Meta-Policy Knowledge Distillation for compact student models

Project description
MPDistil 🎓
Meta-Policy Knowledge Distillation for Training Compact Student Models



MPDistil is a teacher-student collaborative knowledge distillation framework that enables compact student models to outperform larger teacher models through meta-learning and curriculum learning.
Based on the ICLR 2024 paper: A Good Learner can Teach Better: Teacher-Student Collaborative Knowledge Distillation
🌟 Key Features
- 📊 Superior Performance: 6-layer BERT student outperforms 12-layer BERT teacher on 5/6 SuperGLUE tasks
- 🎯 4-Phase Training: Teacher fine-tuning → PKD → Meta-teacher → Curriculum learning
- 🚀 Simple API: Easy-to-use
.train()method with full control over all phases - 📏 Flexible Metrics: Built-in support for accuracy, F1, MCC, correlation via HuggingFace
evaluate - 🔧 Customizable: Works with any HuggingFace model and custom datasets
- 💻 Colab-Ready: GPU-optimized for Google Colab environments
- 📦 Easy Installation: Single pip command to get started
📈 Methodology
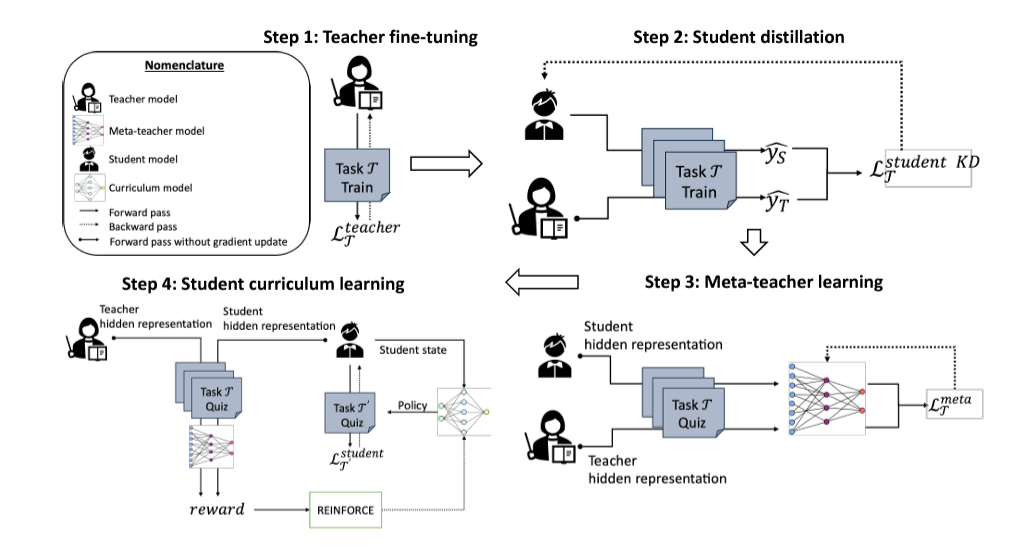
MPDistil consists of 4 training phases:
- Teacher Fine-tuning: Fine-tune teacher model on the target task
- Student PKD: Knowledge distillation with Patient Knowledge Distillation
- Meta-Teacher Learning: Collaborative or competitive loss for meta-learning
- Curriculum Learning: Reinforcement learning-based task selection
🚀 Installation
From GitHub (Recommended)
pip install git+https://github.com/parmanu-lcs2/mpdistil.git
From Source
git clone https://github.com/parmanu-lcs2/mpdistil.git
cd mpdistil
pip install -e .
💡 Quick Start
Basic Usage
from mpdistil import MPDistil, load_superglue_dataset
# Load data
loaders, num_labels = load_superglue_dataset('CB')
# Initialize MPDistil
model = MPDistil(
task_name='CB',
num_labels=num_labels,
metric='f1', # Options: 'accuracy', 'f1', 'mcc', 'correlation', 'auto'
teacher_model='bert-base-uncased',
student_model='bert-base-uncased',
student_layers=6
)
# Train with all 4 phases
history = model.train(
train_loader=loaders['train'],
val_loader=loaders['val'],
teacher_epochs=10, # Phase 1
student_epochs=10, # Phase 2
meta_epochs=1 # Phase 3 (NEW!)
)
# Save trained student
model.save_student('./my_student_model')
# Make predictions
predictions = model.predict(loaders['test'])
With Custom Data
from mpdistil import MPDistil, create_simple_dataloader
# Prepare your data
texts = [("This is text A", "This is text B"), ...]
labels = [0, 1, 0, ...]
