High-performance Chinese text conversion (Simplified ↔ Traditional), segmentation and keyword extraction powered by Rust, PyO3, Jieba and OpenCC lexicons.

Project description
opencc_jieba_pyo3





opencc_jieba_pyo3 is a Python extension module powered
by Rust, Jieba and PyO3, providing
fast and accurate conversion between different Chinese text variants
using opencc-jieba-rs and OpenCC
algorithms.
Features
- Convert between Simplified, Traditional, Hong Kong, Taiwan, and Japanese Kanji Chinese text.
- Fast and memory-efficient, leveraging Rust's performance.
- Easy-to-use Python API.
- Supports punctuation conversion and automatic text code detection.
- Chinese word (Both Traditional and Simplified) segmentation (Jieba).
- Keyword extraction (TF-IDF, TextRank).
- Utility functions for punctuation handling and language detection.
🔁 Supported Conversion Configs
| Code | Description |
|---|---|
s2t |
Simplified → Traditional |
t2s |
Traditional → Simplified |
s2tw |
Simplified → Traditional (Taiwan) |
tw2s |
Traditional (Taiwan) → Simplified |
s2twp |
Simplified → Traditional (Taiwan) with idioms |
tw2sp |
Traditional (Taiwan) → Simplified with idioms |
s2hk |
Simplified → Traditional (Hong Kong) |
hk2s |
Traditional (Hong Kong) → Simplified |
t2tw |
Traditional → Traditional (Taiwan) |
tw2t |
Traditional (Taiwan) → Traditional |
t2twp |
Traditional → Traditional (Taiwan) with idioms |
tw2tp |
Traditional (Taiwan) → Traditional with idioms |
t2hk |
Traditional → Traditional (Hong Kong) |
hk2t |
Traditional (Hong Kong) → Traditional |
t2jp |
Japanese Kyujitai → Shinjitai |
jp2t |
Japanese Shinjitai → Kyujitai |
Installation
Build and install the Python wheel using maturin:
# In project root
maturin build --release
pip install ./target/wheels/opencc_jieba_pyo3-<version>-cp<pyver>-abi3-<platform>.whl
Or for development:
maturin develop -r
See BUILD.md for detailed build and install instructions.
Usage
Python
from opencc_jieba_pyo3 import OpenCC
text = "“春眠不觉晓,处处闻啼鸟。”"
segment_text = "我独自来到无人海岸线"
opencc = OpenCC("s2t")
converted = opencc.convert(text, punctuation=True)
print(converted) # 「春眠不覺曉,處處聞啼鳥。」
# Segmentation
words = opencc.jieba_cut(segment_text, hmm=True)
print(words) # ['我', '独自', '来到', '无人', '海岸线']
# Segmentation and join
joined = opencc.jieba_segment_join(segment_text, mode="cut", delim="/")
print(joined) # 我/独自/来到/无人/海岸线
joined = opencc.jieba_segment_join(segment_text, mode="search", delim="/")
print(joined) # 我/独自/来到/无人/海岸/岸线/海岸线
joined = opencc.jieba_segment_join(segment_text, mode="full", delim="/")
print(joined) # 我/独/独自/自/自来/来/来到/到/无/无人/人/人海/海/海岸/海岸线/岸/岸线/线
joined = opencc.jieba_segment_join(segment_text, mode="tag", delim=" ")
print(joined) # 我/r 独自/d 来到/v 无人/n 海岸线/n
# Keyword extraction (TextRank)
keywords = opencc.jieba_keyword_extract_textrank(segment_text, top_k=3)
print(keywords) # ['海岸线', '无人', '来到']
# Keyword extraction (TF-IDF)
keywords_tfidf = opencc.jieba_keyword_extract_tfidf(segment_text, top_k=3)
print(keywords_tfidf) # ['海岸线', '独自', '无人']
# Keyword weights (TextRank)
kw_weights = opencc.jieba_keyword_weight_textrank(segment_text, top_k=3)
print(kw_weights) # [('海岸线', 9987587364.22353), ('无人', 9986551019.39923), ('来到', 9985428148.988083)]
# Keyword weights (TF-IDF)
kw_weights_tfidf = opencc.jieba_keyword_weight_tfidf(segment_text, top_k=3)
print(kw_weights_tfidf) # [('海岸线', 1.995445949425), ('独自', 1.8446462134525), ('无人', 1.7299179778125)]
CLI
You can also use the CLI interface via Python module or Python script:
Features are:
convert: Convert Chinese text using OpenCC + Jiebasegment: Segment Chinese text using Jiebaoffice: Convert Office document Chinese text using OpenCC + Jieba
convert
Module: python -m opencc_jieba_pyo3 convert --help
Script: opencc-jieba-pyo3 convert --help
usage: opencc_jieba_pyo3 convert [-h] [-i <file>] [-o <file>] [-c <conversion>] [-p] [--in-enc <encoding>] [--out-enc <encoding>]
options:
-h, --help show this help message and exit
-i, --input <file> Read original text from <file>.
