this means that llms.txt files must clearly communicate the purpose of each URL so that the LLM knows which pages to fetch.
LLMsTxt Architect is a Python package that designs and builds LLMs.txt files by extracting and summarizing web content using LLMs. Importantly, it gives the user control over the prompt to summarize pages, the model provider and model for summarization, the input pages to search, the search depth for recursive URL loader for each input page, and the website extractor (e.g., bs4, Markdownify, etc) for each page.
Features
- Recursively crawl a user defined list of web sites to a user-defined depth
- Extract content from each page with a user-defined extractor
- Summarize content using user-defined LLM selected from many providers
- Fault tolerance with checkpoints to resume after interruptions or timeouts
- Periodic progress updates with intermediate results saved during processing
- Skip already processed pages to efficiently resume interrupted runs
- Generate a formatted LLMs.txt file containing all summaries sorted by URL
- Deduplicate summaries to ensure clean output
Quickstart
API key
By default, the package uses Anthropic's Claude models. You can set the API key for the Anthropic provider with:
export ANTHROPIC_API_KEY=your_api_key_here
However, you can easily switch to other providers listed here (see Configurations below).
UVX
Use uvx to fetch and run the package directly with user-defined parameters:
$ curl -LsSf https://astral.sh/uv/install.sh | sh
$ uvx --from llmstxt-architect llmstxt-architect --urls https://langchain-ai.github.io/langgraph/concepts --max-depth 1 --llm-name claude-3-7-sonnet-latest --llm-provider anthropic --project-dir test
Pip
CLI
$ python3 -m venv .venv
$ source .venv/bin/activate # On Windows: .venv\Scripts\activate
$ pip install llmstxt-architect
$ llmstxt-architect --urls https://langchain-ai.github.io/langgraph/concepts --max-depth 1 --llm-name claude-3-7-sonnet-latest --llm-provider anthropic --project-dir test
Python API in Jupyter/IPython notebooks
import asyncio
from llmstxt_architect.main import generate_llms_txt
await generate_llms_txt(
urls=["https://langchain-ai.github.io/langgraph/concepts"],
max_depth=1,
llm_name="claude-3-7-sonnet-latest",
llm_provider="anthropic",
project_dir="test",
)
Python API in a script
import asyncio
from llmstxt_architect.main import generate_llms_txt
async def main():
await generate_llms_txt(
urls=["https://langchain-ai.github.io/langgraph/concepts"],
max_depth=1,
llm_name="claude-3-7-sonnet-latest",
llm_provider="anthropic",
project_dir="test_script",
)
if __name__ == "__main__":
asyncio.run(main())
Configurations
The full list of configurations is available in the CLI help.
| Parameter | Type | Default | Description |
|---|---|---|---|
--urls |
List[str] | Required | List of URLs to process |
--max-depth |
int | 5 | Maximum recursion depth for URL crawling |
--llm-name |
str | "claude-3-sonnet-20240229" | LLM model name |
--llm-provider |
str | "anthropic" | LLM provider |
--project-dir |
str | "llms_txt" | Main project directory to store all outputs |
--output-dir |
str | "summaries" | Directory within project-dir to save individual summaries |
--output-file |
str | "llms.txt" | Output file name for combined summaries |
--summary-prompt |
str | "You are creating a summary..." | Prompt to use for summarization |
--blacklist-file |
str | None | Path to a file containing blacklisted URLs to exclude (one per line) |
--extractor |
str | "default" | HTML content extractor to use (choices: "default" (Markdownify), "bs4" (BeautifulSoup)) |
Model
The package uses LLMs for summarization. By default, it's configured for Anthropic's Claude models:
To use a different LLM provider:
Hosted LLMs (OpenAI, Anthropic, etc.):
- Install the corresponding package (e.g.,
pip install langchain-openai) - Set the appropriate API key (e.g.,
export OPENAI_API_KEY=your_api_key_here) - Specify the provider and model with the
--llm-providerand--llm-nameoptions, e.g.,--llm-provider openai --llm-name gpt-4o
Local Models with Ollama:
- Install Ollama
- Pull your desired model (e.g.,
ollama pull llama3.2:latest) - Install the package:
pip install langchain-ollama - Specify the provider and model with the
--llm-providerand--llm-nameoptions, e.g.,
No API key is required for local models!--llm-provider ollama --llm-name llama3.2:latest
Prompt
By default, it uses this prompt (see llmstxt_architect/cli.py):
"You are creating a summary for a webpage to be used in a llms.txt file "
"to help LLMs in the future know what is on this page. Produce a concise "
"summary of the key items on this page and when an LLM should access it."
