MMG: Mosaic Multi-Grid A research-grade multi-agent gridworld environments for reproducible RL experiments

Project description
mosaic_multigrid
Multi-agent gridworld environments for reproducible RL experiments.
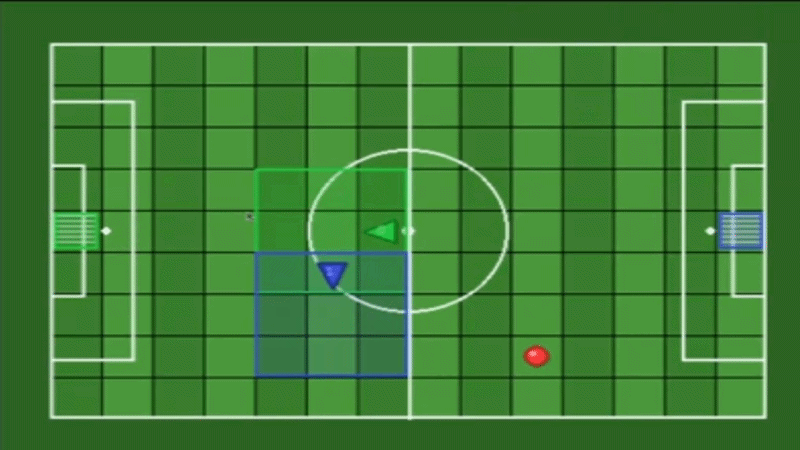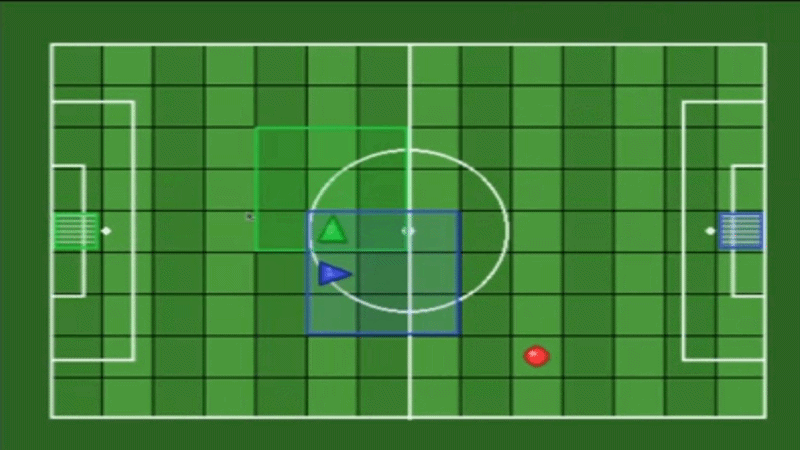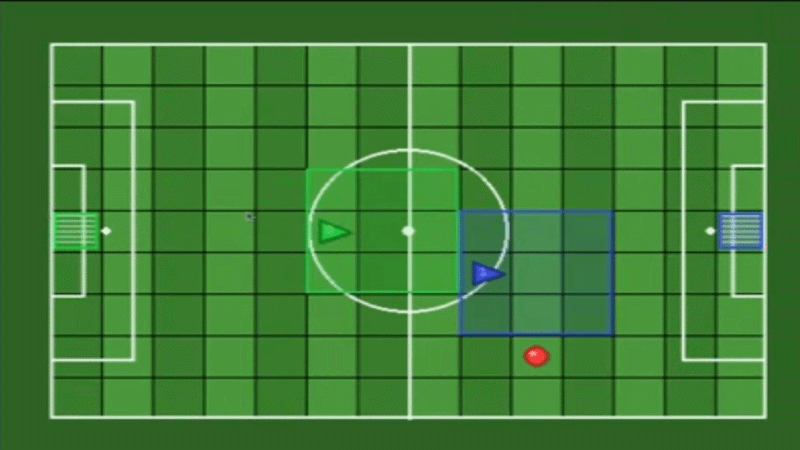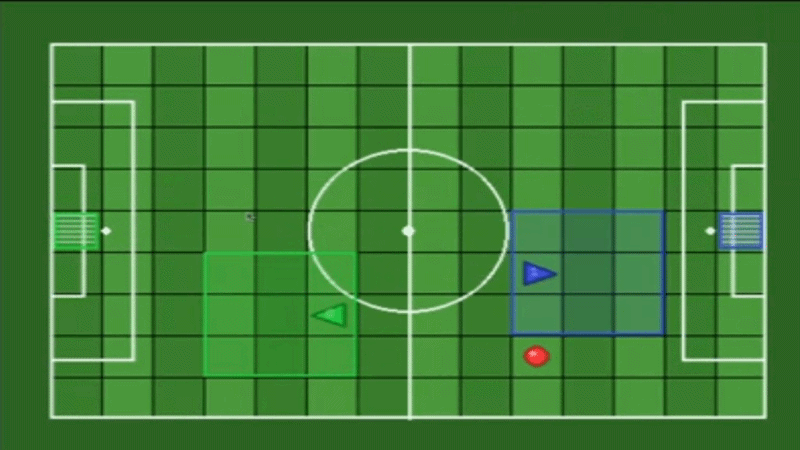
A maintained fork of gym-multigrid by Arnaud Fickinger (2020), modernized to the Gymnasium API with Numba JIT-accelerated observations, reproducible seeding.