-o, --output <file> Write converted text to <file>.
-c, --config <conversion>
Conversion configuration: [s2t|s2tw|s2twp|s2hk|t2s|tw2s|tw2sp|hk2s|jp2t|t2jp]
-p, --punct Punctuation conversion
--in-enc <encoding> Encoding for input
--out-enc <encoding> Encoding for output
segment
python -m opencc_jieba_pyo3 segment --help
opencc-jieba-pyo3 convert segment --help
usage: opencc-jieba-pyo3 segment [-h] [-i <file>] [-o <file>] [-d <char>] [-s <char>] [--no-hmm] [-m {cut,search,full,tag}] [--in-enc <encoding>]
[--out-enc <encoding>]
optional arguments:
-h, --help show this help message and exit
-i <file>, --input <file>
Read input text from <file>. (default: None)
-o <file>, --output <file>
Write segmented text to <file>. (default: None)
-d <char>, --delim <char>
Delimiter to join segments (default: )
-s <char>, --separator <char>
Separator for segment mode: tag (default: /)
--no-hmm Disable HMM (default: False)
-m {cut,search,full,tag}, --mode {cut,search,full,tag}
Segmentation mode (default: cut)
--in-enc <encoding> Encoding for input (default: UTF-8)
--out-enc <encoding> Encoding for output (default: UTF-8)
office
python -m opencc_jieba_pyo3 office --help
usage: opencc_jieba_pyo3 office [-h] [-i <file>] [-o <file>] [-c <conversion>] [-p] [-f <format>] [--auto-ext] [--keep-font]
options:
-h, --help show this help message and exit
-i, --input <file> Input Office document from <file>.
-o, --output <file> Output Office document to <file>.
-c, --config <conversion>
conversion: s2t|s2tw|s2twp|s2hk|t2s|tw2s|tw2sp|hk2s|jp2t|t2jp
-p, --punct Punctuation conversion
-f, --format <format>
Target Office format (e.g., docx, xlsx, pptx, odt, ods, odp, epub)
--auto-ext Auto-append extension to output file
--keep-font Preserve font-family information in Office content)
python -m opencc_jieba_pyo3 convert -i input.txt -o output.txt -c s2t --punct
opencc-jieba-pyo3 convert -i input.txt -o output.txt -c s2t --punct
python -m opencc_jieba_pyo3 segment -i input.txt -o output.txt --delim "/"
opencc-jieba-pyo3 segment -i input.txt -o output.txt --delim "/" --mode search
python -m opencc_jieba_pyo3 office -i input.docx -o output.docx -c s2t --punct --keep-font
opencc-jieba-pyo3 office -i input.epub -o output.epub -c s2tw --punct
API
Class: OpenCC
Unified Python interface for OpenCC and Jieba functionalities.
Constructor
OpenCC(config: str = "s2t")config: Conversion configuration (see above). Defaults to"s2t".
Attributes
config: str- Current OpenCC conversion configuration.
