Framework for collecting multilingual culturally-aligned natural queries.

Project description
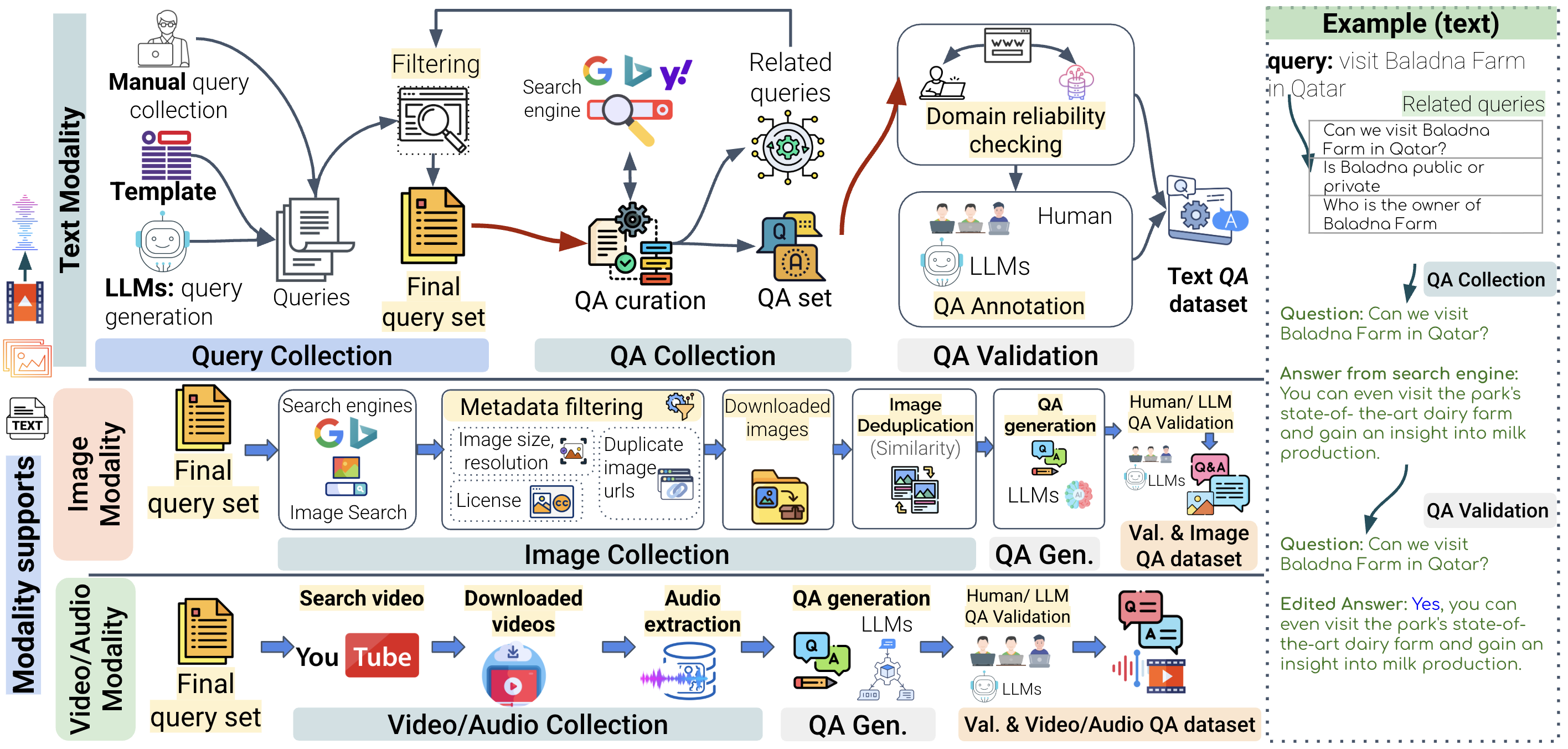
NativQA Framework




NativQA Framework is an open-source toolkit for collecting multilingual, culturally aligned, search-grounded question answering datasets. It helps researchers and practitioners build natural query, multilingual QA, region-aware evaluation, and visual question answering (VQA) resources from real search results across different countries, languages, and domains.
NativQA is designed for teams working on LLM evaluation, benchmark construction, fine-tuning data collection, culturally grounded QA, and location-specific search analysis. Starting from seed queries, it expands through related searches and search result structures to produce datasets that reflect everyday information needs in local contexts.