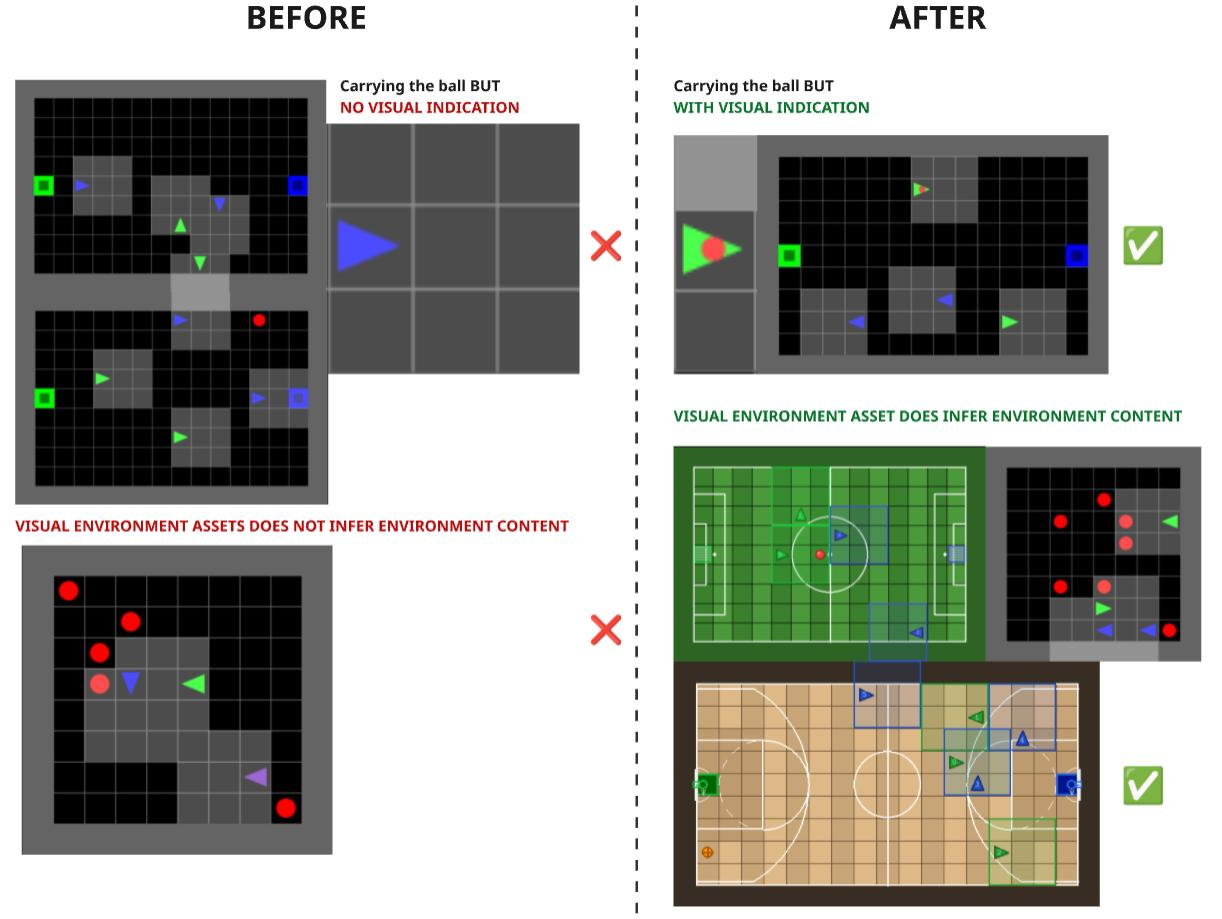
Design Philosophy: Best of Both Worlds
mosaic_multigrid = gym-multigrid game design + INI multigrid modern infrastructure
We kept the challenging partial observability (view_size=3) that makes Soccer/Collect interesting for competitive multi-agent research, while adopting modern API and optimizations from INI multigrid standards.
What We Kept from gym-multigrid (Fickinger 2020)
- Partial observability -
view_size=3forSoccerGame4HEnv10x15N2andCollectGameEnv(challenging team coordination) - Game mechanics - Ball passing, stealing, scoring, team rewards
- Research continuity - Comparable with original papers
What We Adopted from INI multigrid (2022+)
- Gymnasium 1.0+ API - Modern 5-tuple dict-keyed observations
- 3-channel encoding -
[type, color, state]format (not 6-channel) - Agent class design - Separate from WorldObj, cleaner architecture
- pygame rendering - Modern window system (not matplotlib)
- Modular structure - ~20 focused modules (not 1442-line monolith)
What We Built (Our Contributions)
- Reproducibility fix - Fixed critical global RNG bug
- Numba JIT optimization - 10-100x faster observation generation
- Comprehensive tests - 130+ tests covering all functionality
- Framework adapters - PettingZoo Parallel, AEC (Environment Agent Cycle) integration
- Observation wrappers - FullyObs, ImgObs, OneHot, SingleAgent, TeamObs (SMAC-style)
- TeamObs environments - SMAC-style teammate awareness for team coordination research
What Changed from Upstream: The Full Story
Showing how we combined the best of both packages:
| Aspect | gym-multigrid (Fickinger 2020) | INI multigrid (Oguntola 2023) | mosaic_multigrid (This Fork) |
|---|---|---|---|
| API | Old Gym 4-tuple, list-based | Gymnasium 5-tuple, dict-keyed | Gymnasium 5-tuple, dict-keyed (from INI) |
| Actions | 8 (still=0..done=7) | 7 (left=0..done=6) | 8 actions, noop=0..done=7 (noop restored for AEC compatibility) |
| Observations | (3, 3, 6) dict (Soccer) |
(7, 7, 3) dict (default) |
(3, 3, 3) dict (Soccer) |
| Encoding | 6 channels | 3 channels [type, color, state] | 3 channels (from INI) |
| view_size | 3 (Soccer/Collect) | 7 (default) | 3 (KEPT from gym-multigrid) for competitive challenge |
| Game Logic | Soccer, Collect, team rewards | Exploration tasks (no team games) | Soccer, Collect (from gym-multigrid) |
reset() |
List[obs] |
(Dict[obs], Dict[info]) |
(Dict[obs], Dict[info]) (from INI) |
step() |
(List[obs], ndarray, bool, dict) |
(Dict, Dict, Dict, Dict, Dict) |
5-tuple per-agent dicts (from INI) |
| Render | render(mode='human') param |
render_mode constructor param |
render_mode constructor (from INI) |
| Seeding | env.seed(42) + broken global RNG |
reset(seed=42) + self.np_random |
Fixed seeding (from INI) + bug fix (ours) |
| Window | matplotlib | pygame | pygame (from INI) |
| Performance | Pure Python loops | Pure Python | Numba JIT (ours, 10-100× faster) |
| Structure | 1442-line monolith | Modular package | ~20 focused modules (from INI) |
| Dependencies | gym>=0.9.6, numpy |
gymnasium, numpy, pygame |
+ numba, aenum (optimizations) |
| Tests | Basic test script | Unknown | 130 comprehensive tests (ours) |
| PettingZoo | None | Parallel only (ParallelEnv) | Parallel + AEC (ours) via pettingzoo.utils.conversions |
| Use Case | Multi-agent team research | Single-agent exploration | Multi-agent competitive with modern API |
Observation Space Notation: The format is (height, width, channels) where:
- gym-multigrid:
(3, 3, 6)= 3×3 grid with 6-channel encoding for Soccer/Collect - INI multigrid:
(7, 7, 3)= 7×7 grid with 3-channel [type, color, state] encoding (default) - mosaic_multigrid:
(3, 3, 3)= 3×3 grid (kept from gym-multigrid) + 3-channel encoding (from INI)
Legend:
- Bold in the mosaic_multigrid column = What we adopted or built
- Items from gym-multigrid: view_size=3, Soccer/Collect game mechanics
- Items from INI multigrid: Gymnasium API, 3-channel encoding, pygame, modular structure
- Our contributions: Reproducibility fix, Numba JIT, comprehensive tests, PettingZoo adapters
Bugs Fixed
- Reproducibility bug (critical):
step()usednp.random.permutation()(global RNG) for action ordering. Now usesself.np_random.random(size=N).argsort()to respect environment seeding. - No
render_mode: Constructor now acceptsrender_mode='rgb_array'orrender_mode='human', following Gymnasium convention. - Legacy 4-tuple:
step()returns Gymnasium 5-tuple(obs, rewards, terminated, truncated, info)with per-agent dicts.
