Notion Client extension to import notion Database into pandas Dataframe

Project description
Notion2Pandas




Notion2Pandas is a Python 3 package that extends the capabilities of the excellent notion-sdk-py by Ramnes. It enables the seamless import of a Notion database into a pandas dataframe and vice versa, requiring just a single line of code.
Installation
pip install notion2pandas
Quick Start
Synchronous Client
from notion2pandas import Notion2PandasClient
import os
# Create client
n2p = Notion2PandasClient(auth=os.environ["NOTION_TOKEN"])
# Import database to NotionDataFrame
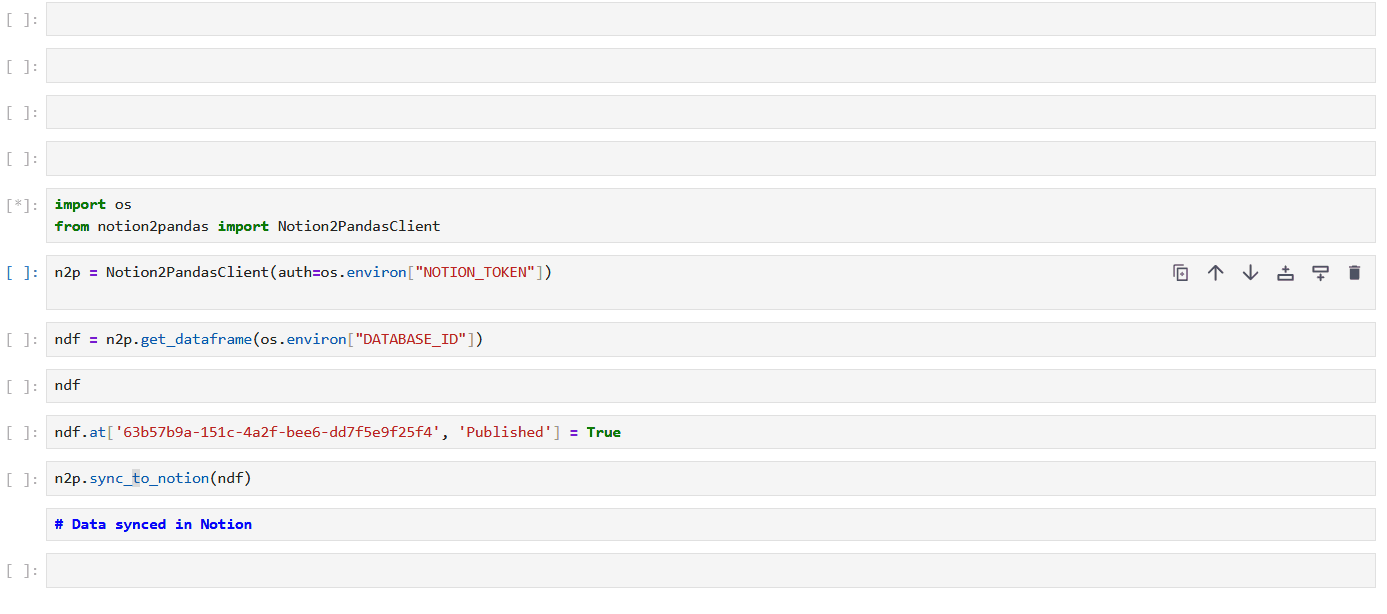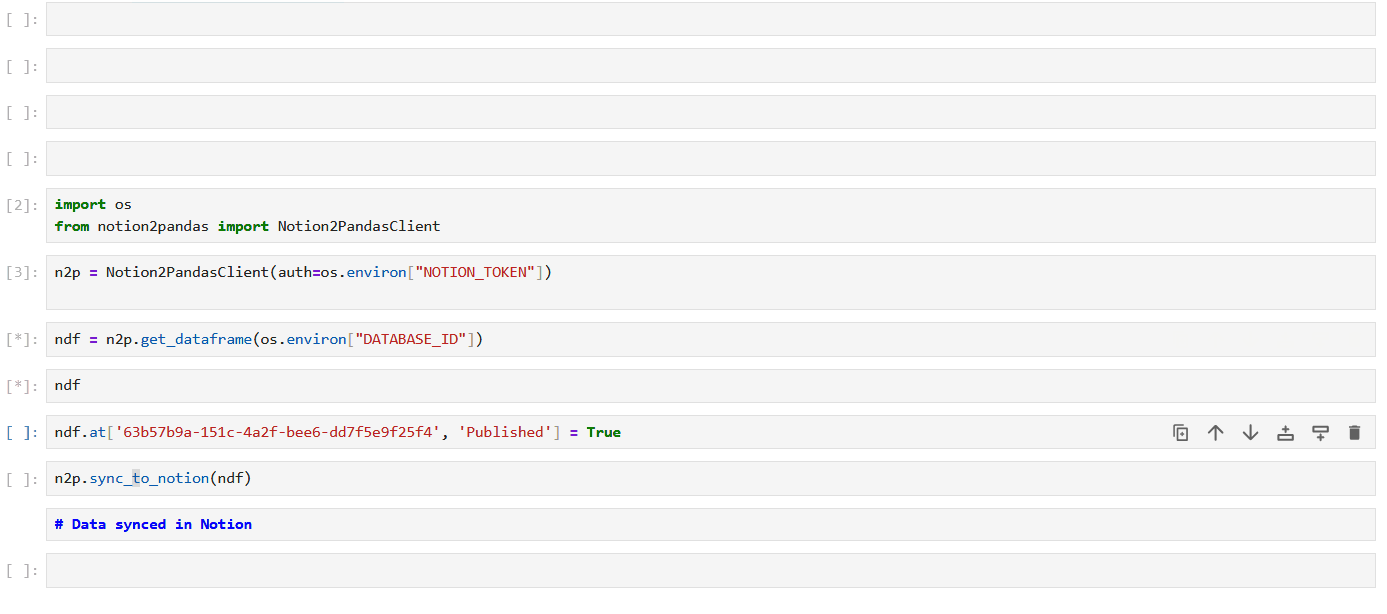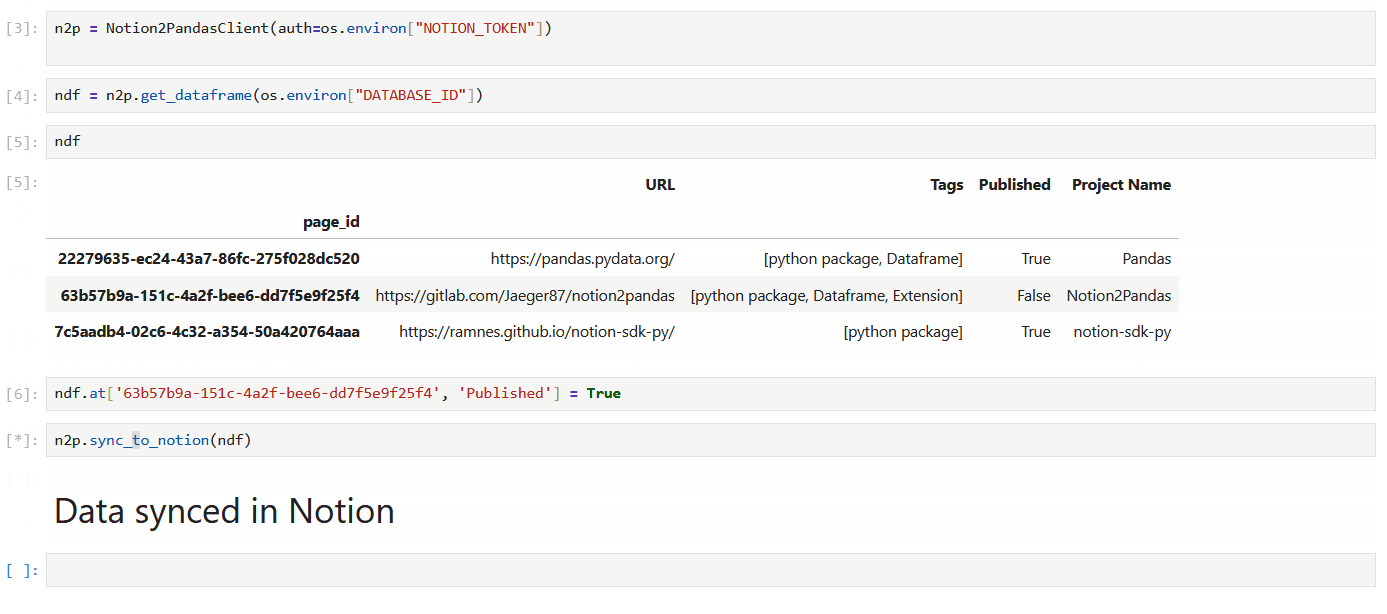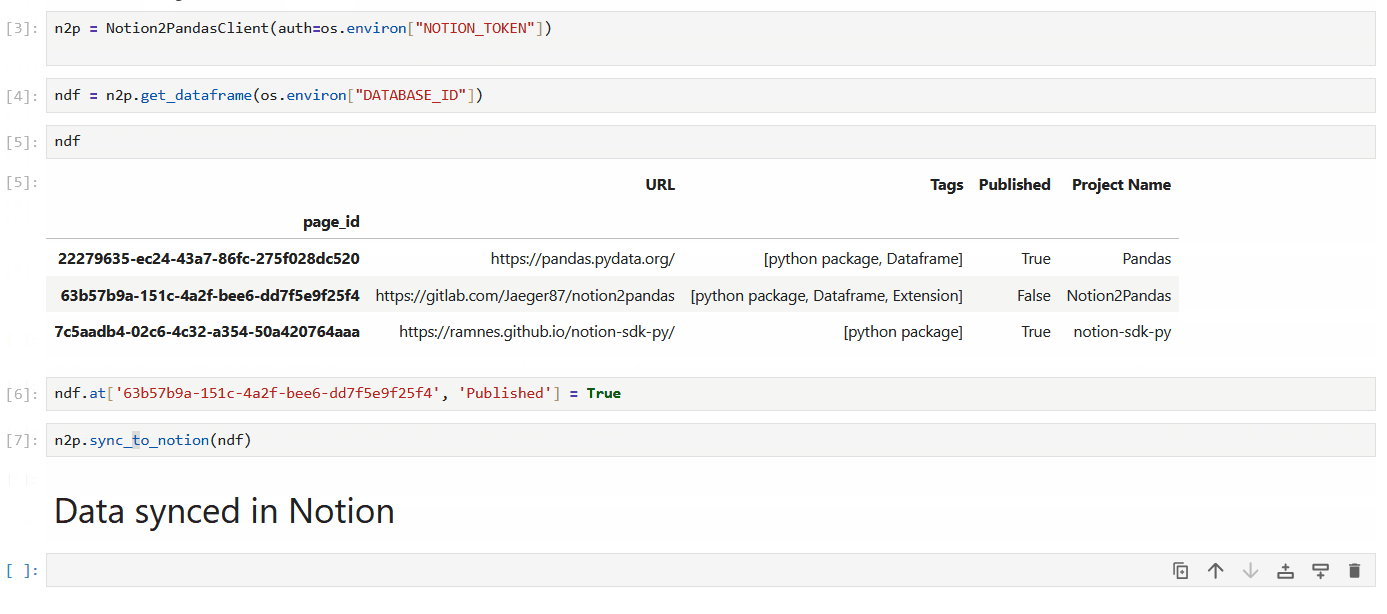
ndf = n2p.get_dataframe(os.environ["DATABASE_ID"])
# Work with your data
ndf.loc[ndf['Status'] == 'Todo', 'Status'] = 'In Progress'
# Save changes back to Notion
n2p.sync_to_notion(ndf)
Asynchronous Client
from notion2pandas import AsyncNotion2PandasClient
import os
# Create async client
async_n2p = AsyncNotion2PandasClient(auth=os.environ["NOTION_TOKEN"])
# Import database to NotionDataFrame (concurrent processing)
ndf = await async_n2p.get_dataframe(os.environ["DATABASE_ID"])