More details are available at https://nativqa.gitlab.io/.
Here is a quick overview video:

Why NativQA?
- Build multilingual QA datasets from real search behavior instead of synthetic prompts alone.
- Collect culturally aligned natural queries tied to a country, city, or language context.
- Generate datasets for text QA, image search, and video search workflows.
- Expand seed queries iteratively through related searches and related questions.
- Support LLM benchmarking, fine-tuning, VQA dataset construction, and domain reliability validation.
- Work with lightweight CSV or TSV inputs that are easy to create, version, and audit.
Use Cases
- Evaluate LLMs on region-specific everyday knowledge rather than generic global trivia.
- Create culturally grounded benchmarks for Arabic, English, and other languages.
- Build image-based datasets for visual question answering and multimodal evaluation.
- Compare how search results differ by location, country code, and multiple-country constraints.
- Bootstrap low-resource language datasets with template-driven or user-collected seed queries.
Search Support
| Search type | Engines | Output dataset |
|---|---|---|
text |
Google, Bing, Yahoo | TSV |
image |
Google, Bing | JSON |
video |
JSON |
Quick Start
Option 1: Install from source
- Clone the repository:
git clone https://gitlab.com/nativqa/nativqa-framework.git cd nativqa-framework
- Install the requirements:
python3 -m pip install -r requirements.txt
- Add your SerpAPI key to
envs/api_key.env:mkdir -p envs printf 'API_KEY="your-serpapi-key"\n' > envs/api_key.env
- Run the sample text-search pipeline:
python3 -m nativqa \ --engine google \ --search_type text \ --input_file data/test_query.csv \ --country_code qa \ --location "Doha, Qatar" \ --env envs/api_key.env \ --n_iter 3
Option 2: Install from PyPI
- Install the package:
python3 -m pip install nativqa-framework
- Create an env file for your SerpAPI key:
mkdir -p envs printf 'API_KEY="your-serpapi-key"\n' > envs/api_key.env
- Create a small seed query file:
cat > test_query.csv <<'EOF' topic,query animal,What is New York City State animal? food,What food is New York City famous for? travel,What is the best time to visit Central Park? EOF
- Run NativQA:
nativqa \ --engine google \ --search_type text \ --input_file test_query.csv \ --country_code us \ --location "New York, United States" \ --env envs/api_key.env \ --n_iter 1
Input Format
NativQA accepts seed queries in CSV or TSV format with two columns:
topic,query
animal,What is New York City State animal?
food,What food is New York City famous for?
travel,What is the best time to visit Central Park?
The topic column is used as a high-level category. The query column is the natural-language seed query sent to the search engine.
Core CLI Parameters
--engine: Search engine to use. Supported values:google,bing,yahoo--search_type: Search mode. Supported values:text,image,video--input_file: Path to the seed query CSV or TSV file--country_code: Country code for location-aware search--location: Search origin location string, for example"Doha, Qatar"--multiple_countries: Optional country restriction string such ascountryQA|countryBD--env: Path to the env file containingAPI_KEY--output_dir: Optional output directory. Defaults to./results/--n_iter: Number of iterative search rounds
Common Examples
Text search
python3 -m nativqa \
--engine google \
--search_type text \
--input_file data/test_query.csv \
--country_code qa \
--location "Doha, Qatar" \
--env envs/api_key.env \
--n_iter 3
Image search
python3 -m nativqa \
--engine google \
--search_type image \
--input_file data/test_query.csv \
--country_code us \
--location "New York, United States" \
--env envs/api_key.env \
--n_iter 1
Video search
python3 -m nativqa \
--engine google \
--search_type video \
--input_file data/test_query.csv \
--country_code us \
--location "New York, United States" \
--env envs/api_key.env \
--n_iter 1
Output Structure
For an input file named test_query.csv, NativQA creates a result directory like:
results/<search_type>/test_query/
Inside that directory:
dataset/- Final merged dataset
textruns produce.tsvimageandvideoruns produce.json
iteration_<n>/output/- Per-iteration raw and processed outputs such as
summary.jsonl,original_response.json, and related-search files
- Per-iteration raw and processed outputs such as
completed_queries.txt- Queries already processed across iterations
Included Utilities
The repository includes helper scripts for common dataset-building tasks:
- scripts/template2seeds.py: generate seed queries from a template file
- scripts/download_images.py: download images from an image-search dataset
- scripts/filter_near_duplicates_flann.py: filter near-duplicate images
- scripts/check_domain_reliability.py: retain answers from reliable domains
- scripts/GPT_4o_labeling.py: annotate datasets with LLM-based labels
Query Collection
Template-based seed generation
python3 scripts/template2seeds.py \
--template_file templates/arabic_template.csv \
--output_file templates/test.csv \
--location "قطر"
Seed query collection app
The repository also includes a lightweight Flask-based seed collection app in seed_query_collector/app.py for gathering user-written queries.