Included Environments
SoccerGame (IndAgObs -- Recommended)
Team-based competitive environment with FIFA-style field rendering. Agents score by dropping the ball at the opposing team's goal. Features teleport passing, stealing with dual cooldown, ball respawn, and first-to-2-goals termination.
Recommended variant: SoccerGame4HIndAgObsEnv16x11N2 -- 4 agents (2v2), 16x11 grid (FIFA ratio), 1 ball, positive-only shared team reward, goal_scored_by tracking in info dict.
CollectGame (Individual Competition)
Individual competitive collection. 3 agents compete individually to collect the most balls.
Default variant: CollectGame3HEnv10x10N3 — 3 agents, 10×10 grid, 5 wildcard balls, zero-sum.
Enhanced variant: CollectGame3HEnhancedEnv10x10N3 — Natural termination when all balls collected (35× faster).
Collect 2v2 Game (Team-Based Collection)
Team-based competitive collection. 4 agents in 2 teams (2v2) compete to collect the most balls. Similar to Soccer but without goals — agents earn points directly by picking up balls. 7 balls ensures no draws!
Default variant: CollectGame4HEnv10x10N2 — 4 agents (2v2), 10×10 grid, 7 wildcard balls.
Soccer 1v1 (IndAgObs)
1v1 variant of the Soccer environment on the same 16x11 FIFA-style grid. Two agents (one per team) compete head-to-head. Teleport passing is a no-op (no teammates), making this a purely individual duel of ball control, stealing, and scoring. First to 2 goals wins.
IndAgObs variant: SoccerGame2HIndAgObsEnv16x11N2 -- 2 agents (1v1), 16x11 grid, 1 ball, zero_sum=True, max_steps=300.
Collect 1v1 (Team-Based Collection)
1v1 variant of the team-based Collect environment. Two agents on separate teams compete to collect 3 wildcard balls on a 10x10 grid. 3 balls (odd number) ensures no draws. Natural termination when all balls are collected.
IndAgObs variant (recommended): CollectGame2HIndAgObsEnv10x10N2 -- 2 agents (1v1), 10x10 grid, 3 balls, zero-sum, max_steps=200.
Base variant: CollectGame2HIndAgObsEnv10x10N2 — same configuration, IndAgObs variant recommended.
Solo Environments (New in v6.0.0)
Single-agent variants of Soccer and Basketball with no opponent on the field. Designed for curriculum pre-training where the agent learns ball pickup, navigation, and scoring mechanics before facing an opponent.
Why solo training? Training IPPO on the full 1v1 or 2v2 game suffers from five compounding problems:
- Sparse reward: on a 14x9 playable field, a random agent has negligible probability of completing the 6-step scoring chain (navigate to ball, face, pickup, navigate to goal, face, drop) in 200 steps
- Non-stationarity: the opponent's policy changes during training, so the agent's "environment" keeps shifting
- Observation poverty:
view_size=3covers only 7% of the soccer field; the agent spends most steps seeing empty floor - Zero-sum curriculum mismatch: Collect uses
zero_sum=True(rewards in [-1, +1]) while Soccer useszero_sum=False(rewards in [0, +1]); hot-swapping corrupts the critic baseline - Under-training: with ~26 scoring events in 4M steps, the gradient signal is too weak for reliable policy improvement
Solo variants address problems 1-2 directly (no opponent means higher scoring probability and no non-stationarity) and partially address problem 3 (no one to steal the ball, so the agent can practice the scoring chain repeatedly).
view_size is a runtime kwarg, no separate gymnasium IDs needed:
# Default: 3x3 partial view
env = gym.make('MosaicMultiGrid-Soccer-Solo-Green-IndAgObs-v1')
# Override: 7x7 partial view (38.9% field coverage on 16x11)
env = gym.make('MosaicMultiGrid-Soccer-Solo-Green-IndAgObs-v1', view_size=7)
Checkpoint deployment note: Green solo produces agent_0 with team_index=1 directly deployable as agent_0 in a 2-player game. Blue solo also produces agent_0 (only agent) but with team_index=2's checkpoint key remapping is needed when deploying as agent_1.
Inherited mechanics that become inert in solo:
- Teleport: passing resulktno teammates, drops to ground instead
- Stealing: no opponents on the field
- Steal cooldown: never triggered
- First-to-2-goals termination: still works (agent can score twice to end early)
BasketballGame (3v3 -- New in v4.0.0)
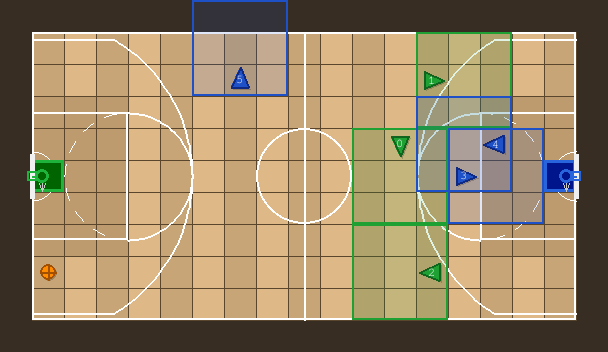
Team-based competitive basketball on a 19x11 grid (17x9 playable area). Agents score by dropping the ball at the opposing team's basket (goal on the baseline). Features teleport passing, stealing with dual cooldown, ball respawn, first-to-2-goals termination, and basketball-court rendering with three-point arcs, paint rectangles, and center circle.
IndAgObs variant: BasketballGame6HIndAgObsEnv19x11N3 — 6 agents (3v3), 19x11 grid, 1 ball, positive-only rewards, event tracking.
TeamObs variant: Basketball3v3TeamObsEnv — IndAgObs + SMAC-style teammate awareness (2 teammates per agent).
Registered Environments (v6.5.0)
All environments use v6.5.0 defaults: scoring +15.0, max_steps=300, zero_sum=True, ball provenance tracking, pass-chain cap, timeout penalty −1.0, proximity reward.
