A LLM serving engine extension to reduce TTFT and increase throughput, especially under long-context scenarios.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers



Project description













| Blog | Documentation | Join Slack | Interest Form | Roadmap
Summary
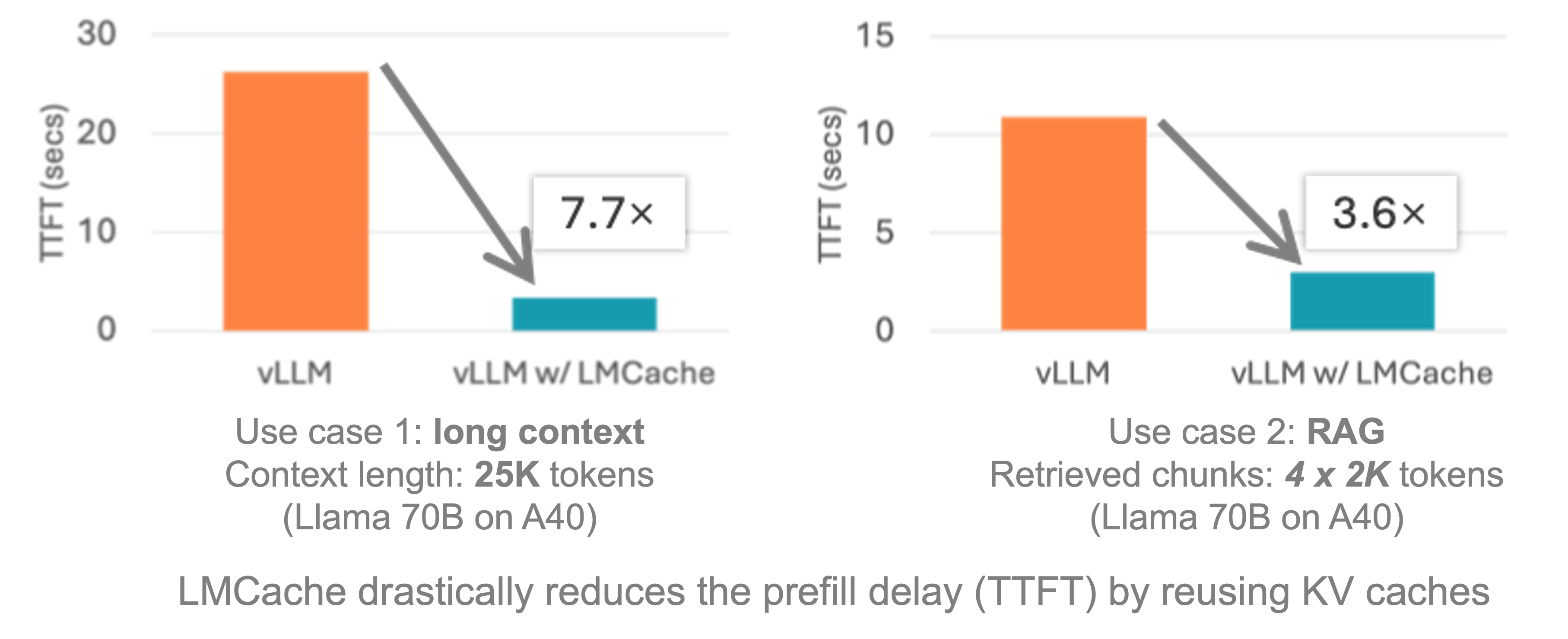
LMCache is an LLM serving engine extension to reduce TTFT and increase throughput, especially under long-context scenarios. By storing the KV caches of reusable texts all over the datacenter (including GPU, CPU, Disk and even S3) with a wide range of acceleration technqiue (zero cpu copy, NIXL, GDS and more). LMCache reuses the KV caches of any reused text (not necessarily prefix) in any serving engine instance. Thus, LMCache saves precious GPU cycles and reduces user response delay.
By combining LMCache with vLLM, developers achieve 3-10x delay savings and GPU cycle reduction in many LLM use cases, including multi-round QA and RAG.
LMCache is used, integrated, or referenced across a growing ecosystem of LLM serving platforms, infrastructure providers, and open-source projects:
- Initiated and officially supported by: Tensormesh
- Adopted by inference providers: GMI cloud (blog post), Google cloud (blog post), CoreWeave (blog post) and more
- Integrated with data and storage infrastructure providers: Redis (blog post), Weka (blog post), PliOps (blog post) and more
- Used by open-source projects and platforms: vLLM
, SGLang
, vLLM Production Stack
, llm-d
, NVIDIA dynamo
, KServe
and more.
For more details, please check our Ray Summit talk and technical report.
