DSpark + DFlash speculative decoding (semi-autoregressive / block-diffusion drafting) for Apple Silicon via MLX

Project description

DeepSeek's DSpark and z-lab's DFlash speculative decoding — native on Apple Silicon via MLX.
Lossless drafters (same output, just faster) for the Qwen3 and Gemma-4 families — plus any matched
DSpark / DFlash checkpoint. Run them at the CLI, from Python, or serve an OpenAI-compatible API to LM Studio / any local tool.




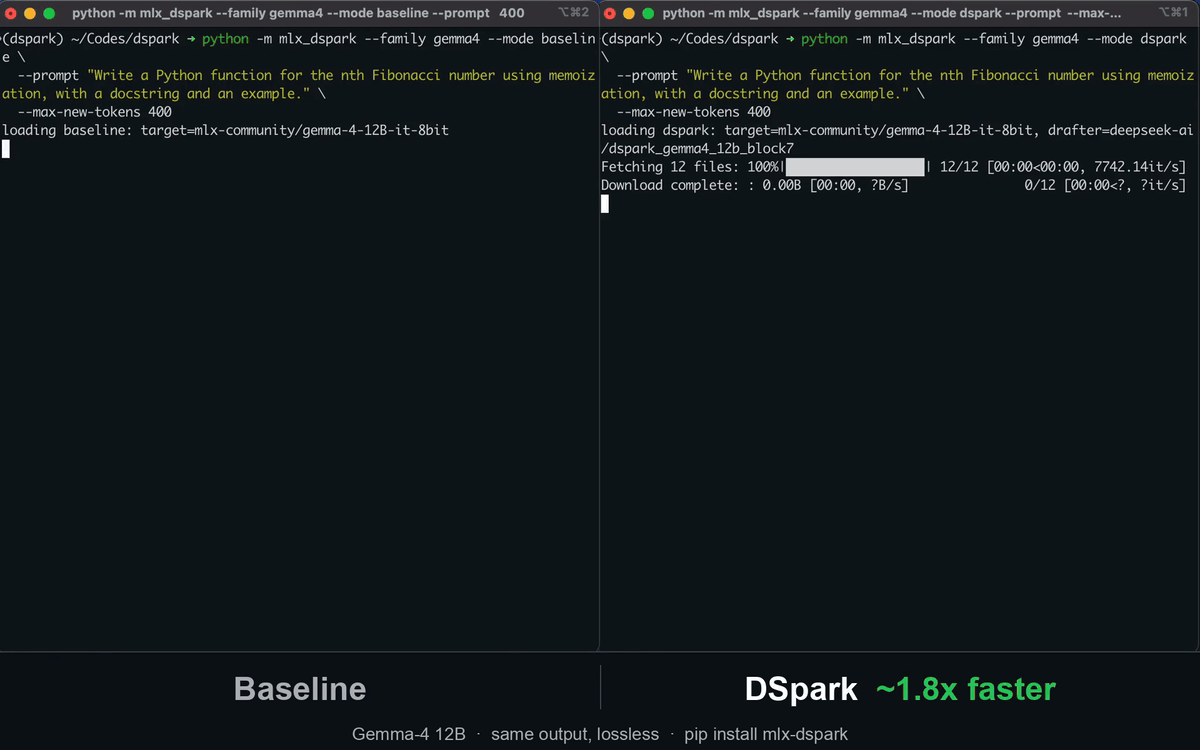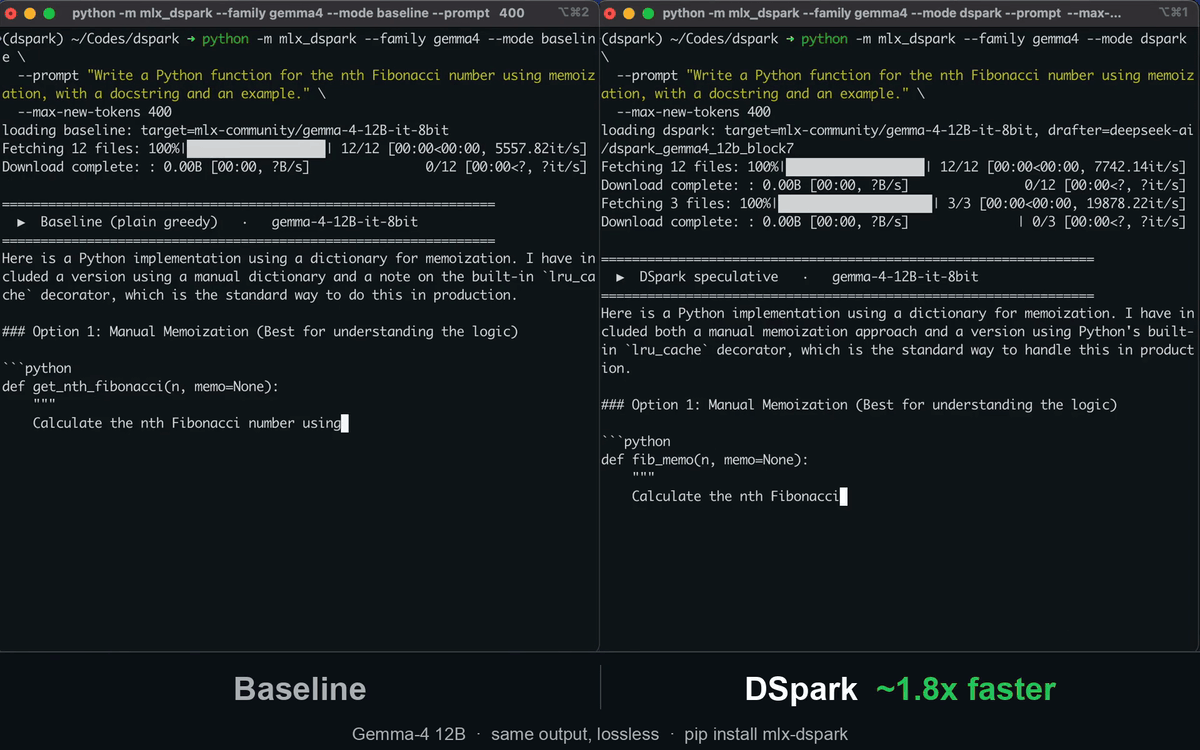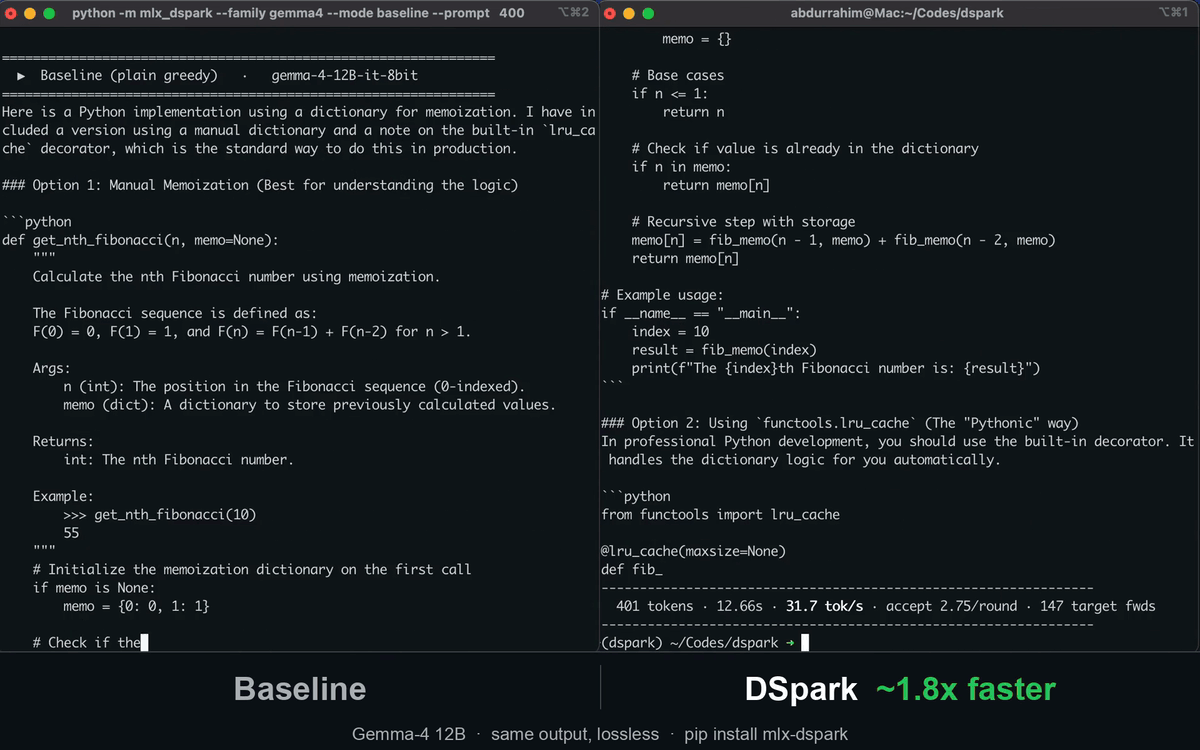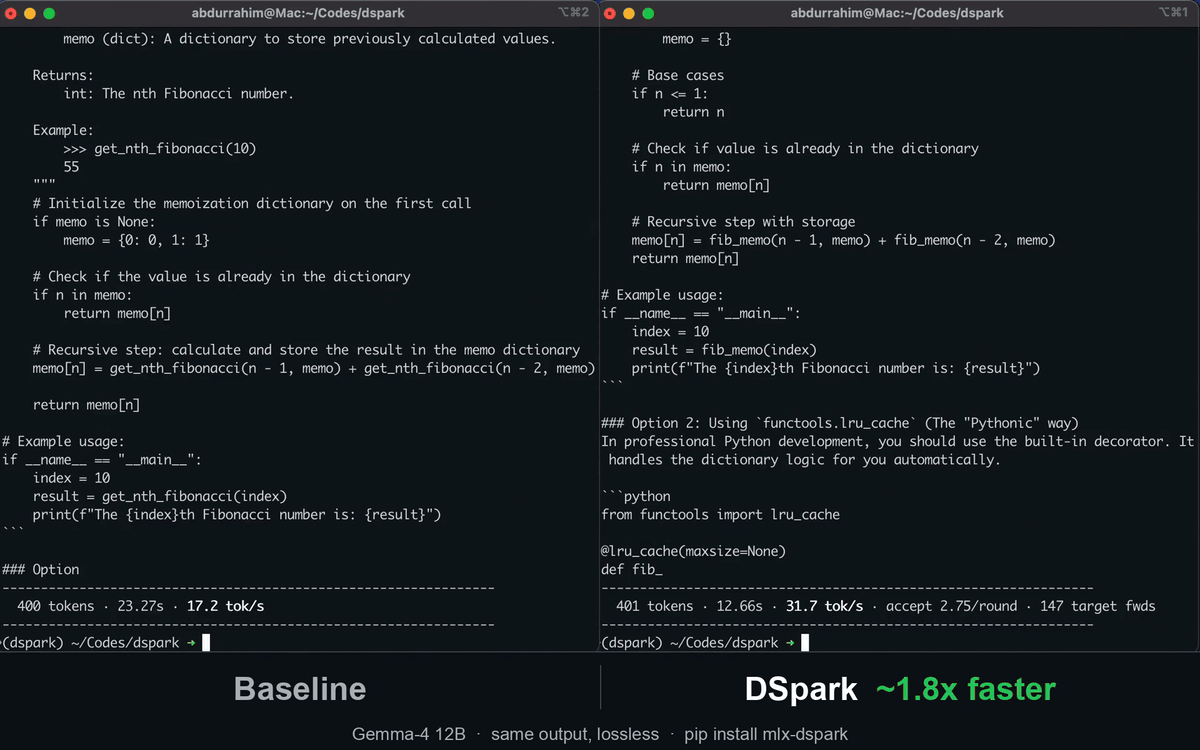
mlx-dspark runs two EAGLE-family speculative-decoding drafters natively on Apple Silicon: DeepSeek's DSpark (semi-autoregressive, from the DeepSpec codebase, used to accelerate DeepSeek-V4) and z-lab's DFlash (block diffusion). Both are lossless — the target verifies every token, so output is identical to normal decoding — and run under one verify loop, so you can serve them, script them, or benchmark them head-to-head.