# Work with your data
ndf.loc[ndf['Status'] == 'Todo', 'Status'] = 'In Progress'
# Save changes back to Notion (concurrent updates)
await async_n2p.sync_to_notion(ndf)
For more complete, real-world examples, see the examples folder.
📖 Documentation
This README covers the basics. For everything else — filters and sorts, data sources, templates, callbacks, custom read/write functions, logging, and more — see the full documentation.
Migrating from v1.x
Version 2.0 introduces several improvements and breaking changes. If you're upgrading from v1.x:
| v1.x | v2.0 |
|---|---|
from_notion_DB_to_dataframe() |
get_dataframe() |
update_notion_DB_from_dataframe() |
sync_to_notion() |
from_notion_database_to_dataframes() |
get_dataframes() |
delete_rows_and_pages() |
delete_pages() |
Returns pd.DataFrame |
Returns NotionDataFrame |
PageID column |
page_id index |
| Manual row appending | ndf.add_page() |
📖 Complete migration guide with examples: MIGRATION-GUIDE.md
📚 v1.x documentation: README-v1.md
All v1.x methods still work with deprecation warnings - you have time to migrate!
Roadmap
Planned features for upcoming releases:
- Managing the 2700 API calls / 15 minutes rate limit
Examples
Real-world scripts covering common use cases are available in the examples folder.
Changelog