50 environments across 4 sports. Naming scheme:
MosaicMultiGrid-<Sport>-[Team-]<Format>-[ObsVariant-]v1
- Sport:
SSoccer ·BBBasketball ·AFAmericanFootball ·CCollect - Team:
GGreen-only ·BBlue-only — omitted for symmetric matchups - Format:
NvM(e.g. 1v0, 1v1, 2v2, 3v3) - ObsVariant:
IndAgObs·TeamObs— omitted for solo (1v0 / 0v1) envs
Soccer (S) — 16×11 grid

| Environment ID | Agents | Description |
|---|---|---|
MosaicMultiGrid-S-G-1v0-v1 |
1 | Solo Green — curriculum pre-training |
MosaicMultiGrid-S-B-0v1-v1 |
1 | Solo Blue — curriculum pre-training |
MosaicMultiGrid-S-1v1-IndAgObs-v1 |
2 | 1v1 competitive |
MosaicMultiGrid-S-2v2-IndAgObs-v1 |
4 | 2v2 competitive, independent 3×3 views |
MosaicMultiGrid-S-2v2-TeamObs-v1 |
4 | 2v2 + SMAC teammate awareness |
MosaicMultiGrid-S-3v3-IndAgObs-v1 |
6 | 3v3 competitive |
MosaicMultiGrid-S-3v3-TeamObs-v1 |
6 | 3v3 + SMAC teammate awareness |
MosaicMultiGrid-S-G-2v0-IndAgObs-v1 |
2 | 2 Green agents, cooperative |
MosaicMultiGrid-S-G-2v0-TeamObs-v1 |
2 | 2 Green + teammate obs |
MosaicMultiGrid-S-G-3v0-IndAgObs-v1 |
3 | 3 Green agents, cooperative |
MosaicMultiGrid-S-G-3v0-TeamObs-v1 |
3 | 3 Green + teammate obs |
MosaicMultiGrid-S-B-0v2-IndAgObs-v1 |
2 | 2 Blue agents, cooperative |
MosaicMultiGrid-S-B-0v2-TeamObs-v1 |
2 | 2 Blue + teammate obs |
MosaicMultiGrid-S-B-0v3-IndAgObs-v1 |
3 | 3 Blue agents, cooperative |
MosaicMultiGrid-S-B-0v3-TeamObs-v1 |
3 | 3 Blue + teammate obs |
Basketball (BB) — 19×11 grid

| Environment ID | Agents | Description |
|---|---|---|
MosaicMultiGrid-BB-G-1v0-v1 |
1 | Solo Green — curriculum pre-training |
MosaicMultiGrid-BB-B-0v1-v1 |
1 | Solo Blue — curriculum pre-training |
MosaicMultiGrid-BB-1v1-IndAgObs-v1 |
2 | 1v1 competitive |
MosaicMultiGrid-BB-1v1-TeamObs-v1 |
2 | 1v1 + teammate obs |
MosaicMultiGrid-BB-2v2-IndAgObs-v1 |
4 | 2v2 competitive |
MosaicMultiGrid-BB-2v2-TeamObs-v1 |
4 | 2v2 + teammate obs |
MosaicMultiGrid-BB-3v3-IndAgObs-v1 |
6 | 3v3 competitive |
MosaicMultiGrid-BB-3v3-TeamObs-v1 |
6 | 3v3 + teammate obs |
MosaicMultiGrid-BB-G-2v0-IndAgObs-v1 |
2 | 2 Green, cooperative |
MosaicMultiGrid-BB-G-2v0-TeamObs-v1 |
2 | 2 Green + teammate obs |
MosaicMultiGrid-BB-G-3v0-IndAgObs-v1 |
3 | 3 Green, cooperative |
MosaicMultiGrid-BB-G-3v0-TeamObs-v1 |
3 | 3 Green + teammate obs |
MosaicMultiGrid-BB-B-0v2-IndAgObs-v1 |
2 | 2 Blue, cooperative |
MosaicMultiGrid-BB-B-0v2-TeamObs-v1 |
2 | 2 Blue + teammate obs |
MosaicMultiGrid-BB-B-0v3-IndAgObs-v1 |
3 | 3 Blue, cooperative |
MosaicMultiGrid-BB-B-0v3-TeamObs-v1 |
3 | 3 Blue + teammate obs |
American Football (AF) — 16×11 grid

| Environment ID | Agents | Description |
|---|---|---|
MosaicMultiGrid-AF-G-1v0-v1 |
1 | Solo Green — curriculum pre-training |
MosaicMultiGrid-AF-B-0v1-v1 |
1 | Solo Blue — curriculum pre-training |
MosaicMultiGrid-AF-1v1-IndAgObs-v1 |
2 | 1v1 competitive |
MosaicMultiGrid-AF-2v2-IndAgObs-v1 |
4 | 2v2 competitive, independent 3×3 views |
MosaicMultiGrid-AF-2v2-TeamObs-v1 |
4 | 2v2 + SMAC teammate awareness |
MosaicMultiGrid-AF-3v3-IndAgObs-v1 |
6 | 3v3 competitive |
MosaicMultiGrid-AF-3v3-TeamObs-v1 |
6 | 3v3 + teammate obs |
MosaicMultiGrid-AF-G-2v0-IndAgObs-v1 |
2 | 2 Green, cooperative |
MosaicMultiGrid-AF-G-2v0-TeamObs-v1 |
2 | 2 Green + teammate obs |
MosaicMultiGrid-AF-G-3v0-IndAgObs-v1 |
3 | 3 Green, cooperative |
MosaicMultiGrid-AF-G-3v0-TeamObs-v1 |
3 | 3 Green + teammate obs |
MosaicMultiGrid-AF-B-0v2-IndAgObs-v1 |
2 | 2 Blue, cooperative |
MosaicMultiGrid-AF-B-0v2-TeamObs-v1 |
2 | 2 Blue + teammate obs |
MosaicMultiGrid-AF-B-0v3-IndAgObs-v1 |
3 | 3 Blue, cooperative |
MosaicMultiGrid-AF-B-0v3-TeamObs-v1 |
3 | 3 Blue + teammate obs |
Collect (C) — 10×10 grid
| Environment ID | Agents | Description |
|---|---|---|
MosaicMultiGrid-C-IndAgObs-v1 |
3 | 3-agent individual competition |
MosaicMultiGrid-C-1v1-IndAgObs-v1 |
2 | 1v1 team collection, 3 balls (no draws) |
MosaicMultiGrid-C-2v2-IndAgObs-v1 |
4 | 2v2 team collection, 7 balls (no draws) |
MosaicMultiGrid-C-2v2-TeamObs-v1 |
4 | 2v2 + SMAC-style teammate awareness |
Critical Bugs Fixed
Soccer Environment:
- Bug: Ball disappears after scoring and never respawns ->
FIXED:Ball respawns at random location - Bug: No natural termination (always runs 10,000 steps) ->
FIXED:First team to 2 goals wins - Bug: Agents can't see who is carrying ball ->
FIXED:STATE channel encoding + visual overlay - Bug: Infinite stealing exploit (no cooldown) ->
FIXED:10-step dual cooldown for both stealer and victim
Collect Environment:
- Bug: No termination signal when all balls collected (wastes 95% of computation) ->
FIXED:termination signal emitted when done - Result: 35× faster training (300 vs 10,000 steps per episode)
TeamObs Environments (v4.0.0) -- SMAC-Style Teammate Awareness
For team coordination research, TeamObs variants add structured teammate features to each agent's observation dict. This follows the standard MARL observation augmentation pattern established by SMAC (Samvelyan et al., 2019).
Why TeamObs?
On a 16x11 field (Soccer) or 10x10 field (Collect) with view_size=3, each
agent sees only 7-9% of the grid. Teammates are almost never visible in
the 3x3 local window. Without TeamObs:
- Passing is blind (teleport to random teammate, no position knowledge)
- Agents cannot coordinate coverage (both may search the same area)
- Team strategies are limited to independent exploration
With TeamObs, each agent receives its local view unchanged, plus:
| Feature | Shape | Description |
|---|---|---|
teammate_positions |
(N, 2) int64 | Relative (dx, dy) from self to each teammate |
teammate_directions |
(N,) int64 | Direction each teammate faces (0-3) |
teammate_has_ball |
(N,) int64 | 1 if teammate carries ball, 0 otherwise |
Where N = number of teammates per agent (1 in 2v2 environments, 2 in 3v3 Basketball).
