DTensor-native pretraining and fine-tuning for LLMs/VLMs with day-0 Hugging Face support, GPU-acceleration, and memory efficiency.



Project description
🚀 NeMo AutoModel





📖 Documentation • 🔥 Ready-to-Use Recipes • 💡 Examples • Model Coverage • Performance • 🤝 Contributing
📣 News and Discussions
- [04/02/2026]Gemma 4 We support fine-tuning for Gemma4 (2B, 4B, 31B, 26BA4B)! Check out our recipes.
- [03/30/2026]NeMo AutoModel ships with agent-friendly skills in skills/ to help you with common development tasks (e.g., running a recipe, model onboarding, development) across the repo. We welcome PRs that improve existing skills or add new ones.
- [03/16/2026]Mistral Small 4 We support fine-tuning for Mistral4 119B! Check out our recipe.
- [03/11/2026]Nemotron Super v3 We support fine-tuning for
nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-BF16. Check out our recipe. - [03/11/2026]GLM-5 We now support finetuning
zai-org/GLM-5. Check out our recipe. - [03/02/2026]Qwen3.5 small models We support finetuning for Qwen3.5 small models 0.8B, 2B, 4B (recipe) and 9B (recipe)
- [02/16/2026]Qwen3.5 MoE We support finetuning for
Qwen/Qwen3.5-397B-A17B(recipe) andQwen/Qwen3.5-35B-A3B(recipe) - [02/13/2026]MiniMax-M2.5 We support finetuning for
MiniMaxAI/MiniMax-M2.5. Checkout our recipe - [02/11/2026]GLM-4.7-Flash We now support finetuning GLM-4.7-Flash. Checkout our packed sequence recipe
- [02/09/2026]MiniMax-M2 We support finetuning for
MiniMaxAI/MiniMax-M2. Checkout our recipe - [02/06/2026]Qwen3 VL 235B We support finetuning for
Qwen/Qwen3-VL-235B-A22B-Instruct. Checkout our recipe - [02/06/2026]GLM4.7 We now support finetuning GLM4.7. Checkout our recipe
- [02/06/2026]Step3.5-flash is out! Finetune it with our finetune recipe
- [02/05/2026]DeepSeek-V3.2 is out! Checkout out the finetune recipe!
- [02/04/2026]Kimi K2.5 VL is out! Finetune it with NeMo AutoModel
- [01/30/2026]Kimi VL We support fine-tuning for
moonshotai/Kimi-VL-A3B-Instruct. Check out our recipe. - [01/12/2026]Nemotron Flash We support fine-tuning for
nvidia/Nemotron-Flash-1B. Check out our recipe. - [01/12/2026]Nemotron Parse We support fine-tuning for
nvidia/NVIDIA-Nemotron-Parse-v1.1. Check out our recipe. - [01/07/2026]Devstral-Small We support fine-tuning for
mistralai/Devstral-Small-2512. Check out our recipe. - [12/18/2025]FunctionGemma is out! Finetune it with NeMo AutoModel!
- [12/15/2025]NVIDIA-Nemotron-3-Nano-30B-A3B is out! Finetune it with NeMo AutoModel!
- [11/6/2025]Accelerating Large-Scale Mixture-of-Experts Training in PyTorch
- [10/6/2025]Enabling PyTorch Native Pipeline Parallelism for 🤗 Hugging Face Transformer Models
- [9/22/2025]Fine-tune Hugging Face Models Instantly with Day-0 Support with NVIDIA NeMo AutoModel
- [9/18/2025]🚀 NeMo Framework Now Supports Google Gemma 3n: Efficient Multimodal Fine-tuning Made Simple
Overview
Nemo AutoModel is a Pytorch DTensor‑native SPMD open-source training library under NVIDIA NeMo Framework, designed to streamline and scale training and finetuning for LLMs and VLMs. Designed for flexibility, reproducibility, and scale, NeMo AutoModel enables both small-scale experiments and massive multi-GPU, multi-node deployments for fast experimentation in research and production environments.
