Whisp (What is in that plot) is an open-source solution which helps to produce relevant forest monitoring information and support compliance with deforestation-related regulations.

Project description
whisp




Convergence of Evidence
Whisp stands for "What is in that plot"?
Numerous publicly available Earth Observation maps provide data on tree cover, land use, and forest disturbances. However, these maps often differ from one another because they use various definitions and classification systems. As a result, no single map can provide a complete picture of any specific area. To address this issue, the Forest Data Partnership (FDaP) and the AIM4Forests Programme advocate for the Convergence of Evidence approach.
The Forest Data Partnership promotes this approach for forest and commodities monitoring, assuming that
- no single source of geospatial data can tell the whole story around any given plot of land;
- all the existing, published and available datasets contribute to telling that story.
Contents
- Whisp pathways
- Whisp datasets
- Whisp notebooks
- System setup
- Add data layers
- Contribute to the code
- Code of conduct
Whisp pathways
Whisp can currently be used directly or implemented in your own code through three different pathways:
-
The Whisp App with its simple interface can be used right here or called from other software by API. The Whisp App currently supports the processing of up to 1000 geometries per job. The original JS & Python code behind the Whisp App and API can be found here.
-
Whisp in Earthmap supports the visualization of geometries on actual maps with the possibility to toggle different relevant map products around tree cover, commodities and deforestation. It is practical for demonstration purposes and spot checks of single geometries but not recommended for larger datasets.
-
Datasets of any size, especially when holding more than 1000 geometries, can be "whisped" through the python package on pip. See example Colab Notebook for implementation with a geojson input. For the detailed procedure please go to the section Whisp notebooks.
Whisp datasets
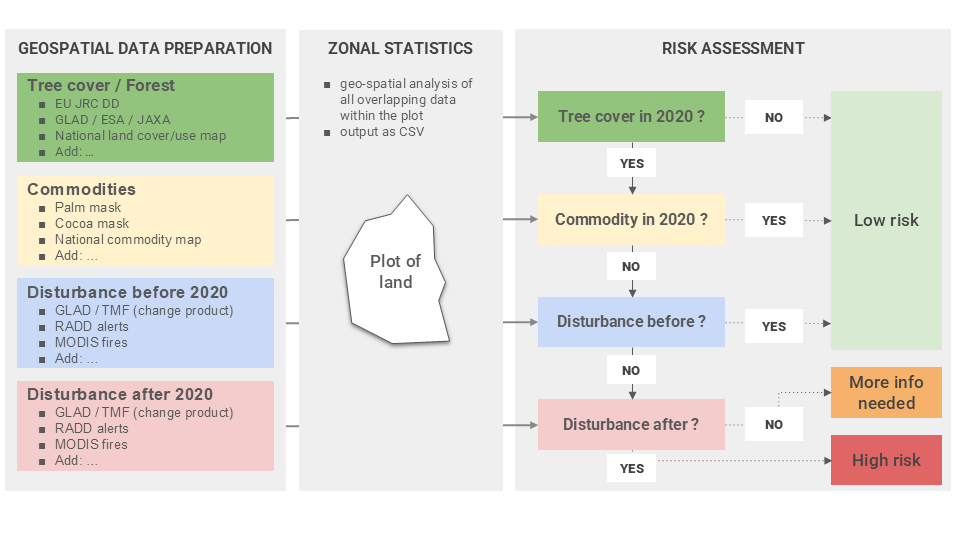
Whisp implements the convergence of evidence approach by providing a transparent and public processing flow using datasets covering the following categories:
- Tree and forest cover (at the end of 2020);
- Commodities (i.e., crop plantations and other agricultural uses at the end of 2020);
- Disturbances before 2020 (i.e., degredation or deforestation until 2020-12-31);
- Disturbances after 2020 (i.e., degredation or deforestation from 2021-01-01 onward).
There are multiple datasets for each category. Find the full current list of datasets used in Whisp here. Whisp checks the plots provided by the user by running zonal statistics on them to answer the following questions:
- Was there tree cover in 2020?
- Were there commodity plantations or other agricultural uses in 2020?
- Were there disturbances until 2020-12-31?