Design Rationale
This follows the observation augmentation pattern from:
Samvelyan, M., Rashid, T., de Witt, C. S., et al. (2019). "The StarCraft Multi-Agent Challenge." CoRR, abs/1902.04043.
In SMAC, each agent receives its local view plus structured ally features (relative positions, health, unit type). We adapt this for gridworld environments. Teammate features are environment-level observation augmentation -- the RL algorithm decides what to do with the extra information.
Not applicable to: MosaicMultiGrid-Collect-IndAgObs-v1 (3 agents, each
on its own team with agents_index=[1,2,3], so N=0 teammates).
Documentation
- FOOTBALL.md: Full Soccer environment analysis, reward shaping, TeamObs design rationale, SMAC citation
- BASKETBALL.md: Basketball 3v3 environment, reward ladder, court layout
- AMERICAN_FOOTBALL.md: American Football environments, end zone scoring, reward shaping
Installation
From PyPI (recommended)
pip install mosaic-multigrid
From source
git clone https://github.com/Abdulhamid97Mousa/mosaic_multigrid.git
cd mosaic_multigrid
pip install -e .
Partial Observability
Agents have limited field of view! We use view_size=3 (from gym-multigrid) for competitive team games. This creates challenging coordination problems where agents can't see the entire field.
Why view_size=3?
We kept the small view size from gym-multigrid for research continuity:
- Challenging - Forces team coordination and communication
- Realistic - Agents can't see everything (fog of war)
- Research proven - Comparable with Fickinger et al. (2020)
We adopted modern infrastructure from INI multigrid:
- Gymnasium API, 3-channel encoding, pygame rendering, Numba JIT
Visual Comparison
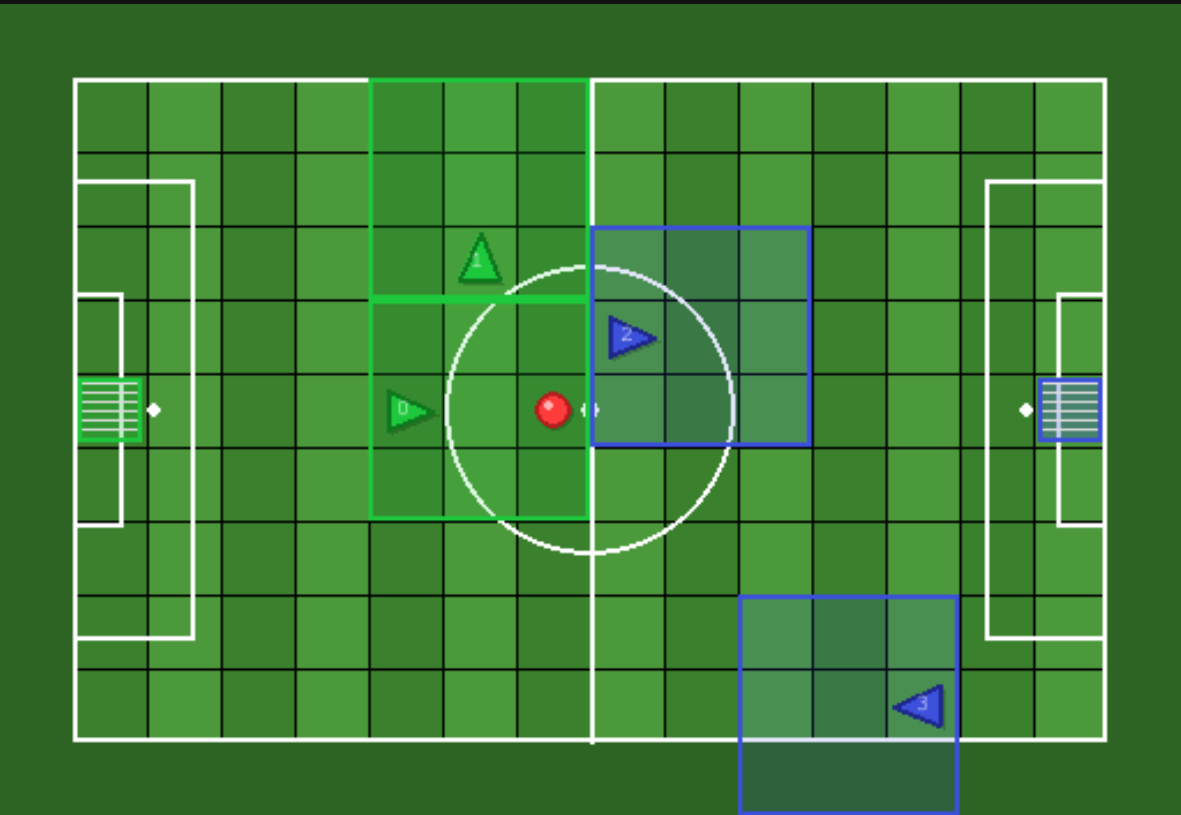
Agent View Size
Each agent has limited perception - they only see a local grid around them, not the entire environment.
Default View: 3×3 (mosaic_multigrid — Competitive)
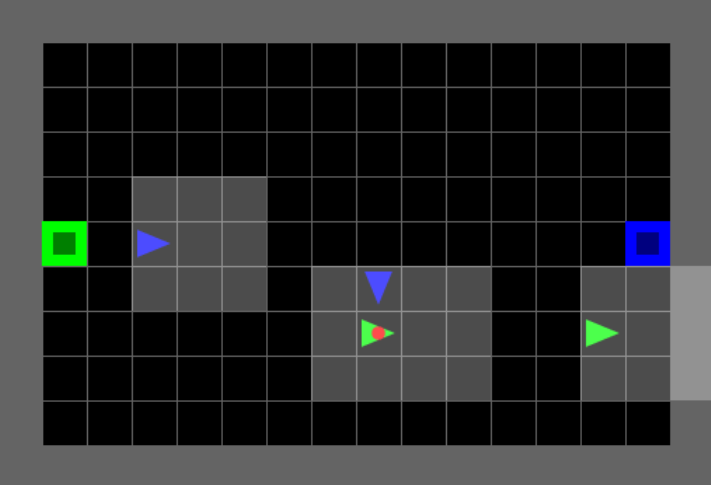
Each agent sees only a 3×3 local window around itself. Coverage: 9 cells. Forward: 2 tiles. Sides: 1 tile each.
Note: With view_size=3, agents typically cannot see the ball, goals, or teammates — forcing team coordination strategies.
View Rotation
The view rotates with the agent! The agent is always at the bottom-center, facing "up" in its own reference frame.



