Framework for collecting multilingual culturally-aligned natural queries.

Project description
NativQA Framework: A Framework for Collecting Multilingual Culturally-Aligned Natural Queries




NativQA Framework is a powerful open-source toolkit designed to effortlessly build large-scale, culturally and regionally aligned question-answering (QA) datasets in native languages. By leveraging user-defined seed queries and real-time search engine results, NativQA captures location-specific, everyday information to generate natural, multilingual QA data. Ideal for evaluating and fine-tuning large language models (LLMs), the framework bridges the gap in region-specific QA resources, empowering inclusive AI development across diverse linguistic and cultural landscapes.
🌍 Key Features
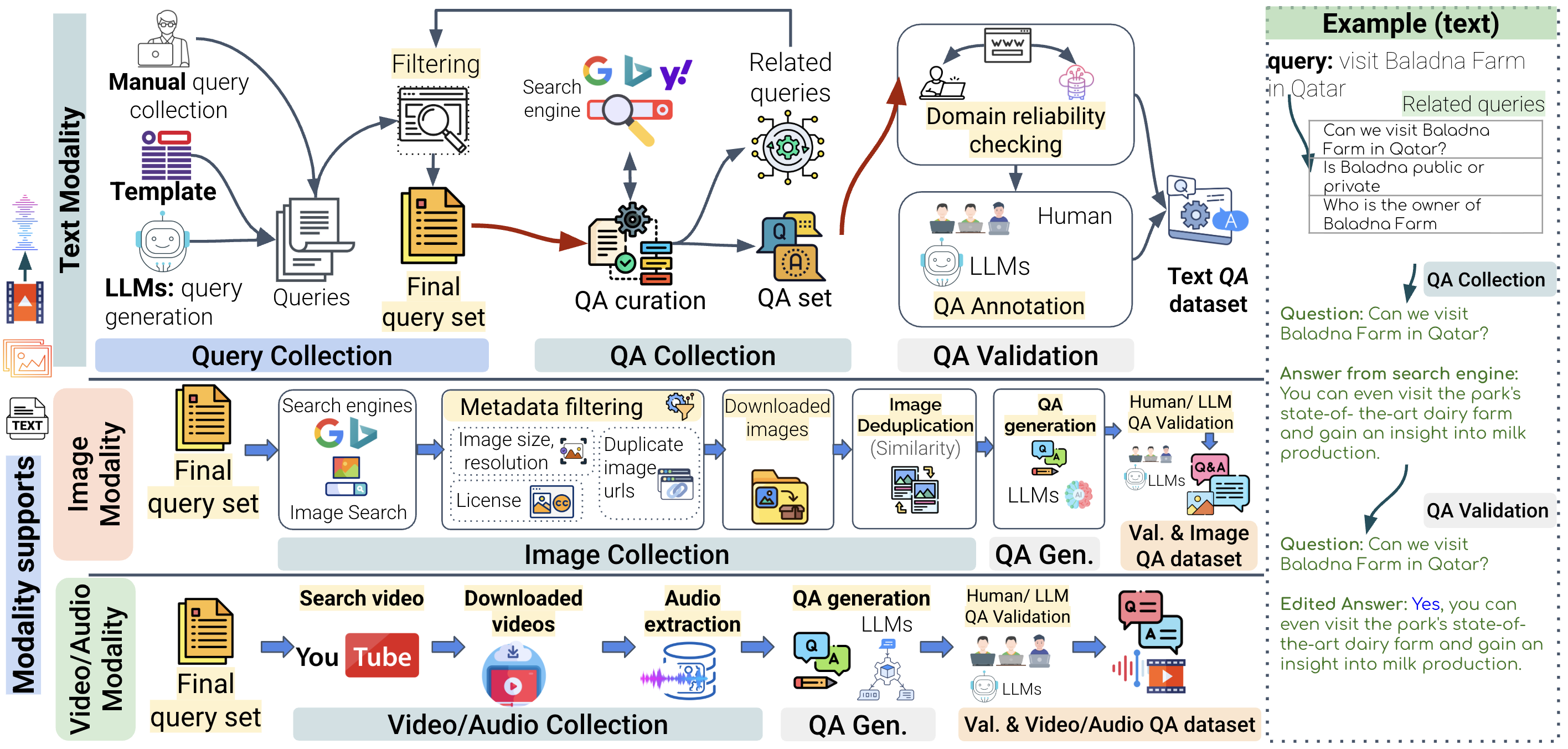
Developing the NativQA Framework is an ongoing effort, and the framework will continue to grow and improve over time. Currently, it offers the following features:
- Supports Google, Yahoo, and Bing search engines for collecting "People also ask" questions and answers.
- Accepts seed queries in CSV or TSV format.
- Open-source and community-driven.
- Supports image collection for visual question answering tasks.
- Multilingual support for diverse language coverage.
Here is a quick overview of NativQA Framework:

Quick Start
- Clone the repository
git clone https://gitlab.com/nativqa/nativqa-framework.git - Navigate to the
nativqa-frameworkdirectory:cd nativqa-framework - Install the requirements:
pip install -r requirements.txt - Put your SerpAPI api key in
envs/api_key.env - Run the program!
For example, to run the program using example seed queries:
python -m nativqa --engine google --search_type text --input_file data/test_query.csv --country_code qa --location "Doha, Qatar" --env envs/api_key.env --n_iter 3
which uses a sample seed query file
Parameters
--engineSearch engine to use for collect QA. Currently supports only Google, Bing, and Yahoo.--search_typeType of search eithertext,image, orvideo. [Currently supports only Google and Bing for image search and Google for video/audio search.]--input_fileseed query file should be CSV/TSV--country_codeParameter defines the country to use for the Google search. The country code supported by Google.--locationParameter defines from where you want the search to originate.--multiple_countriesParameter defines one or multiple countries to limit the search to. For example,countryQA|countryBD--envAPI key file.--outputoutput directory location. Defaults./results/--n_iternumber of search iteration to perform.
Outputs Format
- The framework will create a directory using input
filenameunder the given output directory.- dataset directory has the final QA pair file with the same name of input file.
- iteration_{n} directory contains output folder of each iteration and input queries of each iteration.
- output contains the output of each iteration consisting of
related_search.tsv, original_response.json, summary.jsonl, related_question.json
- output contains the output of each iteration consisting of
- completed_queries.txt List of completed searched queries
Query collection
Template based Query Generation
python scripts/template2seeds.py --template_file templates/arabic_template.csv --output_file templates/test.csv --location "قطر"
LLM based Query Generation
To add
QA Validation
Domain Reliability Check (DRC)
Manually verified domains list file are located in domain/annotated_domains.csv.
To verify the answer source reliability: (the input file will be dataset file generated from nativqa framework.)
python scripts/check_domain_reliability.py --input_file <dataset_directory>/input_filename.csv --output_file <output_directory>/output_filename.csv
Note that we only support csv/tsv file for domain reliability task. We aim to extend other file types in future.
LLM based Annotation
python scripts/GPT_4o_labeling.py --input_file results/text/arabic_qa/dataset.json --env_path envs/gpt4-api-key.env --output_dir results/text/arabic_qa/GPT4o_labeling/ --location "Qatar"
Licence
The NativQA Framework is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0).
You are free to share and adapt the framework for non-commercial purposes, provided that:
- You give appropriate credit.
- You indicate if changes were made.
- You distribute your contributions under the same license.
Citation
Please cite our papers when referring to this framework:
@article{Alam2025nativqa,
title={NativQA Framework: A Framework for Collecting Multilingual Culturally-Aligned Natural Queries},
author={Alam, Firoj and Hasan, Md Arid and Laskar, Sahinur Rahman and Kutlu, Mucahid and Chowdhury, Shammur Absar},
journal={arXiv},
year={2024}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file nativqa_framework-0.1.1.tar.gz.
File metadata
- Download URL: nativqa_framework-0.1.1.tar.gz
- Upload date:
- Size: 20.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fd5211ea13ad2dbdd550d8785bb8eacba064782c36941c702696ee95cd223704
|
|
| MD5 |
211fd172b2703fb6c8ebe10fd4ae8b05
|
|
| BLAKE2b-256 |
a2e9ca99edf08b67febf19059d42a2150a95e8074a0b04fc60d4aea0620ee0b8
|
File details
Details for the file nativqa_framework-0.1.1-py3-none-any.whl.
File metadata
- Download URL: nativqa_framework-0.1.1-py3-none-any.whl
- Upload date:
- Size: 17.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
71cad9eb64bfa13e6cf7be5d4b01ca7f03c32b904ac5ab67cab8095598024106
|
|
| MD5 |
1f7a9078598009b486ce4214ce92b580
|
|
| BLAKE2b-256 |
495efc0ec4dc87644e9b4626765ebea527861807f56165a9abdcfd122f6da0ec
|