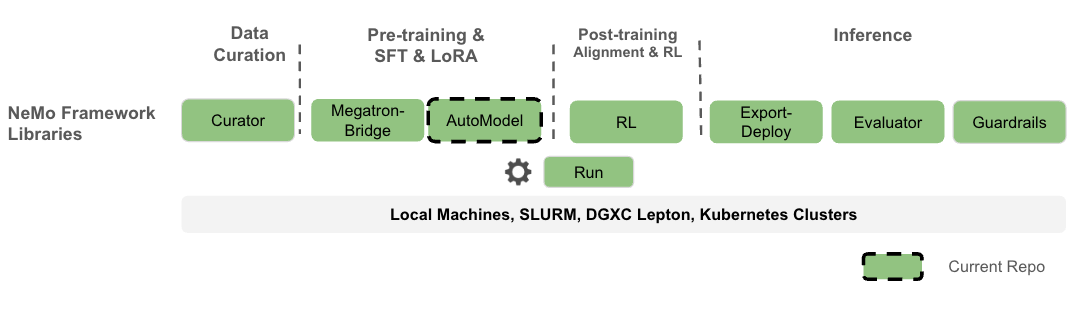
What you can expect:
- Hackable with a modular design that allows easy integration, customization, and quick research prototypes.
- Minimal ceremony: YAML-driven recipes; override any field using CLI.
- High performance and flexibility with custom kernels and DTensor support.
- Seamless integration with Hugging Face for day-0 model support, ease of use, and wide range of supported models.
- Efficient resource management using Kubernetes and Slurm, enabling scalable and flexible deployment across configurations.
- Documentation with step-by-step guides and runnable examples.
⚠️ Note: NeMo AutoModel is under active development. New features, improvements, and documentation updates are released regularly. We are working toward a stable release, so expect the interface to solidify over time. Your feedback and contributions are welcome, and we encourage you to follow along as new updates roll out.
Why PyTorch Distributed and SPMD
- One program, any scale: The same training script runs on 1 GPU or 1000+ by changing the mesh.
- PyTorch Distributed native: Partition model/optimizer states with
DeviceMesh+ placements (Shard,Replicate). - SPMD first: Parallelism is configuration. No model rewrites when scaling up or changing strategy.
- Decoupled concerns: Model code stays pure PyTorch; parallel strategy lives in config.
- Composability: Mix tensor, sequence, and data parallel by editing placements.
- Portability: Fewer bespoke abstractions; easier to reason about failure modes and restarts.
Table of Contents
- Feature Roadmap
- Getting Started
- LLM
- VLM
- Supported Models
- Performance
- Interoperability
- Contributing
- License
TL;DR: SPMD turns “how to parallelize” into a runtime layout choice, not a code fork.
Feature Roadmap
✅ Available now | 🔜 Coming in 26.02
-
✅ Advanced Parallelism - PyTorch native FSDP2, TP, CP, and SP for distributed training.
-
✅ HSDP - Multi-node Hybrid Sharding Data Parallelism based on FSDP2.
-
✅ Pipeline Support - Torch-native support for pipelining composable with FSDP2 and DTensor (3D Parallelism).
-
✅ Environment Support - Support for SLURM and interactive training.
-
✅ Learning Algorithms - SFT (Supervised Fine-Tuning), and PEFT (Parameter Efficient Fine-Tuning).
-
✅ Pre-training - Support for model pre-training, including DeepSeekV3.
-
✅ Knowledge Distillation - Support for knowledge distillation with LLMs; VLM support will be added post 25.09.
-
✅ HuggingFace Integration - Works with dense models (e.g., Qwen, Llama3, etc) and large MoEs (e.g., DSv3).
-
✅ Sequence Packing - Sequence packing for huge training perf gains.
-
✅ FP8 and mixed precision - FP8 support with torchao, requires torch.compile-supported models.
-
✅ DCP - Distributed Checkpoint support with SafeTensors output.
-
✅ VLM: Support for finetuning VLMs (e.g., Qwen2-VL, Gemma-3-VL). More families to be included in the future.
-
✅ Extended MoE support - GPT-OSS, Qwen3 (Coder-480B-A35B, etc), Qwen-next.
-
🔜 Transformers v5 🤗 - Support for transformers v5 🤗 with device-mesh driven parallelism.
-
🔜 Muon & Dion - Support for Muon and Dion optimizers.
-
🔜 SonicMoE - Optimized MoE implementation for faster expert computation.
-
🔜 FP8 MoE - FP8 precision training and inference for MoE models.
-
🔜 Cudagraph with MoE - CUDA graph support for MoE layers to reduce kernel launch overhead.
-
🔜 Extended VLM Support - DeepSeek OCR, Qwen3 VL 235B, Kimi-VL, GLM4.5V
-
🔜 Extended LLM Support - QWENCoder 480B Instruct, MiniMax2.1, and more
-
🔜 Kubernetes - Multi-node job launch with k8s.
Getting Started
We recommend using uv for reproducible Python environments.