Configurable View Size
from mosaic_multigrid.envs import SoccerGameEnv
# Default: 3×3 (competitive challenge)
env = SoccerGameEnv(view_size=3, ...)
obs, _ = env.reset()
print(obs[0]['image'].shape) # (3, 3, 3)
# Match INI multigrid: 7×7 (easier)
env = SoccerGameEnv(view_size=7, ...)
obs, _ = env.reset()
print(obs[0]['image'].shape) # (7, 7, 3)
Observation Format (Enhanced Multi-Agent Encoding)
obs[agent_id]['image']shape:(view_size, view_size, 3)- Channel 0: Object TYPE (wall, ball, goal, agent, etc.)
- Channel 1: Object COLOR (red, blue, green team colors, etc.)
- Channel 2: Object STATE - Context-dependent encoding:
- For doors: 0=open, 1=closed, 2=locked (standard MiniGrid)
- For agents: 0-3 OR 100-103
0-3: Agent direction (right/down/left/up) when NOT carrying ball100-103: Agent direction + ball carrying flag (e.g., 101 = down + has ball)
- For other objects: 0 (unused)
obs[agent_id]['direction']: int (0=right, 1=down, 2=left, 3=up)obs[agent_id]['mission']: Mission string
The agent is always at the bottom-center of its view, looking forward. The view rotates with the agent's direction.
Ball Carrying Observability Enhancement
Key Feature: Agents can now see when other agents are carrying the ball!
This solves a critical observability limitation in the original 3-channel encoding:
# Example: Red agent observing Green agent with ball
obs[red_agent]['image'][1, 0, :] = [Type.agent, Color.green, 101]
# ↑
# STATE=101 means: facing DOWN + HAS BALL!
# Decoding:
has_ball = (state >= 100) # True
direction = state % 100 # 1 (down)
Why this works:
- Soccer and Collect have NO doors (door states 0-2 are unused)
- We repurpose the unused STATE channel space with offset 100
- No conflicts: door states (0-2), agent direction (0-3), agent+ball (100-103) are all separate
- Zero memory overhead - still 3 channels, still uint8 values
Before this fix:
- Agents could NOT see if others had the ball
- Required memory architectures (LSTM) to track ball possession
- Made stealing/defense strategies nearly impossible
After this fix:
- Agents CAN see who has the ball in their view
- Enables reactive defense strategies without memory
- Faster training, better decision-making
See:See PARTIAL_OBSERVABILITY.md for detailed visual diagrams and comparison with INI multigrid.
Reproducibility
# Same seed → identical trajectories (reproducibility bug is fixed)
for trial in range(2):
env = SoccerGame4HEnv10x15N2(render_mode='rgb_array')
obs, _ = env.reset(seed=42)
for step in range(100):
actions = {i: 2 for i in range(4)} # all forward
obs, *_ = env.step(actions)
# obs will be identical across trials
Episode Termination & Truncation
Understanding when and how episodes end is crucial for training RL agents. Following the Gymnasium API standard, MOSAIC multigrid distinguishes between terminated (natural end condition achieved) and truncated (time limit reached).
Terminology
- Terminated: Episode ends naturally when the goal/objective is achieved (e.g., reaching a goal cell, achieving a win condition)
- Truncated: Episode ends due to reaching the maximum step limit without achieving the objective
- max_steps: Maximum number of environment steps before truncation (default: 10,000 for all MOSAIC games)
Environment-Specific Criteria
Soccer Enhanced (MosaicMultiGrid-Soccer-2v2-IndAgObs-v1) RECOMMENDED
| Criterion | Condition |
|---|---|
| Terminated | When any team scores 2 goals (first-to-win) |
| Truncated | When max_steps >= 200 (configurable) |
| Winning Condition | First team to score goals_to_win (default: 2) wins |
| Scoring Mechanism | Drop ball at opponent's ObjectGoal: +1 shared to scoring team (positive-only, no penalty to opponents) |
| Event Tracking | goal_scored_by, passes_completed, steals_completed in info dict for credit assignment |
| Ball Respawn | Ball respawns at random location after each goal |
| Episode Length | Variable (terminates when team wins, or truncates at 200 steps) |
| Cooldown | 10-step dual cooldown on stealing (both stealer and victim) |
Design rationale: Enhanced Soccer provides natural termination when a team wins, significantly reducing training time (~50x faster). Ball respawns after each goal to keep gameplay continuous. Rewards are positive-only (following SMAC convention), with goal_scored_by and passes_completed metadata for credit assignment and assist chain analysis.
env = gym.make('MosaicMultiGrid-Soccer-2v2-IndAgObs-v1')
obs, _ = env.reset(seed=42)
for step in range(200):
actions = {i: agent_policy(obs[i]) for i in range(4)}
obs, rewards, terminated, truncated, info = env.step(actions)
if terminated[0]: #Team scored 2 goals!
# Determine winner from final rewards
team1_total = sum(rewards[i] for i in [0, 1])
team2_total = sum(rewards[i] for i in [2, 3])
winner = "Team 1 (Green)" if team1_total > 0 else "Team 2 (Red)"
print(f"{winner} wins! Episode finished in {step} steps")
break
if truncated[0]: # Time limit reached
print(f"Time limit reached. Determine winner by cumulative score.")
break
Collect (MosaicMultiGrid-Collect-IndAgObs-v1)
| Criterion | Condition |
|---|---|
| Terminated | When all 5 balls are collected |
| Truncated | When max_steps = 300 (configurable) |
| Winning Condition | Agent with highest cumulative reward when episode ends |
| Scoring Mechanism | Pickup wildcard ball (index=0): +1 to agent, -1 to all other agents (zero-sum) |
| Episode Length | Variable (100-300 steps typically, terminates when all balls collected) |
| Training Speedup | 35× faster than original (300 vs 10,000 steps) |
Design rationale: Enhanced Collect terminates naturally when all balls are collected, eliminating the bug where episodes ran for 10,000 steps with nothing to do. This creates a 35× training speedup and provides clear termination signals for RL agents.
env = gym.make('MosaicMultiGrid-Collect-IndAgObs-v1')
obs, _ = env.reset(seed=42)
cumulative_rewards = {i: 0 for i in range(3)}
for step in range(300):
actions = {i: agent_policy(obs[i]) for i in range(3)}
obs, rewards, terminated, truncated, info = env.step(actions)
for i in range(3):
cumulative_rewards[i] += rewards[i]
if terminated[0]: #All 5 balls collected!