What this is not: DeepSeek-V4 inference. The targets are dense models (Gemma-4, Qwen3) that DeepSeek published DSpark drafters for — so this runs their real drafter method on a Mac, but the model producing tokens is Gemma / Qwen, not V4. V4 Flash/Pro (MoE, batched serving) is DSpark's own headline use case.
Install
pip install mlx-dspark # or: uv pip install mlx-dspark
Apple Silicon + Python ≥ 3.10. Model weights download from the Hugging Face cache on first use (none bundled). No server framework is pulled in — the API server is built on the standard library.
Quickstart
You name the target model (--model, an HF repo or local path, exactly like mlx-lm); the matching
drafter is resolved automatically for known targets (see Models), or pass --drafter.
Serve an OpenAI-compatible API
mlx-dspark serve --model mlx-community/Qwen3-8B-8bit # → http://127.0.0.1:8080/v1
# add --mode dflash for the DFlash drafter · --mode baseline for plain decoding
# --no-thinking to silence Qwen3 <think> blocks by default · --api-key KEY to require auth
Then point any OpenAI client at it — the speculative speedup is transparent:
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:8080/v1", api_key="not-needed")
print(client.chat.completions.create(
model="Qwen3-8B-8bit",
messages=[{"role": "user", "content": "Explain rainbows briefly."}],
).choices[0].message.content)
For LM Studio / other tools: set the OpenAI base URL to http://127.0.0.1:8080/v1.
The server speaks the OpenAI API: POST /v1/chat/completions (streaming and non-streaming,
multi-turn), POST /v1/completions, GET /v1/models, GET /health, GET /metrics. It supports
temperature, top_p, top_k, max_tokens, stop, seed, tool calling (tools /
tool_calls), and a per-request thinking toggle (enable_thinking). Each response carries an
x_mlx_dspark block (accept length + tok/s) so the spec-decode gain is visible. Prefix caching is on
by default, so multi-turn chat doesn't re-prefill the conversation each turn (~13× faster follow-up turns
on a long shared context — see Prefix caching).
One-shot generation (CLI)
# downloads the drafter + instruct target on first run
mlx-dspark generate --model mlx-community/Qwen3-4B-8bit --prompt "Explain how rainbows form."
# baseline (plain target) vs dspark — same output, faster (record each, stack for a demo)
mlx-dspark generate --model mlx-community/Qwen3-4B-8bit --mode baseline --prompt "..." --max-new-tokens 400
mlx-dspark generate --model mlx-community/Qwen3-4B-8bit --mode dspark --prompt "..." --max-new-tokens 400
# z-lab DFlash drafter (--max-draft 0 = full 16-block; best on code/math)
mlx-dspark generate --model mlx-community/gemma-4-12B-it-8bit --mode dflash --max-draft 0 --prompt "Write a binary search."
# sampled (not greedy) — lossless w.r.t. the target at temperature T (dspark and dflash)
mlx-dspark generate --model mlx-community/Qwen3-4B-8bit --prompt "Write a short poem." --temperature 1.0 --top-p 0.95 --seed 0
python -m mlx_dspark … works too, and the old flat --prompt … form still maps to generate.
Python
from mlx_dspark import load_pair, speculative_generate
target, tok, drafter, cfg = load_pair("mlx-community/Qwen3-8B-8bit") # drafter auto-resolved
res = speculative_generate(target, tok, drafter, "Explain how rainbows form.")
print(res.text, res.mean_accept_len, res.tokens_per_sec)
from mlx_dspark import load_dflash_pair, dflash_generate # z-lab DFlash instead
target, tok, drafter, cfg = load_dflash_pair("mlx-community/gemma-4-12B-it-8bit")
res = dflash_generate(target, tok, drafter, "Write a binary search in Python.") # max_draft_tokens=None = full block
print(res.text, res.mean_accept_len, res.tokens_per_sec)
Models
Pass any target repo/path to --model; the matched drafter auto-resolves for the targets below
(quantization-agnostic — a -4bit / -8bit / -bf16 of the same model resolves the same drafter). For
anything else, add --drafter <repo>. Run mlx-dspark models to print this table.