- Were there disturbances after 2020-12-31 / starting 2021-01-01?
If no treecover dataset indicates any tree cover for a plot by the end of 2020, Whisp will deem the deforestation risk as low.
If one or more treecover datasets indicate tree cover on a plot by the end of 2020, but a commodity dataset indicates agricultural use by the end of 2020, Whisp will deem the deforestation risk as low.
If treecover datasets indicate tree cover on a plot by late 2020, no commodity datasets indicate agricultural use, but a disturbance datasets indicates disturbances before the end of 2020, Whisp will deem the deforestation risk as low. Such deforestation has happened before the EUDR cutoff date and therefore does not count as high risk for the EUDR.
Now, if the datasets under 1., 2. & 3. indicate that there was tree cover, but no agriculture and no disturbances before or by the end of 2020, the Whisp algorithm checks whether degredation or deforestation have been reported in a disturbance dataset after 2020-12-31. If they have, Whisp will deem the deforestation risk as high.
However, under the same circumstances but with no disturbances reported after 2020-12-31 there is insufficient evidence and the Whisp output will be "More info needed". Such can be the case for, e.g., cocoa or coffee grown under the shade of treecover or agroforestry.
The Whisp algorithm visualized:

Run Whisp package using Python Notebooks
For most users we suggest using the Whisp App to porcess their plots.
For bespoke analyses using or implemetation in a python workflow you can sue the python package directly.
See example Colab Notebook
Requirements
- A Google Earth Engine (GEE) account.
- A registered cloud GEE project.
- Some experience in Python or a similar language.
More info on Whisp can be found in here
Python package installation
... pip install openforis-whisp
import openforis_whisp as whisp ...
If running the package locally we recommend using a virtual environment to keep your main python installation clean.
The package relies upon the earth engine api being setup correctly using a registered cloud project
Earth Engine project name
gee_project_name="my-ee-project"
Where you must replace the GEE project in the ee.Initialize(project=gee_project_name)
Note: this should be a registered cloud project. If unsure of this check pic here: https://developers.google.com/earth-engine/cloud/assets
More info on Whisp can be found in here
How to add data layers to Whisp
There are two main approaches: to request a layer be incorporated into the core Whisp inputs, or to add in your own data directly to complement the core ones in Whisp
Requesting a dataset addition
If you think a particular dataset has wide applicability for Whisp users, you can request it be added to the main Whisp repository by logging as an issue in Github [here] (https://github.com/forestdatapartnership/whisp/issues/). Before requesting consider: 1) is the resolution high enough for plot level analysis (e.g. 30m or 10m resolution), 2) is there an indication of data quality (e.g. accuracy assessment detailed in a scientific publication) and 3) is there relevant metadata available.
Adding your own dataset for a bespoke Whisp analysis (using the Python Notebooks)
Adding your To add other datasets, such as that are specific to your circumstances, or can’t be shared directly in GEE, follow the steps and guidance below.
- Edit the datasets.py and add in a function to make a binary GEE image (i.e., where values are either 0 or 1*). Make sure the function name ends with "_prep", as only functions with this suffix are used.
- Choose a name to represent the data layer in the final CSV output. Place in speech brackets in the .rename() section at the end of the function. See examples elsewhere in the functions in this script.
- Edit parameters/lookup_gee_datasets.csv to include the chosen dataset name in a new row. Make sure other relevant columns are filled in.
The above assumes a single band image that is being included, which results in a single column being added. If you have multiband images to add and want each band to be a layer in Whisp, make sure each band is named. Make sure to add all the bands to the lookup CSV (see Step 3), else they won’t appear in the output.