Methods
-
is_valid_config(config: str) -> bool- Check whether
configis a supported OpenCC conversion name.
- Check whether
-
supported_configs() -> list[str]- Return all supported OpenCC conversion names in canonical lowercase form.
-
canonicalise_config(config: str) -> str- Normalize a valid config name to its canonical lowercase form.
-
set_config(config: str) -> None- Update the active OpenCC conversion configuration.
-
get_config() -> str- Return the current OpenCC conversion configuration.
-
convert(input: str, punctuation: bool = False) -> str- Convert Chinese text using the current OpenCC config.
input: Input text.punctuation: Whether to convert Chinese/Japanese punctuation to the target variant.- Returns: Converted text as a string.
-
zho_check(input: str) -> int- Detect the type of Chinese in the input text.
- Returns: Integer code (1: Traditional, 2: Simplified, 0: Others).
-
jieba_cut(input: str, hmm: bool = True) -> list[str]- Segment Chinese text using Jieba accurate mode.
input: Input text.hmm: Whether to use HMM for new words.- Returns: List of segmented words.
-
jieba_cut_for_search(input: str, hmm: bool = True) -> list[str]- Segment Chinese text in Jieba search mode.
- Produces finer-grained tokens suitable for search indexing.
-
jieba_cut_all(input: str) -> list[str]- Segment Chinese text in Jieba full mode.
- Returns all possible token matches without disambiguation.
-
jieba_tag(input: str, hmm: bool = True) -> list[tuple[str, str]]- Perform Jieba part-of-speech tagging.
- Returns
(word, tag)tuples.
-
jieba_segment_join(input: str, mode: str = "cut", delim: str = " ", hmm: bool = True, separator: str = "/") -> str- Segment text and join the result into a single string.
mode: One of"cut","search","full", or"tag".delim: Delimiter used to join segments or tagged tokens.hmm: Used by"cut","search", and"tag"modes.separator: Separator between word and POS tag in"tag"mode.
-
jieba_cut_and_join(input: str, delimiter: str = "/") -> str- Deprecated compatibility wrapper for
jieba_segment_join(input, mode="cut", delim=delimiter). input: Input text.delimiter: Delimiter for joining words.- Returns: Joined segmented string.
- Deprecated compatibility wrapper for
-
jieba_keyword_extract_textrank(input: str, top_k: int = 10, allowed_pos: list[str] | None = None) -> list[str]- Extract keywords using the TextRank algorithm.
input: Input text.top_k: Number of keywords to extract.allowed_pos: Optional POS filter list. Each item may contain one or more POS tags separated by whitespace.- Returns: List of keywords.
-
jieba_keyword_extract_tfidf(input: str, top_k: int = 10, allowed_pos: list[str] | None = None) -> list[str]- Extract keywords using the TF-IDF algorithm.
input: Input text.top_k: Number of keywords to extract.allowed_pos: Optional POS filter list. Each item may contain one or more POS tags separated by whitespace.- Returns: List of keywords.
jieba_keyword_weight_textrank(input: str, top_k: int = 10, allowed_pos: list[str] | None = None) -> list[tuple[str, float]]
-
Extract keywords and their weights using TextRank.
-
input: Input text. -
top_k: Number of keywords to extract. -
allowed_pos: Optional POS filter list. Each item may contain one or more POS tags separated by whitespace. -
Returns: List of (keyword, weight) tuples.
jieba_keyword_weight_tfidf(input: str, top_k: int = 10, allowed_pos: list[str] | None = None) -> list[tuple[str, float]]
- Extract keywords and their weights using TF-IDF.
input: Input text.top_k: Number of keywords to extract.allowed_pos: Optional POS filter list. Each item may contain one or more POS tags separated by whitespace.- Returns: List of (keyword, weight) tuples.