target (--model) |
DSpark drafter (--mode dspark) |
DFlash drafter (--mode dflash) |
peak RAM |
|---|---|---|---|
mlx-community/Qwen3-4B-8bit |
deepseek-ai/dspark_qwen3_4b_block7 |
z-lab/Qwen3-4B-DFlash-b16 |
~8 GB |
mlx-community/Qwen3-8B-8bit |
deepseek-ai/dspark_qwen3_8b_block7 |
z-lab/Qwen3-8B-DFlash-b16 |
~11 GB |
mlx-community/gemma-4-12B-it-8bit |
deepseek-ai/dspark_gemma4_12b_block7 |
z-lab/gemma4-12B-it-DFlash |
~15 GB |
Peak RAM is measured on an M4 Pro (8-bit target + 4-bit drafter + KV cache); add headroom for macOS.
A 4-bit target (--model …-it-4bit) roughly halves the target's share (fits smaller Macs). Use the
matched instruct target the drafter was trained against — a base model drops acceptance sharply.
--drafter lets you run any other matched z-lab / DeepSpec checkpoint (e.g. Qwen3-14B) with no code change.
The legacy --family qwen3|gemma4 flags still work but are deprecated in favor of --model.
How it works
- DSpark — a parallel backbone (5 layers) consumes the target's hidden states (EAGLE3-style) and proposes a 7-token block at once; a rank-256 Markov head adds a cheap previous-token correction that kills "suffix decay"; a confidence head scores each position (optional adaptive block length).
- DFlash (
--mode dflash) — a block-diffusion drafter that denoises a whole 16-token block in one parallel pass and reuses the target's own embed/lm-head. Different trade-offs (see below). - The target verifies every token, so output is greedy-correct by construction (identical to plain
decoding up to floating-point tie-breaking).
--temperature > 0switches to lossless speculative sampling — an exact sample from the target at temperature T (with--top-p/--top-k).
The drafter loads 1:1 from the HF checkpoint and is 4-bit quantized by default (cheap to run each round; quantization doesn't change acceptance — that's set by the drafter↔target match).
Which target & drafter should I use?
The winner is model-dependent, not just content-dependent — it comes down to how expensive the target's verify step is:
| target (verify cost) | DSpark (--mode dspark, cap 2) |
DFlash (--mode dflash --max-draft 0) |
pick |
|---|---|---|---|
| Gemma-4 12B — expensive verify | 1.65× chat, ~1.9× code/math | ~2.1× code/math, ~1.0× chat | DFlash on code/math, DSpark on chat |
| Qwen3-8B — cheap verify | ~1.6× everywhere | ~0.9–1.1× (a wash) | DSpark |
| Qwen3-4B — cheapest verify | ~1.4× | modest | DSpark |
Rule of thumb: bigger / slower-verify target → DFlash's full block pays off on code/math; smaller / fast target → DSpark wins outright. For target precision: 8-bit is the sweet spot (best acceptance + quality); 4-bit gives the highest absolute throughput and fits smaller Macs but a smaller speedup ratio; bf16 is slower on M-series (verify dominates). The drafter stays 4-bit either way. Full numbers and the reasoning are in Benchmarks & deep dive.
Results at a glance
DSpark vs the official MLX tools (mlx_lm.generate / mlx_vlm.generate) on the same model, at its
cap=2 optimum (M4 Pro, warm, 8-bit instruct target, 4-bit drafter):
| target | accept len | baseline (official) | mlx-dspark | speedup |
|---|---|---|---|---|
| Gemma-4 12B | ~2.5 | 18.4 tok/s | ~30 tok/s | ~1.6× (≤2× on code/math) |
| Qwen3-8B | ~2.44 | 29.4 tok/s | ~47 tok/s | ~1.6× |
| Qwen3-4B | ~2.25 | 52.9 tok/s | ~73 tok/s | ~1.4× |
All paths produce identical output to plain decoding — they're just faster. These land in the DSpark paper's own band (60–85% per-user speedup in batched serving = ~1.6–1.85×); the "2–4×" figures elsewhere are other papers on datacenter GPUs. Why a Mac can't go much higher, the full DSpark-vs-DFlash head-to-head, and the cost model are below.