Features
- 🔥 Integration with vLLM v1 with the following features:
- High performance CPU KVCache offloading
- Disaggregated prefill
- P2P KVCache sharing
- Integration with SGLang for KV cache offloading
- Storage support as follows:
- CPU
- Disk
- NIXL
- Installation support through pip and latest vLLM
Installation
To use LMCache, simply install lmcache from your package manager, e.g. pip:
pip install lmcache
Works on Linux NVIDIA GPU platform.
More detailed installation instructions are available in the docs, particularly if you are not using the latest stable version of vllm or using another serving engine with different dependencies. Any "undefined symbol" or torch mismatch versions can be resolved in the documentation.
Getting started
The best way to get started is to checkout the Quickstart Examples in the docs.
Documentation
Check out the LMCache documentation which is available online.
We also post regularly in LMCache blogs.
Examples
Go hands-on with our examples, demonstrating how to address different use cases with LMCache.
Interested in Connecting?
Fill out the interest form, sign up for our newsletter, join LMCache slack, or drop an email, and our team will reach out to you!
Community meeting
The community meeting Zoom Link for LMCache is hosted bi-weekly. All are welcome to join!
Meetings are held bi-weekly on: Tuesdays at 9:00 AM PT – Add to Google Calendar
We keep notes from each meeting on this document for summaries of standups, discussion, and action items.
Recordings of meetings are available on the YouTube LMCache channel.
Contributing
We welcome and value all contributions and collaborations. Please check out Contributing Guide on how to contribute.
We continually update [Onboarding] Welcoming contributors with good first issues!
Citation
If you use LMCache for your research, please cite our papers:
@inproceedings{liu2024cachegen,
title={Cachegen: Kv cache compression and streaming for fast large language model serving},
author={Liu, Yuhan and Li, Hanchen and Cheng, Yihua and Ray, Siddhant and Huang, Yuyang and Zhang, Qizheng and Du, Kuntai and Yao, Jiayi and Lu, Shan and Ananthanarayanan, Ganesh and others},
booktitle={Proceedings of the ACM SIGCOMM 2024 Conference},
pages={38--56},
year={2024}
}
@article{cheng2024large,
title={Do Large Language Models Need a Content Delivery Network?},
author={Cheng, Yihua and Du, Kuntai and Yao, Jiayi and Jiang, Junchen},
journal={arXiv preprint arXiv:2409.13761},
year={2024}
}
@inproceedings{10.1145/3689031.3696098,
author = {Yao, Jiayi and Li, Hanchen and Liu, Yuhan and Ray, Siddhant and Cheng, Yihua and Zhang, Qizheng and Du, Kuntai and Lu, Shan and Jiang, Junchen},
title = {CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion},
year = {2025},
url = {https://doi.org/10.1145/3689031.3696098},
doi = {10.1145/3689031.3696098},
booktitle = {Proceedings of the Twentieth European Conference on Computer Systems},
pages = {94–109},
}
@article{cheng2025lmcache,
title={LMCache: An Efficient KV Cache Layer for Enterprise-Scale LLM Inference},
author={Cheng, Yihua and Liu, Yuhan and Yao, Jiayi and An, Yuwei and Chen, Xiaokun and Feng, Shaoting and Huang, Yuyang and Shen, Samuel and Du, Kuntai and Jiang, Junchen},
journal={arXiv preprint arXiv:2510.09665},
year={2025}
}
Socials
License
The LMCache codebase is licensed under Apache License 2.0. See the LICENSE file for details.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file lmcache-0.4.2.tar.gz.