Development
- Rust source: src/lib.rs
- Python bindings: /opencc_jieba_pyo3/__init __.py, opencc_jieba_pyo3/opencc_jieba_pyo3.pyi
- CLI: opencc_jieba_pyo3/__main __.py
Rust Module Required
opencc-jieba-rs : A Rust implementation of Jieba + OpenCC
Benchmarks
Package: opencc_jieba_pyo3
Python 3.13.4 (tags/v3.13.4:8a526ec, Jun 3 2025, 17:46:04) [MSC v.1943 64 bit (AMD64)]
Platform: Windows-11-10.0.26100-SP0
Processor: Intel64 Family 6 Model 191 Stepping 2, GenuineIntel
BENCHMARK RESULTS
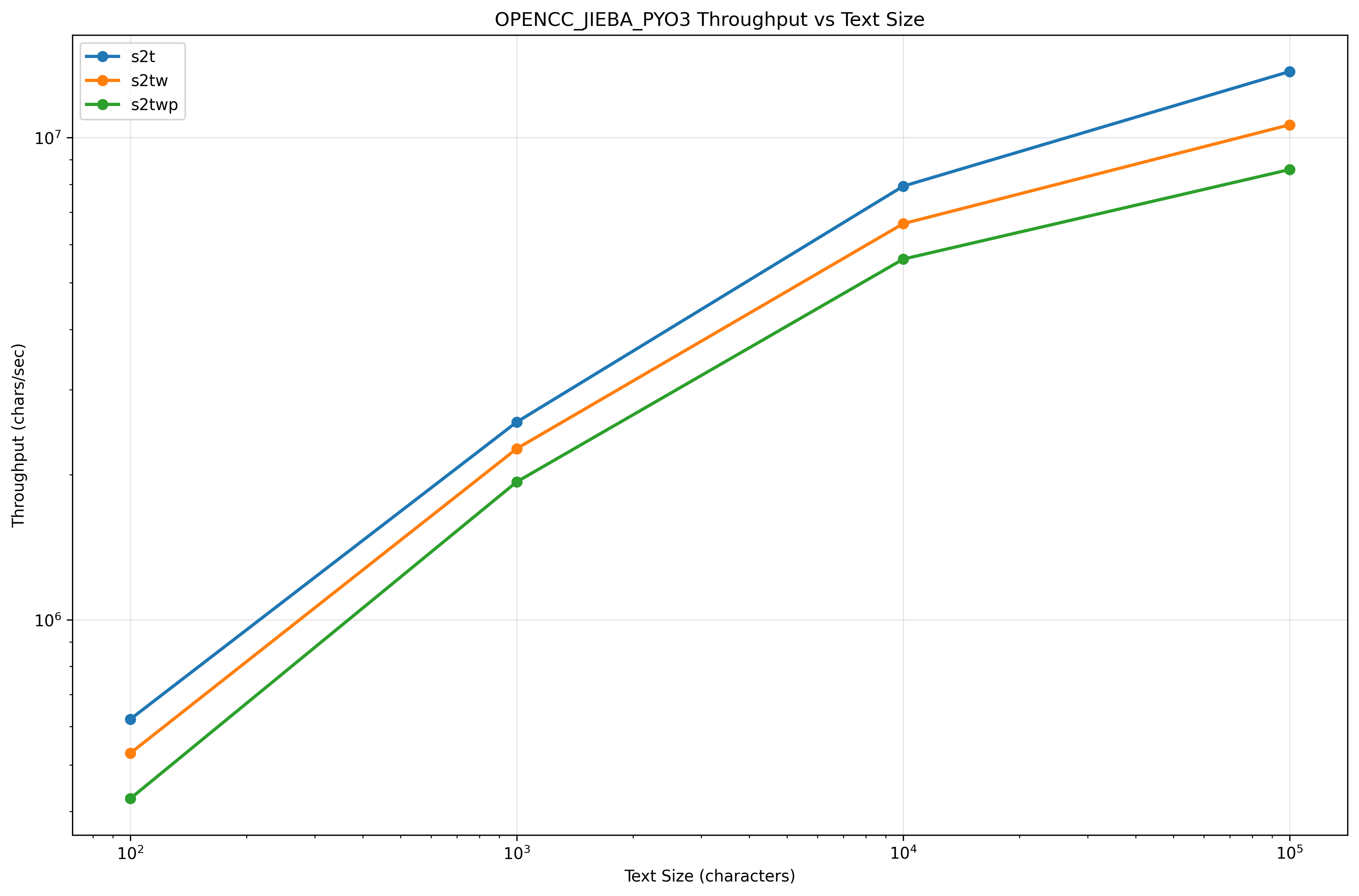
| Method | Config | TextSize | Mean | StdDev | Min | Max | Ops/sec | Chars/sec |
|---|---|---|---|---|---|---|---|---|
| Convert_Small | s2t | 100 | 0.161 ms | 0.109 ms | 0.080 ms | 0.794 ms | 6,217 | 621,740 |
| Convert_Medium | s2t | 1,000 | 0.389 ms | 0.092 ms | 0.286 ms | 0.829 ms | 2,571 | 2,571,236 |
| Convert_Large | s2t | 10,000 | 1.261 ms | 0.314 ms | 1.072 ms | 2.580 ms | 793 | 7,932,120 |
| Convert_XLarge | s2t | 100,000 | 7.290 ms | 0.464 ms | 6.864 ms | 9.848 ms | 137 | 13,716,798 |
| Convert_Small | s2tw | 100 | 0.189 ms | 0.104 ms | 0.103 ms | 0.620 ms | 5,285 | 528,519 |
| Convert_Medium | s2tw | 1,000 | 0.442 ms | 0.152 ms | 0.322 ms | 1.084 ms | 2,264 | 2,264,206 |
| Convert_Large | s2tw | 10,000 | 1.508 ms | 0.200 ms | 1.367 ms | 2.371 ms | 663 | 6,631,682 |
| Convert_XLarge | s2tw | 100,000 | 9.403 ms | 0.585 ms | 9.009 ms | 13.320 ms | 106 | 10,635,363 |
