Modin: Make your pandas code run faster by changing one line of code.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers







Project description

Scale your pandas workflows by changing one line of code
Dev Community & Support |
Forums |
Socials |
Docs |
|---|---|---|---|
 |
 |






What is Modin?
Modin is a drop-in replacement for pandas. While pandas is single-threaded, Modin lets you instantly speed up your workflows by scaling pandas so it uses all of your cores. Modin works especially well on larger datasets, where pandas becomes painfully slow or runs out of memory. Also, Modin comes with the additional APIs to improve user experience.
By simply replacing the import statement, Modin offers users effortless speed and scale for their pandas workflows:

In the GIFs below, Modin (left) and pandas (right) perform the same pandas operations on a 2GB dataset. The only difference between the two notebook examples is the import statement.
 |
 |
|---|---|
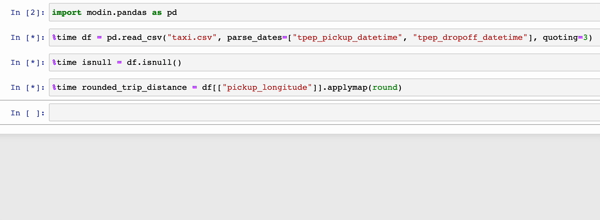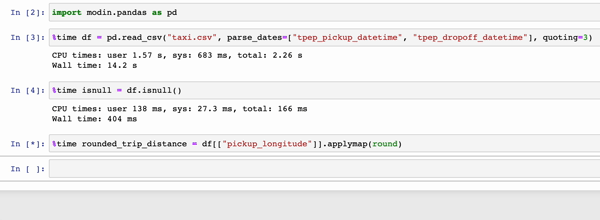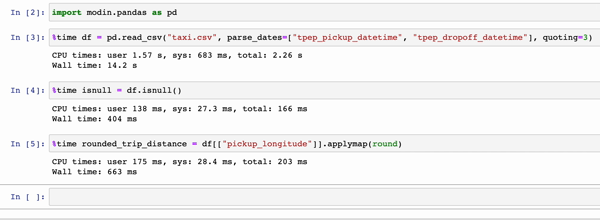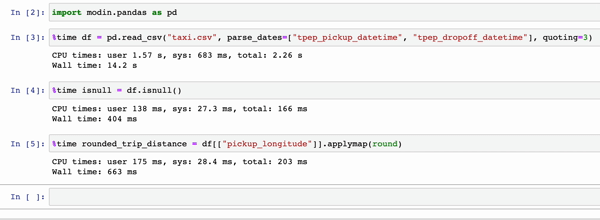 |
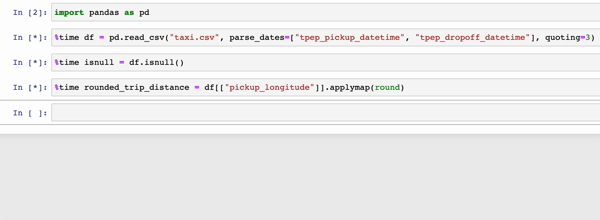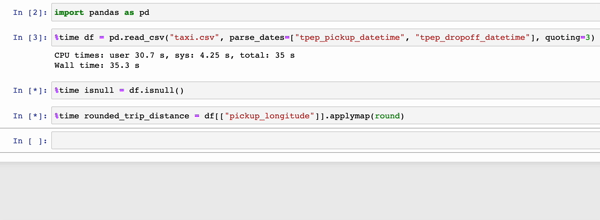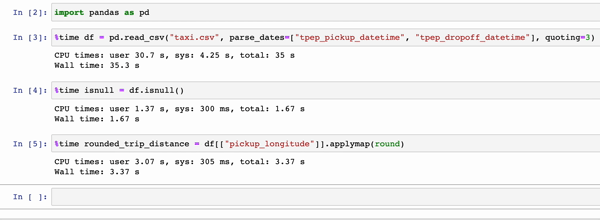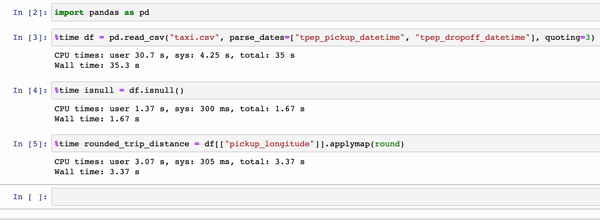 |
The charts below show the speedup you get by replacing pandas with Modin based on the examples above. The example notebooks can be found here. To learn more about the speedups you could get with Modin and try out some examples on your own, check out our 10-minute quickstart guide to try out some examples on your own!