# Setup environment before running any recipes
uv venv
# Choose ONE:
uv sync --frozen # LLM recipes (default)
# uv sync --frozen --extra vlm # VLM recipes (fixes: ImportError: qwen_vl_utils is not installed)
# uv sync --frozen --extra cuda # Optional CUDA deps (e.g., Transformer Engine, bitsandbytes)
# uv sync --frozen --extra all # Most optional deps (includes `vlm` and `cuda`)
# uv sync --frozen --all-extras # Everything (includes `fa`, `moe`, etc.)
# One-off runs (examples):
# uv run --extra vlm <command>
# uv run --extra cuda <command>
uv run python -c "import nemo_automodel; print('NeMo AutoModel ready')"
Run a Recipe
All recipes are launched via the automodel CLI (or its short alias am). Each YAML config specifies the recipe class and all training parameters:
# LLM example: multi-GPU fine-tuning with FSDP2
automodel examples/llm_finetune/llama3_2/llama3_2_1b_hellaswag.yaml --nproc-per-node 8
# VLM example: single-GPU fine-tuning (Gemma-3-VL) with LoRA
automodel examples/vlm_finetune/gemma3/gemma3_vl_4b_cord_v2_peft.yaml
# Both commands also work with uv run:
uv run automodel examples/llm_finetune/llama3_2/llama3_2_1b_hellaswag.yaml --nproc-per-node 8
[!TIP] Login-node / CI installs: If you only need to submit jobs (SLURM, k8s, NeMo-Run) and don't need to train locally, install the lightweight CLI package:
pip install nemo-automodel[cli]
LLM Pre-training
LLM Pre-training Single Node
We provide an example SFT experiment using the FineWeb dataset with a nano-GPT model, ideal for quick experimentation on a single node.
automodel examples/llm_pretrain/nanogpt_pretrain.yaml --nproc-per-node 8
LLM Supervised Fine-Tuning (SFT)
We provide an example SFT experiment using the SQuAD dataset.
LLM SFT Single Node
The default SFT configuration is set to run on a single GPU. To start the experiment:
automodel examples/llm_finetune/llama3_2/llama3_2_1b_squad.yaml
This fine-tunes the Llama3.2-1B model on the SQuAD dataset using a single GPU.
To use multiple GPUs on a single node, add the --nproc-per-node argument:
automodel examples/llm_finetune/llama3_2/llama3_2_1b_squad.yaml --nproc-per-node 8
LLM SFT Multi Node
To launch on a SLURM cluster, copy the reference sbatch script and adapt it to your cluster:
cp slurm.sub my_cluster.sub
# Edit my_cluster.sub — change CONFIG, #SBATCH directives, container, mounts, etc.
sbatch my_cluster.sub
All cluster-specific settings (nodes, GPUs, partition, container, mounts) live in your sbatch script.
NeMo-Run (nemo_run:) sections are also supported -- see our
cluster guide for details.
LLM Parameter-Efficient Fine-Tuning (PEFT)
We provide a PEFT example using the HellaSwag dataset.
LLM PEFT Single Node
# Memory-efficient SFT with LoRA
automodel examples/llm_finetune/llama3_2/llama3_2_1b_hellaswag_peft.yaml
# Override any YAML parameter via the command line:
automodel examples/llm_finetune/llama3_2/llama3_2_1b_hellaswag_peft.yaml \
--step_scheduler.local_batch_size 16
[!NOTE] Launching a multi-node PEFT example uses the same
sbatch slurm.subworkflow as the SFT case above.
VLM Supervised Fine-Tuning (SFT)
We provide a VLM SFT example using Qwen2.5-VL for end-to-end fine-tuning on image-text data.
VLM SFT Single Node
# Qwen2.5-VL on 8 GPUs
automodel examples/vlm_finetune/qwen2_5/qwen2_5_vl_3b_rdr.yaml --nproc-per-node 8
VLM Parameter-Efficient Fine-Tuning (PEFT)
We provide a VLM PEFT (LoRA) example for memory-efficient adaptation with Gemma3 VLM.
VLM PEFT Single Node
# Gemma-3-VL PEFT on 8 GPUs
automodel examples/vlm_finetune/gemma3/gemma3_vl_4b_medpix_peft.yaml --nproc-per-node 8
Supported Models
NeMo AutoModel provides native support for a wide range of models available on the Hugging Face Hub, enabling efficient fine-tuning for various domains. Below is a small sample of ready-to-use families (train as-is or swap any compatible 🤗 causal LM), you can specify nearly any LLM/VLM model available on 🤗 hub:
[!NOTE] Check out more LLM and VLM examples. Any causal LM on Hugging Face Hub can be used with the base recipe template, just overwrite
--model.pretrained_model_name_or_path <model-id>in the CLI or in the YAML config.