| Convert_Small | s2twp | 100 | 0.235 ms | 0.113 ms | 0.129 ms | 0.648 ms | 4,256 | 425,586 |
| Convert_Medium | s2twp | 1,000 | 0.518 ms | 0.112 ms | 0.363 ms | 0.913 ms | 1,932 | 1,932,266 |
| Convert_Large | s2twp | 10,000 | 1.786 ms | 0.209 ms | 1.590 ms | 2.739 ms | 560 | 5,598,571 |
| Convert_XLarge | s2twp | 100,000 | 11.644 ms | 0.979 ms | 10.892 ms | 17.130 ms | 86 | 8,588,034 |
Throughput VS Size
License
Powered by Rust, Jieba, PyO3, OpenCC and opencc-jieba-rs.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file opencc_jieba_pyo3-0.7.5.tar.gz.
File metadata
- Download URL: opencc_jieba_pyo3-0.7.5.tar.gz
- Upload date:
- Size: 29.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
34271723d39758110db81185fb83f5923dfb8e41f4eb0af5002738194837b4e6
|
|
| MD5 |
6644adb6eb0a308f14583094d5e2f6aa
|
|
| BLAKE2b-256 |
e9c9a41713911fccf427a36d5bad7db3ee795640f1241cc5ff847f8c40ea6313
|
File details
Details for the file opencc_jieba_pyo3-0.7.5-cp38-abi3-win_arm64.whl.
File metadata
- Download URL: opencc_jieba_pyo3-0.7.5-cp38-abi3-win_arm64.whl
- Upload date:
- Size: 7.0 MB
- Tags: CPython 3.8+, Windows ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
59cbf1fcbe334ac7daec8b09a845fcd86ab2a16900d072f5fe7549550cfae2f7
|
|
| MD5 |
e903f5654846ec784dcd466cf8fed3de
|
|
| BLAKE2b-256 |
2c425642d3966a82d220697d26b9f5803327d78cb7288251cbb3c6875d64f0e5
|
File details
Details for the file opencc_jieba_pyo3-0.7.5-cp38-abi3-win_amd64.whl.
