Python Tamil OCR package

Project description
OCR Tamil - Easy, Accurate and Simple to use Tamil OCR - (ஒளி எழுத்துணரி)
❤️️❤️️Please star✨ it if you like❤️️❤️️




OCR Tamil can help you extract text from signboard, nameplates, storefronts etc., from Natural Scenes with high accuracy. This version of OCR is much more robust to tilted text compared to the Tesseract, Paddle OCR and Easy OCR as they are primarily built to work on the documents texts and not on natural scenes. This model is work in progress, feel free to contribute!!!
Languages Supported 🔛
➡️ English
➡️ Tamil (தமிழ்)
Accuracy 🎯
✔️ English > 98%
✔️ Tamil > 95%
Comparison between Tesseract OCR and OCR Tamil ⚖️
| Input Image | OCR TAMIL 🏆 | Tesseract | EasyOCR |
|---|---|---|---|
 |
வாழ்கவளமுடன்✅ | க் க்கஸாரகளள௮ஊகஎளமுடன் ❌ | வாழக வளமுடன்❌ |
 |
தமிழ்வாழ்க✅ | NO OUTPUT ❌ | தமிழ்வாழ்க✅ |
 |
கோபி ✅ | NO OUTPUT ❌ | ப99❌ |
 |
தாம்பரம் ✅ | NO OUTPUT ❌ | தாம்பரம❌ |
 |
நெடுஞ்சாலைத் ✅ | NO OUTPUT ❌ | நெடுஞ்சாலைத் ✅ |
 |
அண்ணாசாலை ✅ | NO OUTPUT ❌ | ல@I9❌ |
 |
ரெடிமேடஸ் ✅ | NO OUTPUT ❌ | ரெடிமேடஸ் ❌ |
Obtained Tesseract and EasyOCR results using the Colab notebook with Tamil and english as language
Handwritten Text (Experimental)

model output: நிமிர்ந்த நன்னடை மேற்கொண்ட பார்வையும் நிலத்தில் யார்க் கும் அஞ்சாத நெறிகளும் திமிர்ந்த ஞானச் செருக்கும் இருப்பதால் செம்மை மாதர் திறம்புவ தில்லையாம் அமிழ்ந்து பேரிஞ் ளாமறி யாமையில் அவல மெய்திக் கலையின் Ca வாழவதை உமிழ்ந்து தள்ளுதல் பெண்ணற மாகுமாம் உதய கன்ன உரைப்பது கேட்டிரோ பாரதியார் ஹேமந்த் பூ
How to Install and Use OCR Tamil 👨🏼💻
Quick links🌐
📔 Detailed explanation on Medium article.
✍️ Experiment in Colab notebook
🤗 Test it in Huggingface spaces
Pip install instructions🐍
In your command line, run the following command pip install ocr_tamil
If you are using jupyter notebook , install like !pip install ocr_tamil
Python Usage - Single image inference
Text Recognition only
from ocr_tamil.ocr import OCR
image_path = r"test_images\1.jpg" # insert your own path here
ocr = OCR()
text_list = ocr.predict(image_path)
print(text_list[0])
## OUTPUT : நெடுஞ்சாலைத்

Text Detect + Recognition
from ocr_tamil.ocr import OCR
image_path = r"test_images\0.jpg" # insert your own image path here
ocr = OCR(detect=True)
texts = ocr.predict(image_path)
print(" ".join(text_list[0]))
## OUTPUT : கொடைக்கானல் Kodaikanal

