Python-based Illumina methylation array preprocessing software

Project description
methylprep is a python package for processing Illumina methylation array data.
View on ReadTheDocs.







Methylprep is part of the methylsuite
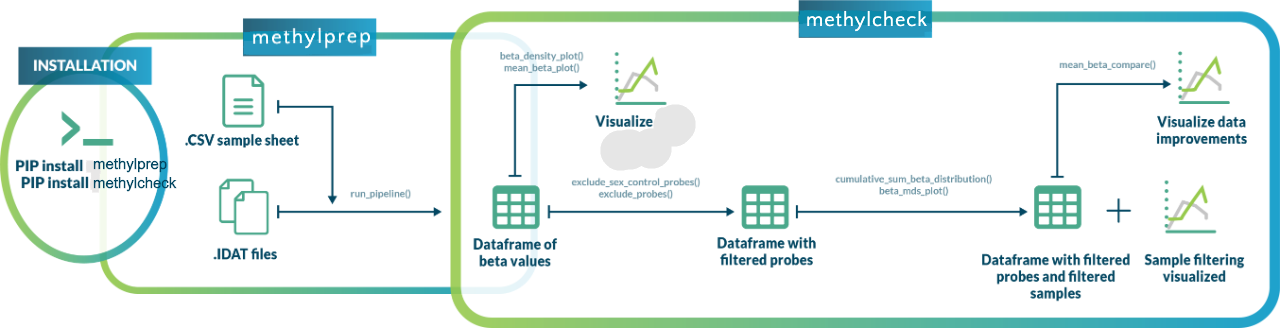
methylprep is part of the methylsuite of python packages that provide functions to process and analyze DNA methylation data from Illumina's Infinium arrays (27k, 450k, and EPIC, as well as mouse arrays). The methylprep package contains functions for processing raw data files from arrays and downloading/processing public data sets from GEO (the NIH Gene Expression Omnibus database repository), or from ArrayExpress. It contains both a command line interface (CLI) for processing data from local files, and a set of functions for building a custom pipeline in a jupyter notebook or python scripting environment. The aim is to offer a standard process, with flexibility for those who want it.
methylprep data processing has also been tested and benchmarked to match the outputs of two popular R packages: sesame (v1.10.4) and minfi (v1.38).
Methylsuite package components
You should install all three components, as they work together. The parts include:
-
methylprep: (this package) for processingidatfiles or downloading GEO datasets from NIH. Processing steps include- infer type-I channel switch
- NOOB (normal-exponential convolution on out-of-band probe data)
- poobah (p-value with out-of-band array hybridization, for filtering lose signal-to-noise probes)
- qualityMask (to exclude historically less reliable probes)
- nonlinear dye bias correction (AKA signal quantile normalization between red/green channels across a sample)
- calculate beta-value, m-value, or copy-number matrix
- large batch memory management, by splitting it up into smaller batches during processing
-
methylcheck: for quality control (QC) and analysis, including- functions for filtering out unreliable probes, based on the published literature
- Note that
methylprep processwill exclude a set of unreliable probes by default. You can disable that using the --no_quality_mask option from CLI.
- Note that
- sample outlier detection
- array level QC plots, based on Genome Studio functions
- a python clone of Illumina's Bead Array Controls Reporter software (QC)
- data visualization functions based on
seabornandmatplotlibgraphic libraries. - predict sex of human samples from probes
- interactive method for assigning samples to groups, based on array data, in a Jupyter notebook
- functions for filtering out unreliable probes, based on the published literature
-
methylizeprovides more analysis and interpretation functions- differentially methylated probe statistics (between treatment and control samples)
- volcano plots (which probes are the most different?)
- manhattan plots (where in genome are the differences?)
Installation
methylprep maintains configuration files for your Python package manager of choice: pipenv or pip. Conda install is coming soon.
>>> pip install methylprep
or if you want to install all three packages at once:
>>> pip install methylsuite
Tutorials and Guides
If you're new to DNA methylation analysis, we recommend reading through this introduction in order get the background knowledge needed to best utilize methylprep effectively. Otherwise, you're ready to use methylprep for:
- processing your own methylation data
- downloading unprocessed data (like IDAT files) from GEO.
- downloading preprocessed data (like beta values) from GEO.
- building a composite dataset using control samples from GEO.
- building a composite dataset from GEO data with any keyword you choose (e.g. combining all GEO datasets that have methylation data from patients with brain cancer).
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file methylprep-1.7.1.tar.gz.
File metadata
- Download URL: methylprep-1.7.1.tar.gz
- Upload date:
- Size: 115.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/3.10.0 pkginfo/1.7.0 requests/2.27.1 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.8.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bd0d24d1c322372098717bc5cca3617d6d726568aea9f9f4fabbd9346461a629
|
|
| MD5 |
8eec7745bc2c72c7564abc5f6eeeb694
|
|
| BLAKE2b-256 |
6b58677b958474072bccae801805608fb8a700ebdafdda7fc86c2e5a66ce165a
|
File details
Details for the file methylprep-1.7.1-py3-none-any.whl.
File metadata
- Download URL: methylprep-1.7.1-py3-none-any.whl
- Upload date:
- Size: 1.3 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/3.10.0 pkginfo/1.7.0 requests/2.27.1 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.8.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8374476036a5c7bc33641666321c8a9ece88c36dfa32cd6aaa9d7edd512b50ec
|
|
| MD5 |
f7a940c25a126d20784803c8809ebd89
|
|
| BLAKE2b-256 |
5b4d20c5f58c9c20baa5e058371e1d890720ca201ad0b5cee1d80a35bf167e78
|