View the complete version history on the changelog page.
Support
Notion2Pandas is an open-source project. Contributions are welcome!
- Report Issues: Found a bug? Open an issue
- Propose Changes: Have an improvement? Submit a merge request
- Fork the Project: Disagree with the direction? You're free to fork with our blessing!
All proposals will be evaluated and responded to.
License
This project is open-source and available under the MIT License.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file notion2pandas-2.6.0.tar.gz.
File metadata
- Download URL: notion2pandas-2.6.0.tar.gz
- Upload date:
- Size: 2.0 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
566ea5b78a655dcf6adfe467c884a18b2a493a94cf759fc1dc8353b30cf5e266
|
|
| MD5 |
2c0a21dccf8936aea755e018c8128abd
|
|
| BLAKE2b-256 |
765d81de94fadfb6bf4c5fff0f02c0895837bf22baf7c288a66f5c5aff7946c0
|
File details
Details for the file notion2pandas-2.6.0-py3-none-any.whl.
File metadata
- Download URL: notion2pandas-2.6.0-py3-none-any.whl
- Upload date:
- Size: 44.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8b349095343964e858d6e013dc58b2a567a9dffdb9ba9c29961f9321e8d005dc
|
|
| MD5 |
865ff428e681c13c4da5d5add324c08d
|
|
| BLAKE2b-256 |
8613e33c0687cc4c6f426a1db2d426935c6fb295b6a20ff27ff7b93ba6905d16
|