Performance
NeMo AutoModel achieves great training performance on NVIDIA GPUs. Below are highlights from our benchmark results:
| Model | #GPUs | Seq Length | Model TFLOPs/sec/GPU | Tokens/sec/GPU | Kernel Optimizations |
|---|---|---|---|---|---|
| DeepSeek V3 671B | 256 | 4096 | 250 | 1,002 | TE + DeepEP |
| GPT-OSS 20B | 8 | 4096 | 279 | 13,058 | TE + DeepEP + FlexAttn |
| Qwen3 MoE 30B | 8 | 4096 | 212 | 11,842 | TE + DeepEP |
For complete benchmark results including configuration details, see the Performance Summary.
🔌 Interoperability
- NeMo RL: Use AutoModel checkpoints directly as starting points for DPO/RM/GRPO pipelines.
- Hugging Face: Train any LLM/VLM from 🤗 without format conversion.
- Megatron Bridge: Optional conversions to/from Megatron formats for specific workflows.
🗂️ Project Structure
NeMo-Automodel/
├── cli/ # `automodel` / `am` CLI entry-point
│ └── app.py
├── docker/ # Container build files
├── docs/ # Documentation and guides
├── examples/
│ ├── benchmark/ # Benchmarking scripts
│ ├── llm_finetune/ # LLM finetune YAML configs
│ ├── llm_kd/ # LLM knowledge-distillation configs
│ ├── llm_pretrain/ # LLM pretrain configs
│ ├── llm_seq_cls/ # LLM sequence classification configs
│ ├── vlm_finetune/ # VLM finetune configs
│ └── vlm_generate/ # VLM generation configs
├── nemo_automodel/
│ ├── _transformers/ # HF model integrations
│ ├── components/ # Core library
│ │ ├── _peft/ # PEFT implementations (LoRA)
│ │ ├── attention/ # Attention implementations
│ │ ├── checkpoint/ # Distributed checkpointing
│ │ ├── config/
│ │ ├── datasets/ # LLM (HellaSwag, etc.) & VLM datasets
│ │ ├── distributed/ # FSDP2, Megatron FSDP, Pipelining, etc.
│ │ ├── launcher/ # Launcher backends (SLURM, k8s, NeMo-Run)
│ │ ├── loggers/ # Loggers
│ │ ├── loss/ # Optimized loss functions
│ │ ├── models/ # User-defined model examples
│ │ ├── moe/ # Optimized kernels for MoE models
│ │ ├── optim/ # Optimizer/LR scheduler components
│ │ ├── quantization/ # FP8
│ │ ├── training/ # Train utils
│ │ └── utils/ # Misc utils
│ ├── recipes/
│ │ ├── llm/ # Main LLM train loop
│ │ └── vlm/ # Main VLM train loop
│ └── shared/
├── tools/ # Developer tooling
└── tests/ # Comprehensive test suite
Citation
If you use NeMo AutoModel in your research, please cite it using the following BibTeX entry:
@misc{nemo-automodel,
title = {NeMo AutoModel: DTensor-native SPMD library for scalable and efficient training},
howpublished = {\url{https://github.com/NVIDIA-NeMo/Automodel}},
year = {2025--2026},
note = {GitHub repository},
}
🤝 Contributing
We welcome contributions! Please see our Contributing Guide for details.
📄 License
NVIDIA NeMo AutoModel is licensed under the Apache License 2.0.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file nemo_automodel-0.4.0.tar.gz.
File metadata
- Download URL: nemo_automodel-0.4.0.tar.gz
- Upload date:
- Size: 879.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
407dcdf1251ea608f3cb1f7d4a9b79b9401cfbc53386172486d69535aa9d8cb2
|
|
| MD5 |
ad55fb51305c440e24c99c927128667e
|
|
| BLAKE2b-256 |
f72b303821a87b340dc0466517e1728636d6296cfc7a00ac4dcc7406763cd38b
|
File details
Details for the file nemo_automodel-0.4.0-py3-none-any.whl.
File metadata
- Download URL: nemo_automodel-0.4.0-py3-none-any.whl
- Upload date:
- Size: 1.1 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
08e66717eabb4288eba437f1e53e85abc6f0f7f0b19264f09dcb338c9d5487a2
|
|
| MD5 |
1633bef8a2f9ed7aedce993b42a61543
|
|
| BLAKE2b-256 |
277ebec1f6444c63149004e50f5912d0718a6d11c1922bec2617d50e10788e51
|