Batch inference mode 💻
Text Recognition only
from ocr_tamil.ocr import OCR
image_path = [r"test_images\1.jpg",r"test_images\2.jpg"] # insert your own image paths here
ocr = OCR()
text_list = ocr.predict(image_path)
for text in text_list:
print(text)
## OUTPUT : நெடுஞ்சாலைத்
## OUTPUT : கோபி
Text Detect + Recognition
from ocr_tamil.ocr import OCR
image_path = [r"test_images\0.jpg",r"test_images\tamil_sentence.jpg"] # insert your own image paths here
ocr = OCR(detect=True)
text_list = ocr.predict(image_path)
for item in text_list:
print(" ".join(item))
## OUTPUT : கொடைக்கானல் Kodaikanal
## OUTPUT : செரியர் யற்கை மூலிகைகளில் இருந்து ஈர்த்தெடுக்க்கப்பட்ட வீரிய உட்பொருட்களை உள்ளடக்கி எந்த இரசாயன சேர்க்கைகளும் இல்லாமல் உருவாக்கப்பட்ட இந்தியாவின் முதல் சித்த தயாரிப்பு
Advanced usage
- If you need to get the confidence information of each text, initialize the OCR(details=1)
- If you need to get the confidence and bounding box information of each text, initialize the OCR(details=2)
Tested using Python 3.10 on Windows & Linux (Ubuntu 22.04) Machines
Applications⚡
- ADAS system navigation based on the signboards + maps (hybrid approach) 🚁
- License plate recognition 🚘
Limitations⛔
- Unable to read the text if they are present in rotated forms


-
Currently supports Only English and Tamil Language
-
Document Text reading capability is limited. Auto identification of Paragraph, line are not supported along with Text detection model inability to detect and crop the Tamil text leads to accuracy decrease (WORKAROUND Can use your own text detection model along with OCR tamil text recognition model)

Cropped Text from Text detection Model
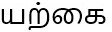
Character **இ** missing due to text detection model error
**?**யற்கை மூலிகைகளில் இருந்து ஈர்த்தெடுக்கக்கப்பட்ட வீரிய உட்பொருட்களை உள்ளடக்கி எந்த இரசாயன சேர்க்கைகளும் இல்லாமல் உருவாக்கப்பட்ட இந்தியாவின் முதல் சித்த தயாரிப்பு
Acknowledgements 👏
Text detection - CRAFT TEXT DECTECTION
Text recognition - PARSEQ
@InProceedings{bautista2022parseq,
title={Scene Text Recognition with Permuted Autoregressive Sequence Models},
author={Bautista, Darwin and Atienza, Rowel},
booktitle={European Conference on Computer Vision},
pages={178--196},
month={10},
year={2022},
publisher={Springer Nature Switzerland},
address={Cham},
doi={10.1007/978-3-031-19815-1_11},
url={https://doi.org/10.1007/978-3-031-19815-1_11}
}
@inproceedings{baek2019character,
title={Character Region Awareness for Text Detection},
author={Baek, Youngmin and Lee, Bado and Han, Dongyoon and Yun, Sangdoo and Lee, Hwalsuk},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={9365--9374},
year={2019}
}
Citation
@InProceedings{GnanaPrasath,
title={Tamil OCR},
author={Gnana Prasath D},
month={01},
year={2024},
url={https://github.com/gnana70/tamil_ocr}
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ocr_tamil-0.2.7.tar.gz.
File metadata
- Download URL: ocr_tamil-0.2.7.tar.gz
- Upload date:
- Size: 42.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2480ceae4824c35a2dc2d314a6c0533132e6eecd5181c6de6f2cfc2b59361fde
|
|
| MD5 |
412ec11f80628083061c95222b5a10dd
|
|
| BLAKE2b-256 |
318ad632309698dca9869f7c26c17cd0d790f4d546f444af9a8727320ff89b8a
|
File details
Details for the file ocr_tamil-0.2.7-py3-none-any.whl.
File metadata
- Download URL: ocr_tamil-0.2.7-py3-none-any.whl
- Upload date:
- Size: 49.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5dfb2d31eb0ec11233392a8e2364b5cb27fd8f85f3d735ca5a7fcd1713e24d9f
|
|
| MD5 |
9b0c61ae387ec3cfb8b7b61f4eac326e
|
|
| BLAKE2b-256 |
171f6c56bcd3739e544cfc6bda959efa833a110c8de44e4f42b79b7376d422fc
|