winner = max(cumulative_rewards, key=cumulative_rewards.get)
print(f"Agent {winner} wins! Episode finished in {step} steps")
print(f"Final scores: {cumulative_rewards}")
break
Collect 2v2 (MosaicMultiGrid-Collect-2v2-IndAgObs-v1) RECOMMENDED
| Criterion | Condition |
|---|---|
| Terminated | When all 7 balls are collected |
| Truncated | When max_steps = 400 (configurable) |
| Winning Condition | Team with highest cumulative score when episode ends |
| Scoring Mechanism | Pickup wildcard ball: +1 to entire team, -1 to opponent team (zero-sum) |
| Episode Length | Variable (150-400 steps typically) |
| Ball Count | 7 balls (ODD number prevents draws!) |
| Team Assignment | agents_index=[1, 1, 2, 2] → Team 1 (agents 0,1) vs Team 2 (agents 2,3) |
env = gym.make('MosaicMultiGrid-Collect-2v2-IndAgObs-v1')
obs, _ = env.reset(seed=42)
for step in range(400):
actions = {i: agent_policy(obs[i]) for i in range(4)}
obs, rewards, terminated, truncated, info = env.step(actions)
if terminated[0]: #All 7 balls collected!
team1_score = sum(rewards[i] for i in [0, 1])
team2_score = sum(rewards[i] for i in [2, 3])
winner = "Team 1 (Green)" if team1_score > team2_score else "Team 2 (Red)"
print(f"{winner} wins!")
break
Soccer 1v1 (MosaicMultiGrid-Soccer-1v1-IndAgObs-v1)
| Criterion | Condition |
|---|---|
| Terminated | When any agent scores 2 goals (first-to-win) |
| Truncated | When max_steps >= 200 (configurable) |
| Winning Condition | First agent to score goals_to_win (default: 2) wins |
| Scoring Mechanism | Drop ball at opponent's goal: +1 to scorer (positive-only, no penalty to opponent) |
| Ball Respawn | Ball respawns at random location after each goal |
| Episode Length | Variable (terminates when agent wins, or truncates at 200 steps) |
| Passing | Teleport pass is a no-op (no teammates) -- drop always places ball on ground |
env = gym.make('MosaicMultiGrid-Soccer-1v1-IndAgObs-v1')
obs, _ = env.reset(seed=42)
for step in range(200):
actions = {i: agent_policy(obs[i]) for i in range(2)}
obs, rewards, terminated, truncated, info = env.step(actions)
if terminated[0]: # An agent scored 2 goals!
winner = "Agent 0 (Green)" if rewards[0] > 0 else "Agent 1 (Red)"
print(f"{winner} wins! Episode finished in {step} steps")
break
if truncated[0]: # Time limit reached
print(f"Time limit reached. Determine winner by cumulative score.")
break
Collect 1v1 (MosaicMultiGrid-Collect-1v1-IndAgObs-v1)
| Criterion | Condition |
|---|---|
| Terminated | When all 3 balls are collected |
| Truncated | When max_steps = 200 (configurable) |
| Winning Condition | Agent with highest cumulative reward when episode ends |
| Scoring Mechanism | Pickup wildcard ball: +1 to agent, -1 to opponent (zero-sum) |
| Episode Length | Variable (terminates when all 3 balls collected, or truncates at 200 steps) |
| Ball Count | 3 balls (ODD number prevents draws!) |
| Team Assignment | agents_index=[1, 2] -- each agent is its own team |
env = gym.make('MosaicMultiGrid-Collect-1v1-IndAgObs-v1')
obs, _ = env.reset(seed=42)
cumulative_rewards = {i: 0 for i in range(2)}
for step in range(200):
actions = {i: agent_policy(obs[i]) for i in range(2)}
obs, rewards, terminated, truncated, info = env.step(actions)
for i in range(2):
cumulative_rewards[i] += rewards[i]
if terminated[0]: # All 3 balls collected!
winner = max(cumulative_rewards, key=cumulative_rewards.get)
print(f"Agent {winner} wins! Episode finished in {step} steps")
print(f"Final scores: {cumulative_rewards}")
break
Comparison with MiniGrid
MiniGrid environments typically use both termination and truncation:
- Terminated: When agent reaches the green goal square (
step_on_goal = True) - Truncated: When
max_stepsreached (default varies: 100-1000 steps) - Episode length: Variable (ends as soon as goal is reached)
MOSAIC multigrid uses natural termination (v6.5.0+):
- Terminated: When a team scores
goals_to_win(default: 2) — episode ends early - Truncated: When
max_steps = 300(configurable) is reached without a winner - Episode length: Variable — early termination on win, timeout penalty −1.0 discourages stalling
- Rationale: Natural termination gives a clear win signal; timeout penalty prevents "do nothing" Nash equilibria
Implementation Details (base.py)
def step(self, actions):
self.step_count += 1
rewards = self.handle_actions(actions)
observations = self.gen_obs()
# Termination: check agent-level terminated flags
# (Never set in Soccer/Collect - always False)
terminations = dict(enumerate(self.agent_states.terminated))
# Truncation: check time limit
truncated = self.step_count >= self.max_steps
truncations = dict(enumerate(repeat(truncated, self.num_agents)))
return observations, rewards, terminations, truncations, info
Soccer and Collect environments never call on_success() or on_failure() callbacks, so agent.state.terminated remains False throughout the episode. Only truncation ends the episode.
Configuring max_steps
from mosaic_multigrid.envs import SoccerGame4HIndAgObsEnv16x11N2
# Default: 300 steps
env = SoccerGame4HIndAgObsEnv16x11N2()
# Custom: 500 steps for longer episodes
env = SoccerGame4HIndAgObsEnv16x11N2(max_steps=500)
# Via gym.make with kwargs
env = gym.make('MosaicMultiGrid-Soccer-2v2-IndAgObs-v1', max_steps=500)
Core Design Decisions
Agent-not-in-grid: Agents are NOT stored on the grid (following multigrid-ini). Agent positions are tracked via AgentState.pos. The observation generator inserts agents into the observation grid dynamically. This avoids grid corruption when agents overlap.
numpy subclass pattern: WorldObj(np.ndarray) and AgentState(np.ndarray) — domain objects ARE their numerical encoding. No serialization overhead.
team_index separation: agent.index (unique identity) vs agent.team_index (team membership).
Numba JIT: All observation generation functions use @nb.njit(cache=True). Enum values are extracted to plain int constants at module level because Numba cannot access Python enum attributes.
Action Space
Action Enum Comparison
| Action | Upstream (Fickinger 2020) | mosaic_multigrid (this fork) | multigrid-ini (Oguntola 2023) |
|---|---|---|---|
| noop | still |
0 | -- |
| still | 0 | -- | -- |
| left | 1 | 1 | 0 |
| right | 2 | 2 | 1 |
| forward | 3 | 3 | 2 |
| pickup | 4 | 4 | 3 |
| drop | 5 | 5 | 4 |
| toggle | 6 | 6 | 5 |
| done | 7 | 7 | 6 |
| Total | 8 | 8 | 7 |
Why noop was added (AEC + Parallel API compatibility):
In AEC (Agent-Environment Cycle) mode, only one agent acts per physics step. All other agents must still submit a valid action so the environment can advance, but they must not change state. Without a dedicated no-op:
- The previous action 0 was
left(turn left). - Non-acting agents would silently rotate on every step — corrupting the episode and invalidating any comparison between AEC and Parallel results.
noop=0 is the fix. This design is directly inspired by MeltingPot (Google DeepMind),
which uses NOOP=0 for the same reason. The done action (index 7) signals intentional
task completion and is semantically different — both cause no physical movement, but only
noop should be used by non-acting agents in AEC mode.