File metadata
- Download URL: opencc_jieba_pyo3-0.7.5-cp38-abi3-win_amd64.whl
- Upload date:
- Size: 7.1 MB
- Tags: CPython 3.8+, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d0635c306ca88fdb8c7e8b795b436d021ad2d7254d8a7e2442e973160352fbdf
|
|
| MD5 |
e96e8a663a7b9e68e99caae29076aebd
|
|
| BLAKE2b-256 |
9dafdb3f77a441bf20ce94e647358f93a411e54a949a7620cd95035af3c07f86
|
File details
Details for the file opencc_jieba_pyo3-0.7.5-cp38-abi3-win32.whl.
File metadata
- Download URL: opencc_jieba_pyo3-0.7.5-cp38-abi3-win32.whl
- Upload date:
- Size: 6.9 MB
- Tags: CPython 3.8+, Windows x86
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c1d9a1eac64075c70cfe47a1671ddeeea580d2f6fab693bef51ca7633c0abd3e
|
|
| MD5 |
8ee1582806dd415fef8f624eb2a78f8f
|
|
| BLAKE2b-256 |
fcecb2529487e59c64c76e2537971a9515a56df018a2ea80cbf2d70944f3ec0f
|
File details
Details for the file opencc_jieba_pyo3-0.7.5-cp38-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: opencc_jieba_pyo3-0.7.5-cp38-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 7.4 MB
- Tags: CPython 3.8+, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bc8f6d44148ae6d59d251eacd3a76d8c36f636279209174743e4b911bdcbb326
|
|
| MD5 |
1d2b25a3bcfd930b551c0d82473403f6
|
|
| BLAKE2b-256 |
19006ee88ebeea1165b7636b2daf69ec9255f4a38ef24c695d61c772b1cd2a4a
|
File details
Details for the file opencc_jieba_pyo3-0.7.5-cp38-abi3-manylinux_2_17_aarch64.manylinux2014_aarch64.whl.
File metadata
- Download URL: opencc_jieba_pyo3-0.7.5-cp38-abi3-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
- Upload date:
- Size: 7.5 MB
- Tags: CPython 3.8+, manylinux: glibc 2.17+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b1c0ab66d313cb7a7963a567a7b6602606b208a08357faca77f6fa31785d802e
|
|
| MD5 |
6683acde41b3b4eaf1154d720acefdaa
|
|
| BLAKE2b-256 |
52852d2c780af6ded8bb7969b3c28bade485b4f82c355d7a9c6be0bf4a3ff1b4
|
File details
Details for the file opencc_jieba_pyo3-0.7.5-cp38-abi3-macosx_11_0_arm64.whl.
File metadata
- Download URL: opencc_jieba_pyo3-0.7.5-cp38-abi3-macosx_11_0_arm64.whl
- Upload date:
- Size: 7.2 MB
- Tags: CPython 3.8+, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6b83f93ca42817314a9bb9cda1428760f0f4daa4122a8a74463a3c2228f488cf
|
|
| MD5 |
ee048c6ed13a49209aa241b975484011
|
|
| BLAKE2b-256 |
a6cd81e9fef2471f5f14f3f2bbfe42b1117e23bf8ea305a3bf2bdffb96e4138a
|
File details
Details for the file opencc_jieba_pyo3-0.7.5-cp38-abi3-macosx_10_12_x86_64.whl.
File metadata
- Download URL: opencc_jieba_pyo3-0.7.5-cp38-abi3-macosx_10_12_x86_64.whl
- Upload date:
- Size: 7.2 MB
- Tags: CPython 3.8+, macOS 10.12+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
025b37904a213e8693727fcad4606b9cf15d524cd921d5a8c48bc408b0620004
|
|
| MD5 |
1476fad563cf9692250097ba0254788f
|
|
| BLAKE2b-256 |
06a05e7278719e4d9052cdc2a3861f6970940913f0b174345f2ee7be590a9346
|