# Create DataLoader
train_loader = create_simple_dataloader(
texts=texts,
labels=labels,
tokenizer_name='bert-base-uncased',
max_length=128,
batch_size=8
)
# Train model
model = MPDistil(task_name='MyTask', num_labels=2, metric='accuracy')
history = model.train(train_loader, val_loader)
With Meta-Learning (Curriculum)
# Load multiple tasks for curriculum learning
cb_loaders, _ = load_superglue_dataset('CB')
rte_loaders, _ = load_superglue_dataset('RTE')
boolq_loaders, _ = load_superglue_dataset('BoolQ')
# Train with curriculum learning
history = model.train(
train_loader=cb_loaders['train'],
val_loader=cb_loaders['val'],
meta_loaders={
'RTE': rte_loaders['val'],
'BoolQ': boolq_loaders['val']
},
teacher_epochs=10, # Phase 1
student_epochs=10, # Phase 2
meta_epochs=3, # Phase 3 - can train for multiple epochs!
num_episodes=200 # Phase 4 - curriculum learning episodes
)
📖 API Reference
MPDistil Class
Constructor
MPDistil(
task_name: str, # Name of the main task
num_labels: int, # Number of output classes
metric: str = 'accuracy', # Metric: 'accuracy', 'f1', 'mcc', 'correlation', 'auto'
teacher_model: str = 'bert-base-uncased', # HuggingFace model name
student_model: str = 'bert-base-uncased', # HuggingFace model name
student_layers: int = 6, # Number of layers for student
device: str = 'auto', # 'auto', 'cuda', or 'cpu'
output_dir: str = './mpdistil_outputs'
)
Methods
| Method | Description |
|---|---|
train(train_loader, val_loader, **kwargs) |
Train the model (all 4 phases) |
predict(test_loader) |
Generate predictions |
save_student(path) |
Save student model in HuggingFace format |
load_student(path) |
Load a saved student model |
save_predictions(predictions, path, label_mapping) |
Save predictions to TSV |
TrainingConfig
Configure training hyperparameters:
from mpdistil import TrainingConfig
config = TrainingConfig(
# Phase 1: Teacher
teacher_epochs=10,
teacher_lr=2e-5,
# Phase 2: Student PKD
student_epochs=10,
student_lr=3e-5,
alpha=0.5, # Soft loss weight
beta=100.0, # PKD loss weight
temperature=5.0, # Distillation temperature
# Phase 3: Meta-Teacher
meta_epochs=3, # NEW! Meta-teacher can train for multiple epochs
meta_lr=1e-3,
use_competitive_loss=False, # Use collaborative loss
# Phase 4: Curriculum
num_episodes=200,
reward_type='binary', # or 'real'
# General
batch_size=8,
seed=42,
report_to=None # Options: 'wandb', 'tensorboard', None
)
history = model.train(train_loader, val_loader, config=config)
Training Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
teacher_epochs |
int | 10 | Phase 1: Teacher training epochs |
student_epochs |
int | 10 | Phase 2: Student training epochs |
meta_epochs |
int | 1 | Phase 3: Meta-teacher training epochs (NEW!) |
num_episodes |
int | 200 | Phase 4: Curriculum learning episodes |
teacher_lr |
float | 2e-5 | Teacher learning rate |
student_lr |
float | 3e-5 | Student learning rate |
meta_lr |
float | 1e-3 | Meta-learning rate |
alpha |
float | 0.5 | Soft vs hard loss weight |
beta |
float | 100.0 | PKD loss weight |
temperature |
float | 5.0 | Distillation temperature |
use_competitive_loss |
bool | False | Competitive vs collaborative |
reward_type |
str | 'binary' | 'binary' or 'real' |
batch_size |
int | 8 | Batch size |
seed |
int | 42 | Random seed |
📊 Results
Performance on SuperGLUE tasks (BERT-base teacher → BERT-6L student):
| Model | BoolQ | CB | COPA | RTE | WiC | WSC |
|---|---|---|---|---|---|---|
| Teacher | 75.3 | 83.9 | 63.0 | 67.1 | 57.1 | 64.4 |
| Student (Undistilled) | 71.6 | 75.0 | 53.0 | 64.6 | 56.0 | 63.5 |
| MPDistil (Ours) | 73.4 | 83.9 | 70.0 | 67.5 | 59.6 | 65.4 |
✨ Student outperforms teacher on 5/6 tasks!
📝 Examples
See the examples/ directory for Jupyter notebooks:
- GLUE.ipynb: Usage with SuperGLUE
📊 Evaluation Metrics
MPDistil supports multiple evaluation metrics via HuggingFace evaluate library:
Available Metrics
| Metric | Use Case | Returns |
|---|---|---|
'accuracy' |
Standard classification (default) | {'acc': float} |
'f1' |
Imbalanced datasets, multi-class | {'acc': float, 'f1': float, 'acc_and_f1': float} |
'mcc' |
Binary classification, imbalanced | {'mcc': float} |
'correlation' |
Regression tasks (STS-B) | {'pearson': float, 'spearmanr': float} |
'auto' |
Auto-detect based on task | Task-specific metric |
Example: Using Different Metrics
# Accuracy (default)
model = MPDistil(task_name='BoolQ', num_labels=2, metric='accuracy')
# F1 score (recommended for CB, MultiRC)
model = MPDistil(task_name='CB', num_labels=3, metric='f1')
# Matthews Correlation (for binary with imbalance)
model = MPDistil(task_name='CoLA', num_labels=2, metric='mcc')
# Correlation (for regression)
model = MPDistil(task_name='STS-B', num_labels=1, metric='correlation', is_regression=True)
# Auto-detect
model = MPDistil(task_name='CB', num_labels=3, metric='auto') # Uses F1 for CB
🔬 How It Works
Phase 1: Teacher Fine-tuning
Fine-tune a large teacher model (e.g., BERT-base) on your target task.
Phase 2: Student PKD
Train a smaller student model using:
- Soft targets from teacher (KL divergence)
- Hard labels (cross-entropy)
- Patient KD (intermediate feature matching)
Loss: α * soft_loss + (1-α) * hard_loss + β * pkd_loss
Phase 3: Meta-Teacher
Create a meta-teacher that learns from both teacher and student representations:
Collaborative loss (default):
L = 0.5 * CE(T'(h_teacher), y) + 0.5 * CE(T'(h_student), y)
Competitive loss:
L = -mean(P_teacher) + mean(P_student) + CE_loss
Phase 4: Curriculum Learning
Use reinforcement learning to select which auxiliary tasks help the student learn:
- Action model selects next task
- Reward based on student improvement over teacher
- REINFORCE algorithm updates policy
🛠️ Advanced Usage
Custom Model Architectures
model = MPDistil(
task_name='MyTask',
num_labels=3,
teacher_model='roberta-large',
student_model='distilbert-base-uncased',
student_layers=6
)
Weights & Biases Logging
history = model.train(
train_loader=train_loader,
val_loader=val_loader,
report_to='wandb', # Options: 'wandb', 'tensorboard', None
wandb_project='my-project',
wandb_run_name='experiment-1'
)
Access Trained Models
# Access student model
student = model.student
# Access teacher model
teacher = model.teacher
# Use with HuggingFace
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('./my_student_model')
model = AutoModel.from_pretrained('./my_student_model')
📚 Citation
If you use MPDistil in your research, please cite:
@inproceedings{sengupta2024mpdistil,
title={A Good Learner can Teach Better: Teacher-Student Collaborative Knowledge Distillation},
author={Sengupta, Ayan and Dixit, Shantanu and Akhtar, Md Shad and Chakraborty, Tanmoy},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=Ixi4j6LtdX}
}
📄 License
This project is licensed under the MIT License - see the LICENSE file for details.
🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
🙏 Acknowledgments
- Original paper: ICLR 2024
- Built with PyTorch and HuggingFace Transformers
📧 Contact
For questions or issues, please open an issue on GitHub or contact the authors.
Made with ❤️ for the research community
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file mpdistil-0.1.0.tar.gz.
File metadata
- Download URL: mpdistil-0.1.0.tar.gz
- Upload date:
- Size: 66.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c7e2cfe12c917046e5c72a95e18e1c1ce3cc36c8ae8346e9e41922ad466020b6
|
|
| MD5 |
3a4567ccf37b84b261a131be12bc23a9
|
|
| BLAKE2b-256 |
af92b181517327afb442e8de4baddfb5d26fa9cbbdcb461a882c5478b600dece
|
File details
Details for the file mpdistil-0.1.0-py3-none-any.whl.
File metadata
- Download URL: mpdistil-0.1.0-py3-none-any.whl
- Upload date:
- Size: 34.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2fee1b95582f5f55bd04fcc5d74b86d28a0ea68f265042438df21c6a4670c903
|
|
| MD5 |
f9dc0506c947cde5f617ca174921c89a
|
|
| BLAKE2b-256 |
378370d3e9eea49a48144f8e434d7913383f38cee8c3c595eabefbc935356060
|