Prefix caching
The server keeps the target KV cache (and, for DSpark, the drafter context) from the previous turn and reuses the shared conversation prefix instead of re-prefilling it. On a ~750-token shared context this makes follow-up turns ~13× faster (measured: 87 ms vs 1132 ms). It's lossless to the same standard as the rest of the project (a warm turn differs from a cold one only at logit-margin≈0 ties) and invalidates itself on any error so it can't desync.
On by default for --mode dspark / baseline on dense targets (Qwen3). It's disabled for DFlash and for
Gemma-4 (whose sliding-window KV caches can't be safely rolled back to an arbitrary prefix) — those fall back
to a fresh prefill. Flags: --no-prefix-cache, and --prefix-cache-dir DIR + --prefix-cache-max-ram-mb N
to enable the optional SSD spill tier for very long contexts.
Benchmarks & deep dive
Everything below is for readers who want the numbers and the why. The sections above are enough to use it.
The Apple-Silicon speedup ceiling
Speculative decoding amortizes a memory-bound single-token decode across the K tokens verified in one
forward. On a datacenter GPU that arbitrage is huge (parallel verify is nearly free, so speedup ≈ acceptance
length). On an M-series chip it's much weaker — verify cost grows with the number of tokens (measured
≈ +14 ms/token for Gemma-4 12B, +1.5 ms/token for Qwen3-4B; multi-token verify drops out of MLX's fast
quantized GEMV path). With the cost model tok/s ≈ A / (drafter + 0.035 + slope·C) for accept length A
and draft cap C, even a perfect drafter accepting the whole 7-token block tops out around ~2.2× here.
The binding limiter is acceptance length (set by the drafter↔target match) — not drafter quantization
(4-bit / 8-bit / bf16 give identical acceptance; 4-bit is simply fastest). After a drafter-slice fix and the
cap=2 default, verify dominates (~76% of each round).
DSpark vs DFlash (head-to-head)
Three drafters from the same DeepSpec lineage, all EAGLE-family (a tiny drafter that consumes the target's hidden states): EAGLE3 is autoregressive (high quality, draft latency grows with block size); DFlash drafts a whole block in one pass (fast, but later positions collide — "suffix decay"); DSpark = DFlash's parallel backbone + a rank-256 Markov head that reinjects token-to-token dependency, fixing suffix decay for ~0.6 ms/round. This is the first MLX port of DSpark; it also runs z-lab's original DFlash (block diffusion, Chen et al., arXiv:2602.06036, MIT) through the same lossless loop.
Gemma-4 12B (it-8bit, M4 Pro, warm, greedy, 4 prompts/domain — accept / tok·s; greedy ≈ 17.3 tok/s):
| method | chat | code | math |
|---|---|---|---|
| DSpark (cap 2) | 2.45 / 28.5 | 2.78 / 32.8 | 2.86 / 32.4 |
| DFlash (cap 2) | 2.15 / 24.2 | 2.76 / 31.3 | 2.71 / 29.6 |
| DFlash (full 16) | 2.68 / 16.9 | 5.95 / 36.6 | 6.20 / 36.3 |
They're complementary, matching the paper's framing: DFlash's block-16 wins structured content on both axes (accept ~6.0 on code/math vs DSpark's block-7 ceiling ~2.8; ~2.1× throughput) because high acceptance amortizes the wide verify; DSpark's Markov head wins open chat (2.45 / 1.65×; DFlash's block never fills on unpredictable text — full-16 chat is a slight net loss).