Installation
From PyPI
Modin can be installed with pip on Linux, Windows and MacOS:
pip install "modin[all]" # (Recommended) Install Modin with Ray and Dask engines.
If you want to install Modin with a specific engine, we recommend:
pip install "modin[ray]" # Install Modin dependencies and Ray.
pip install "modin[dask]" # Install Modin dependencies and Dask.
pip install "modin[mpi]" # Install Modin dependencies and MPI through unidist.
To get Modin on MPI through unidist (as of unidist 0.5.0) fully working
it is required to have a working MPI implementation installed beforehand.
Otherwise, installation of modin[mpi] may fail. Refer to
Installing with pip
section of the unidist documentation for more details about installation.
Note: Since Modin 0.30.0 we use a reduced set of Ray dependencies: ray instead of ray[default].
This means that the dashboard and cluster launcher are no longer installed by default.
If you need those, consider installing ray[default] along with modin[ray].
Modin automatically detects which engine(s) you have installed and uses that for scheduling computation.
From conda-forge
Installing from conda forge using modin-all
will install Modin and three engines: Ray, Dask and
MPI through unidist.
conda install -c conda-forge modin-all
Each engine can also be installed individually (and also as a combination of several engines):
conda install -c conda-forge modin-ray # Install Modin dependencies and Ray.
conda install -c conda-forge modin-dask # Install Modin dependencies and Dask.
conda install -c conda-forge modin-mpi # Install Modin dependencies and MPI through unidist.
Note: Since Modin 0.30.0 we use a reduced set of Ray dependencies: ray-core instead of ray-default.
This means that the dashboard and cluster launcher are no longer installed by default.
If you need those, consider installing ray-default along with modin-ray.
Refer to Installing with conda section of the unidist documentation for more details on how to install a specific MPI implementation to run on.
To speed up conda installation we recommend using libmamba solver. To do this install it in a base environment:
conda install -n base conda-libmamba-solver
and then use it during istallation either like:
conda install -c conda-forge modin-ray --experimental-solver=libmamba
or starting from conda 22.11 and libmamba solver 22.12 versions:
conda install -c conda-forge modin-ray --solver=libmamba
Choosing a Compute Engine
If you want to choose a specific compute engine to run on, you can set the environment
variable MODIN_ENGINE and Modin will do computation with that engine:
export MODIN_ENGINE=ray # Modin will use Ray
export MODIN_ENGINE=dask # Modin will use Dask
export MODIN_ENGINE=unidist # Modin will use Unidist
If you want to choose the Unidist engine, you should set the additional environment
variable UNIDIST_BACKEND. Currently, Modin only supports MPI through unidist:
export UNIDIST_BACKEND=mpi # Unidist will use MPI backend
This can also be done within a notebook/interpreter before you import Modin:
import modin.config as modin_cfg
import unidist.config as unidist_cfg
modin_cfg.Engine.put("ray") # Modin will use Ray
modin_cfg.Engine.put("dask") # Modin will use Dask
modin_cfg.Engine.put('unidist') # Modin will use Unidist
unidist_cfg.Backend.put('mpi') # Unidist will use MPI backend
Note: You should not change the engine after your first operation with Modin as it will result in undefined behavior.
Which engine should I use?