How to fill out the columns parameters/lookup_gee_datasets.csv a. name: the name for the dataset column. NB must be exactly the same as the name of the image band in step 1. b. order: choose a number for where you want the dataset column placed in the CSV output. c. theme: a word denoting the dataset Theme. Currently there are five themes where i to iv correspond to: i. treecover: for forest or treecover at the end of 2020 ii. commodities: representing commodities in 2020 (typically ones that tree cover might be confused with in remote sensing products). iii. disturbance_before: forest/tree cover disturbance before the end of 2020 iv. disturbance_after: forest/tree cover disturbance after the end of 2020 v. ancillary: other relevant layers, such as representing protected areas or areas of importance for biodiversity. d. use_for_risk: if 1 is added here this dataset is included in the risk calculations. The type of risk indicator it will contribute to is automatically governed by the “theme” column. NB if there is in a 1 in the "exclude_from_output" column this over-rules all of the above and the dataset is ignored. There are functions (in the modules/risk.py), to create lists for each of the 4 indicators from the lookup csv. These are used in the "whisp_risk" function for creating default columns to include in the final overall risk column. e. exclude_from_output: removes the column from the formatted final table (to remove input code out the function in the datasets.py) f. col_type: - choose 'float32' (most ) - exceptions are 'bool' for showing True/False, where values >0 gives True. e. is nullable: set to 1 f. is required: set to 0 g. corresponding variable: the name of the function for creating the dataset in datasets.py (should end with "_prep")
Tips for preparing and adding in your data
• It’s sometimes easier to do initial checks in JavaScript and check all looks ok on the map in Code Editor, and then convert the code into Python. Tools that can help convert include AI interfaces such as ChatGPT, or [geemap] (https://giswqs.medium.com/15-converting-earth-engine-javascripts-to-python-code-with-just-a-few-mouse-clicks-6aa02b1268e1/). • Check your data: Python functions will still need sense checking and putting on a map is one way to do this using functions in [geemap] (https://geemap.org/notebooks/09_plotting/) • A binary input image is expected, but non-integer values are allowed if they range between 0 and 1. This is most appropriate for datasets that have proportion of coverage in a pixel (e.g., a value of 0.5 would represent having half the pixel covered). • If you are adding timeseries data, when creating the function you can use loops/mapping to compile a multiband input and to name each band accordingly.
Key files
Parameters:
lookup_gee_datasets.csvcontains the list of input datasets, the order they will be displayed, which ones are to be excluded from the current analysis, and which ones are shown as flags (i.e., shown as presence or absence instead of figures).
src code
Main Whisp analysis functions are found in the following files:
datasets.pyfunctions for compiling GEE datasets into a single multiband image ready for input into the whisp analysisstats.pyfunctions to run Whisp analysis for each GEE dataset, providing results for coverage of each plot as an area in hectares -risk.pyfunctions for estimating risk of deforestation.
Contributing to the Whisp code base
Contributions to the Whisp code in GitHub are welcome. They can be made by forking the repository making and pushing the required changes, then making a pull request to the Whisp repository. After briefly reviewing the request, we can make a branch for which to make a new pull request to. If in doubt get in contact first or log as an issue [here] (https://github.com/forestdatapartnership/whisp/issues/).
Install the package in editable mode with the additional dependencies required for testing and running pre-commit hooks:
git clone https://github.com/forestdatapartnership/whisp.git
cd whisp/
pip install -e .[dev]
Setup the pre-commit hooks:
pre-commit install
You should be able to run the Pytest suite by simple running the pytest command from the repo's root folder.
Please read the 
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file openforis_whisp-0.1.0a1.tar.gz.
File metadata
- Download URL: openforis_whisp-0.1.0a1.tar.gz
- Upload date:
- Size: 37.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.0.1 CPython/3.12.0 Windows/10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5303ab6bd490480340484a0d525b0810a709223cba613231a19e3af99e303550
|
|
| MD5 |
84ccab602ba95c82bce1264219e51db7
|
|
| BLAKE2b-256 |
0ad25535bc6dc09a768898a8cb4b251b93ee084980b520471d64111c415046dc
|
File details
Details for the file openforis_whisp-0.1.0a1-py3-none-any.whl.
File metadata
- Download URL: openforis_whisp-0.1.0a1-py3-none-any.whl
- Upload date:
- Size: 36.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/2.0.1 CPython/3.12.0 Windows/10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4954df72c97b549720886c51e88a10298d191c823059dc0fe175dc34251da1a4
|
|
| MD5 |
14f7a90b934a30904057c8eaafb99957
|
|
| BLAKE2b-256 |
1e6b173762106e8a93b39953e88f1fc8f180bc30651bd4ff8c4a6dc6c842bee7
|