You can override this prompt with the --summary-prompt option, e.g.,
--summary-prompt "You are creating a summary for a webpage to be used in a llms.txt file "
Extractor
The package uses LangChain's RecursiveURLLoader to crawl the URLs.
You can specify which built-in extractor to use with the --extractor CLI option:
# Use BeautifulSoup extractor
llmstxt-architect --urls https://example.com --extractor bs4
# Use default Markdownify extractor
llmstxt-architect --urls https://example.com --extractor default
For advanced use cases, you can override the default extractor in the Python API with your own custom extractor function, e.g.,
def my_extractor(html: str) -> str:
"""
Extract content from HTML using xxx.
Args:
html (str): The HTML content to extract from
Returns:
content (str): Extracted text content
"""
# TODO: Implement your custom extractor here
return content
import asyncio
from llmstxt_architect.main import generate_llms_txt
await generate_llms_txt(
urls=["https://langchain-ai.github.io/langgraph/concepts"],
max_depth=1,
llm_name="claude-3-7-sonnet-latest",
llm_provider="anthropic",
project_dir="test",
extractor=my_extractor
)
Resuming Interrupted Runs
The tool provides robust checkpoint functionality to handle interruptions during processing:
Checkpoint Files
- Progress tracker:
<project_dir>/<output_dir>/summarized_urls.json - Individual summaries:
<project_dir>/<output_dir>/<url>.txt - Combined output:
<project_dir>/<output_file>
All paths are configurable with the --project-dir, --output-dir, and --output-file options.
Auto-Resume Functionality
If processing is interrupted (timeout, network issues, etc.), simply run the same command again. The tool will:
- Skip already processed pages using the checkpoint file
- Resume processing from where it left off
- Update the output file periodically (every 5 documents)
- Generate a complete, sorted llms.txt file upon completion
This is particularly valuable when processing large websites or when using rate-limited API-based LLMs.
URL Blacklisting
You can exclude specific URLs from your llms.txt file by providing a blacklist file:
# Create a blacklist file
cat > blacklist.txt << EOF
# Deprecated pages
https://example.com/old-version/
https://example.com/beta-feature
# Pages with known issues
https://example.com/broken-page
EOF
The name of the blacklist file is configurable with the --blacklist-file option.
The blacklist file should contain one URL per line. Empty lines and lines starting with # are ignored. The tool will:
- Skip summarization of blacklisted URLs during crawling
- Filter out blacklisted URLs from the final llms.txt file
- Report how many blacklisted URLs were excluded
This is useful for excluding deprecated documentation, beta features, or pages with known issues.
Summary of Features
The tool includes several features to handle large-scale documentation processing:
- Interruption Handling: Even if the process is interrupted by timeouts or errors, progress is preserved
- Incremental Updates: The output file is updated periodically during processing (every 5 successful summaries)
- URL Deduplication: Summaries for pages that have already been processed are not regenerated
- Content Deduplication: Duplicate summaries are filtered out from the final output
- Organized Output: Summaries in the final llms.txt file are sorted by URL for better readability
- URL Blacklisting: Support for excluding specific URLs via a blacklist file
- Exception Handling: Errors during summarization of individual pages don't halt the entire process
- Progress Tracking: Clear console output shows which pages have been processed and skipped
These enhancements make the tool suitable for processing large documentation websites with hundreds of pages, even when using rate-limited API-based LLM providers.
License
MIT


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file llmstxt_architect-0.4.0.tar.gz.
File metadata
- Download URL: llmstxt_architect-0.4.0.tar.gz
- Upload date:
- Size: 60.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0475a9aabea3f8fff5e36540e3e2474a0bcf5baf5c0976c5471eb4d0a69ed000
|
|
| MD5 |
3dd54d9d5003b0e58dd5bf3fbb71273c
|
|
| BLAKE2b-256 |
677f23c6337393d4fccabfaf0b4fe56f7e019180c659bd3974155a1dbf4c2dd8
|
File details
Details for the file llmstxt_architect-0.4.0-py3-none-any.whl.
File metadata
- Download URL: llmstxt_architect-0.4.0-py3-none-any.whl
- Upload date:
- Size: 14.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7911a6b52170599ce2b6127d866f85f08fca712539c7af034c4a78d56419c9dc
|
|
| MD5 |
172e66683e85ec836664ced57ed664d5
|
|
| BLAKE2b-256 |
dd296c70ff7f54facc7ba57ae4434658706927ae3441a888987021df89b5275e
|