But the winner flips on a smaller, cheap-verify target. Qwen3-8B-8bit (warm, greedy, 3 prompts/domain; greedy ≈ 28.8):
| method | chat | code | math |
|---|---|---|---|
| DSpark (cap 2) | 2.38 / 45.7 | 2.55 / 48.8 | 2.40 / 46.1 |
| DFlash (cap 2) | 1.99 / 33.8 | 2.22 / 37.0 | 2.11 / 35.7 |
| DFlash (full 16) | 2.19 / 21.1 | 2.94 / 27.6 | 2.66 / 25.5 |
Here DSpark wins everywhere (~1.6×) and DFlash's block advantage evaporates — full-16 is a net loss
(~0.9×) because the cheap verify makes the wide block cost more than it returns, and accept never climbs
(~2.9 on code vs 5.95 on the 12B). Cross-checked against z-lab's own optimized runner
dflash-mlx on the identical target+drafter: its baseline matches
ours (29.3 tok/s) and its DFlash is also a net loss / wash at 8B (0.92× code full-block, ~1.08× adaptive) —
even with its hand-written Metal verify kernels. So this is DFlash at this model scale on Apple Silicon,
not an artifact of our verify loop.
Per the paper (accept length, full block, temp=1.0), DSpark beats DeepSpec's DFlash by +16–18% and EAGLE3 by +27–31%; our greedy exact-match numbers are lower than the paper's temp=1.0 speculative-sampling numbers because greedy is the strictest possible accept rule (not a bug).
Target precision
Since verify dominates, target precision is a speed/quality knob:
| target | 8-bit (default) | 4-bit |
|---|---|---|
| Gemma-4 12B | greedy 17.5 → spec 30 tok/s (1.73×) | greedy 30.6 → spec 34–38 tok/s (1.1–1.25×) |
| Qwen3-4B | greedy 49.8 → spec 73 tok/s (1.45×) | greedy 82 → spec 96–103 tok/s (1.17–1.26×) |
8-bit for the biggest spec benefit + best quality; 4-bit for max absolute throughput or small RAM
(--model …-it-4bit). The drafter stays 4-bit; a bf16 target is not a win (verify roughly doubles).
Tuning
- DSpark —
--max-draft 2is the measured optimum for every target (default): verify cost grows per token and the marginal draft token rarely survives.--confidence-threshold 0.6truncates the block adaptively via the confidence head instead. - DFlash — use
--max-draft 0(full 16-block, its native point) on code/math, where acceptance reaches ~6; use a short cap on open chat, where the block doesn't fill and the full block is a net loss. - Sampling —
--temperature > 0(+--top-p/--top-k) is lossless w.r.t. the target at temperature T (the paper's §2.1 method). On M-series it's ≈ greedy speed (the extra acceptance lives in a tail a short cap never reaches) — it's a sampled-output feature, not a speed lever.
License
MIT — see LICENSE. An independent MLX port of the inference path of DeepSeek's DSpark drafter;
the z-lab DFlash drafter classes are vendored (MIT) with attribution in NOTICE. No model weights
are bundled.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mlx_dspark-0.1.0.tar.gz.
File metadata
- Download URL: mlx_dspark-0.1.0.tar.gz
- Upload date:
- Size: 6.3 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.11.14 {"installer":{"name":"uv","version":"0.11.14","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e9cbe89e99dd9d870f0368956c2595d5650f1a0bd879f880f6d5d2dd4cefda6a
|
|
| MD5 |
da91b3a91471e8553418adb1f1dec64d
|
|
| BLAKE2b-256 |
e402405ae9f61e19d0c4bac6559a982c734a736b76e6bcf566eff10be585bee0
|
File details
Details for the file mlx_dspark-0.1.0-py3-none-any.whl.
File metadata
- Download URL: mlx_dspark-0.1.0-py3-none-any.whl
- Upload date:
- Size: 50.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.11.14 {"installer":{"name":"uv","version":"0.11.14","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f60add85b94b3ba94315aa3d51ac82a0727f00724ae6a669d5710c6d1d363362
|
|
| MD5 |
2cf63e58e7052834ad147c3ebfec1519
|
|
| BLAKE2b-256 |
5394196a5f444acdcba9c31ad001951a458d530bb0b2f676f0e542ffca6c9008
|