On Linux, MacOS, and Windows you can install and use either Ray, Dask or MPI through unidist. There is no knowledge required to use either of these engines as Modin abstracts away all of the complexity, so feel free to pick either!
Pandas API Coverage
| pandas Object | Modin's Ray Engine Coverage | Modin's Dask Engine Coverage | Modin's Unidist Engine Coverage |
|---|---|---|---|
pd.DataFrame |
 |
|
|
pd.Series |
 |
|
|
pd.read_csv |
✅ | ✅ | ✅ |
pd.read_table |
✅ | ✅ | ✅ |
pd.read_parquet |
✅ | ✅ | ✅ |
pd.read_sql |
✅ | ✅ | ✅ |
pd.read_feather |
✅ | ✅ | ✅ |
pd.read_excel |
✅ | ✅ | ✅ |
pd.read_json |
✳️ | ✳️ | ✳️ |
pd.read_<other> |
✴️ | ✴️ | ✴️ |
More about Modin
For the complete documentation on Modin, visit our ReadTheDocs page.
Scale your pandas workflow by changing a single line of code.
Note: In local mode (without a cluster), Modin will create and manage a local (Dask or Ray) cluster for the execution.
To use Modin, you do not need to specify how to distribute the data, or even know how many cores your system has. In fact, you can continue using your previous pandas notebooks while experiencing a considerable speedup from Modin, even on a single machine. Once you've changed your import statement, you're ready to use Modin just like you would with pandas!
Faster pandas, even on your laptop
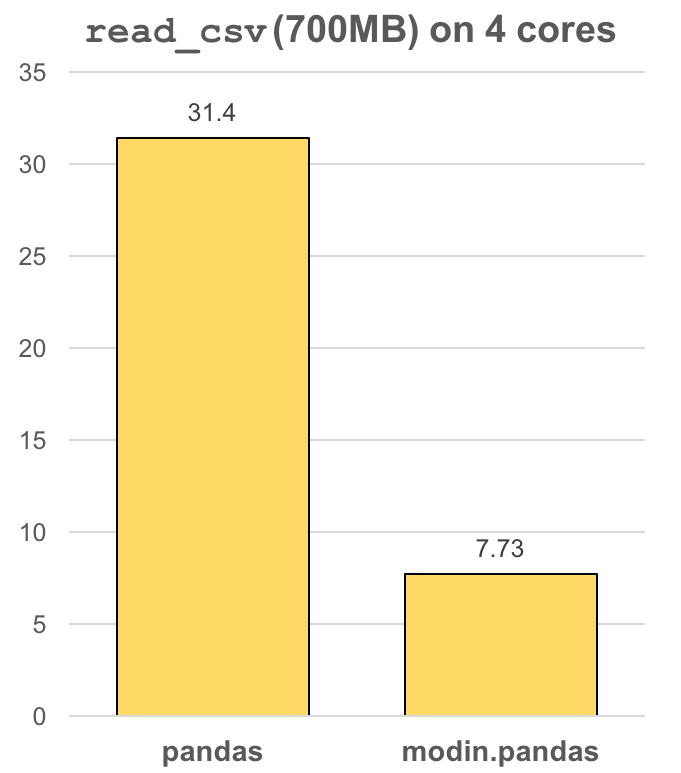
The modin.pandas DataFrame is an extremely light-weight parallel DataFrame.
Modin transparently distributes the data and computation so that you can continue using the same pandas API
while working with more data faster. Because it is so light-weight,
Modin provides speed-ups of up to 4x on a laptop with 4 physical cores.