QA Validation
Domain Reliability Check (DRC)
Manually verified domain labels are stored in domain/annotated_domains.csv.
To filter answers by source reliability:
python3 scripts/check_domain_reliability.py \
--input_file <dataset_directory>/input_filename.tsv \
--output_file <output_directory>/output_filename.tsv
LLM-based annotation
python3 scripts/GPT_4o_labeling.py \
--input_file results/text/arabic_qa/dataset.json \
--env_path envs/gpt4-api-key.env \
--output_dir results/text/arabic_qa/GPT4o_labeling/ \
--location "Qatar"
License
NativQA Framework is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0).
You are free to share and adapt the framework for non-commercial purposes, provided that you give appropriate credit, indicate changes, and distribute contributions under the same license.
Citation
Please cite our papers when referring to this framework:
@article{Alam2025nativqa,
title={NativQA Framework: A Framework for Collecting Multilingual Culturally-Aligned Natural Queries},
author={Alam, Firoj and Hasan, Md Arid and Laskar, Sahinur Rahman and Kutlu, Mucahid and Chowdhury, Shammur Absar},
journal={arXiv},
year={2024}
}
@inproceedings{hasan-etal-2025-nativqa,
title = "{N}ativ{QA}: Multilingual Culturally-Aligned Natural Query for {LLM}s",
author = "Hasan, Md. Arid and
Hasanain, Maram and
Ahmad, Fatema and
Laskar, Sahinur Rahman and
Upadhyay, Sunaya and
Sukhadia, Vrunda N and
Kutlu, Mucahid and
Chowdhury, Shammur Absar and
Alam, Firoj",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2025",
month = jul,
year = "2025",
address = "Vienna, Austria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.findings-acl.770/",
doi = "10.18653/v1/2025.findings-acl.770",
pages = "14886--14909",
ISBN = "979-8-89176-256-5",
abstract = "Natural Question Answering (QA) datasets play a crucial role in evaluating the capabilities of large language models (LLMs), ensuring their effectiveness in real-world applications. Despite the numerous QA datasets that have been developed and some work done in parallel, there is a notable lack of a framework and large-scale region-specific datasets queried by native users in their own languages. This gap hinders effective benchmarking and the development of fine-tuned models for regional and cultural specificities. In this study, we propose a scalable, language-independent framework, NativQA, to seamlessly construct culturally and regionally aligned QA datasets in native languages for LLM evaluation and tuning. We demonstrate the efficacy of the proposed framework by designing a multilingual natural QA dataset, MultiNativQA, consisting of approximately {\textasciitilde}64K manually annotated QA pairs in seven languages, ranging from high- to extremely low-resource, based on queries from native speakers from 9 regions covering 18 topics. We benchmark both open- and closed-source LLMs using the MultiNativQA dataset. The dataset and related experimental scripts are publicly available for the community at: https://huggingface.co/datasets/QCRI/MultiNativQAand https://gitlab.com/nativqa/multinativqa."
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file nativqa_framework-0.1.2.tar.gz.
File metadata
- Download URL: nativqa_framework-0.1.2.tar.gz
- Upload date:
- Size: 23.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
358e7ce6d8970b885c3bf6d05316869faa947e296957b079182eb3f5e122b413
|
|
| MD5 |
f42eba1412345fea473c19b753b0d622
|
|
| BLAKE2b-256 |
8694a7c705e2cd6f3a20f41b4b9e79ceff15baf27a62a55b71d65a1df6b63123
|
File details
Details for the file nativqa_framework-0.1.2-py3-none-any.whl.
File metadata
- Download URL: nativqa_framework-0.1.2-py3-none-any.whl
- Upload date:
- Size: 19.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bffec15878279f1197db0353515cc9028ae879264cc6ac68bb256f014f287cc3
|
|
| MD5 |
1534a82cdd7f89274f027a738cf24911
|
|
| BLAKE2b-256 |
e9ac18b53e346447bb00f30c994a86d104d98a5dbecb172fd5cae4fa8728fe10
|