Migration note (v1 → v2): All action indices shifted up by 1. Any pre-trained policy or hardcoded action index from v1 will need updating:
left=0→1 right=1→2 forward=2→3 pickup=3→4 drop=4→5 toggle=5→6 done=6→7
Observation Space
Each agent receives a partial observation dict:
{
'image': np.ndarray, # (view_size, view_size, 3) — [Type, Color, State] per cell
'direction': int, # Agent facing direction (0=right, 1=down, 2=left, 3=up)
'mission': str, # Mission string
}
The default view_size=3 gives each agent a 3x3 partial view (matching our competitive game design). Each cell encodes 3 values (Type index, Color index, State index), down from 6 in the original.
Wrappers
| Wrapper | Description |
|---|---|
FullyObsWrapper |
Full grid observation instead of partial agent view |
ImgObsWrapper |
Returns only the image array (drops direction/mission) |
OneHotObsWrapper |
One-hot encodes the observation image (Numba JIT) |
SingleAgentWrapper |
Unwraps multi-agent dict for single-agent use |
Framework Adapters
PettingZoo
mosaic_multigrid supports both PettingZoo stepping paradigms:
- Parallel API (docs): All agents submit actions simultaneously via a single
step(actions_dict)call. This is the native mode for mosaic_multigrid. - AEC API (docs): Agents take turns sequentially via
agent_iter(). Internally, this converts the Parallel env using PettingZoo'sparallel_to_aec()utility -- actions are buffered until every agent has acted, then forwarded to the underlying parallel env in one batch.
For background on PettingZoo's multi-agent API design, see Terry et al. (2021).
Parallel API (simultaneous stepping)
from mosaic_multigrid.envs import SoccerGame4HEnv10x15N2
from mosaic_multigrid.pettingzoo import to_pettingzoo_env
PZParallel = to_pettingzoo_env(SoccerGame4HEnv10x15N2)
env = PZParallel(render_mode='rgb_array')
obs, infos = env.reset(seed=42)
while env.agents:
actions = {agent: env.action_space(agent).sample() for agent in env.agents}
obs, rewards, terms, truncs, infos = env.step(actions)
env.close()
AEC API (sequential turn-based stepping)
from mosaic_multigrid.envs import SoccerGame4HEnv10x15N2
from mosaic_multigrid.pettingzoo import to_pettingzoo_aec_env
PZAec = to_pettingzoo_aec_env(SoccerGame4HEnv10x15N2)
env = PZAec(render_mode='rgb_array')
env.reset(seed=42)
for agent in env.agent_iter():
obs, reward, term, trunc, info = env.last()
action = None if term or trunc else env.action_space(agent).sample()
env.step(action)
env.close()
Both APIs pass PettingZoo's official parallel_api_test and aec_api_test validators (32 tests total).
Install with:
pip install mosaic-multigrid[pettingzoo] # requires pettingzoo >= 1.22
Ray RLlib
from mosaic_multigrid.rllib import to_rllib_env
env_cls = to_rllib_env('MosaicMultiGrid-Soccer-2v2-IndAgObs-v1')
# Returns an RLlib MultiAgentEnv class (adds __all__ keys to terminated/truncated)
Requirements
- Python >= 3.9
- gymnasium >= 0.26
- numpy >= 1.18
- numba >= 0.53
- pygame >= 2.2
- aenum >= 1.3
Optional:
ray[rllib] >= 2.0(for RLlib adapter)pettingzoo >= 1.22(for PettingZoo adapter)
Tests
pip install -e ".[dev]"
pytest tests/ -v
94 tests covering: Action enum, Type/Color/State/Direction enums, WorldObj encode/decode, Grid operations, AgentState vectorized ops, Agent team_index, Mission/MissionSpace, MultiGridEnv reset/step/render, pickup/drop mechanics, Numba JIT observations, rendering dimensions, and reproducibility.
Citation
If you use this environment, please cite the relevant works:
@misc{gym_multigrid,
author = {Fickinger, Arnaud},
title = {Multi-Agent Gridworld Environment for OpenAI Gym},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/ArnaudFickinger/gym-multigrid}},
}
@article{oguntola2023theory,
title = {Theory of Mind as Intrinsic Motivation for Multi-Agent Reinforcement Learning},
author = {Oguntola, Ini and Campbell, Joseph and Stepputtis, Simon and Sycara, Katia},
journal = {arXiv preprint arXiv:2307.01158},
year = {2023},
url = {https://github.com/ini/multigrid},
}
@misc{mosaic_multigrid,
author = {Mousa, Abdulhamid},
title = {mosaic\_multigrid: Research-Grade Multi-Agent Gridworld Environments},
year = {2026},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Abdulhamid97Mousa/mosaic_multigrid}},
}
@article{terry2021pettingzoo,
title = {PettingZoo: Gym for Multi-Agent Reinforcement Learning},
author = {Terry, J. K and Black, Benjamin and Grammel, Nathaniel and Jayakumar, Mario
and Hari, Ananth and Sullivan, Ryan and Santos, Luis S and Dieffendahl, Clemens
and Horsch, Caroline and Perez-Vicente, Rodrigo and Williams, Niall L
and Lokesh, Yashas and Ravi, Praveen},
journal = {Advances in Neural Information Processing Systems},
volume = {34},
pages = {2242--2254},
year = {2021},
url = {https://pettingzoo.farama.org/},
}
License
Apache License 2.0 -- see LICENSE for details.
Original work: MiniGrid (Copyright 2020 Maxime Chevalier-Boisvert), MultiGrid extension (Copyright 2020 Arnaud Fickinger), INI multigrid (Copyright 2023 Ini Oguntola et al.).
This fork: Copyright 2026 Abdulhamid Mousa.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mosaic_multigrid-6.6.0.tar.gz.
File metadata
- Download URL: mosaic_multigrid-6.6.0.tar.gz
- Upload date:
- Size: 145.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6f6da822e5860d48fc7b8c0669b16e2fc560c4a7d486e54bd288cf778ed8a8c3
|
|
| MD5 |
23104d0d1ef41f1703df834c25454ed4
|
|
| BLAKE2b-256 |
32cc4317115e185e653aa7cd6a882465b10e6dd1ad8a24ad59e92c79cd0e96fd
|
File details
Details for the file mosaic_multigrid-6.6.0-py3-none-any.whl.
File metadata
- Download URL: mosaic_multigrid-6.6.0-py3-none-any.whl
- Upload date:
- Size: 97.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
62ec97a3eafc9e850d71b287b30ca2e56d42c85704f4fa51746e194cb731d276
|
|
| MD5 |
aa909270b8ceb97ef7d2e588d4552cea
|
|
| BLAKE2b-256 |
f51ecacf5487ee6783c7e55e1a66488f5bcc79e54067e6afa84efe9e7189669a
|