File metadata
- Download URL: lmcache-0.4.2.tar.gz
- Upload date:
- Size: 2.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9a3a216e0d0275c88e62bac0f1c8a0dace45564da4653504c36d26d8013cbafc
|
|
| MD5 |
6be2f1497ea8d497a867ca048d06656e
|
|
| BLAKE2b-256 |
c16646ebc3616abde54a76334b39ec514b417b4649a012ae14e3a82b9eca5891
|
Provenance
The following attestation bundles were made for lmcache-0.4.2.tar.gz:
Publisher:
publish.yml on LMCache/LMCache
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
lmcache-0.4.2.tar.gz -
Subject digest:
9a3a216e0d0275c88e62bac0f1c8a0dace45564da4653504c36d26d8013cbafc - Sigstore transparency entry: 1119303785
- Sigstore integration time:
-
Permalink:
LMCache/LMCache@9d413181c30ec2ec97bcb6b17defa7c5f9f8e36e -
Branch / Tag:
refs/tags/v0.4.2 - Owner: https://github.com/LMCache
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@9d413181c30ec2ec97bcb6b17defa7c5f9f8e36e -
Trigger Event:
release
-
Statement type:
File details
Details for the file lmcache-0.4.2-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: lmcache-0.4.2-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 8.6 MB
- Tags: CPython 3.13, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d9e2221e5112e88cb51210e7506d7ee0582f6bb236f447dc65439077e2fd8355
|
|
| MD5 |
d1be10c46cc865478e4290ce90063ce4
|
|
| BLAKE2b-256 |
9fdfcee6b5bcbb2197e831aaadd43d4335e9aef09c22e1053749df53dd30d6c6
|
Provenance
The following attestation bundles were made for lmcache-0.4.2-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl:
Publisher:
publish.yml on LMCache/LMCache
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
lmcache-0.4.2-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl -
Subject digest:
d9e2221e5112e88cb51210e7506d7ee0582f6bb236f447dc65439077e2fd8355 - Sigstore transparency entry: 1119303789
- Sigstore integration time:
-
Permalink:
LMCache/LMCache@9d413181c30ec2ec97bcb6b17defa7c5f9f8e36e -
Branch / Tag:
refs/tags/v0.4.2 - Owner: https://github.com/LMCache
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@9d413181c30ec2ec97bcb6b17defa7c5f9f8e36e -
Trigger Event:
release
-
Statement type:
File details
Details for the file lmcache-0.4.2-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: lmcache-0.4.2-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 8.6 MB
- Tags: CPython 3.12, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f25861d8a4230100f1daab18a2255d17ef100ad29cfd58f1803e665547d53b26
|
|
| MD5 |
1df2818b3a7dd61c8395d92a8a9f11e7
|
|
| BLAKE2b-256 |
61f8c98ca48237fd04aff2e20957e4883373dcbbd56b921a7a9e82e03c4ec425
|
Provenance
The following attestation bundles were made for lmcache-0.4.2-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl:
Publisher:
publish.yml on LMCache/LMCache
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
lmcache-0.4.2-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl -
Subject digest:
f25861d8a4230100f1daab18a2255d17ef100ad29cfd58f1803e665547d53b26 - Sigstore transparency entry: 1119303787
- Sigstore integration time:
-
Permalink:
LMCache/LMCache@9d413181c30ec2ec97bcb6b17defa7c5f9f8e36e -
Branch / Tag:
refs/tags/v0.4.2 - Owner: https://github.com/LMCache
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@9d413181c30ec2ec97bcb6b17defa7c5f9f8e36e -
Trigger Event:
release
-
Statement type:
File details
Details for the file lmcache-0.4.2-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: lmcache-0.4.2-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 8.6 MB
- Tags: CPython 3.11, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
eab49a84680e4416bd9599f1c8a5225a41a3d91eebd0818fc81af4e738028d7e
|
|
| MD5 |
fc014147a5aa75ed6402d72306e26726
|
|
| BLAKE2b-256 |
9876cf1e5255aa8d4c9ed3d767a2e6ff9d18f8d0c8d0aa89134c08e578325248
|
Provenance
The following attestation bundles were made for lmcache-0.4.2-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl:
Publisher:
publish.yml on LMCache/LMCache
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
lmcache-0.4.2-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl -
Subject digest:
eab49a84680e4416bd9599f1c8a5225a41a3d91eebd0818fc81af4e738028d7e - Sigstore transparency entry: 1119303790
- Sigstore integration time:
-
Permalink:
LMCache/LMCache@9d413181c30ec2ec97bcb6b17defa7c5f9f8e36e -
Branch / Tag:
refs/tags/v0.4.2 - Owner: https://github.com/LMCache
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@9d413181c30ec2ec97bcb6b17defa7c5f9f8e36e -
Trigger Event:
release
-
Statement type:
File details
Details for the file lmcache-0.4.2-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl.
File metadata
- Download URL: lmcache-0.4.2-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl
- Upload date:
- Size: 8.5 MB
- Tags: CPython 3.10, manylinux: glibc 2.27+ x86-64, manylinux: glibc 2.28+ x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2024b6af21d9ffa9d03ccb32dfeb1d3c5d48250172777b5bfc2a54dd373ec84d
|
|
| MD5 |
41104a5920238dec8eda103fee5fb4d8
|
|
| BLAKE2b-256 |
fd1cfeec8eb0e7b1a75d3861b4141387b29a18a6749a9ce9e2383a502e5120f9
|
Provenance
The following attestation bundles were made for lmcache-0.4.2-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl:
Publisher:
publish.yml on LMCache/LMCache
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
lmcache-0.4.2-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl -
Subject digest:
2024b6af21d9ffa9d03ccb32dfeb1d3c5d48250172777b5bfc2a54dd373ec84d - Sigstore transparency entry: 1119303792
- Sigstore integration time:
-
Permalink:
LMCache/LMCache@9d413181c30ec2ec97bcb6b17defa7c5f9f8e36e -
Branch / Tag:
refs/tags/v0.4.2 - Owner: https://github.com/LMCache
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@9d413181c30ec2ec97bcb6b17defa7c5f9f8e36e -
Trigger Event:
release
-
Statement type:







