Preflight checks for LLM prototypes.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
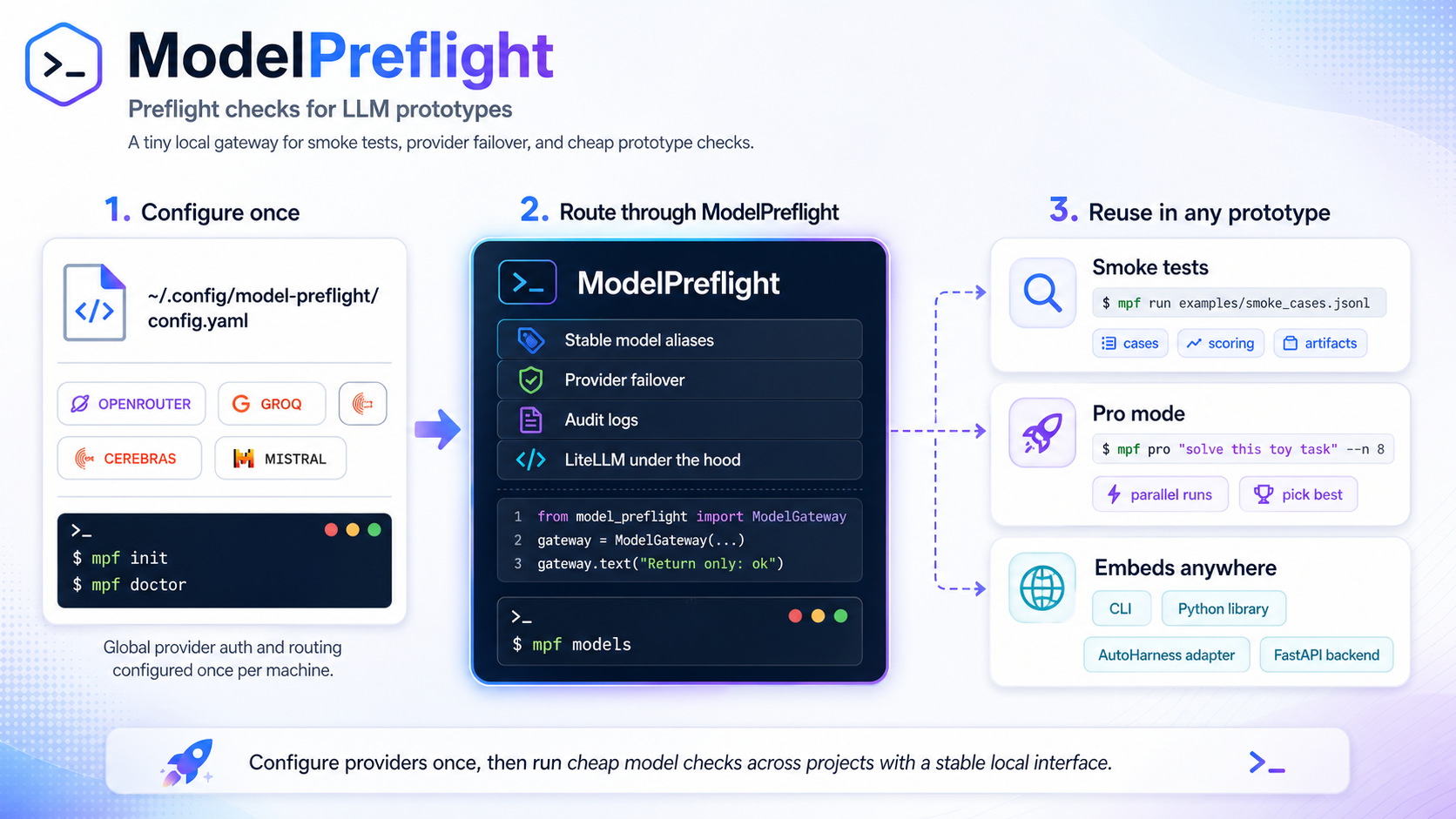
ModelPreflight
Preflight checks for LLM prototypes.
A tiny local gateway for LLM smoke tests, provider failover, and cheap prototype checks before you wire an LLM into something bigger.





| If you want to... | Start here |
|---|---|
| Get one green check quickly | 60-second start |
| Try it without keys | No-key demo path |
| Configure provider groups once | Machine-local config |
| Run project smoke cases | Smoke tests |
| Fan out a one-off prompt | Pro Mode |
| Use it as a Python helper | Library usage |
ModelPreflight keeps provider setup machine-local and keeps smoke cases project-local. It gives prototypes stable model-group aliases, simple failover, and JSONL audit logs without becoming a benchmark harness or hosted gateway.
60-second start
uvx model-preflight --help
# In a persistent tool or project environment:
uv tool install model-preflight
# or:
pipx install model-preflight
Pick one provider, set one key, and run one live check:
mpf init --provider nvidia
export NVIDIA_NIM_API_KEY=...
mpf doctor --live
mpf demo
Expected signal:
mpf init --provider nvidiawrites your machine-local config and printsnext: mpf doctor --live.mpf doctor --liveprints a deployments table, thenlive check ok: group=....mpf demoprints JSON with"passed": trueand an empty"failures": []list.
Add checks to a project:
cd my-project
mpf init-project
mpf run
Expected signal:
mpf init-projectwritesevals/smoke.jsonl, writes.model-preflight/README.md, and updates.gitignore.mpf runprints JSON results for the starter cases. Every passing case has"passed": true.- A failing case exits non-zero and includes strings under
"failures"so you know what drifted.
Both mpf and model-preflight are installed as console scripts.
ModelPreflight catches missing keys, broken provider routes, prompt formatting regressions, output-shape drift, accidental model/provider changes, and "this worked yesterday" prototype failures before you wire the LLM call into something larger.
No-key demo path
Use the minimal offline preset when you want to test the CLI and project workflow without a provider account:
mpf init --preset minimal
mpf doctor --live
mpf demo
mpf init-project
mpf run
What this proves:
- Config loading works without secrets.
- The CLI can run a live-style check through the offline echo provider.
- Project bootstrap works by creating
evals/smoke.jsonl. - Smoke scoring works when
mpf runreturns JSON where every case has"passed": true.
What it does not prove: remote provider auth, quota, latency, or model quality. Use the OpenRouter path below for that.
Machine-local config
ModelPreflight reads provider routes from ~/.config/model-preflight/config.yaml by default. Override the path with either --config or MODEL_PREFLIGHT_CONFIG.
mpf init --provider openrouter
mpf doctor
mpf models
Provider setup is discoverable from the CLI:
mpf providers list
mpf providers guide nvidia
mpf providers guide openrouter
mpf providers test nvidia
mpf providers test openrouter
NVIDIA Build / NIM is the primary high-capability open/open-weight endpoint option. OpenRouter is still the lowest-friction discovery option because one API key can route to many model providers through an OpenAI-compatible API.
Use either primary path:
mpf init --provider nvidia
export NVIDIA_NIM_API_KEY=...
mpf doctor --provider nvidia --live
mpf init --provider openrouter
export OPENROUTER_API_KEY=...
mpf doctor --provider openrouter --live
| Provider | Best for | Env var | Setup |
|---|---|---|---|
| NVIDIA Build / NIM | Primary high-capability open/open-weight endpoint pool | NVIDIA_NIM_API_KEY |
API keys |
| OpenRouter | One-key first run with broad model access | OPENROUTER_API_KEY |
Authentication docs |
| Groq | Fast repeated calls after first-run setup works | GROQ_API_KEY |
Groq console |
| Cerebras | Fast inference experiments when current dev-tier limits fit | CEREBRAS_API_KEY |
Cerebras inference docs |
| Mistral | First-party Mistral model-family smoke checks | MISTRAL_API_KEY |
Mistral API keys |
Secondary/overflow pool to add manually once the primary pool works: Google Gemini/Gemma, Cloudflare Workers AI, GitHub Models, Hugging Face Inference Providers, and SambaNova. These are documented in docs/PROVIDER_PRESETS.md, but not packaged as first-run presets yet because auth shape, model IDs, and free/dev limits are more account-specific.
The default config creates logical groups, then maps each group to one or more LiteLLM deployments:
router:
num_retries: 1
timeout_seconds: 60
default_group: free_reasoning
audit_jsonl: null
artifacts_dir: ~/.cache/model-preflight/artifacts
deployments:
- name: nvidia_nim_nemotron_3_super
provider: nvidia
group: free_reasoning
model: nvidia_nim/nvidia/nemotron-3-super-120b-a12b
api_key_env: NVIDIA_NIM_API_KEY
enabled: true
required: true
status: best_effort
setup_url: https://build.nvidia.com/settings/api-keys
rpm: 10
tier: reasoning
Provider presets are best-effort starter data, not authoritative claims about free availability. User-local config wins over bundled defaults, optional/disabled providers do not block first-run checks, and endpoint names, quotas, pricing, and behavior can change without this package knowing.
Smoke tests
Smoke cases are JSONL files owned by the project that is doing the prototype work.
{"id":"basic-ok","prompt":"Return only: ok","expected_substrings":["ok"]}
{"id":"avoid-word","prompt":"Answer yes without using the word nope","forbidden_substrings":["nope"]}
Run them with:
mpf run
# or:
mpf run path/to/smoke_cases.jsonl
mpf run prints JSON results and exits non-zero if any case fails.
Pro Mode
mpf pro fans out a one-off prompt, then synthesizes a final answer through a judge group.
mpf pro "Suggest three robust JSON schemas for this toy extraction task" --n 8
Defaults:
| Option | Default | Role |
|---|---|---|
--n |
8 |
number of sampled answers |
--sample-group |
free_fast |
fanout group |
--judge-group |
free_reasoning |
synthesis group |
Fanout multiplies live provider calls. Keep --n low while testing, use restricted provider keys where available, and review provider dashboards when running against paid endpoints.
Library usage
from model_preflight import ModelGateway, load_config, pro_mode
gateway = ModelGateway(load_config())
print(gateway.text("Return only: ok", group="free_reasoning"))
result = pro_mode(gateway, "Solve this toy puzzle", n=8)
print(result["final"])
The library API is intentionally thin:
load_config()reads the same machine-local config as the CLIModelGatewaywraps LiteLLM Router with stable group aliases and audit loggingpro_mode()runs fanout plus synthesis for one-off prototype prompts
Audit artifacts
By default, ModelPreflight writes audit logs under:
~/.cache/model-preflight/artifacts/audit.jsonl
Each live call should be traceable enough to debug provider drift: timestamp, logical group, resolved provider/model when available, prompt or case metadata, latency, token usage when available, and response id when available.
Non-goals
ModelPreflight is not a model leaderboard, a formal benchmark framework, a hosted inference gateway, a provider catalog authority, or proof that an endpoint is free, fast, or available today.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file model_preflight-0.1.7.tar.gz.
File metadata
- Download URL: model_preflight-0.1.7.tar.gz
- Upload date:
- Size: 1.5 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: uv/0.11.8 {"installer":{"name":"uv","version":"0.11.8","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ddeeb005c808fb7adc23a1d728b9cbdc88b976e2f4413d8cbb547ed4f39b613e
|
|
| MD5 |
b71ba6b215ff441c7589bbb808a68294
|
|
| BLAKE2b-256 |
159db43dc32a4ada40b3f339d95341e9f9e9fa0b58a57bb6cad3cabbb3db3665
|
File details
Details for the file model_preflight-0.1.7-py3-none-any.whl.
File metadata
- Download URL: model_preflight-0.1.7-py3-none-any.whl
- Upload date:
- Size: 19.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: uv/0.11.8 {"installer":{"name":"uv","version":"0.11.8","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
098798bba7fc198326e15a4bec4c0f104730494e8d5913af0307403abc633652
|
|
| MD5 |
9a04f7e181c7851ec9a3cc01921a6e70
|
|
| BLAKE2b-256 |
a9c447a3b30e71c3788466a204443b581996ee294a67fa2076842fc5c3c4e4af
|