In pandas, you are only able to use one core at a time when you are doing computation of
any kind. With Modin, you are able to use all of the CPU cores on your machine. Even with a
traditionally synchronous task like read_csv, we see large speedups by efficiently
distributing the work across your entire machine.
import modin.pandas as pd
df = pd.read_csv("my_dataset.csv")
Modin can handle the datasets that pandas can't
Often data scientists have to switch between different tools for operating on datasets of different sizes. Processing large dataframes with pandas is slow, and pandas does not support working with dataframes that are too large to fit into the available memory. As a result, pandas workflows that work well for prototyping on a few MBs of data do not scale to tens or hundreds of GBs (depending on the size of your machine). Modin supports operating on data that does not fit in memory, so that you can comfortably work with hundreds of GBs without worrying about substantial slowdown or memory errors. With cluster and out of core support, Modin is a DataFrame library with both great single-node performance and high scalability in a cluster.
Modin Architecture
We designed Modin's architecture to be modular so we can plug in different components as they develop and improve:

Other Resources
Getting Started with Modin
- Documentation
- 10-min Quickstart Guide
- Examples and Tutorials
- Videos and Blogposts
- Benchmarking Modin
Modin Community
Learn More about Modin
- Frequently Asked Questions (FAQs)
- Troubleshooting Guide
- Development Guide
- Modin is built on many years of research and development at UC Berkeley. Check out these selected papers to learn more about how Modin works:
- Flexible Rule-Based Decomposition and Metadata Independence in Modin (VLDB 2021)
- Dataframe Systems: Theory, Architecture, and Implementation (PhD Dissertation 2021)
- Towards Scalable Dataframe Systems (VLDB 2020)
Getting Involved
modin.pandas is currently under active development. Requests and contributions are welcome!
For more information on how to contribute to Modin, check out the Modin Contribution Guide.
License
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file modin-0.37.1.tar.gz.
File metadata
- Download URL: modin-0.37.1.tar.gz
- Upload date:
- Size: 925.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
40edbeafc2b8e07fda622b38475ec0b4d580cb8f0cdf9907f1c58c1d84b9a796
|
|
| MD5 |
59f7b317a0d72205a514554d4dd972e3
|
|
| BLAKE2b-256 |
833dae84a61a19f61e4a069c916426708b302edd73403a5653277cfe5f0adcff
|
Provenance
The following attestation bundles were made for modin-0.37.1.tar.gz:
Publisher:
publish-to-pypi.yml on modin-project/modin
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
modin-0.37.1.tar.gz -
Subject digest:
40edbeafc2b8e07fda622b38475ec0b4d580cb8f0cdf9907f1c58c1d84b9a796 - Sigstore transparency entry: 581346665
- Sigstore integration time:
-
Permalink:
modin-project/modin@bce3707443d525cdca5c50f9c5e65f2f82fcc882 -
Branch / Tag:
refs/tags/0.37.1 - Owner: https://github.com/modin-project
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-to-pypi.yml@bce3707443d525cdca5c50f9c5e65f2f82fcc882 -
Trigger Event:
push
-
Statement type:
File details
Details for the file modin-0.37.1-py3-none-any.whl.
File metadata
- Download URL: modin-0.37.1-py3-none-any.whl
- Upload date:
- Size: 1.2 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
afb96c4b1fc4953c6895f5376b49af765575ad6f4d948a7726055614777e7b90
|
|
| MD5 |
362942de0be6addfa0094d8fe10c4c19
|
|
| BLAKE2b-256 |
3998027653454863ee32379faa5b9242ab4e9540c4da2a9427d0ceaa5169478b
|
Provenance
The following attestation bundles were made for modin-0.37.1-py3-none-any.whl:
Publisher:
publish-to-pypi.yml on modin-project/modin
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
modin-0.37.1-py3-none-any.whl -
Subject digest:
afb96c4b1fc4953c6895f5376b49af765575ad6f4d948a7726055614777e7b90 - Sigstore transparency entry: 581346673
- Sigstore integration time:
-
Permalink:
modin-project/modin@bce3707443d525cdca5c50f9c5e65f2f82fcc882 -
Branch / Tag:
refs/tags/0.37.1 - Owner: https://github.com/modin-project
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish-to-pypi.yml@bce3707443d525cdca5c50f9c5e65f2f82fcc882 -
Trigger Event:
push
-
Statement type:







